
在日常分析中,常会遇到不知道选择什么分析方法的尴尬情况出现,尤其是在面对几种相似的方法,不知道它们之间有什么差别,一念之差就会选错方法。相信这样的小盲点,依然困扰着不少人。
因此,SPSSAU整理了一份相似方法的对比目录,可以一目了然地比较出方法间的差异。由于方法较多,将分几部分整理出来。
1. 基本描述统计
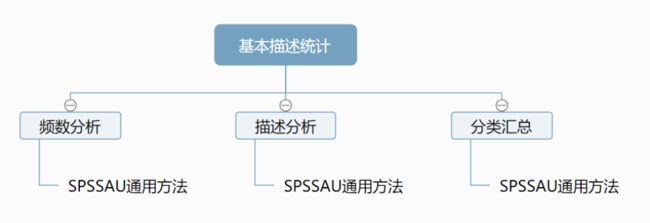
频数分析是用于分析定类数据的选择频数和百分比分布。
描述分析用于描述定量数据的集中趋势、波动程度和分布形状。如要计算数据的平均值、中位数等,可使用描述分析。
分类汇总用于交叉研究,展示两个或更多变量的交叉信息,可将不同组别下的数据进行汇总统计。
2. 信度分析
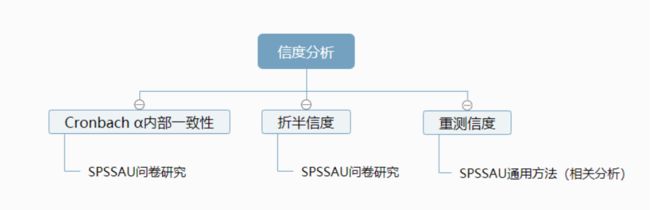
信度分析的方法主要有以下三种:Cronbach α信度系数法、折半信度法、重测信度法。

Cronbach α信度系数法为最常使用的方法,即通过Cronbach α信度系数测量测验或量表的信度是否达标。
折半信度是将所有量表题项分为两半,计算两部分各自的信度以及相关系数,进而估计整个量表的信度的测量方法。可在信度分析中选择使用折半系数或是Cronbach α系数。
重测信度是指同一批样本,在不同时间点做了两次相同的问题,然后计算两次回答的相关系数,通过相关系数去研究信度水平。
3. 效度分析
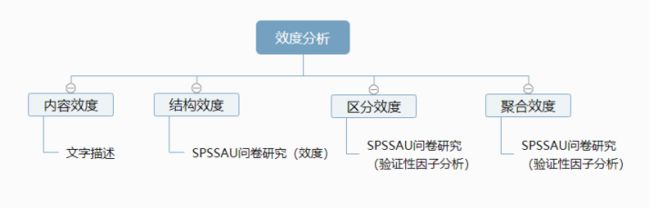
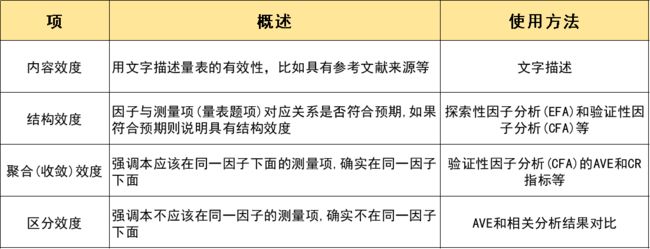
效度有很多种,可分为四种类型:内容效度、结构效度、区分效度、聚合效度。具体区别如下表所示:
4. 差异关系研究

T检验可分析X为定类数据,Y为定量数据之间的关系情况,针对T检验,X只能为2个类别。
当组别多于2组,且数据类型为X为定类数据,Y为定量数据,可使用方差分析。
如果要分析定类数据和定类数据之间的关系情况,可使用交叉卡方分析
如果研究定类数据与定量数据关系情况,且数据不正态或者方差不齐时,可使用非参数检验。
5. 影响关系研究
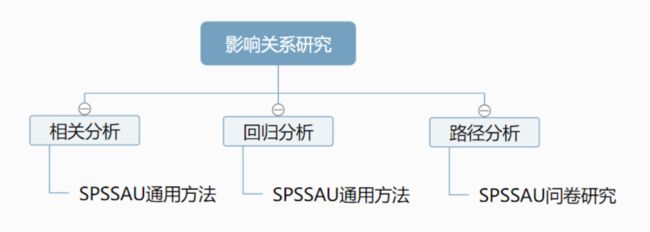
相关分析用于研究定量数据之间的关系情况,可以分析包括是否有关系,以及关系紧密程度等。分析时可以不区分XY,但分析数据均要为定量数据。
回归分析通常指的是线性回归分析,一般可在相关分析后进行,用于研究影响关系情况,其中X通常为定量数据(也可以是定类数据,需要设置成哑变量),Y一定为定量数据。
回归分析通常分析Y只有一个,如果想研究多个自变量与多个因变量的影响关系情况,可选择路径分析。
6. 相关分析汇总
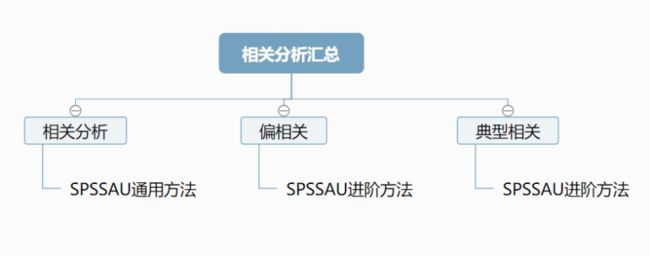
相关分析用于研究X和Y的关系情况,X、Y都为定量数据。
(1)简单相关分析是分析对两个变量之间的相关关系。
(2)当两个变量都与第三个变量相关时,为了消除第三个变量的影响,值关注这两个变量之间的关系情况,此时可使用偏相关分析。
(3)如果是研究两组变量之间的整体相关性,可用典型相关分析。
7. 线性回归汇总
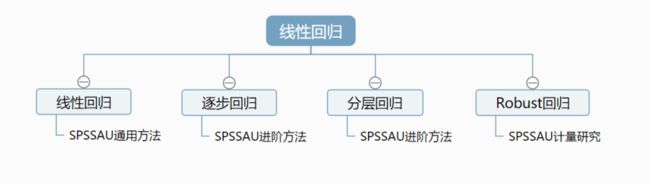
线性回归用于研究X对于Y的影响,前提是因变量Y为定量数据。
如果X很多时,可使用逐步回归自动找出有影响的X;
如果需要研究多个线性回归的层叠变化情况,此时可使用分层回归;
如果数据中有异常值,可使用Robust回归进行研究。
8. Logistic回归汇总
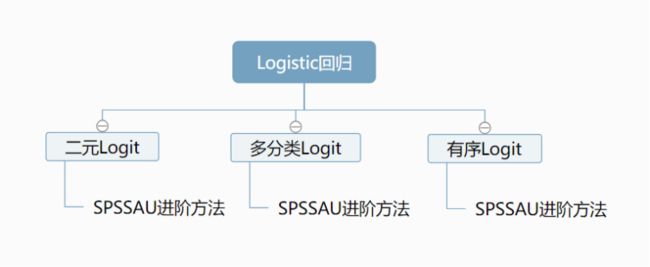
Logistic回归用于研究X对于Y的影响,因变量Y一定为定类数据。
如果Y有两个选项时,可使用二元Logit回归。
如果Y的选项大于2个时,可使用多分类Logit回归。
如果Y为定类数据,且选项有顺序大小之分时,可使用有序Logit回归。
9. T检验汇总
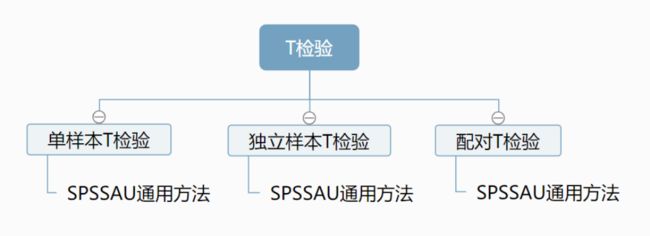
T检验用于分析定类数据与定量数据之间的关系情况,且X的组别只限于为两组。
如果是对比单个变量与某个数字的差异,可用单样本T检验。
如果是对比两个变量之间(X定类,Y定量)的差异关系,可用独立样本T检验。
如果两个变量是配对数据,比如对一个群体用同一个工具前后测量了两次,可用配对T检验分析。
10. 方差分析汇总
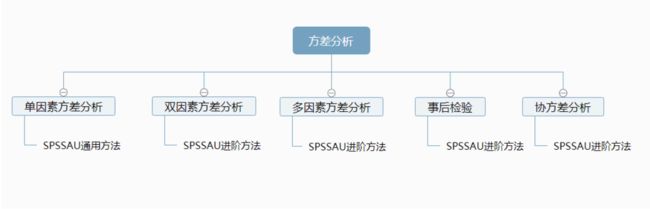
方差分析用于分析定类数据与定量数据之间的关系情况,可分析两组或两组以上的变量差异。
如果X为一个,则使用单因素方差分析,即通用方法里的方差。
如果X的个数为2个,可使用双因素方差分析。
当X个数超过2个,可使用多因素方差分析。通常双因素方差分析与多因素方差分析多用于实验研究中。
事后检验是基于方差分析基础上进行,如果X的组别超过两组,可用事后检验进一步分析两两组别之间的差异。
如果研究中有干扰因素(控制变量),可使用协方差分析。
11. 多选题研究
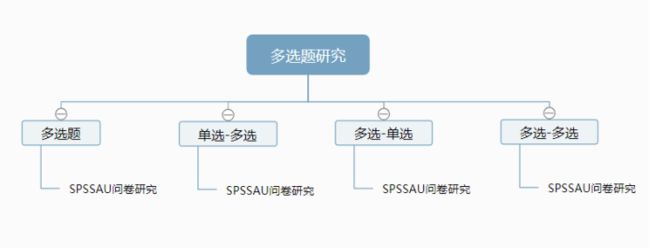
多选题分析可分为四种类型包括:多选题、单选-多选、多选-单选、多选-多选。
“多选题分析”是针对单个多选题的分析方法,可分析多选题各项的选择比例情况
“单选-多选”是针对X为单选,Y为多选的情况使用的方法,可分析单选和多选题的关系。
“多选-单选”是针对X为多选,Y为单选的情况使用的方法。
“多选-多选”是针对X为多选,Y为多选的情况使用的方法。
12. 聚类分析
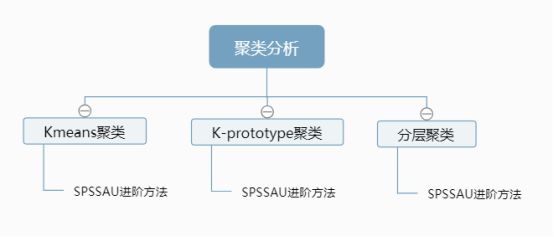
聚类分析以多个研究标题作为基准,对样本对象进行分类。
如果是按样本聚类,则使用SPSSAU的进阶方法模块中的“聚类”功能,系统会自动识别出应该使用K-means聚类算法还是K-prototype聚类算法。
如果是按变量(标题)聚类,此时应该使用分层聚类,并且结合聚类树状图进行综合判定分析。
13. 权重研究
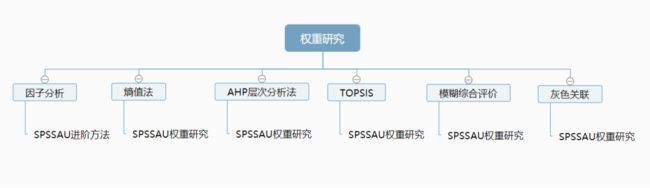
权重研究是用于分析各因素或指标在综合体系中的重要程度,最终构建出权重体系。权重研究有多种方法包括:因子分析、熵值法、AHP层次分析法、TOPSIS、模糊综合评价、灰色关联等。
因子分析:因子分析可将多个题项浓缩成几个概括性指标(因子),然后对新生成的各概括性指标计算权重。
熵值法:熵值法是利用熵值携带的信息计算每个指标的权重,通常可配合因子分析或主成分分析得到一级权重,利用熵值法计算二级权重。
AHP层次分析法:AHP层次分析法是一种主观加客观赋值的计算权重的方法。先通过专家打分构造判断矩阵,然后量化计算每个指标的权重。
TOPSIS法:TOPSIS权重法是一种评价多个样本综合排名的方法,用于比较样本的排名。
模糊综合评价:是通过各指标的评价和权重对评价对象得出一个综合性评价。
灰色关联:灰色关联是一种评价多个指标综合排名的方法,用于判断指标排名。
14. 非参数检验
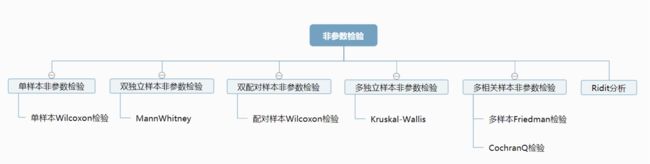
非参数检验用于研究定类数据与定量数据之间的关系情况。如果数据不满足正态性或方差不齐,可用非参数检验。
单样本Wilcoxon检验用于检验数据是否与某数字有明显的区别。
如果X的组别为两组,则使用MannWhitney统计量,如果组别超过两组,则应该使用Kruskal-Wallis统计量结果,SPSSAU可自动选择。
如果是配对数据,则使用配对样本Wilcoxon检验
如果要研究多个关联样本的差异情况,可以用多样本Friedman检验。
如果是研究定类数据与定量(等级)数据之间的差异性,还可以使用Ridit分析。
15. 数据分布
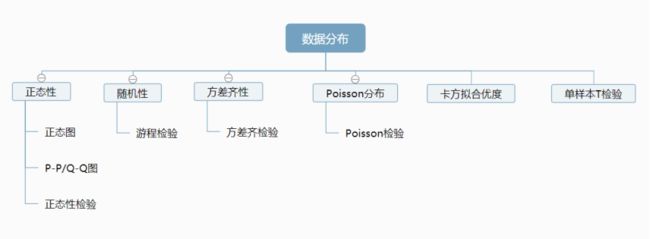
判断数据分布是选择正确分析方法的重要前提。
正态性:很多分析方法的使用前提都是要求数据服从正态性,比如线性回归分析、相关分析、方差分析等,可通过正态图、P-P/Q-Q图、正态性检验查看数据正态性。
随机性:游程检验是一种非参数性统计假设的检验方法,可用于分析数据是否为随机。
方差齐性:方差齐检验用于分析不同定类数据组别对定量数据时的波动情况是否一致,即方差齐性。方差齐是方差分析的前提,如果不满足则不能使用方差分析。
Poisson分布:如果要判断数据是否满足Poisson分布,可通过Poisson检验判断或者通过特征进行判断是否基本符合Poisson分布(三个特征即:平稳性、独立性和普通性)
卡方拟合优度检验:卡方拟合优度检验是一种非参数检验方法,其用于研究实际比例情况,是否与预期比例表现一致,但只针对于类别数据。
单样本T检验:单样本T检验用于分析定量数据是否与某个数字有着显著的差异性。
16. 模型研究方法
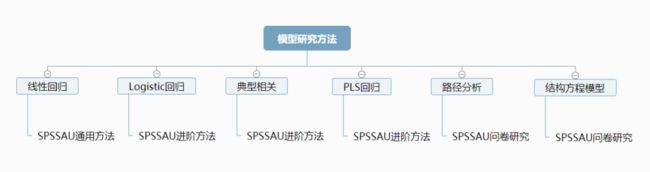
当需要研究多个变量之间的关系情况时,通常可构建统计模型用于分析及预测。
如果研究一个X或多个X对Y的影响关系,其中Y为定量数据,可使用线性回归分析,构建回归模型。
如果研究一个X或多个X对Y的影响关系,其中Y为定类数据,可使用Logistic分析,构建Logistic回归模型。
如果要分析1组X与一组Y之间的关系情况,可使用典型相关分析。
如果要分析多个X与多个Y之间的影响关系情况,且样本量较小(通常小于200),可使用PLS回归分析。
如需分析多个X对多个Y的影响关系,以及具体哪些X对哪些Y有影响如何影响,可使用路径分析。
还有一种方法称为结构方程模型,包含测量模型和结构模型。如果需要测量模型和结构模型,可使用结构方程模型。
17. 信息浓缩方法
当研究中包括有很多题目或很多变量时,可通过信息浓缩的方法,把数据浓缩成一个或多个变量,以便用于后续的分析。
主成分分析和因子分析都是信息浓缩的方法,即将多个分析项信息浓缩成几个概括性指标。如果希望进行将指标命名,SPSSAU建议使用因子分析。原因在于因子分析在主成分基础上,多出一项旋转功能,该旋转目的即在于命名。
平均值和求和也是信息浓缩的常用方法,比如要将多个题项合并成一个变量,可通过求平均值概括成一个题项。当数据不满足正态,存在极端值时,可用中位数代替平均值。
18. 一致性研究方法
一致性检验的目的在于比较不同方法得到的结果是否具有一致性。检验一致性的方法有很多比如:Kappa检验、ICC组内相关系数、Kendall W协调系数等。
Kappa系数检验,适用于两次数据(方法)之间比较一致性,比如两位医生的诊断是否一致,两位裁判的评分标准是否一致等。
ICC组内相关系数检验,用于分析多次数据的一致性情况,功能上与Kappa系数基本一致。ICC分析定量或定类数据均可;但是Kappa一致性系数通常要求数据是定类数据。
Kendall W协调系数,是分析多个数据之间关联性的方法,适用于定量数据,尤其是定序等级数据。
19. 配对数据研究方法
配对研究是一种医学上常见的研究设计,常见于单组样本前后对比研究,或者将样本分为实验组和对比组两组,针对干预措施进行研究。
如果配对样本数据为定量数据时,可使用配对样本T检验。
如果配对样本数据为定量数据,但配对样本的差值不符合正态分布,则考虑使用配对Wilcoxon检验
如果数据为定类数据,则使用配对卡方检验。
20. 多元统计研究
判别分析:用于在分类确定前提下,根据数据的特征来判断新的未知属于哪个类别。
对应分析:用于分析定类数据的分类情况,并结合图形展示。
曲线分析:如果想要研究X对Y的影响关系,且X和Y不满足线性关系(可通过散点图观察),而呈现出曲线关系,建议根据曲线拟合图结果,选择拟合程度较好的曲线进行曲线回归分析。
更多干货内容可登录SPSSAU官网查看