Featuretools是一个可以自动进行特征工程的python库,主要原理是针对多个数据表以及它们之间的关系,通过转换(Transformation)和聚合(Aggregation)操作自动生成新的特征。转换操作的对象是单一数据表的一列或多列(例如对某列取绝对值或者计算两列之差);聚合操作的对象是具有父子 (one-to-many)关系的两个数据表,通过对父表的某列进行归类(groupby)计算子表某列对应的统计值。下面通过几个简单的例子进行介绍,Featuretools在实际应用中的案例可以参考它的Github仓库。
1. 顾客交易记录,每个交易对应一个顾客,可分多次支付(需要求解的问题是关于顾客的)
- 建立数据
 View Code
View Codeimport featuretools as ft import pandas as pd ### 构建简单的数据表 customers = pd.DataFrame({'customer_id':[1,2],}) transactions = pd.DataFrame({'transaction_id':[1,2,3,4,5], 'customer_id':[1,1,1,2,2], \ 'amount':[3.,8.,6.,4.,9.]}) payments = pd.DataFrame({'payment_id':[1,2,3,4,5,6,7,8], 'transaction_id':[1,1,2,3,3,4,4,5], \ 'money':[3,7,6,5,8,2,4,7]}) ### 建立数据表之间的关系 es = ft.EntitySet('example1') es.entity_from_dataframe(dataframe=payments, entity_id='payments', index='payment_id') es.entity_from_dataframe(dataframe=transactions, entity_id='transactions', index='transaction_id') es.entity_from_dataframe(dataframe=customers, entity_id='customers', index='customer_id') r1 = ft.Relationship(es['customers']['customer_id'], es['transactions']['customer_id']) r2 = ft.Relationship(es['transactions']['transaction_id'], es['payments']['transaction_id']) es = es.add_relationship(r1) es = es.add_relationship(r2) print(es)

- 生成新的特征
View Code
# 自定义primitive # Featuretools内置了许多常用的primitive, 这里仅为了介绍Featuretools更多的特性 def plusOne(column): return column+1 plus_one = ft.primitives.make_trans_primitive(function=plusOne, input_types=[ft.variable_types.Numeric],\ return_type=ft.variable_types.Numeric) def maximum(column): return max(column) Maximum = ft.primitives.make_agg_primitive(function=maximum, input_types=[ft.variable_types.Numeric], \ return_type=ft.variable_types.Numeric) # max_depth控制转换和聚合的次数 feature_matrix, feature_defs = ft.dfs(entityset=es, target_entity="customers", trans_primitives=[plus_one], \ agg_primitives=["sum", Maximum], max_depth=3) print(feature_defs)
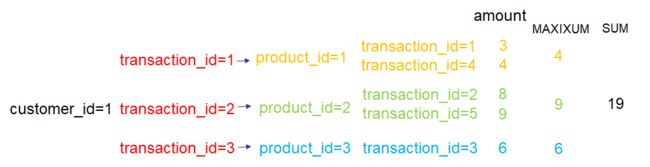
以特征SUM(transactions.PLUSONE(MAXIMUM(payments.money)))为例,下图说明了对customer_id=1的顾客该特征是如何计算的:

2. 顾客交易记录,每个交易对应一个顾客,可分多次支付(需要求解的问题是关于交易的)
- 同上,仅改动一行代码:
feature_matrix, feature_defs = ft.dfs(entityset=es, target_entity="transactions", trans_primitives=[plus_one], \ agg_primitives=["sum", Maximum], max_depth=3)
以特征customers.PLUSONE(SUM(payments.money))为例,下图说明了对transaction_id=1的交易该特征是如何计算的:

3. 顾客交易记录,每个交易对应一个顾客和一个商品(需要求解的问题是关于顾客的)
- 建立数据
View Code
customers = pd.DataFrame({'customer_id':[1,2],}) transactions = pd.DataFrame({'transaction_id':[1,2,3,4,5], 'customer_id':[1,1,1,2,2], \ 'amount':[3.,8.,6.,4.,9.], 'product_id':[1,2,3,1,2]}) products = pd.DataFrame({'product_id':[1,2,3]}) ### 建立数据表之间的关系 es = ft.EntitySet('example') es.entity_from_dataframe(dataframe=products, entity_id='products', index='product_id') es.entity_from_dataframe(dataframe=transactions, entity_id='transactions', index='transaction_id') es.entity_from_dataframe(dataframe=customers, entity_id='customers', index='customer_id') r1 = ft.Relationship(es['customers']['customer_id'], es['transactions']['customer_id']) r2 = ft.Relationship(es['products']['product_id'], es['transactions']['product_id']) es = es.add_relationship(r1) es = es.add_relationship(r2) print(es)
-
生成新的特征
View Codedef plusOne(column): return column+1 plus_one = ft.primitives.make_trans_primitive(function=plusOne, input_types=[ft.variable_types.Numeric],\ return_type=ft.variable_types.Numeric) def maximum(column): return max(column) Maximum = ft.primitives.make_agg_primitive(function=maximum, input_types=[ft.variable_types.Numeric], \ return_type=ft.variable_types.Numeric) feature_matrix, feature_defs = ft.dfs(entityset=es, target_entity="customers", trans_primitives=[plus_one], \ agg_primitives=["sum", Maximum], max_depth=3) print(feature_defs)
以特征SUM(transactions.products.MAXIMUM(transactions.amount))为例,下图说明了对customer_id=1的顾客该特征是如何计算的:
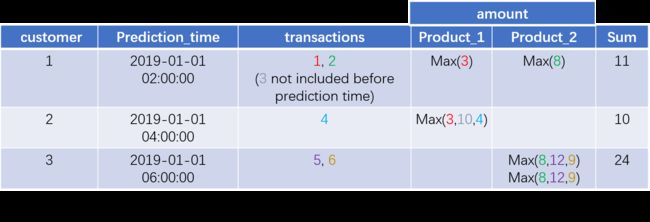
Featuretools的一个重要特性是可以在建立特征工程时自动考虑时间的影响,防止数据泄露。下面仍以一个简单的例子进行说明,同上仍为顾客交易记录,每个交易对应一个顾客和一个商品,但是需要求解的问题是关于顾客在某个时间点的情况。
- 建立数据
View Code
import featuretools as ft import pandas as pd ### 构建交易数据表 transactions = pd.DataFrame({'transaction_id':[1,2,3,4,5,6], 'customer_id':[1,1,1,2,3,3], 'product_id':[1,2,1,1,2,2], \ 'time':[pd.Timestamp('1/1/2019')+pd.Timedelta(x,'h') for x in [1,2,3,4,5,6]], \ 'amount':[3., 8., 10., 4., 12., 9]}) #加入了交易时间 products = pd.DataFrame({'product_id':[1,2]}) ### 对每个顾客,定义对应的预测时间 cutoff_times = pd.DataFrame({'customer_id':[1,2,3],'time':[pd.Timestamp('1/1/2019')+pd.Timedelta(x,'h') for x in [2,4,6]]}) ### 从原始数据表中生成新的数据表并建立关系 es = ft.EntitySet('example') es.entity_from_dataframe(dataframe=transactions, entity_id='transactions', index='transaction_id', time_index='time') es.normalize_entity(base_entity_id='transactions', new_entity_id='customers',index='customer_id') es.normalize_entity(base_entity_id='transactions', new_entity_id='products',index='product_id') print(es)

- 生成新的特征
View Code
feature_matrix, feature_defs = ft.dfs(entityset=es, target_entity="customers", agg_primitives=["max","sum"], \ max_depth=3, cutoff_time=cutoff_times) #添加了cutoff_time这一参数 print(feature_defs)
下图以特征SUM(transactions.products.MAX(transactions.amount))为例,说明建立特征时如何考虑了时间的影响