第一章 OpenStack基础
- OpenStack管理的资源及提供的服务
OpenStack做为一个操作系统,它管理的资源主要有三个方面:计算,存储,网络。OpenStack管理这些资源并提供给上层应用或用户去使用。这些资源管理是通过OpenStack中的各个项目来实现的。其中计算资源管理相关项目是Nova;存储相关的主要有块存储服务Cinder,对象存储服务Swift和镜像存储服务Glance;与网络相关的主要是一个和软件定义网络相关的项目Neutron(原名叫Qauntum)。另外Nova中有一个管理网络的模块叫做NovaNetwork,它做为一个比较稳定的遗留组件,现在仍然在OpenStack里和Neutron并存,在小规模部署里面,为了追求稳定和减少工作量会去使用它对网络资源进行管理。
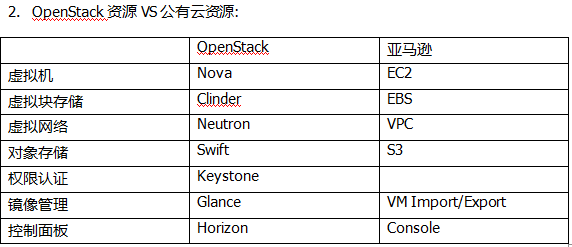
2.OpenStack资源VS公有云资源:
- OpenStack基本组件
1) Nova(OpenStack Compute):
它是OpenStack里最核心的项目, 主要作用是控制虚拟机的创建以及改变他的容量和配置;它还可以做虚拟机的销毁,即虚拟机的整个生命周期都是由Nova来控制的。Nova的部署和运行一般有两种情况:一种是作为Controller节点去运行,它的核心部分主要有Scheduler(决定将要启动的虚拟机调度到哪个物理节点上),Conductor(对所有的计算节点进行统一管理),NovaCell(级联),用这些来控制其它一些运算节点。另外一种是作为Compute节点运行,它的核心部分是Nova Compute,用来控制运行实际的虚拟机。
2) Cinder:
它主要用途是用来提供块存储服务。它最核心的两个部分是Scheduler和Cinder Volume。此处Scheduler的功能和Nova的Scheduler功能接近,用来决定通过哪个Cinder Volume进行读取操作。而Cinder Volume是实际控制存储设备的节点。
3) Neutron
它是当下流行的SDN(软件定义网络)在OpenStack里的一个实现。Neutron有一个很大特点就是它提供了Plugin组件/模块(用户可以自定义)。
4) Swift
相对独立的一个组件,它和其他组件的交互关系比较少。它提供对象存储服务,类似于亚马逊S3或者国内七牛这样一个存储服务。
5) Glance
它是OpenStack里面使用Swift最多的组件,它主要是用Swift来存储虚拟机的镜像和快照等。
6) Keystone
它主要是为各个组件提供用户的认证,建权等服务。
7) Horizon
它是一个图形界面。
8) 其它组件
Heat: 用来做各个服务的编排。
Sahara: 使Hadoop能够在OpenStack上运行。
……
第二章 OpenStack架构分析
1.OpenStack组件间的逻辑关系
以E版本为例,含七大基本组件:
Dashboard(即Horizon);Identity(即keystone)compute(即Nova);Image(即Glance);Object Storage(即Swift);Network(即Neutron);Block Storage(即Clinder);
*注:其中Network(即Neutron)和Block Storage(即Clinder)分别是从Compute Network和Compute Vloume发展出来的。但Network组件并没有直接去替换Compute Network,它是相对独立的(也是当下流行的SDN)的一个项目,它为Compute提供网络连接,提供网络资源管理这些服务。而Block Storage则替换了Compute Vloume,它为Compute提供块存储服务。
- OpenStack的API
1)OpenStack各组件间通过相互调用API实现通信。OpenStack的API是基于HTTP协议的RESTful Web API。(REST:表现状态传输VS另外一种Web服务接口协议:SOAP)
2)REST架构里对资源的操作包括获取,创建,修改和删除。正好对应HTTP里提供的GET,POST,PUT,DELETE方法。所以用HTTP来实现REST是比较方便的。
3)RESTful Web API主要有以下三个要点:
①资源地址(即资源的URI):如以http开头的地址
②传输资源的表现形式(即Web服务接受与返回的互联网媒体类型):JSON, XML等。
③对资源的操作(即Web服务在该资源上所支持的一系列请求方法):如GET,POST,PUT或DELETE
4)调用及调试API的方式
①curl命令:linux下发送http请求并接受响应的命令行工具
②OpenStack命令行客户端:python写的命令行客户端
③FireFox或Chrome浏览器的REST客户端:图形界面
④OpenStack的SDK: 不要手写代码发送HTTP请求调用REST接口,省去一些诸如Token等数据的管理工作,能够很方便地基于OpenStack做开发。
3.OpenStack组件间的通信关系
OpenStack组件间的通信关系分为四类:
1)基于HTTP协议的通信
① 出现在各个组件API之间的调用。最常见的是通过Horizon(或说命令行接口)对各组件进行操作的时候产生的通信;另外就是各组件通过Keystone对用户身份进行校验的时候产生的通信;还有就是Nova Compute在获取镜像的时候对Glance API的调用及Swift数据的读写也是通过HTTP协议的RESTful Web API来进行的。
2)基于(消息队列)AMQP协议的通信
① 主要是每个项目内部各个组件之间的通信。例如Nova的Nova Compute和Scheduler之间及Scheduler和Cinder Volume之间。(注意:由于Cinder是从Nova Volume演化出来的,所以Cinder和Nova之间也有通过AMQP协议通信的关系)
② AMQP协议进行通信也属于面向服务的架构,所以虽然大部分通过AMQP协议进行通信的组件属于同一个项目,但是并不要求它们安装部署在同一个节点上。如NovaCompute 和Nova Conductor反而反而通常要求它们不能部署在同一个节点上;而实际上Nova Conductor和Nova Scheduler也可以放到不同的节点上,这有利于系统的横向扩展,我们可对其中的各个组件分别按照它们的负载情况进行横向扩展。(用不同数量的节点去承载它们这些服务)
③ OpenStack并没有规定AMQP协议的实现,我们经常使用的是private MQ,实际用户可根据自身情况选择其它的消息中间件。
3)基于数据库连接的通信(主要是SQL)
① 出现在各个组件和数据库之间,这些通信大多也属于项目内部,和前面基AMQP的类似。它也不要求数据库和项目其它组件安装在同一个节点上,它也可以分开安装,甚至我们还可专门部署这个数据库服务器,把这些数据库服务放在上面,然后之间是通过基于SQL的这些连接来进行通信。
② OpenStack同样没有规定必须使用哪种数据库,我们通常使用的是MySQL,实际用户可根据自身情况选择其它的数据库。
4)基于第三方API(或称为NativeAPI)进行通信
① 出现在各OpenStack各组件和第三方的软件或硬件之间。如Cinder和存储后端设备之间的通信;又如Neutron的agent(或者说插件)和网络设备之间的通信。这些通信都需要调用第三方设备或第三方软件的API(Native API)。
- OpenStack中几种不同的存储
1)OpenStack的三种存储服务:Glance,Swift,Cinder
① Glance(镜像存储): 一个镜像管理服务,本身不具备存储功能,它的后端可以接其它的存储系统,可以是存储设备,本地存储,Swift,也可以是亚马逊S3等。
附:三种存储概念:
文件系统:(有POSIX接口)如Glance里的GFS,Hadoop里的HDFS
块存储:如EMC设备,华为的SAN设备,NetApp;“散存储”一般都提供块存储。
对应Cinder,其实Cinder本身也并不是提供数据存储的,它也需要接一个存储的后端,即EMC的散设备等,及最新流行的开源的分布式存储Ceph(可提供块存储服务)。
对象存储:对应Swift,典型代表如亚马逊的AWS S3。它是通过RESTful Web API去访问的,它的优势在于可以很方便地去访问存储的数据。
② Cinder
给OpenStack提供块存储的接口。它有一个很重要的功能叫卷管理功能。虚拟机并不直接去使用存储设备(或使用后端的存储系统),它使用的是虚拟机上的块设备,可称为卷(Volume),实际上Cinder就是去创建和管理这些Volume,并且把它挂载到虚拟机上。
③ Swift
提供对象存储服务。如果使用文件系统,当数据量特别大的时候,存储性能会急剧下降。而对象存储抛弃了目录树的结构,用一种扁平化的结构去管理数据。实际上Swift只有三层结构:Account(关联账户), Container(容器,对Object分类), Object (最终的数据/即文件)。
- OpenStack工作流程
OpenStack工作流程 相当复杂(有五十多个步骤)。虚拟机创建的四个阶段 :
scheduling , networking ,block_device_mapping, spawing
- OpenStack的部署架构
1)OpenStack各个项目,组件按一定方式安装到实际的服务器节点上,实际的存储设备上,然后通过网络把它们连接起来,这就是OpenStack的部署架构。
2)OpenStack部署分为单节点部署和多节点部署(集群部署)
3)OpenStack的部署架构不是一层不变的,而是根据实际需求设计不同的实施方案。
4)OpenStack的简单部署架构:
附:三种网络:
①(绿色)管理网络:OpenStack的管理节点(或管理服务)对其它的节点进行管理的网络。它们之间有如不同组件之间的API调用,虚拟机之间的迁移等
②(蓝色)存储网络:是计算节点,访问存储服务的网络。包括向存储设备里读写数据的流量基本上都需要从存储网络走。
③(黄色)服务网络:是由OpenStack去管理的这些虚拟机对外提供服务的网络。
四种节点:
①控制节点:是OpenStack的管理节点,先前介绍的OpenStack大部分服务都是运行在控制节点上。如keystone认证服务,Glance管理服务等。
注:特别的,Nova和Neutron这两个组件必须采用分布式部署。
对于Nova,因为Nova-Compute是控制和管理虚拟机的,所以它必须部署在计算节点上,而Nova其它几个服务则应该部署在控制节点上。特别要强调的是,Nova-Compute和Nova-Conductor一定不能部署在同一个节点上,因为二者分开的目的就是为了解耦。
对于Neutron,Neutron的插件或Agent需要部署在网络节点和计算节点上,而其它部分,如Neutron Server可以部署在控制节点上。
②计算节点:指实际运行虚拟机的节点,就是OpenStack的管理的那些虚拟机实际上最后是在计算节点上运行的。
③存储节点:可以是提供对象存储的Swift的节点,或者是Swift集群的Proxy节点,也可以是一个其它服务的存储后端。
④ 网络节点:主要是实现网关和路由的功能。
5)OpenStack的复杂部署架构:要点如下:
①规模较大的情况下,把各种管理服务部署到不同的服务器上。
② 把OpenStack的同一个服务部署到不同的节点上,形成双机热备或者多机热备的高可用集群。(或者可用负载均衡集群的方式去实现高可用)
③ 在复杂的数据中心环境中,考虑如何与第三方服务进行对接和集成。(如LDAP服务,DNS服务等)
第三章 OpenStack各组件解析(基础)
1.Nova组件解析
- Nova的架构
除了先前介绍的七大组件外,在此补充两个组件:nova-conslole,nova-consoleauth,它们的作用是通过支持VNC 或SPICE(独立计算环境简单协议)客户端来访问虚拟机界面。
SPICE协议支持USB设备和多屏显示等功能,使用它需修改nova.conf文件。 - Nova对虚拟机的调度机制
①placement (放置): 把虚拟机放在哪个物理机上启动
②migration(迁移):从哪个物理机迁移到哪个物理机
*实际上Nova中的调度器(Scheduler)只完成了placement (放置)的工作,migration(迁移)实际上是由其它组件协同完成的。
**配置Nova.conf文件:Nova-Scheduler基于Filters对虚拟机进行调度的机制分为两步,第一步是通过Filters筛选宿主机(含有Compute)这,第二步是对虚拟机进行排序,Nova中该排序叫称重(weighting),最终完成调度算法,决定了应用哪台宿主机上启动哪台虚拟机。
注:在nova.conf中可以通过ram_allocation_ratio参数设置内存的超配比例,其前提是使用RamFilter。
- Swift组件解析
1)Swift历史相对较长,比较独立,它和其它组件的耦合度比较低,有自己完整的存储体系,不依赖第三方软件或设备(如不依赖keystone做用户认证和建权)。
★对象存储:采用RESTful接口,支持直接从互联网访问存储系统进行数据的读写。
2)Swift接口:它和其它组件接口类似,也是RESTful的Web API,总共有四个部分组成:第一个是HTTP操作(GET,POST,PUT或DELETE);第二个是认证信息(主要是用户的身份信息);第三个是指示资源地址的URL(包含域名或地址及Account, Container,Object);第四个是(可选项)数据和元数据。
3)Swift其它要点:
Swift的架构:整体架构是RESTful API,它是通过一个叫Proxy Server来实现的。(可对它进行扩展,做Load Balancer,用它去接收上面的HTTP请求,然后把请求转发到实际的StorageServer上)
搭建Swift时的注意事项:
a.(小规模集群)采用全对等架构,即它的每个(Server)节点都一样。
b.用Load Balancer把服务器组成一个集群。
c. (小规模集群)每个服务器是一个zone。
d. 小规模Swift集群,服务器数量最少是5个。(或说最小集群是五个服务器)
e. 不要用虚拟机和RAID。(不要把Swift放到虚拟机里去做实现。)
附:Swif 2.0的新功能:
a. 存储策略(核心功能):让用户能够选择数据的存储策略。 - Cinder组件解析
1)传统数据中心的存储设备:SAN或盘阵,指一类设备,通过网络连接给服务器提供存储空间。SAN设备和服务器之间的网络连接主要有两种形式,第一种叫Fibre Channel(FC),用专用光线连接网络; 另外一种叫iSCSI,基于以太网协议/IP协议。
注:Cinder存储服务可以为虚拟机提供云硬盘。
2)Cinder API
①不同于Swift的RESTful API,它提供一些操作和管理功能
②实际流量是不通过Cinder的这些组件的,而是直接通过存储设备和服务器之间的网络连接走的,该连接可以是FC(光纤通道)或iSCIS(基于IP的数据传输通道)传输数据到服务器。
- CinderVolume
① 通过Driver适配其它设备。(屏蔽底层硬件异构性)
- Neutron组件解析
1)传统数据中心的网络:它分为几个层(Tier),首先是服务器接入的第一级交换机叫接入交换机(往往在机架的顶部又称为(TOR)架顶交换机);往上会接入一个汇聚层的交换机叫汇聚交换机(往往放在一排机架的顶头位置);再往上会接入核心交换机,它把汇聚交换机连接起来,往往不只一个。
2)根据ISO网络模型,网络分为七个层(此处是协议栈里的层,layer),OpenStack和Neutron主要关注其中的二三层,分别是数据链层和网络层。
3)在OpenStack和Neutron出现之前的虚拟化网络:用Qauntum去虚拟化网络,它使用linux系统里的一个软件叫虚拟网桥,它实现的网桥不存在物理信号问题,可简单为它是一个二层的交换机(跑在服务器虚拟机内部,把虚拟机都连接到此交换机上),可用它来搭建一个虚拟化环境,但是如果放到云环境中去,涉及租户间流量隔离问题,此网桥就不满足需求了,因为它是连通的(把所有虚拟机连接在同一个虚拟网络里),跟普通交换机无太大区别。
4)Nova中的一个管理网络模块Nova Network在前面网桥的基础上增加了一个模块,它可以有两种工作模式:①Flat DHCP工作模式②基于VLAN的隔离 ,它勉强满足了云的要求,所以可在一个简单的,对网络要求不高的云计算环境中使用NovaNetwork实现一个比较简单的网络。
5)Neutron功能
①VLAN隔离
② 软件定义网络(SDN)
如L2-in-L3隧道,GRE 隧道等,还支持OpenFlow(SDN协议)
③ 第三方API扩展
④ 第三方Plugin扩展
注:可见通过Neutron,租户可以定制rich topology的虚拟网络;可以通过各种agent和plugin实现具体功能并和第三方设备,软件对接。
eg.构建一个基于三层架构的Web服务:
Web页面服务器;应用服务器;数据库服务器 - Horizon组件解析
1)提供可视化GUI。OpenStack原生的Horizon满足不了需求,需在其上做二次开发。
2)Horizon内部架构
可参照python的一个Web应用框架django。Horizon的内部设计分为三个层次:
① Dashboard ② PanelGroup③ panel
Horizon三级代码组织形式:
① horizon: 表格,标签页,表单,工作流,base.py文件(实现动态加载panel)
② openstack_dashboard: dashboard子文件(包含各个面板的实现代码,即业务逻辑都在里面,它会去加载或调用horizon文件夹里的那些组件)
6.Glance组件解析
1)Glance架构:上层Glance API Server(提供RESTful API) ,所有访问请求会通过它;
Registry Server(提供镜像注册和检索服务);Store Adapter【和Cinder类似,可使用不同存储后端,如Filesystem Store(可理解为Glance本地的一个文件存储), 还有Swfit Store,S3Store, HTTP Store ,这些都是通过HTTP协议来访问的。所以Glance可以看成是一个典型的对象存储应用。】
2) 和Swift一样,可以把Glance的API Server做横向扩展,然后给它做一个负载均衡的集群,下面再转到实际的存储后端去。但不同的情况是,Glance存储和管理的镜像,有的镜像用户访问量特别巨大,所以虽然对Glance的API Server做了负载均衡,实际的后端访问负载还是会落到一个点上,给它造成很大压力。为解决这个问题Glance提供 了一种缓存机制,使每个通过Glance到达服务器的Server端的镜像都会缓存到API Server上,如果我们有多个API Server,随着用户访问请求的增多,被经常访问的同一个镜像会在每一个API Server上都有一份,后续再有访问请求的时候,它就会直接调用API Server上的这个镜像文件,而不会再去访问到存储后端上来。而且这个机制对终端用户来说是透明的,即终端用户并不清楚Glance服务获取的这个镜像到底存在哪里。(注:如果我们只有一个节点提供API服务,这种缓存机制就没有意义了。)
3) 缓存管理注意事项:
a. 控制cache总量的大小(它有cache总量大小的控制):周期性的运行一个命令来处理cache总量的大小限制。
b. 清理状态异常的cache文件。
c. 预热某些热门镜像到新增的API节点中:通过命令预先把一些比较热门的镜像先加载到新增的API节点中。
d. 手动删除缓存镜像来释放空间
- KeyStone组件解析
1)KeyStone的作用:
a.权限管理:用户,租户,角色(Role,keystone访问控制机制的核心)。
★注:用户和租户之间是多对多的关系。可通过Role进行权限管理以及将同一个用户分配到不同的tenant。
b.服务目录:服务,端点
2)keystone只是云安全的一部分,二者不可等同。公有云上常见的安全防护手段:
a.安全访问:允许使用安全的Https访问
b.内置防火墙功能:通过配置内置防火墙让云上的环境或应用更安全
c.加密数据存储
d.帮助租户监测安全状况:主动监测租户的安全状况并给出提示
问题集:
1)比较Swift和Cinder两种存储之间的异同
异:Swift比较独立,它和其它组件的耦合度比较低,有自己完整的存储体系,不依赖第三方软件或设备(如不依赖keystone做用户认证和建权),采用RESTful接口,支持直接从互联网访问存储系统进行数据的读写。
而Cinder本身并不是提供数据存储的,它需要接一个存储的后端,即EMC的散设备等,它有一个很重要的功能叫卷管理功能。虚拟机并不直接去使用存储设备(或使用后端的存储系统),它使用的是虚拟机上的块设备,可称为卷(Volume),实际上Cinder就是去创建和管理这些Volume,并且把它挂载到虚拟机上。
同:二者整体架构都是RESTful API,但Swift是通过一个叫ProxyServer来实现的。Cinder API不同于Swift的RESTful API,它提供一些操作和管理功能。
2)比较Neutron和Nova-Network的异同
Nova Network只是早先Nova中的一个管理网络模块,它在网桥的基础上增加了一个模块,它可以有两种工作模式:①Flat DHCP工作模式②基于VLAN的隔离,它勉强满足了云的要求,所以可在一个简单的,对网络要求不高的云计算环境中使用Nova Network实现一个比较简单的网络。Neutron做为一个Openstack项目出现之后,租户可以定制rich topology的虚拟网络;可以通过各种agent和plugin实现具体功能并和第三方设备,软件对接。
第四章 OpenStack各组件解析(进阶)
- Ceilometer组件解析
1) Ceilometer又称为Openstack Telemetry: 远程测量收集数据
2) Ceilometer主要目的:为计费提供数据支持
3) 计费用和监控用计量数据的区别:
a. 侧重点 b.不可抵赖性
4) Ceilometer要点:
a. 原始数据的来源:
①通过AMQP消息中间件收集各个组件发出的消息
②通过Ceilometer的agent(可扩展)调用Openstack各个组件的API获得数据
注:支持第三方的agent,plugin或driver来扩展Openstack是常用的手段。
③在每个计算节点上运行Ceilometer的polling agent获得虚拟机的信息。
b. 数据的存储:
① 和Nova及Cinder等使用MYSQL作为默认的后端存储不一样,Ceilometer默认的后端数据库是MongoDB(是一个key-value数据库),当然它也可以用Hbase,MYSQL等数据库。
c. (如何提供给)第三方系统
① 通过Ceilometer 的API获得计量数据,设置报警条件和预值。
- Heat组件解析
Heat又称为Ochestration:把一个IT系统的各个模块和资源组织,调度起来。它和AWS里的CloudFormation比较类似,它按照用户写的模板或脚本(Template)把Openstack的各种资源(如虚拟机或卷)实例化并组织起来形成一个完整的应用。按照Tempalte生成的东西叫stack(栈)。Tempalte写了创建一个stack需要用到哪些资源,及这些资源的相互关系。Heat的主要任务就是负责stack的创建,更新和销毁。(创建命令:heat stack-create … -template-file …)
附:完整的Template包括,version ,description , resources,parameters, outputs
*更复杂的结构:创建一个wordpress网站;创建一个三层架构的网站;可以拆分为几个Template分别实现不同功能。
注:Heat可以和Ceilometer配合使用来实现auto scaling,另外Heat可兼容CloudFormation模板。 - Trove组件解析
1) Trove的功能:根据用户的请求创建一个包含数据库的虚拟机
2) 数据库的建立:可以是创建完虚拟机后由trove去安装;也可事先做好trove的镜像(里面已经安装好数据库了)。后者效率更高,Trove支持关系型数据库MySQL, NoSQL数据库,MongoDB, Cassandra等
3) Trove的功能实现依赖四个组件:
a. Trove API:提供RESTful API
b. Taskmanager: 完成管理命令的执行(创建/销毁/管理示例,操作数据库),它的主要工作方式主要是去监听RabbitMQ这个中间件上的MQP等调用请求并实现。
c. Trove-Conductor: 和Nova-Conductor比较类似,负责和数据库交互。
d. Guest agent: 类似于Neutron agent ,对应数据库
4) Trove目前面临的挑战:不支持自动配置数据库的HA - Sahara组件解析(Sahara原名叫Savanna)
1) Sahara作用:
a. 在Openstack上快速创建Hadoop集群
b. 利用Iaas上空闲的计算能力做大数据的离线处理
2) Sahara的架构(原理)要点:
a. Horison:里包含Sahara的dashboard
b. Plugin:用来支持Hadoop各种发行版
c. Swift: 存储持久化数据(不该再放到Hadoop的HDFS里,因为它的生命周期和虚拟化的Hadoop集群的生命周期一样)
d. Sahara API:不同于其它组件,它的API分为两个服务入口,一个叫Service.api,另外一个叫Service.edp.api。
3) Sahara的使用模式
① Iaas模式/管理模式:
a. 节点(此处不同于先前讲的计算节点等),它是运行Hadoop集群的机器。
b. 节点组:按照节点类型划分,通过节点组模板定义节点组
c. 集群:完整的Hadoop集群,通过集群模板定义集群
d. Job:(有工作流的性质),它可能是若干个Hadoop job组织起来形成Sahara
② Pass,DAaas模式/用户模式/EDP模式
a. 前提:至少创建一个Hadoop集群
b. 准备工作:上传要处理的数据;编写job并上传;给Sahara一个三元组(即调用EDP API时的参数,分别是使用哪个集群,数据元素在哪,要运行的job是什么) - Ironic组件解析
1) 用Ironic(由单词iron演化而来)实现对物理机械的管理或者说用物理机器实现云服务。
2) 它和Openstack在部署架构上管理虚拟机和物理机器的区别:
a. 在控制节点上多了一个Ironic API组件
b. 在Compute Node上除了Nova-Compute, Neutron agent以外,还有一个Ironic Conductor 。(注:此处的节点和先前的节点不一样,它和Cinder Volume类似,并不是实际提供存储资源的节点)
3) 它和Openstack在计算资源调度流程上或启动一台机器的工作流程上的区别:
物理机器节点上的Nova Compute调用Ironic API,实际启动的物理机器节点或说实际提供计算资源的物理机器节点是由Ironic Conductor通过PXE ,IPMI远程管理的。
4) Ironic实际上是由Nova的一个部分演化而来(以前Nova中专门管理物理机器的Novadriver)(同样的,先前说的Cinder是Nova Volume演化而来)
问题集:
Heat中的模板和Sahara中的模板的异同:
异:
Heat和AWS里的CloudFormation比较类似,它按照用户写的模板或脚本(Template)把Openstack的各种资源(如虚拟机或卷)实例化并组织起来形成一个完整的应用。按照Tempalte生成的东西叫stack(栈), Tempalte写了创建一个stack需要用到哪些资源,及这些资源的相互关系。
Sahara 的Iaas模式/管理模式中,通过节点组模板定义节点组,通过集群模板定义集群。
同:都包含了配置信息,用来对组件进行配置,通常包括version ,description , resources,parameters, outputs等信息。
第五章 OpenStack实际操作
- OpenStack部署环境准备
1) 创建一个路由器(Router);创建一个交换机(用Neutron 中的Network,它相当于交换机,需配置子网(广播域)),最后把两者连接起来。为了让网络里的连接其它设备能够正常访问公网(Internet)需用Floating IP(也是Netron中的一个概念,它实际上就是云计算环境可用的公网IP),它有两种用法,一是将其绑定到路由器上,二是将其绑定到云主机上(让这台云主机和外网相连通。它显示有2个IP,但实际只有一个IP,它是通过Neutron的一种机制把两个IP映射起来。当然我们也可通过Neutron实现修改虚拟机真正的IP地址和MAC地址)。
2) 创建云主机(Instance) - KeyStone的安装部署
a. 登录Controller节点安装KeyStone(apt-get),并修改KeyStone配置文件【修改etc目录下keystone.conf文件中的三个部分:和数据库连接相关的设置;修改或设置写log的位置(log_dir=/var/log/keystone);设置keystone服务和其它服务共享的一个token】
b. 创建用户(需要带两个参量:token和url),创建租户,创建角色;创建服务
c. (Controller节点上)把常用参数(username,password,tenant-name,auth-url等)作为环境变量导出
- Glance的安装部署
a. 安装Glance(安装Glance服务及Glance的python客户端),并修改Glance配置文件【主要修改etc目录下glance-api.conf文件和glance-registry.conf。首先进行glance-api.conf和glance-registry.conf文件中和数据库连接相关的配置,且检查/var/lib/glance目录,如果存在sqlite数据库文件(glance.sqlite)需将其删除,防止误读;而后修改glance-registry.conf】
b. 创建Glance数据库(MySQL)并同步(glance-manage db_sync)
c. 用keystone命令给Glance创建用户并添加该用户到先前的租户里
d. 修改glance-api.conf文件和glance-registry.conf文件中keystone相关的设置,
并在keystone中注册Glance以及它的端点。
e. 上传镜像
- Nova的安装部署
1) 在Controller节点进行安装,此处不能和先前一样写个Nova,要写清楚具体安装哪些组件(如Scheduller,Conductor,Nova-api,Nova的python客户端等)。
2) 在Compute节点安装Nova-compute-kvm(此处kvm实际上是由qemu模拟的一个虚拟机),没有Neutron则需安装nova-network,nova-api-matadata .
3) 同先前组件一样,先修改nova.conf相关配置,同样要去检查/var/lib/glance目录,如果存在sqlite数据库文件将其删除,创建数据库(MySQL)并同步(把数据项或信息填充到现在的数据库,glance-manage db sync,不同于先前的命令,此处无下划线)
4) 继续修改nova.conf中keystone相关的设置,在keystone里创建用户并注册服务和端点。
5) 在Compute节点上配置nova.network.api.API
6) 在控制节点上创建网络
7) 启动虚拟机(用nova boot命令)
- OpenStack支撑服务的安装配置
支撑服务:NTP(时间同步服务),mysql数据库服务,RabbitMQ(消息中间件服务)。配置host文件,实现通过主机名访问虚拟机。
1)NTP服务:它有两个作用,一是将本机时间和网络上的一台时间同步器去同步;另外一个作用是将本机作为一个时间同步器提供给其它节点去使用。
在Opentstack部署环境中,建议让Controller结点去和互联网上的一个时间同步器同步,让其它结点和这个Controller结点同步,这样一来,其它结点和这个Controller结点的时间同步就在一个局域网内,时间同步性更高。安装完NTP后为实现把Controller结点做为时间同步源,需在其它结点上编辑它的配置文件(etc文件夹下的ntp.conf,加上servercontroller)。
2)在Contorller结点上安装mysql服务(需安装python-mysqldb客户端和mysql-server服务进程),并修改配置文件(etc文件夹中mysql下的my.cnf,修改bind-address(绑定访问mysql服务器所需要的IP地址);修改或添加数据库引擎配置(mysql默认或推荐的数据库引擎是InnoDB)。
注:【实际运用中可把数据库服务安装到单独的一个机器上(可配置全ssd),公司里常用全ssd服务器来支撑数据库服务,提高其性能】
其它结点上不用再安装数据库服务,只需安装一个python客户端即可,Openstack就可以访问Contorller结点上的那个数据库了。
附:安装mysql时会创建一个匿名用户和一些Database,为正常使用起见可将其清除(可手动清除,也可用mysql提供的一个命令:mysql_secure_installtion)。
3)在Contorller结点上安装RabbitMQ服务。消息中间件还可用别的如Qpid,ZeroMQ
- 通过图形界面使用OpenStack
1)除了安装horizion(dashboard),还需安装apache等其它几个服务,这些都是为了显示动态网页所需要的。另外还要删除一个包(openstack-dashboard-ubantu-theme),因为它影响到horizon图形界面的显示。然后修改配置文件(etc中openstack-dashboard下的一个.py结尾的文件local_settings.py),修改BACKEND和LOCATION(它们是对显示的web界面缓存的设置),让其参数与memcached中一致。
- 通过命令行使用OpenStack
1)先前多数是在Controller节点上用过命令行访问本地的服务,此处介绍远程访问的方法。为了模拟远程访问的环境,可在使用的公有云里创建一个ubuntu的云主机作为客户端(还是接入先前的子网),并修改配置文件(hosts)。然后安装相应客户端(如python-novaclient)。
注:可以创建脚本,把导出环境变量的命令都放在里面,方便以后使用(里面的命令需根据自己的环境进行修改)。之后不直接执行脚本,而是用source命令执行脚本,这样才能把脚本里设置的环境变量带到当前用户的操作环境中。(可用echo命令查看环境变量设置是否成功)
第六章 OpenStack扩展话题
- OpenStack自动化部署
1)分为三个层次:
A. 单节点自动安装:常用于准备一个开发环境,常用工具是DevStack
B. 集群化安装:最常用工具是puppet
C. 多个集群安装部署:典型代表工具是Mirantis公司推出的fuel
2)DevStack的安装演示(单节点自动安装的实际操作过程)
a. 创建云主机。更新一下安装源(apt-get update),安装git,通过git clone命令下载DevStack的源代码。然后用devstack文件夹里提供的一个工具创建一个用来安装和运行DevStack的用户(./create-stack-user.sh)。将下载的源码在当前用户的home文件夹下拷贝一份(可从本地拷贝或再次从源端下载),找到devstack文件夹中samples下的local.conf文件,拷贝一份到上一级目录并修改其中的相关配置(把HOST_IP修改成当前当前机器的内网IP)。
b. 运行./stack.sh脚本,进入自动安装过程。
- Hadoop云化时存在的问题
1)Hadoop是用来做大数据处理的一个工具,它也有自己庞大的生态圈,其中最重要的两个软件是HDFS(分布式存储系统),MapReduce(任务调度框架)
注:HDFS把文件分成块,把块做三个副本存储到不同节点上,形成一个比较高可靠性的文件系统;MapReduce把我们提交的数据处理任务(job)拆分成不同的task分发到不同的节点上,以实现并行处理。MapReduce最大的特点是能够把任务调度到离数据近的节点上,尽量减少数据在网络间的传输,使我们可用通用廉价的X86服务器和网络设备来构筑一个数据并行处理系统。
★Openstack虚拟机调度和Hadoop任务调度实际上是两个不同层次的资源调度。要把Hadoop做云化就需要解决两个不同层次上的资源和任务调度问题。Hadoop最重要的两个部分HDFS和MapReduce云化时也会出现相应问题,为解决相关问题Hadoop提供了一个由VMware主导的开源项目HVE(Hadoop Virtual Extensions)。
- 基于OpenStack实现Hadoop云化
1)Sahara分别从部署管理和提供数据处理服务两个层次上对Hadoop云化做了一些工作。
2)HDFS和Swift集成:在Hadoop集群里仍用本地根硬盘来构筑HDFS,但是把数据源和job放在Swift里。此外,由VMware主导的开源项目BDE(Big Data Extensions),它和Openstack的Sahara很类似,但是在各个方面都做得比Sahara好得多,且它和HVE 集成做得很好。
- Ceph简介
1)Ceph现在经常被用来做为RBD设备提供块存储服务。
2)Ceph层次结构:
底层RADOS,中间层LIBRADOS ,顶层RADOS GW, RBD, CEPH FS
① RADOS:可靠的,自动化的,分布式的对象存储。底层是一个完整的存储系统,它的核心是OSD(Object Storage Daemon),Daemon是一个服务软件(进程),它和Cinder里定义的OSD(Object Storage Device)之间有很强的对应关系,可认为是其简略版本。
注:不同于Swift存储 的对象(文件),Ceph的对象实际上是把一个文件拆分成若干个Object,分别放到底层的存储设备上。
★RADOS逻辑结构:OSDs , Monitors , Clients
注:此处的客户端和Swift客户端有本质区别,Swift客户端只是用Pyhon写的一个供用户使用能够调用RESTful接口的客户端程序而已,没有它我们直接调用RESTful接口也可以读写Swift,但是在RADOS里如果没有Clients,整个数据读写就难以实现,它是存储系统的一部分。
★Ceph系统中的寻址流程(文件存储到底层OSD上)
它首先把文件拆分成若干个Objects,然后把Objects放到PG组里面,每个组再通过CRUSH算法给它映射到不同的OSD上。此存储过程特点是它每一步都是通过计算得到的,它中间没有查表,这使得Ceph拥有较好的扩展性。
②LIBRADOS: 提供一组直接访问RADOS的API
③ RADOSGW, RBD, CEPH FS:RADOS GateWay把底层对象存储系统往外再次封装,提供兼容Swift和亚马逊S3对象存储接口,这个接口也是HTTP的。RBD经常作为Cinder的后端为虚拟机提供卷。CEPH FS是在Ceph基础上封装了一个POSIX接口,形成文件系统。
- Ceph在OpenStack中的应用
1)Ceph在OpenStack中受欢迎的原因:
①有了Ceph,可基于X86搭建分布式块存储系统
附:块存储有强一致性和高性能的要求,这对于Swift和HDFS都是没有或比较弱的。
★Cinder支持Ceph提供的RBD设备,二者结合可基于X86普通服务器更加廉价方便地搭建一个块存储系统提供(卷)给虚拟机去使用。
②提供Swift兼容的对象接口
★Ceph和Swift仍不可互为替代,二者比较如下:
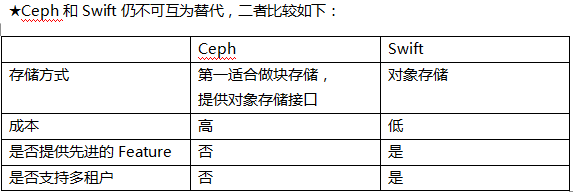
案例一:目前OpenStack规模小,节点数量少,此时使用Swift节点浪费存储,可选用Ceph
案例二:提供云盘服务(面对大量用户,强调用户体验,用户可选存储策略(Storage Policy)),此时选用Swift更好,它更好地支持规模化部署,有先进的Feature,成本比Ceph更低。
④ 现在OpenStack所有存储都(开始)支持Ceph作为后端
- OpenStack与Docker
附:HyperVisor:在一个宿主机上搭建环境,可在环境里创建虚拟机,再在虚拟机里装客户操作系统(Guest OS),然后在其上面装中间件,之后再装应用等。
Container技术:另外一种虚拟化技术,无需再装Guest OS,而直接基于宿主机操作系统来操作,可在其上做运行环境隔离,资源划分等,并形成容器,让应用在容器中运行。容器之间底层是共享一个操作系统的,甚至可以共享一些公用的库。和传统的HyperVisor相比,它的优势在于省去了Guest OS的开销;劣势在于只能使用和宿主机相同的操作系统。
1)Docker:是基于容器的一个引擎,让开发者可以打包应用,并将其依赖包打到可移植的容器里,而容器可发布到任何linux机器上。OpenStack里将Docker也看成是一种HyperVisor
2)OpenStack+Docker:(结合点)
①使用Swift做Docker镜像的存储后端
②Nova里有针对Docker的Driver或插件,可用Nova调度和管理Docker容器。
③使用Heat来实现Docker的Ochestration
④基于Neutron设计与实现适用于Docker的SDN方案
⑤使用Glance来管理Docker镜像
……