本文记录RabbitMQ集群搭建过程中遇到的问题
环境
vmware12 虚拟机,CentOS7
本文以两台CentOS 为例,IP 192.168.32.128,192.168.32.129
磁盘节点和内存节点
集群中,每一个RabbitMQ实例都是一个节点,而节点分为磁盘节点和内存节点
内存节点:将Rabbit中的元数据(Queue, Exchange, binding, vhost等)存储在内存中,持久化的 Message 依旧保存在磁盘中,内存节点的性能只能体现在资源管理上,消息的发送和接收和磁盘节点没有区别
磁盘节点:元数据存储在磁盘中,一个Rabbit集群要求至少有一个磁盘节点,因为内存节点中不存储元数据,所以每次内存节点启动,都会从其他节点中同步元数据
另外如果唯一磁盘的磁盘节点崩溃了,不能进行如下操作:
- 不能创建队列
- 不能创建交换器
- 不能创建绑定
- 不能添加用户
- 不能更改权限
- 不能添加和删除集群几点
RabbitMQ集群的几种类型
单一模式:仅有一个rabbit实例
普通模式:默认集群模式,每个节点各自维护自己的数据,两个节点仅存有相同的元数据。例如RabbitA 和 RabbitB,A中存在 QueueA,消费者可以从RabbitB实例中,读取QueueA的消息,这时RabbitB会从A中读取消息,返回给消费者。但是如果RabbitA 宕机,这时就无法获取QueueA的数据了
镜像模式:Rabbit 会将数据同步到其他节点中,这固然提高了可用性,但是随之而来的问题是,系统的性能会降低。节点之间消息的传递会占用带宽,而每个节点存储的数据量会变大
普通模式
我们先来搭建普通模式的集群,在RabbitMQ中,每个节点的名必须是唯一的,默认以 rabbit@hostname为节点name
而每台虚拟机中默认的host是localhost,这就导致了每个节点的name都是 rabbit@localhost
1. 修改hosts
修改两台主机的hosts文件,以下是129的配置,我们把128定义为F,129定义为G
cat /etc/hosts
127.0.0.1 G
::1 G
192.168.32.129 G
192.168.32.128 F
保证F和G可以ping通

2. 安装RabbitMQ
可以参考 https://www.linuxprobe.com/install-rabbitmq-on-centos-7.html
当时安装完一直发现无法访问 Rabbit的web控制台,除了开启插件,和添加一个用户之外,还需要放开防火墙的端口
firewall-cmd --add-port=4369/tcp --permanent
firewall-cmd --add-port=25672/tcp --permanent
firewall-cmd --add-port=5671-5672/tcp --permanent
firewall-cmd --add-port=15672/tcp --permanent
firewall-cmd --add-port=61613-61614/tcp --permanent
firewall-cmd --add-port=1883/tcp --permanent
firewall-cmd --add-port=8883/tcp --permanent
firewall-cmd --reload # 重载配置
3. 同步Erlang cookie
Erlang VM将尝试在RabbitMQ服务器启动时创建一个随机生成的值(Erlang Cookie)。集群环境中,所有节点的Erlang Cookie必须一致。
.erlang.cookie 通常在 $HOME下或者/var/lib/rabbitmq下
# 找到其中一台主机的 .erlang.cookie
# 修改权限
chmod 777 /var/lib/rabbitmq/.erlang.cookie
# 拷贝到另一台主机
scp /var/lib/rabbitmq/.erlang.cookie G:/var/lib/rabbitmq/
# 再把权限修改回来
chmod 400 /var/lib/rabbitmq/.erlang.cookie
4. 检查节点名
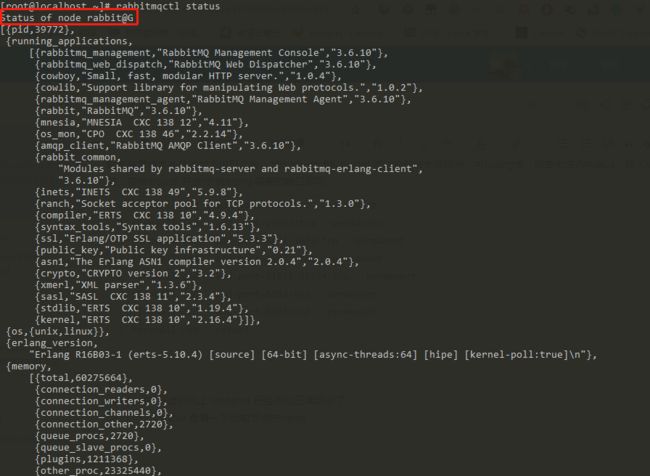
如果两个节点都是 rabbit@localhost,这是无法建立集群的
我当时就是遇到了这个问题,需要修改节点name,参考 https://ubuntuqa.com/article/6619.html
我采取的方法:
vi /etc/rabbitmq/rabbitmq-env.conf
# 添加如下配置
NODENAME=rabbit@G
# 保存后,重启rabbitmq 生效
service rabbitmq-server restart
5. 组成集群
上述步骤都成功后,我们可以组成集群了
这个时候我们先启动rabbitmq@F,然后rabbit@G执行以下操作,加入F,组成集群
rabbitmqctl stop_app # 停止rabbitmq服务
rabbitmqctl reset # 清空节点状态
rabbitmqctl join_cluster rabbit@F # 加入F,组成集群
rabbitmqctl start_app
集群中,任意节点停机后,执行 rabbitmqctl start_app 即可再次加入集群
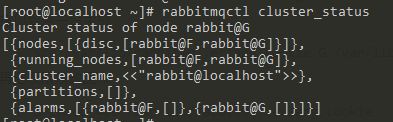
查看集群状态 rabbitmqctl cluster_status
镜像模式
任意rabbit节点输入命令,将所有队列,同步到所有节点中
rabbitmqctl set_policy ha-all "^" '{"ha-mode":"all"}'
rabbitmqctl set_policy [-p Vhost] Name Pattern Definition [Priority]
-p Vhost: 可选参数,针对指定vhost下的queue进行设置
Name: policy的名称
Pattern: queue的匹配模式(正则表达式)
Definition:镜像定义,包括三个部分ha-mode, ha-params, ha-sync-mode
ha-mode:指明镜像队列的模式,有效值为 all/exactly/nodes
all:表示在集群中所有的节点上进行镜像
exactly:表示在指定个数的节点上进行镜像,节点的个数由ha-params指定
nodes:表示在指定的节点上进行镜像,节点名称通过ha-params指定
ha-params:ha-mode模式需要用到的参数
ha-sync-mode:进行队列中消息的同步方式,有效值为automatic和manual
priority:可选参数,policy的优先级
关于镜像模式策略的更多请参考官方文档:https://www.rabbitmq.com/ha.html
集群的负载均衡
为什么有了集群还需要负载均衡?
这里我纠结了好几天,原因是,在我的理解里 集群 == 负载均衡,这样的理解是有问题的。
正解:分布式集群保证的是高可用,而并不是负载均衡。
rabbitmq文档中,也建议我们使用TCP负载均衡器,这样也不需要在我们应用程序里管理集群的地址
Connecting to Clusters from Clients
A client can connect as normal to any node within a cluster. If that node should fail, and the rest of the cluster survives, then the client should notice the closed connection, and should be able to reconnect to some surviving member of the cluster. Generally, it's not advisable to bake in node hostnames or IP addresses into client applications: this introduces inflexibility and will require client applications to be edited, recompiled and redeployed should the configuration of the cluster change or the number of nodes in the cluster change. Instead, we recommend a more abstracted approach: this could be a dynamic DNS service which has a very short TTL configuration, or a plain TCP load balancer, or some sort of mobile IP achieved with pacemaker or similar technologies. In general, this aspect of managing the connection to nodes within a cluster is beyond the scope of RabbitMQ itself, and we recommend the use of other technologies designed specifically to solve these problems.
网上比较多的方案是使用 HAProxy 作为负载均衡器,这里大家可以参考一下这一篇 HAProxy从零开始到掌握 具体安装配置的细节本文就不说了
这里我又添加了一台 130 的虚拟机来跑 HAProxy
贴一下我的 haproxy.cfg,仅供参考
global
daemon
pidfile /home/ha/haproxy/conf/haproxy.pid
log 127.0.0.1 local2
defaults
mode tcp
maxconn 10000
timeout connect 5s
timeout client 100s
timeout server 100s
frontend http-in
bind *:5670
maxconn 30000
default_backend default_servers
backend default_servers
balance roundrobin
server F 192.168.32.128:5672 check inter 2000 rise 2 fall 3 weight 1
server G 192.168.32.129:5672 check inter 2000 rise 2 fall 3 weight 1
listen stats
bind *:1936
mode http
stats refresh 30s #每30秒更新监控数据
stats uri /stats #访问监控页面的uri
stats realm HAProxy\ Stats #监控页面的认证提示
stats auth admin:admin
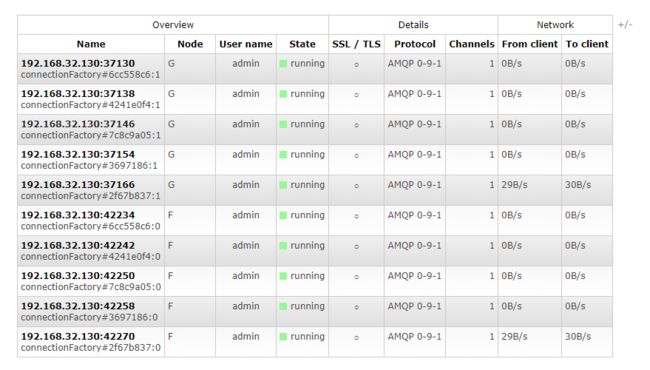
做完负载均衡之后,可以跑一下程序,查看一下负载均衡的效果,这里我的10个 Connection 按照权重 1:1 分配在了两台 Rabbit 上
参考
https://www.cnblogs.com/knowledgesea/p/6535766.html
https://www.rabbitmq.com/clustering.html