1.故事背景
泰坦尼克号沉船事故是世界上最著名的沉船事故之一。1912年4月15日,在她的处女航期间,泰坦尼克号撞上冰山后沉没,造成2224名乘客和机组人员中超过1502人的死亡。这一轰动的悲剧震惊了国际社会,并导致更好的船舶安全法规。 事故中导致死亡的一个原因是许多船员和乘客没有足够的救生艇。然而在被获救群体中也有一些比较幸运的因素:一些人群在事故中被救的几率高于其他人,比如妇女、儿童和上层阶级。 在这个case里,我们需要分析,哪些因素会影响一个人是否能够获救,同时利用train数据建立模型对test数据进行预测,检查自己的模型对乘客生存预测的准确度。

2.数据初探
1)了解数据特征含义:
Index(['PassengerId', 'Survived', 'Pclass', 'Name', 'Sex', 'Age', 'SibSp', 'Parch', 'Ticket', 'Fare', 'Cabin', 'Embarked'], dtype='object')
PassengerId:乘客编号,唯一; Survived:是否获救 0未获救 1获救; Pclass:客舱等级;Name:乘客姓名; Sex:性别; Age:年龄;SibSp:在船上的兄弟姐妹或者配偶数量; Parch:在船上的父母或儿女数量; Ticket:船票编号; Fare:船票价格; Cabin:客舱号; Embarked:登船港口
其中PassengerId为预测唯一序号,Survived为预测目标值。
2)了解数据基本情况:
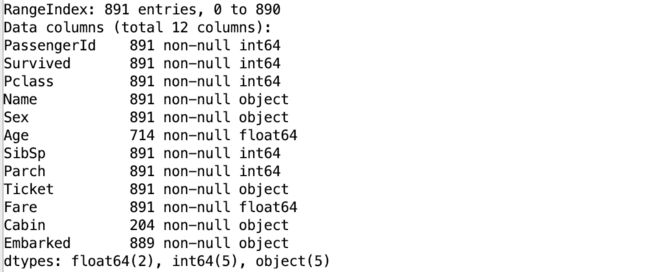
可以发现,训练数据集一共891个样本,其中Age、Cabin、Embarked属性有缺失值。我们需要对缺失值进行处理,Age字段缺失值可以用平均年龄来代替,Cabin字段我们用NP(Not Providied)填充,Embarked字段由于数据仅有两个样本缺值,可以选择随机填充该属性特征例值,或者删除这两个样本,我们选择用随机值填充。
3)查看各特征值有无异常
Survived属性包含0、1两种值无异常,其中549死亡,342存活;Pclass包含1、2、3三种值无异常;Name属性包含891个值,无重复无异常;Sex包含male 577位,female 314位;SibSp 包含0、1、2、3、4、5、8几种值,其中属性为n的人数,应该为n+1的倍数,即若某人有8个SIbSp则至少有9个人互为SibSp,该数据出现的原因是因为训练数据只包含部分船上的人员,因此该特征暂未发现异常;Parch特征类似,暂未发现异常;Ticket字段包含681个不同值,该值为每个票据的基本特征,与生存与否关系不大;特征Fare为船票价格,未发现异常,可能与Pclass属性有关,也可以划分区间作为预测是否存活的特征;特征Cabin存在缺失值可单独处理,另外我们发现客舱编号以A、B、C、D、E开头,可能与船舱位置有关;特征Embarked包含三个值,船上乘客来源于三个地方。
3.特征分析
PassengerId为每个样本的序列值,可以作为index。Name为乘客姓名,与生存与否关系应该不大。因此,我们选择对除这两列的其他特征进行分析。
1)每个特征与是否存活的目标之间的关系分析:
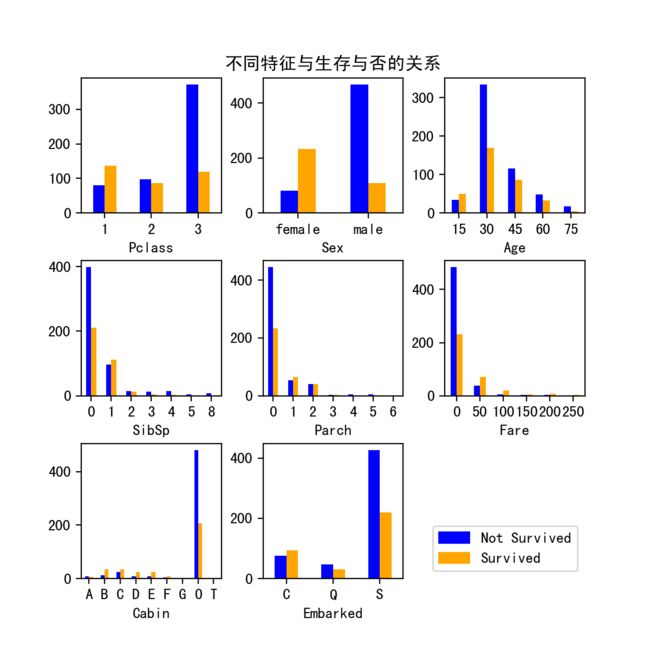
上图子图1展示了不同客舱等级获救人数与未获救人数对比,从图中可以看出Class1获救人数大于未获救人数大约50%,在Class2中获救人数与未获救人数基本持平,在class3中未获救人数远远大于获救人数。子图2中可以看出,女性获救的概率比男性大很多。子图3我们将不同年龄段内获救人数与未获救人数进行分段统计,可以看出老人和孩子获救几率高,而处于20-40之间的人则大多未获救。从子图3、4中可以看出,有亲人同在船上的人获救几率更高。从子图6可以看出船票价值高的乘客获救比例远高于船票价值很低的乘客。在子图7中,我们将未标记船舱的样本标记为O,其余以船舱首字母区分进行统计,我猜测船舱编号的首字母可能与船舱位置或船舱的票价有关,可以看出,无船舱人员大多未能获救,而有船舱的乘客中,BDE等舱的获救比例又高于其他客舱。子图8展示了从不同港口出发的乘客生还对比,可以看出,生还几率C港>Q港>S港。
上图从侧面反应了当时不同阶级之间的不平等,即使在遇到这种大型海难时,有钱的资本家也要比普通人,获救几率大。同时,也可以看出当时的营救策略,老人孩子和妇女先上船,因此更容易获救。许多男性也主动将生还的机会留给了妇女和儿童。这一点值得被称赞。
2)探索部分特征变量之间的关系
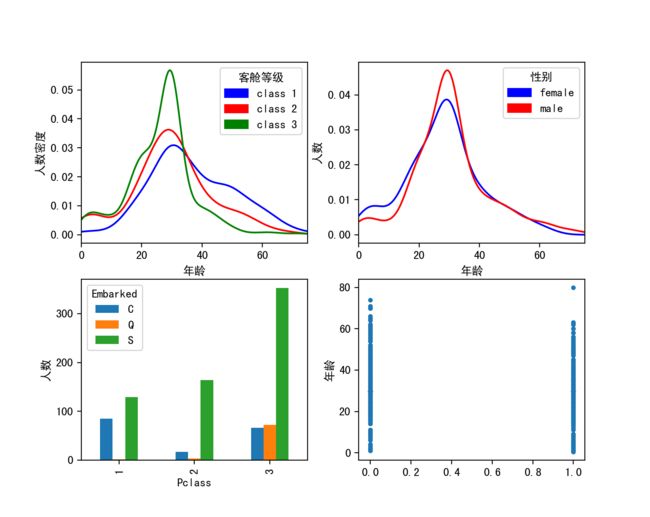
子图一展示了不同客舱等级内乘客年龄的分布,可以发现,客舱等级3年龄主要集中在25左右,而客舱等级2比客舱等级1内年龄稍微偏大,而客舱等级1内则主要为中年以上人群。这正反映了,不同客舱人群收入的不同,年轻人收入较少只能乘坐客舱3,而中年以上有了一定的经济收入和社会地位,更多的集中在客舱2和客舱1。子图2展示了,男女的年龄分布,可以发现男性的年龄分布峰度比女性大,男女分布最多的年龄在30左右。子图4反应了不同港口登船的乘客的客舱等级分布,可以看出,C港登船的人员主要集中在1、3舱,侧面反应了C城市的贫富差距比其他两个城市大(若训练数据为随机抽样,可猜测),而Q港等船的人则大多在3舱,Q城发展水平相比另外两成较低,而登船人员中S港人数最多,说明S港的繁华,也侧面反应S城市的经济繁荣。子图4,我们发现一个有趣的现象,65岁以上只有一个80岁的大爷获救。
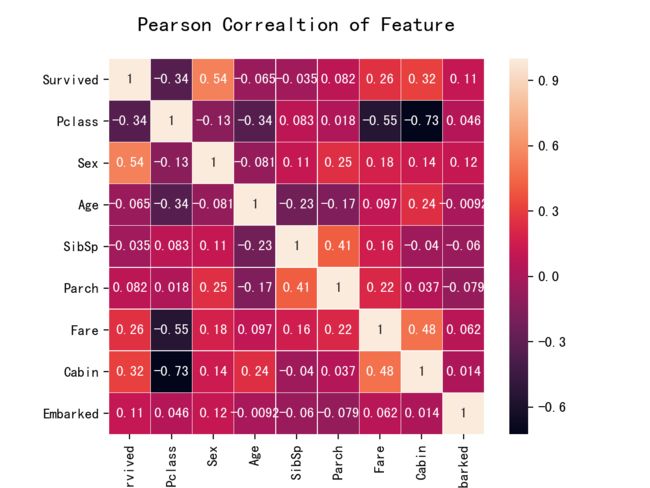
可以看出票价和船舱等级相关性极高,票价越高,等级越高(等级1为高);另一方面由于我们数据进行处理时,将有舱设为1无舱设为0,因此客舱等级与Cabin也呈现出高相关性。
3)特征选择和处理
对特征数值话,弃掉无法用于预测的特征:
df = dataFrame.set_index(['PassengerId'])
df = df.drop(['Name','Ticket'],axis=1)
df['Age'] = df['Age'].fillna(df['Age'].median())
df['Embarked'] = df['Embarked'].fillna(df['Embarked'].value_counts().index[0])
df.loc[df['Sex'] =='male','Sex'] =0
df.loc[df['Sex'] =='female','Sex'] =1
df.loc[df['Embarked'] =='S','Embarked'] =0
df.loc[df['Embarked'] =='C','Embarked'] =1
df.loc[df['Embarked'] =='Q','Embarked'] =2
df.loc[df['Cabin'].notnull(),'Cabin'] =1
df.loc[df['Cabin'].isnull(),'Cabin'] =0
4)特征工程:
train_data =df.copy()
train_data['CabinLetter'] = train_data['Cabin'].map(lambda x: re.compile("([a-zA-Z]+)").search(x).group())
train_data['CabinLetter'] = pd.factorize(train_data['CabinLetter'])[0]
将数据减去平均值
scaler = preprocessing.StandardScaler()
train_data['Age_scaled'] = scaler.fit_transform(train_data['Age'].values.reshape(-1,1))
Embarked进行dummy处理:
train_data['Embarked'].fillna(train_data['Embarked'].mode().iloc[0],inplace=True)
embark_dummies = pd.get_dummies(train_data['Embarked'])
train_data = train_data.join(embark_dummies)
train_data.drop(['Embarked'],axis=1,inplace=True)
将Sex进行factorize处理:
train_data['Sex'] = pd.factorize(train_data['Sex'])[0]
sex_dummies_df = pd.get_dummies(train_data['Sex'],prefix=train_data[['Sex']].columns[0])
train_data = pd.concat([train_data, sex_dummies_df],axis=1)
将Fare分为5各档位:
train_data['Fare'] = train_data[['Fare']].fillna(train_data.groupby('Pclass').transform(np.mean))
train_data['Group_Ticket'] = train_data['Fare'].groupby(
by=train_data['Ticket']).transform('count')
train_data['Fare'] = train_data['Fare'] / train_data['Group_Ticket']
train_data.drop(['Group_Ticket'],axis=1,inplace=True)
train_data['Fare_bin'] = pd.qcut(train_data['Fare'],5)
train_data['Fare_bin_id'] = pd.factorize(train_data['Fare_bin'])[0]
fare_bin_dummies_df = pd.get_dummies(train_data['Fare_bin_id']).rename(columns=lambda x:'Fare_' +str(x))
train_data = pd.concat([train_data, fare_bin_dummies_df],axis=1)
train_data.drop(['Fare_bin'],axis=1,inplace=True)
将每个人以家庭为单位区分,按家庭大小分类:
train_data['Family_Size'] = train_data['Parch'] + train_data['SibSp'] +1
train_data['Family_Size_Category'] = train_data['Family_Size'].map(family_size_category)
le_family = LabelEncoder()
le_family.fit(np.array(['Single','Small_Family','Large_Family']))
train_data['Family_Size_Category'] = le_family.transform(train_data['Family_Size_Category'])
family_size_dummies_df = pd.get_dummies(train_data['Family_Size_Category'],
prefix=train_data[['Family_Size_Category']].columns[0])
train_data = pd.concat([train_data, family_size_dummies_df],axis=1)
4.生存模型预测:
1)线性拟合:对拟合结果>0.5认为生存,拟合结果小于0.5认为死亡
df = load_data('train.csv')
df = pre_processing(df)
lr = liner_regession(df)
df = load_data('test.csv')
df = pre_processing(df)
df.loc[df['Fare'].isna(),'Fare'] =0
predictors = ['Pclass','Sex','Age','SibSp','Parch','Fare','Cabin','Embarked']
test_predictions = lr.predict(df[predictors])
test_predictions[test_predictions >0.5] =1
test_predictions[test_predictions <=0.5] =0
print(test_predictions)
对训练模型采用三折检验,正确率为0.79;对整个训练数据进行参数拟合,并对测试数据进行预测,提交Kaggle,得到错误率0.75,结果比较差。
2)逻辑回归:
predictors = ['Pclass','Sex','Age','SibSp','Parch','Fare','Cabin','Embarked']
LogRegAlg = LogisticRegression(random_state=1,solver='liblinear')
re = LogRegAlg.fit(df[predictors], df["Survived"])
df = load_data('test.csv')
df = pre_processing(df)
df.loc[df['Fare'].isna(),'Fare'] =0
test_predictions = LogRegAlg.predict(df[predictors])
提交Kaggle,得到错误率0.76,正确率有所提高,但还是觉得低。
3)随机森林:
predictors = ['Pclass','Sex','Age','SibSp','Parch','Fare','Cabin','Embarked']
alg = RandomForestClassifier(random_state=1,n_estimators=10,min_samples_split=2,min_samples_leaf=1)
kf = KFold(n_splits=3,shuffle=False,random_state=1)
scores = cross_val_score(alg, df[predictors], df["Survived"],cv=kf)
对训练数据,其交叉检验误差为0.85,提交Kaggle,准确率0.81,虽然在训练数据上准确率有所提高,但是在测试数据上,准确率反而降低了。
4)SVM
predictors = ['Pclass','Sex','Age','SibSp','Parch','Fare','Cabin','Embarked']
rbf_svm = SVC(gamma='auto')
rbf_svm.fit(df[predictors],df['Survived'])
df = load_data('test.csv')
df = pre_processing(df)
df.loc[df['Fare'].isna(),'Fare'] =0
test_predictions = rbf_svm.predict(df[predictors])
对训练数据,其准确率为0.885,然而对测试数据仅为0.72。
5.总结
通过分析,我们发现当时的历史背景下,所属阶层、经济水平处于高位的人更容易获救,并且由于当时的急救策略,女人、孩子以及有家庭成员存在的人更容易获救。并且能够发现,当时上传的三个港口经济发展情况。
通过,集中模型,我们对乘客生存进行预测,发现对于预测结果并不是特别满意,想要获得一个理想对模型,需要对数据进行进一步的特征化,同时可以利用xgboost对不同模型进行融合,调整参数,增加预测准确率。