这是我们源码解读的最后一个部分了。fine-tune搞明白之后推断也就没必要再分析了,反正形式都是一样的,重要的是明白根据不同任务调整输入格式和对loss的构建,这两个知识点学会之后,基本上也可以依葫芦画瓢做一些自己的任务了。
bert官方给了两个任务的fine-tune代码:
1.run_classifier.py
2.run_squad.py
其实就是我们在Bert系列(一)——demo运行里运行的demo,下面我就对这两个代码进行展开说明:
一、run_classifier.py
1、参数
## Required parameters
flags.DEFINE_string(
"data_dir", None,
"The input data dir. Should contain the .tsv files (or other data files) "
"for the task.")
flags.DEFINE_string(
"bert_config_file", None,
"The config json file corresponding to the pre-trained BERT model. "
"This specifies the model architecture.")
flags.DEFINE_string("task_name", None, "The name of the task to train.")
flags.DEFINE_string("vocab_file", None,
"The vocabulary file that the BERT model was trained on.")
flags.DEFINE_string(
"output_dir", None,
"The output directory where the model checkpoints will be written.")
## Other parameters
flags.DEFINE_string(
"init_checkpoint", None,
"Initial checkpoint (usually from a pre-trained BERT model).")
flags.DEFINE_bool(
"do_lower_case", True,
"Whether to lower case the input text. Should be True for uncased "
"models and False for cased models.")
flags.DEFINE_integer(
"max_seq_length", 128,
"The maximum total input sequence length after WordPiece tokenization. "
"Sequences longer than this will be truncated, and sequences shorter "
"than this will be padded.")
flags.DEFINE_bool("do_train", False, "Whether to run training.")
flags.DEFINE_bool("do_eval", False, "Whether to run eval on the dev set.")
flags.DEFINE_bool(
"do_predict", False,
"Whether to run the model in inference mode on the test set.")
flags.DEFINE_integer("train_batch_size", 32, "Total batch size for training.")
flags.DEFINE_integer("eval_batch_size", 8, "Total batch size for eval.")
flags.DEFINE_integer("predict_batch_size", 8, "Total batch size for predict.")
flags.DEFINE_float("learning_rate", 5e-5, "The initial learning rate for Adam.")
flags.DEFINE_float("num_train_epochs", 3.0,
"Total number of training epochs to perform.")
flags.DEFINE_float(
"warmup_proportion", 0.1,
"Proportion of training to perform linear learning rate warmup for. "
"E.g., 0.1 = 10% of training.")
flags.DEFINE_integer("save_checkpoints_steps", 1000,
"How often to save the model checkpoint.")
flags.DEFINE_integer("iterations_per_loop", 1000,
"How many steps to make in each estimator call.")
flags.DEFINE_bool("use_tpu", False, "Whether to use TPU or GPU/CPU.")
tf.flags.DEFINE_string(
"tpu_name", None,
"The Cloud TPU to use for training. This should be either the name "
"used when creating the Cloud TPU, or a grpc://ip.address.of.tpu:8470 "
"url.")
tf.flags.DEFINE_string(
"tpu_zone", None,
"[Optional] GCE zone where the Cloud TPU is located in. If not "
"specified, we will attempt to automatically detect the GCE project from "
"metadata.")
tf.flags.DEFINE_string(
"gcp_project", None,
"[Optional] Project name for the Cloud TPU-enabled project. If not "
"specified, we will attempt to automatically detect the GCE project from "
"metadata.")
tf.flags.DEFINE_string("master", None, "[Optional] TensorFlow master URL.")
flags.DEFINE_integer(
"num_tpu_cores", 8,
"Only used if `use_tpu` is True. Total number of TPU cores to use.")
这些参数相信运行过demo的同学都已经认识了,不认识读读上面的英文解释也大概能明白什么意思。其中有两个可能需要说明下:
max_seq_length:指定WordPiece tokenization 之后的sequence的最大长度,要求小于等于预训练模型的最大sequence长度。当输入的数据长度小于max_seq_length时用0补齐,如果长度大于max_seq_length则truncate处理;
warmup_proportion:warm up 步数的比例,比如说总共学习100步,warmup_proportion=0.1表示前10步用来warm up,warm up时以较低的学习率进行学习(lr = global_step/num_warmup_steps * init_lr),10步之后以正常(或衰减)的学习率来学习。至于这么做的目的不太明白,有知道的同学请务必留言告诉我下,感激不尽。
2、数据预处理(以MRPC为例)
class InputExample(object):
"""A single training/test example for simple sequence classification."""
def __init__(self, guid, text_a, text_b=None, label=None):
self.guid = guid
self.text_a = text_a
self.text_b = text_b
self.label = label
这是输入语料样本的数据结构。
guid是该样本的唯一ID,text_a和text_b表示句子对,lable表示句子对关系,如果是test数据集则label统一为0。
class InputFeatures(object):
"""A single set of features of data."""
def __init__(self, input_ids, input_mask, segment_ids, label_id):
self.input_ids = input_ids
self.input_mask = input_mask
self.segment_ids = segment_ids
self.label_id = label_id
tokenization过后的样本数据结构,input_ids其实就是tokens的索引,input_mask不用解释,segment_ids对应模型的token_type_ids以上三者构成模型输入的X,label_id是标签,对应Y。
class MrpcProcessor(DataProcessor):
"""Processor for the MRPC data set (GLUE version)."""
def get_train_examples(self, data_dir):
"""See base class."""
return self._create_examples(
self._read_tsv(os.path.join(data_dir, "train.tsv")), "train")
def get_dev_examples(self, data_dir):
"""See base class."""
return self._create_examples(
self._read_tsv(os.path.join(data_dir, "dev.tsv")), "dev")
def get_test_examples(self, data_dir):
"""See base class."""
return self._create_examples(
self._read_tsv(os.path.join(data_dir, "test.tsv")), "test")
def get_labels(self):
"""See base class."""
return ["0", "1"]
def _create_examples(self, lines, set_type):
"""Creates examples for the training and dev sets."""
examples = []
for (i, line) in enumerate(lines):
if i == 0:
continue
guid = "%s-%s" % (set_type, i)
text_a = tokenization.convert_to_unicode(line[3])
text_b = tokenization.convert_to_unicode(line[4])
if set_type == "test":
label = "0"
else:
label = tokenization.convert_to_unicode(line[0])
examples.append(
InputExample(guid=guid, text_a=text_a, text_b=text_b, label=label))
return examples
MRPC的数据解析器,输入格式:
label 句子1ID 句子2ID 句子1 句子2
输出的格式为InputExample数据结构。
def file_based_convert_examples_to_features(
examples, label_list, max_seq_length, tokenizer, output_file):
"""Convert a set of `InputExample`s to a TFRecord file."""
writer = tf.python_io.TFRecordWriter(output_file)
for (ex_index, example) in enumerate(examples):
if ex_index % 10000 == 0:
tf.logging.info("Writing example %d of %d" % (ex_index, len(examples)))
feature = convert_single_example(ex_index, example, label_list,
max_seq_length, tokenizer)
def create_int_feature(values):
f = tf.train.Feature(int64_list=tf.train.Int64List(value=list(values)))
return f
features = collections.OrderedDict()
features["input_ids"] = create_int_feature(feature.input_ids)
features["input_mask"] = create_int_feature(feature.input_mask)
features["segment_ids"] = create_int_feature(feature.segment_ids)
features["label_ids"] = create_int_feature([feature.label_id])
tf_example = tf.train.Example(features=tf.train.Features(feature=features))
writer.write(tf_example.SerializeToString())
将examples转换成features,用到的函数是convert_single_example:
def convert_single_example(ex_index, example, label_list, max_seq_length,
tokenizer):
"""Converts a single `InputExample` into a single `InputFeatures`."""
label_map = {}
for (i, label) in enumerate(label_list):
label_map[label] = i
tokens_a = tokenizer.tokenize(example.text_a)
tokens_b = None
if example.text_b:
tokens_b = tokenizer.tokenize(example.text_b)
if tokens_b:
_truncate_seq_pair(tokens_a, tokens_b, max_seq_length - 3)
else:
# Account for [CLS] and [SEP] with "- 2"
if len(tokens_a) > max_seq_length - 2:
tokens_a = tokens_a[0:(max_seq_length - 2)]
tokens = []
segment_ids = []
tokens.append("[CLS]")
segment_ids.append(0)
for token in tokens_a:
tokens.append(token)
segment_ids.append(0)
tokens.append("[SEP]")
segment_ids.append(0)
if tokens_b:
for token in tokens_b:
tokens.append(token)
segment_ids.append(1)
tokens.append("[SEP]")
segment_ids.append(1)
input_ids = tokenizer.convert_tokens_to_ids(tokens)
input_mask = [1] * len(input_ids)
# Zero-pad up to the sequence length.
while len(input_ids) < max_seq_length:
input_ids.append(0)
input_mask.append(0)
segment_ids.append(0)
assert len(input_ids) == max_seq_length
assert len(input_mask) == max_seq_length
assert len(segment_ids) == max_seq_length
label_id = label_map[example.label]
if ex_index < 5:
tf.logging.info("*** Example ***")
tf.logging.info("guid: %s" % (example.guid))
tf.logging.info("tokens: %s" % " ".join(
[tokenization.printable_text(x) for x in tokens]))
tf.logging.info("input_ids: %s" % " ".join([str(x) for x in input_ids]))
tf.logging.info("input_mask: %s" % " ".join([str(x) for x in input_mask]))
tf.logging.info("segment_ids: %s" % " ".join([str(x) for x in segment_ids]))
tf.logging.info("label: %s (id = %d)" % (example.label, label_id))
feature = InputFeatures(
input_ids=input_ids,
input_mask=input_mask,
segment_ids=segment_ids,
label_id=label_id)
return feature
把一个InputExample数据转换成InputFeatures数据结构。
(1)构造label_map ,因为label_list就["0", "1"]所以,label_map ={"0":0, "1":1};
(2)将text_a和text_b转化成token_a和token_b,并且将二者截取到长度之和为max_seq_length - 3,如果只有token_a没有token_b,则将tokens_a截取到长度为max_seq_length - 2;
(3)构造tokens和segment_ids,如果不满足长度用0补齐,并且构造input_mask。
3、模型构建
def create_model(bert_config, is_training, input_ids, input_mask, segment_ids,
labels, num_labels, use_one_hot_embeddings):
"""Creates a classification model."""
model = modeling.BertModel(
config=bert_config,
is_training=is_training,
input_ids=input_ids,
input_mask=input_mask,
token_type_ids=segment_ids,
use_one_hot_embeddings=use_one_hot_embeddings)
output_layer = model.get_pooled_output()
hidden_size = output_layer.shape[-1].value
output_weights = tf.get_variable(
"output_weights", [num_labels, hidden_size],
initializer=tf.truncated_normal_initializer(stddev=0.02))
output_bias = tf.get_variable(
"output_bias", [num_labels], initializer=tf.zeros_initializer())
with tf.variable_scope("loss"):
if is_training:
# I.e., 0.1 dropout
output_layer = tf.nn.dropout(output_layer, keep_prob=0.9)
logits = tf.matmul(output_layer, output_weights, transpose_b=True)
logits = tf.nn.bias_add(logits, output_bias)
probabilities = tf.nn.softmax(logits, axis=-1)
log_probs = tf.nn.log_softmax(logits, axis=-1)
one_hot_labels = tf.one_hot(labels, depth=num_labels, dtype=tf.float32)
per_example_loss = -tf.reduce_sum(one_hot_labels * log_probs, axis=-1)
loss = tf.reduce_mean(per_example_loss)
return (loss, per_example_loss, logits, probabilities)
X和Y都已经构造好了,将X作为模型的输入,剩下的就是将模型输出和Y进行计算得到loss。
这里的模型输出取的是pooled_output,之前我们已经说过pooled_output是模型最后一层的第一个片段。之后再用一个全连接+softmax和labels的one_hot计算loss。
二、run_squad.py
run_squad是基于SQuAD数据进行阅读理解任务的fine-tune,除了X/Y数据的转换、loss构建其他和run_classifier是一样的,下面我们重点学习下这两块。
1、X/Y数据的转换
class SquadExample(object):
def __init__(self,
qas_id,
question_text,
doc_tokens,
orig_answer_text=None,
start_position=None,
end_position=None,
is_impossible=False):
self.qas_id = qas_id
self.question_text = question_text
self.doc_tokens = doc_tokens
self.orig_answer_text = orig_answer_text
self.start_position = start_position
self.end_position = end_position
self.is_impossible = is_impossible
qas_id 样本ID,question_text问题文本,doc_tokens阅读材料[word0, word1, ...]的形式,orig_answer_text 原始答案的文本,start_position答案在文本中开始的位置,end_position答案在文本中结束的位置,is_impossible在SQuAD2里才会用到的字段这里可以不用关心。
class InputFeatures(object):
"""A single set of features of data."""
def __init__(self,
unique_id,
example_index,
doc_span_index,
tokens,
token_to_orig_map,
token_is_max_context,
input_ids,
input_mask,
segment_ids,
start_position=None,
end_position=None,
is_impossible=None):
self.unique_id = unique_id
self.example_index = example_index
self.doc_span_index = doc_span_index
self.tokens = tokens
self.token_to_orig_map = token_to_orig_map
self.token_is_max_context = token_is_max_context
self.input_ids = input_ids
self.input_mask = input_mask
self.segment_ids = segment_ids
self.start_position = start_position
self.end_position = end_position
self.is_impossible = is_impossible
unique_id feature的唯一id,example_index样本的索引,用于建立feature和example的对应,
doc_span_index该feature在doc_span的索引,如果一个文本很长,那么势必需要对其进行截取,截取成若干片段装进doc_span,doc_span里的各个片段会装进各个feature里面,所以一个feature对应的就会有一个doc_span_index;
tokens该样本的token序列,token_to_orig_map是tokens里面每一个token在原始doc_token的索引;
token_is_max_context是一个序列,里面的值表示该位置的token在当前span里面是否是最全上下文的。
例如bought这个词
Doc: the man went to the store and bought a gallon of milk
Span A: the man went to the
Span B: to the store and bought
Span C: and bought a gallon of
bought在spanB和spanC里都有出现,但很显然span C里bought是语境最全的,既有上文也有下文
input_ids 是tokens转化为token id作为模型的输入,input_mask 、segment_ids、is_impossible 不用多说了;
start_position 、 end_position为答案在当前tokens序列里面的位置(跟上面的不同,不是整个context里面的位置),需要注意的是如果答案不在当前span里的话,start_position 、 end_position均为0 。
SquadExample到InputFeatures转换的过程也是类似的,不用细讲,与run_classifier唯一不同的是classifier的输入是[CLS]句子a[SEP]句子b[SEP], 而squad是[CLS]问题[SEP]阅读材料片段[SEP]。
input_ids = features["input_ids"]
input_mask = features["input_mask"]
segment_ids = features["segment_ids"]
和这三个元素作为模型的输入X,而start_position和end_position作为Y,如果知道了Y就等于知道了答案的位置,然后反向在阅读材料context里面去找出来就可以了,逻辑大概就是这样。
2、loss构建
def model_fn_builder(bert_config, init_checkpoint, learning_rate,
num_train_steps, num_warmup_steps, use_tpu,
use_one_hot_embeddings):
"""Returns `model_fn` closure for TPUEstimator."""
def model_fn(features, labels, mode, params): # pylint: disable=unused-argument
"""The `model_fn` for TPUEstimator."""
tf.logging.info("*** Features ***")
for name in sorted(features.keys()):
tf.logging.info(" name = %s, shape = %s" % (name, features[name].shape))
unique_ids = features["unique_ids"]
input_ids = features["input_ids"]
input_mask = features["input_mask"]
segment_ids = features["segment_ids"]
is_training = (mode == tf.estimator.ModeKeys.TRAIN)
(start_logits, end_logits) = create_model(
bert_config=bert_config,
is_training=is_training,
input_ids=input_ids,
input_mask=input_mask,
segment_ids=segment_ids,
use_one_hot_embeddings=use_one_hot_embeddings)
tvars = tf.trainable_variables()
initialized_variable_names = {}
scaffold_fn = None
if init_checkpoint:
(assignment_map, initialized_variable_names
) = modeling.get_assignment_map_from_checkpoint(tvars, init_checkpoint)
if use_tpu:
def tpu_scaffold():
tf.train.init_from_checkpoint(init_checkpoint, assignment_map)
return tf.train.Scaffold()
scaffold_fn = tpu_scaffold
else:
tf.train.init_from_checkpoint(init_checkpoint, assignment_map)
tf.logging.info("**** Trainable Variables ****")
for var in tvars:
init_string = ""
if var.name in initialized_variable_names:
init_string = ", *INIT_FROM_CKPT*"
tf.logging.info(" name = %s, shape = %s%s", var.name, var.shape,
init_string)
output_spec = None
if mode == tf.estimator.ModeKeys.TRAIN:
seq_length = modeling.get_shape_list(input_ids)[1]
def compute_loss(logits, positions):
one_hot_positions = tf.one_hot(
positions, depth=seq_length, dtype=tf.float32)
log_probs = tf.nn.log_softmax(logits, axis=-1)
loss = -tf.reduce_mean(
tf.reduce_sum(one_hot_positions * log_probs, axis=-1))
return loss
start_positions = features["start_positions"]
end_positions = features["end_positions"]
start_loss = compute_loss(start_logits, start_positions)
end_loss = compute_loss(end_logits, end_positions)
total_loss = (start_loss + end_loss) / 2.0
train_op = optimization.create_optimizer(
total_loss, learning_rate, num_train_steps, num_warmup_steps, use_tpu)
output_spec = tf.contrib.tpu.TPUEstimatorSpec(
mode=mode,
loss=total_loss,
train_op=train_op,
scaffold_fn=scaffold_fn)
elif mode == tf.estimator.ModeKeys.PREDICT:
predictions = {
"unique_ids": unique_ids,
"start_logits": start_logits,
"end_logits": end_logits,
}
output_spec = tf.contrib.tpu.TPUEstimatorSpec(
mode=mode, predictions=predictions, scaffold_fn=scaffold_fn)
else:
raise ValueError(
"Only TRAIN and PREDICT modes are supported: %s" % (mode))
return output_spec
return model_fn
从上面的代码我们可以发现,loss由两部分组成,答案start_positions的预测和end_positions的预测。
def create_model(bert_config, is_training, input_ids, input_mask, segment_ids,
use_one_hot_embeddings):
"""Creates a classification model."""
model = modeling.BertModel(
config=bert_config,
is_training=is_training,
input_ids=input_ids,
input_mask=input_mask,
token_type_ids=segment_ids,
use_one_hot_embeddings=use_one_hot_embeddings)
final_hidden = model.get_sequence_output()
final_hidden_shape = modeling.get_shape_list(final_hidden, expected_rank=3)
batch_size = final_hidden_shape[0]
seq_length = final_hidden_shape[1]
hidden_size = final_hidden_shape[2]
output_weights = tf.get_variable(
"cls/squad/output_weights", [2, hidden_size],
initializer=tf.truncated_normal_initializer(stddev=0.02))
output_bias = tf.get_variable(
"cls/squad/output_bias", [2], initializer=tf.zeros_initializer())
final_hidden_matrix = tf.reshape(final_hidden,
[batch_size * seq_length, hidden_size])
logits = tf.matmul(final_hidden_matrix, output_weights, transpose_b=True)
logits = tf.nn.bias_add(logits, output_bias)
logits = tf.reshape(logits, [batch_size, seq_length, 2])
logits = tf.transpose(logits, [2, 0, 1])
unstacked_logits = tf.unstack(logits, axis=0)
(start_logits, end_logits) = (unstacked_logits[0], unstacked_logits[1])
return (start_logits, end_logits)
模型的输出来自于sequence_output,即模型最后一层的输出,shape为[batch_size, seq_length, hidden_size ],之后再加一个全连接层,unpack成两个部分,分别对应答案的两个位置。
总结:
以上便是这两个demo的全部解读,squad里有很多细节特别是sample到feature的转换过程,比较复杂,但因为时间有限我们不做具体介绍,感兴趣的同学可以自己深入阅读一下。
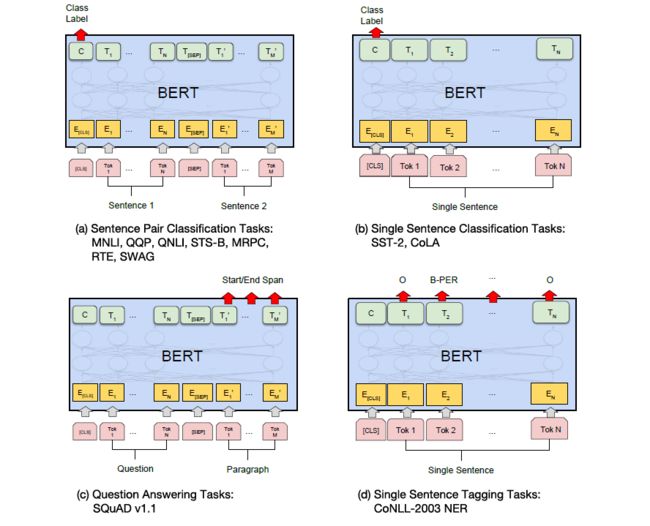
这两个任务可以和论文里面的示意图结合起来看,句子对分类任务对应的是图(a),阅读理解任务对应的是图(c)
本文系列
Bert系列(一)——demo运行
Bert系列(二)——模型主体源码解读
Bert系列(三)——源码解读之Pre-train
Bert系列(五)——中文分词实践 F1 97.8%(附代码)
Reference
1.https://github.com/google-research/bert
2.BERT: Pre-training of Deep Bidirectional Transformers for
Language Understanding