背景介绍
截至编写此文,A系统已经成功上线2年有多,作为国内主流电商公司核心的基础公共服务系统之一,每天承载了数十亿级别流量。自上线以来成功地经受住了双十一,周年店庆等大促的检验,为我司提供了高效稳定的接口服务。作为稳定服务体系的重要一环,缓存自然是重中之重,本文将对A系统中使用到的缓存组件spymemcached+memcached进行参数阐述,结合spymemcached源码,温故而知新,也算是对过去工作的一次总结,以期能帮助大家避免重复掉坑,并提出一些最优实践建议
spymemcached简介
A系统于memcached通信主要是通过java组件spymemcached来完成,spymemcached底层是通过Java NIO机制来实现,是一个使用简单,异步和单线程的客户端,具体优势如下:
spymemcahed具有如下特点:
高效存储
强力兼容服务器和网络各种中断
全面提供异步操作API
单线程简单高效
极致优化带来高吞吐量处理能力
有兴趣的可以访问官网了解更多:
https://code.google.com/archive/p/spymemcached/
spymemcached中有一些核心组件:
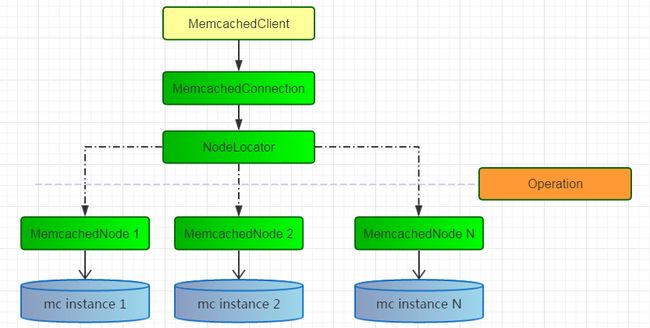
- MemcachedClient:
MemcachedClient是spymemcached对外提供API Facade - MemcachedConnection:
MemcachedConnection是spymemcached的核心组件,它是管理mc链接的manager - NodeLocator:
NodeLocator是用于查找key对应的mc实例,其之类包含常用的查找算法,如ArrayModNodeLocator、KetamaNodeLocator。A系统中使用的就是实现了Ketama 一致性哈希算法的KetamaNodeLocator - MemcachedNode:
MemcachedNode负责与单个mc实例建立连接,处理真正的mc操作。其实现类中通过结合NIO的使用,提供高效mc操作能力 - Operation:
在spymemcaced中任何mc操作都被抽象为Operation。作为传递单位在MemcachedConnection与MemcachedNode之间进行交互。同事,一个相同的操作分别也按照不同协议,提供不同实现,使用者可按需使用
memcached使用那些事:
那些事之一:
A系统上线之初,系统流量慢慢的接入,似乎一切尽在掌控。然而就在一个阳光明媚的周日早上,监控中心的一个电话打破了这美好时光,故障来了:A系统前端接口在9点左右突然响应急剧上升,后台日志发现有大量超时error。经与DBA配合排查,初步断定是A系统mc集群中的一个mc实例有跪了。但奇怪的是,按照我们之前测试场景的认知:一个mc实例跪了,根据一致性hash算法,应该会自动找到替代节点的,而不应该出现生产环境上大量timeout的情况。
经DBA排查,出现故障的mc实例并不是直接down掉,而是hang住了,处于假死的状态,导致spymemcached无法立刻判断该mc实例处于下线状态,而造成后面的请求依然会尝试使用该mc实例。然而一个有趣的现象引起了我们的注意,每个应用实例针对该故障mc实例的TimeoutException都刚好的不超过1000个,是巧合吗?这就得从spymemcached应对TimeoutException的处理机制说起了,从源码可知,spymemcached为某个MemcachedNode的timeout设置了计数器,当timeout累积到了一定程度之后后会断开该链接并尝试重连。
- DEFAULT_MAX_TIMEOUTEXCEPTION_THRESHOLD就是timeout计数器的阀值,默认为998个,这也是为什么所有的TimeoutException都没有超过1000的缘故。
- MemcachedConnection在处理每个operation时都会在handleIO()时触发timeout计数器检查
- 超过timeout阀值之后,像故障mc的状况,新链接将无法创建而导致该实例被spymemcached视作下线,新的mc operation将被rehash到存活的实例中去。
所有的代码都在MemcachedConnection和DefaultConnectionFactory的之内,具体如下:
/**
* Default implementation of ConnectionFactory.
*
*
* This implementation creates connections where the operation queue is an
* ArrayBlockingQueue and the read and write queues are unbounded
* LinkedBlockingQueues. The Redistribute FailureMode is always
* used. If other FailureModes are needed, look at the ConnectionFactoryBuilder.
*
*
*/
public class DefaultConnectionFactory extends SpyObject implements
ConnectionFactory {
...
/**
* Maximum number + 2 of timeout exception for shutdown connection.
*/
public static final int DEFAULT_MAX_TIMEOUTEXCEPTION_THRESHOLD = 998;
...
}
/**
* Main class for handling connections to a memcached cluster.
*/
public class MemcachedConnection extends SpyThread {
...
/**
* Check if one or more nodes exceeded the timeout Threshold.
*/
private void checkPotentiallyTimedOutConnection() {
boolean stillCheckingTimeouts = true;
while (stillCheckingTimeouts) {
try {
for (SelectionKey sk : selector.keys()) {
MemcachedNode mn = (MemcachedNode) sk.attachment();
if (mn.getContinuousTimeout() > timeoutExceptionThreshold) {
getLogger().warn("%s exceeded continuous timeout threshold", sk);
lostConnection(mn);
}
}
stillCheckingTimeouts = false;
} catch(ConcurrentModificationException e) {
getLogger().warn("Retrying selector keys after "
+ "ConcurrentModificationException caught", e);
continue;
}
}
}
/**
* Helper method for {@link #handleIO()} to encapsulate everything that
* needs to be checked on a regular basis that has nothing to do directly
* with reading and writing data.
*
* @throws IOException if an error happens during shutdown queue handling.
*/
private void handleOperationalTasks() throws IOException {
checkPotentiallyTimedOutConnection();
if (!shutDown && !reconnectQueue.isEmpty()) {
attemptReconnects();
}
if (!retryOps.isEmpty()) {
ArrayList operations = new ArrayList(retryOps);
retryOps.clear();
redistributeOperations(operations);
}
handleShutdownQueue();
}
/**
* Handle all IO that flows through the connection.
*
* This method is called in an endless loop, listens on NIO selectors and
* dispatches the underlying read/write calls if needed.
*/
public void handleIO() throws IOException {
...
handleOperationalTasks();
}
...
}
知道原因就好办了,从源码可知,理论上spymemcached已经通过timeout计数器帮我们针对问题mc实例做了隔离,如此算来,该机房我们的应用集群有30台机器,只要能够忍受1000*30=30w次TimeoutException,我们完全可以不去处理该mc实例。但出去对生产环境的敬畏之心,我们还是赶紧的让dba直接将该问题mc实例从生产环境摘除下线,利用一致性hash算法让mc操作快速的分散到其它mc节点。
此次故障虽已顺利解决,但却给我们带来了另外的思考(每次timeout花费的时间将近3s,这对于一个平均响应时间1ms以内的系统而言是无法接受的)——我们系统无法快速的隔离响应(虽然spymemcached已经帮我们做了一定程度的隔离,但我们认为依然不够)
那有什么办法在遇到同样故障场场景的情况下依然保有某种程度的高效响应呢,为此我们修改了代码,将原来同步读写mc的操作变成了异步操作,并在异步操作的代码了设置了超时间(300ms),于是哪怕同样的故障场景发生,起码我们可以将响应时间控制在合理的范围
以下以mc批量读取操作为例
修改前代码:
...
MemcachedClient memcachedClient = (MemcachedClient) (((SpyMemcachedConnection) connection).getNativeConnection());
try {
return memcachedClient.getBulk(keys);
} catch (InterruptedException | ExecutionException | TimeoutException e) {
logger.error("mc getbulk error", e);
}
修改后代码:
...
MemcachedClient memcachedClient = (MemcachedClient) (((SpyMemcachedConnection) connection).getNativeConnection());
try {
return memcachedClient.asyncGetBulk(keys).get(300, TimeUnit.MILLISECONDS);
} catch (InterruptedException | ExecutionException | TimeoutException e) {
logger.error("mc getbulk error", e);
}
TIPS 最佳实践:
- Fail fast, 以上面故障场景为例,在高响应大并发的场景下,穿透缓存回源db获取相应信息并非不可接受,所以有时候快速失败(Fail fast)是更好的一种选择
那些事之二:
从上面的场景一我们建议Failfast,那是否将超时时间设得越短越好,答案显然不是的,就A系统的后端域后台任务而言,每天需要完成大量的批量mc操作,mc操作主要集中在类似缓存预热/缓存更新上,这类操作对每笔操作的时间要求不是十分的严格,反而要求的是确保百分百的成功率,但凡有任何更新失败,都会影响线上售卖。
针对这种情况,我们做了以下措施:
- 将mc操作的OperationTimeoutException时间设置为2500ms
- 针对mc操作失败的加入了重试机制
尽然我们已经设置了较大的超时时间,按理说不应该出现OperationTimeoutException的了,然而没天预热程序都有少量的超时出现:
[2017-10-10 06:58:47.491][ERROR] [init_cache_db-pool-12] [c.vip.venus.data.memcached.core.MemcachedAccessor]
>>> net.spy.memcached.OperationTimeoutException: Timeout waiting for bulk values: waited 2,500 ms.
Node status: Connection Status { ... active: true, authed: true, last read: 2,905 ms ago }
at net.spy.memcached.MemcachedClient.getBulk(MemcachedClient.java:1567)
at net.spy.memcached.MemcachedClient.getBulk(MemcachedClient.java:1601)
at net.spy.memcached.MemcachedClient.getBulk(MemcachedClient.java:1616)
所以我们怀疑:
- 批量操作的item数太多需要更大
- 网络抖动
- spymemcached性能瓶颈
但后面的跟踪分析都一一否定了上面的假设
- 批量操作的item数太多需要更大
首先,我们发现OperationTimeoutException出现的情况,就算是在操作单独一个mc key时候也会出现,这就很奇怪,很能说明问题了——说明了OperationTimeoutException与数量没有必然的因果关系 - 网络抖动
其次,若是网络抖动问题,同台机器&同个实例的操作应该一起出现OperationTimeoutException问题,然而现实并没有 - spymemcached性能瓶颈
在开发环境,我们模拟线上加大线程,加大并发去测试,也无法重现线上问题
-最终网上的一篇技术讨论使我豁然开朗
 image.png
image.png
http://grokbase.com/t/gg/spymemcached/137nxny78q/issues-with-operationtimeoutexception
于是我们转向了应用的gc日志:
2017-10-10T06:58:44.152+0800: 3523.843: [GC [PSYoungGen: 1310002K->547861K(1488576K)] 3306395K->2545237K(3585728K), 0.3244270 secs] [Times: user=5.74 sys=0.00, real=0.33 secs]
2017-10-10T06:58:44.738+0800: 3524.430: [GC [PSYoungGen: 1488533K->608553K(1307712K)] 3485909K->2675273K(3404864K), 0.4456690 secs] [Times: user=5.90 sys=2.07, real=0.44 secs]
2017-10-10T06:58:45.184+0800: 3524.875: [Full GC [PSYoungGen: 608553K->0K(1307712K)] [PSOldGen: 2066720K->960493K(2097152K)] 2675273K->960493K(3404864K) [PSPermGen: 32161K->32161K(262144K)], 2.2263360 secs] [Times: user=2.23 sys=0.00, real=2.23 secs]
2017-10-10T06:58:47.640+0800: 3527.331: [GC [PSYoungGen: 699136K->183558K(1398144K)] 1659629K->1144051K(3495296K), 0.1224060 secs] [Times: user=2.13 sys=0.04, real=0.12 secs]
2017-10-10T06:58:48.049+0800: 3527.741: [GC [PSYoungGen: 882694K->174247K(1398144K)] 1843187K->1134740K(3495296K), 0.0936960 secs] [Times: user=1.66 sys=0.00, real=0.09 secs]
2017-10-10T06:58:48.454+0800: 3528.145: [GC [PSYoungGen: 873383K->259059K(958208K)] 1833876K->1219552K(3055360K), 0.1439410 secs] [Times: user=2.55 sys=0.01, real=0.15 secs]
2017-10-10T06:58:48.855+0800: 3528.547: [GC [PSYoungGen: 958195K->257351K(1399808K)] 1918688K->1217845K(3496960K), 0.1370100 secs] [Times: user=2.44 sys=0.00, real=0.14 secs]
从日志系统中可以看到,OperationTimeoutException和Full GC的在时间点上是吻合的,它俩结对出现,问题到此就豁然开朗了,罪魁祸首就是应用程序的FUll GC导致STW。而解决办法自然就是整改优化代码,尽量减少应用的Full GC了,至于如何减少Full GC这个话题完全可以拉出一篇新的讨论了,在此便不再展开:)。
TIPS 最佳实践:
- Design For Failure,任何涉及准确性高的系统都需要在设计之初就考虑怎么处理失败的状况,而可以幂等操作的retry就是其中有效的方式之一
- 天下武功为快不破,系统性能恶化或者异常往往来自于大而重的设计,轻而快才是程序优化的方向
那些事之三:
从场景一可以看到,利用一致性hash算法,spymemcached可以自动的应对某个mc实例down掉的情况,从而进行rehash。然而假设线上不是只有某个mc实例down掉,而是2个,3个,...n个呢?为此,我们通过模拟A系统生产环境逐个mc down掉的状况,接下来会出现什么状况呢?好吧,让我们一探究竟
测试场景:拿100个sku,让key均匀的分布在15个mc实例中,压力机开10个线程,
每次请求使用批量10个sku,在压力机一直运行的情况下,不断地逐个关闭mc实例,
并监控其TPS及响应时间
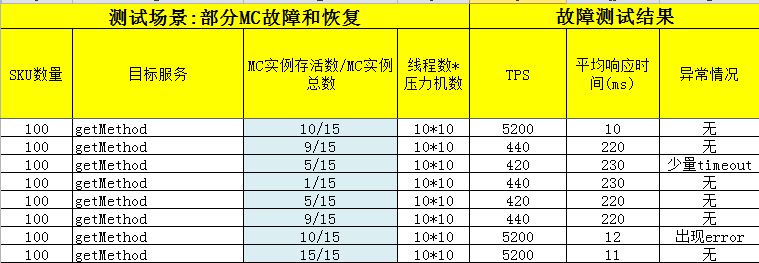
从测试结果可以看到,只要down掉的mc实例超过6个,TPS会有断崖式的下降。说好的spymemcached会自动rehash的情况没有出现。实际情况再一次和我之前的认知不一致了,跟踪spymemcached其源码,具体如下:
public final class KetamaNodeLocator extends SpyObject implements NodeLocator {
...
public Iterator getSequence(String k) {
// Seven searches gives us a 1 in 2^7 chance of hitting the
// same dead node all of the time.
return new KetamaIterator(k, 7, getKetamaNodes(), hashAlg);
}
...
}
也就是说spymemcached在hash了7次之后就直接采取回源的策略了,所以如果要让spymemcached继续重试rehash,完全可以通过新增一个NodeLocator子类,重写getSequence方法增大重试次数。
public Iterator getSequence(String k) {
return new KetamaIterator(k, 14, getKetamaNodes(), hashAlg);
}
注:个人意见而言并非重试次数越多越好,得根据自身业务通过测试得到其最优值
那些事之四:
随着A系统的日常访问量节节攀升(截至目前为止录得最大qps为33w,每天总流量高峰可达40亿次),还有数据量的不断累积(20亿条数据左右)。在大访问量和大数据量访问的过程,其中最直接的体现就是网卡流量,netin/netout的不断攀升,后来进行的线上压测都最终由于网卡流量告警而鸣金收兵。所以针对系统德尔优化势在必行,而我们优化最先想到的就是压缩缓存大小,通过此举应该可以获得几个好处:
- 减少网络流量,避免告警
- 较少mc的占用内存大小
- 更少的网络流量,带来更快的响应速度
于是乎我们通过一些方式减少了缓存的大小:
- 从业务上压缩数据量的大小
- 对字段进行最小编码,从而获得数据体积的压缩,减少网络传输压力
完了就愉快顺利上线了,然而事与愿违的状况有发生了,问题又来了。。。
- mc占用内存的大小不减反增加
- 网络流量mc实例的net-out确实减少了
-
接口响应出现强烈的抖动,而且非常之有规律,呈锯齿状,波动不停
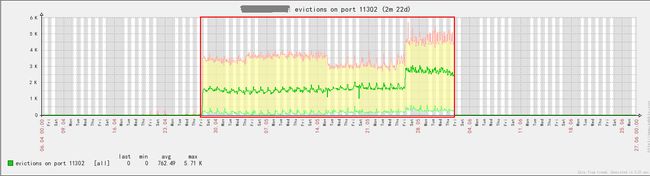
通过反复的查找,问题终于被定为出来了,变动上线之后,导致到一个明显的情况是mc的淘汰数不断上升,而在这之前,该指标一直为0,留意到淘汰率的变化之后,状况就解释的通了,响应时间不断抖动的原因就是不断的有一批key被淘汰出来,从而导致回源db获取数据造成响应下降。
 问题mc实例移除率.png
问题mc实例移除率.png
道理是明白了,可为什么会发生淘汰?
这就得从mc的内存模型说起了,下面是memcached的一个内存示意图:

该图片可以简单的理解为:
- memcached所占用的均被Slab Class * 所拥有
- 我们往memcached所塞的key-value是按Chunk存储的
- 每个Slab Class扩容时是以Page为单位的,默认是1M,然后再按Slab中Chunk的大小切成容量一致的多个小块
- memcached对已经分配的Slab中Chunk的个数不会重新分配,除非通过命令强制调整或重启实例
- memcached对已过期的item做懒清除,只有新的item被划分到对应slab,需要用到对应的chunk时才会根据LRU等具体算法对其内存进行重新利用
此时我们查了下问题的mc实例:
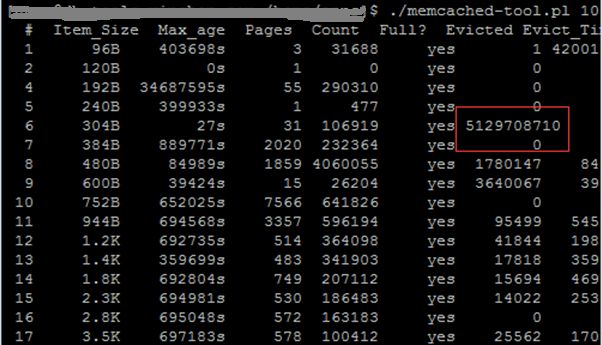
从slab分布详情真可以看出304B这个slab不断的在做evict,同时480B和600B也有不少移除,至此问题根源已经清晰:
- 304B Slab不断的evict是造成缓存击穿,接口响应不断周期抖动的具体原因
- 在对mc内容进行压缩之前,value主要分布在752B~3.5K之间的slabs中
- 在对mc内容进行压缩之后,value主要分布在304B~600B之间的slabs中
- 由于压缩之前的几个大slab被大量数据填塞后,留给其它slab的空间就不多了
- 所以压手内容之后的slab由于无法申请更多的内存,而只能通过不断的移除来满足新增key的使用
至此,我们通过安排mc实例在低流量时间进行重启,重启之后evict又恢复了往日的移除率,基本为零;而接口响应也如之前说预计在更小的网络开销下得到了将近50%的性能提升。
写在最后
memcached的使用只是我们系统的一部分,而一个稳定高效的系统还远远不止这些,需要有很多相关配套措施。例如为了克服跨机房的调用延时,我们在主要的机房都部署了相应的mc集群。当然更多的mc集群也对我们的mc操作提出了更更高的要求,比如说进群中的一致性问题。另外我们也使用loacal cache等方式结合mc使用,以达到更好的效果。而这所有的所有,都是在系统发展到一定程度或者遇到了某些问题之后,慢慢调整和进化而来。公司在不断的发展,技术人员在不断的进步,而系统也在不断的进化中日益强大,我在想,这应该就是技术人追求的发展道路。
关键字:spymemcached 源码 memcaced slab 电商系统 大并发 低延迟
参考文档及wiki:
http://grokbase.com/t/gg/spymemcached/137nxny78q/issues-with-operationtimeoutexception
http://blog.51cto.com/dba10g/1840065