介绍
一直想有时间学习爬虫技术,现在来吧,跟着OReilly 出版的Web Scraping with Python 这本书来学习。
环境准备
因为本书推荐Python3为例,去官网下载Python3.x版本的Python安装包,直接安装就好了。安装的时候注意勾选加入path。
话说我还没有学Python呢亲( ⊙ o ⊙ )!,没关系先稀里糊涂的用吧~~~ 不行了再说
第一只爬虫
书中首先做了一些介绍,主要内容是网络传输的过程,说白了就是web交互其实可以跟浏览器没有啥关系,而爬虫就是不通过浏览器从服务端去爬数据...
初见
ok闲言碎语不要讲来写爬虫吧
新建一个文件夹,里面建一个test.py文件,在里面写入:
from urllib.request import urlopen
html = urlopen("http://pythonscraping.com/pages/page1.html")
print(html.read())
据说Python是一个很矫情的对空格、缩进敏感的语言..所以一定要注意不要乱打空格和缩进
保存,然后命令行cd到这个文件的目录:
phython test.py
可以看到打印出来的html
美丽的汤
BeautifulSoup是一个lib,用来更好的解析html和xml的。
安装汤
python3自带了pip所以可以直接用pip安装
pip install beautifulsoup4
Virtual Environments是一个隔离各个项目lib防止冲突的机制,由于我初学,先不用
安装完bs4之后试一下:
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen("http://www.pythonscraping.com/pages/page1.html")
bsObj = BeautifulSoup(html.read())
print(bsObj.h1)
直接使用bsObj.h1找到了html中的h1标签里的内容。这是比较暴力的写法,比较精确的写法是bsObj.html.body.h1
异常处理
异常处理可以使程序更健壮,不容易直接挂掉。看下面的写法:
from urllib.request import urlopen
from urllib.error import HTTPError
from bs4 import BeautifulSoup
def getTitle(url):
try:
html = urlopen(url)
except HTTPError as e:
return None
try:
bsObj = BeautifulSoup(html.read())
title = bsObj.body.h1
except AttributeError as e:
return None
return title
title = getTitle("http://www.pythonscraping.com/pages/page1.html")
if title == None:
print("Title could not be found")
else:
print(title)
以上方法才是比较正规健壮的写法,一定要注意格式,不然会报错的,不行就装个IDE 比如Pycharm,如果格式不正确会有提示。
高级HTML解析
从一个复杂的页面提取到需要的信息可能需要深层的抓取比如:
bsObj.findAll("table")[4].findAll("tr")[2].find("td").findAll("div")[1].find("a")
这样的代码很可怕也很脆弱,当页面出现改动后,这个路径就抓不到信息了。
有什么解决方案?
- 通过手机版或打印预览,来获取更规范的HTML
- 解析网页引用的js文件
- 通过网页URL获取信息
- 从其他类似的网站获取信息
书上说的以上方法很湿,一点都不干货...
BeautifulSoup 的其功能
使用属性、导航树、搜索标签
网页的样式表 也可以用来查找信息
看例子,这个网页,有red和green的文字:
http://www.pythonscraping.com/pages/warandpeace.html
下面我们来爬一下,打印出所有绿色的文字:
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen("http://www.pythonscraping.com/pages/warandpeace.html")
bsObj = BeautifulSoup(html)
nameList = bsObj.findAll("span", {"class":"green"})
for name in nameList:
print(name.get_text())
以上,使用bsObj.findAll(tagName, tagAttributes)查询返回列表
find()和findAll()的用法
findAll(tag, attributes, recursive, text, limit, keywords)
find(tag, attributes, recursive, text, keywords)
查找多个类型的标题:
.findAll({"h1","h2","h3","h4","h5","h6"})
查找多个属性:
.findAll("span", {"class":"green", "class":"red"})
递归
findAll()方法的递归属性默认是true,意味着查找所有子节点。
以内容为条件查询标签:
nameList = bsObj.findAll(text="the prince")
print(len(nameList))
limit
limit是限制查找的个数,比如只返回前10个符合条件的标签
keywords
有点复杂 先不看
Navigation Trees
Navigation Tree就类似这种用法:
bsObj.tag.subTag.anotherSubTag
一个用来做例子的页面:
http://www.pythonscraping.com/pages/page3.html
处理子节点和后代节点
在BeautifulSoup里面 子节点child和“”孙子及后代“descendants 是被两个概念。两个范围没有交集。
注意bsObj.body.h1这个代码返回的不一定是 body-h1,而有可能是body-........h1。
如果只想得到儿子则使用:bsObj.find("table",{"id":"giftList"}).children这种方式。
处理sibling兄弟姐妹
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen("http://www.pythonscraping.com/pages/page3.html")
bsObj = BeautifulSoup(html)
for sibling in bsObj.find("table",{"id":"giftList"}).tr.next_siblings:
print(sibling)
打印出了所有的产品内容,出了第一行title。原因:
- sibling(兄弟)不包括自己
- next_siblings只返回next的,而不是它和它之前的,如果object本身在在队列中间,那么只返回它后面的兄弟
同理如果需要返回前面的兄弟可以使用previous_siblings
以上两周可以理解为,返回哥哥、返回弟弟
另外,去掉siblings后面的s 可以只返回一个靠的最近的兄弟。
处理爹妈,父标签(这标题...)
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen("http://www.pythonscraping.com/pages/page3.html")
bsObj = BeautifulSoup(html)
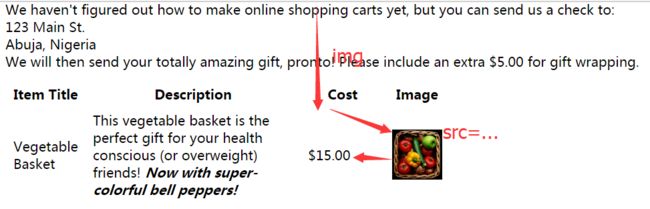
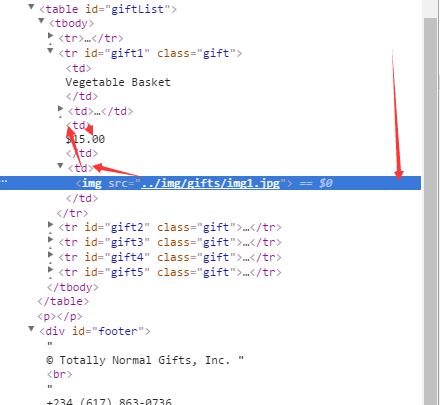
print(bsObj.find("img",{"src":"../img/gifts/img1.jpg"}).parent.previous_sibling.get_text())
正则表达
正则表达式....呃 头大
As the old computer-science joke goes: “Let’s say you have a problem, and you decide
to solve it with regular expressions. Well, now you have two problems.”
爬虫技术脱不了使用正则表达式
上面的例子使用的是准确的src来找到特指的img,但是如果要找很多的img就要使用正则了:
from urllib.request import urlopen
from bs4 import BeautifulSoup
import re
html = urlopen("http://www.pythonscraping.com/pages/page3.html")
bsObj = BeautifulSoup(html)
images = bsObj.findAll("img", {"src":re.compile("\.\.\/img\/gifts/img.*\.jpg")})
for image in images:
print(image["src"])
获取属性
myImgTag.attrs['src']
Lambda表达式
将一个方法作为变量传递到另一个方法中,但是方法的参数必须是一个tag返回一个boolean
例子:
soup.findAll(lambda tag: len(tag.attrs) == 2)
返回有两个属性的标签
这可能是替代正则表达式的一种方法