In the last article (I hope) of this series I want to look at what happens when I change the parallel distribution method on the query that I’ve been using in my previous demonstrations. This was a query first introduced in a note on Bloom Filters (opens in a separate window) where I show two versions of a four-table parallel hash join, one using using the broadcast distribution mechanism throughout, the other using the hash distribution method. For reference you can review the table definitions and plan (with execution stats) for the serial join in this posting (also opens in a separate window).
To change distribution methods from the broadcast example to the hash example I’ve simply changed a few hints in my code. Here are two sets of hints showing what I’ve done; the first is a repeat from the third article showing the broadcast example, the second shows the small change needed to get the hash example:
/*+
leading(t4 t1 t2 t3)
full(t4) parallel(t4, 2)
use_hash(t1) swap_join_inputs(t1) pq_distribute(t1 none broadcast)
full(t1) parallel(t1, 2)
use_hash(t2) swap_join_inputs(t2) pq_distribute(t2 none broadcast)
full(t2) parallel(t2, 2)
use_hash(t3) swap_join_inputs(t3) pq_distribute(t3 none broadcast)
full(t3) parallel(t3, 2)
monitor
*/
/*+
leading(t4 t1 t2 t3)
full(t4) parallel(t4, 2)
use_hash(t1) swap_join_inputs(t1) pq_distribute(t1 hash hash)
full(t1) parallel(t1, 2)
use_hash(t2) swap_join_inputs(t2) pq_distribute(t2 hash hash)
full(t2) parallel(t2, 2)
use_hash(t3) swap_join_inputs(t3) pq_distribute(t3 hash hash)
full(t3) parallel(t3, 2)
monitor
*/
Because of the combination of leading() hint with the use_hash() and swap_join_inputs() hints the plan WILL still build in-memory hash tables from t1, t2, and t3 and it WILL still probe each hash table in turn with the rows (that survive) from t4; but the order of activity in the hash distribution plan will be dramatically different from the order in the serial and parallel broadcast plans where the order in which Oracle actually built the in-memory hash tables was t3, t2, t1.
Here – with a little cosmetic adjustment – is the parallel execution plan using hash distribution on 11.2.0.4, captured from memory with rowsource execution stats enabled (the 12c plan would report PX SEND HYBRID HASH” operators with an associated “STATISTICS COLLECTOR” operator showing that adaptive execution was a possibility – with three points at which the plan might switch from hash distribtion to broadcast):
--------------------------------------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | Cost (%CPU)| E-Time | TQ |IN-OUT| PQ Distrib | A-Rows | A-Time | Buffers | Reads |
--------------------------------------------------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 437 (100)| | | | | 1 |00:00:00.08 | 16 | 5 |
| 1 | SORT AGGREGATE | | 1 | | | | | | 1 |00:00:00.08 | 16 | 5 |
| 2 | PX COORDINATOR | | 1 | | | | | | 2 |00:00:00.08 | 16 | 5 |
| 3 | PX SEND QC (RANDOM) | :TQ10006 | 0 | | | Q1,06 | P->S | QC (RAND) | 0 |00:00:00.01 | 0 | 0 |
| 4 | SORT AGGREGATE | | 2 | | | Q1,06 | PCWP | | 2 |00:00:00.01 | 0 | 0 |
|* 5 | HASH JOIN | | 2 | 437 (3)| 00:00:03 | Q1,06 | PCWP | | 27 |00:00:00.01 | 0 | 0 |
| 6 | JOIN FILTER CREATE | :BF0000 | 2 | 2 (0)| 00:00:01 | Q1,06 | PCWP | | 3 |00:00:00.01 | 0 | 0 |
| 7 | PX RECEIVE | | 2 | 2 (0)| 00:00:01 | Q1,06 | PCWP | | 3 |00:00:00.01 | 0 | 0 |
| 8 | PX SEND HASH | :TQ10004 | 0 | 2 (0)| 00:00:01 | Q1,04 | P->P | HASH | 0 |00:00:00.01 | 0 | 0 |
| 9 | PX BLOCK ITERATOR | | 2 | 2 (0)| 00:00:01 | Q1,04 | PCWC | | 3 |00:00:00.01 | 4 | 2 |
|* 10 | TABLE ACCESS FULL | T3 | 2 | 2 (0)| 00:00:01 | Q1,04 | PCWP | | 3 |00:00:00.01 | 4 | 2 |
| 11 | PX RECEIVE | | 2 | 435 (3)| 00:00:03 | Q1,06 | PCWP | | 27 |00:00:00.01 | 0 | 0 |
| 12 | PX SEND HASH | :TQ10005 | 0 | 435 (3)| 00:00:03 | Q1,05 | P->P | HASH | 0 |00:00:00.01 | 0 | 0 |
| 13 | JOIN FILTER USE | :BF0000 | 2 | 435 (3)| 00:00:03 | Q1,05 | PCWP | | 27 |00:00:00.01 | 0 | 0 |
|* 14 | HASH JOIN BUFFERED | | 2 | 435 (3)| 00:00:03 | Q1,05 | PCWP | | 630 |00:00:00.01 | 0 | 0 |
| 15 | JOIN FILTER CREATE | :BF0001 | 2 | 2 (0)| 00:00:01 | Q1,05 | PCWP | | 3 |00:00:00.01 | 0 | 0 |
| 16 | PX RECEIVE | | 2 | 2 (0)| 00:00:01 | Q1,05 | PCWP | | 3 |00:00:00.01 | 0 | 0 |
| 17 | PX SEND HASH | :TQ10002 | 0 | 2 (0)| 00:00:01 | Q1,02 | P->P | HASH | 0 |00:00:00.01 | 0 | 0 |
| 18 | PX BLOCK ITERATOR | | 2 | 2 (0)| 00:00:01 | Q1,02 | PCWC | | 3 |00:00:00.01 | 4 | 2 |
|* 19 | TABLE ACCESS FULL | T2 | 2 | 2 (0)| 00:00:01 | Q1,02 | PCWP | | 3 |00:00:00.01 | 4 | 2 |
| 20 | PX RECEIVE | | 2 | 432 (3)| 00:00:03 | Q1,05 | PCWP | | 632 |00:00:00.01 | 0 | 0 |
| 21 | PX SEND HASH | :TQ10003 | 0 | 432 (3)| 00:00:03 | Q1,03 | P->P | HASH | 0 |00:00:00.01 | 0 | 0 |
| 22 | JOIN FILTER USE | :BF0001 | 2 | 432 (3)| 00:00:03 | Q1,03 | PCWP | | 632 |00:00:00.09 | 0 | 0 |
|* 23 | HASH JOIN BUFFERED | | 2 | 432 (3)| 00:00:03 | Q1,03 | PCWP | | 14700 |00:00:00.09 | 0 | 0 |
| 24 | JOIN FILTER CREATE | :BF0002 | 2 | 2 (0)| 00:00:01 | Q1,03 | PCWP | | 3 |00:00:00.01 | 0 | 0 |
| 25 | PX RECEIVE | | 2 | 2 (0)| 00:00:01 | Q1,03 | PCWP | | 3 |00:00:00.01 | 0 | 0 |
| 26 | PX SEND HASH | :TQ10000 | 0 | 2 (0)| 00:00:01 | Q1,00 | P->P | HASH | 0 |00:00:00.01 | 0 | 0 |
| 27 | PX BLOCK ITERATOR | | 2 | 2 (0)| 00:00:01 | Q1,00 | PCWC | | 3 |00:00:00.01 | 4 | 2 |
|* 28 | TABLE ACCESS FULL| T1 | 2 | 2 (0)| 00:00:01 | Q1,00 | PCWP | | 3 |00:00:00.01 | 4 | 2 |
| 29 | PX RECEIVE | | 2 | 427 (2)| 00:00:03 | Q1,03 | PCWP | | 14700 |00:00:00.08 | 0 | 0 |
| 30 | PX SEND HASH | :TQ10001 | 0 | 427 (2)| 00:00:03 | Q1,01 | P->P | HASH | 0 |00:00:00.01 | 0 | 0 |
| 31 | JOIN FILTER USE | :BF0002 | 2 | 427 (2)| 00:00:03 | Q1,01 | PCWP | | 14700 |00:00:00.05 | 6044 | 6018 |
| 32 | PX BLOCK ITERATOR | | 2 | 427 (2)| 00:00:03 | Q1,01 | PCWC | | 14700 |00:00:00.04 | 6044 | 6018 |
|* 33 | TABLE ACCESS FULL| T4 | 26 | 427 (2)| 00:00:03 | Q1,01 | PCWP | | 14700 |00:00:00.04 | 6044 | 6018 |
--------------------------------------------------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
5 - access("T3"."ID"="T4"."ID3")
10 - access(:Z>=:Z AND :Z<=:Z)
filter((TO_NUMBER("T3"."SMALL_VC")=1 OR TO_NUMBER("T3"."SMALL_VC")=2 OR TO_NUMBER("T3"."SMALL_VC")=3))
14 - access("T2"."ID"="T4"."ID2")
19 - access(:Z>=:Z AND :Z<=:Z)
filter((TO_NUMBER("T2"."SMALL_VC")=1 OR TO_NUMBER("T2"."SMALL_VC")=2 OR TO_NUMBER("T2"."SMALL_VC")=3))
23 - access("T1"."ID"="T4"."ID1") 28 - access(:Z>=:Z AND :Z<=:Z)
filter((TO_NUMBER("T1"."SMALL_VC")=1 OR TO_NUMBER("T1"."SMALL_VC")=2 OR TO_NUMBER("T1"."SMALL_VC")=3))
33 - access(:Z>=:Z AND :Z<=:Z)
filter(SYS_OP_BLOOM_FILTER(:BF0000,"T4"."ID1"))
There are a couple of significant points that are very easy to point out in this plan. First, we have a number of lines which are “BLOOM FILTER CREATE/USE” lines that did not appear in the broadcast plan; second that we can only see one sys_op_bloom_filter() in the predicate section rather than three (don’t worry, it’s – partly – a reporting defect); finally we have seven virtual tables (table queues :TQnnnnn) in this plan rather than four, and those virtual tables seems to be scattered rather more randomly around the plan.
To make it easier to understand what’s happened with a parallel execution plan, I usually also dump out the contents of v$pq_tqstat after running the query – so here’s the result after running the above:
DFO_NUMBER TQ_ID SERVER_TYPE INSTANCE PROCESS NUM_ROWS BYTES WAITS TIMEOUTS AVG_LATENCY
---------- ---------- --------------- -------- --------------- ---------- ---------- ---------- ---------- -----------
1 0 Producer 1 P002 3 69 1 0 0
1 P003 0 48 0 0 0
Consumer 1 P000 2 62 30 16 0
1 P001 1 55 26 14 0
1 Producer 1 P002 1476 35520 2 1 0
1 P003 13224 317880 1 0 0
Consumer 1 P000 9800 235584 20 14 0
1 P001 4900 117816 20 14 0
2 Producer 1 P000 3 69 0 0 0
1 P001 0 48 0 0 0
Consumer 1 P002 2 62 33 19 0
1 P003 1 55 32 19 0
3 Producer 1 P000 422 9754 0 0 0
1 P001 210 4878 0 0 0
Consumer 1 P002 420 9708 33 19 0
1 P003 212 4924 32 18 0
4 Producer 1 P002 3 69 1 0 0
1 P003 0 48 0 0 0
Consumer 1 P000 2 62 42 20 0
1 P001 1 55 39 15 0
5 Producer 1 P002 18 444 0 0 0
1 P003 9 246 0 0 0
Consumer 1 P000 18 444 41 20 0
1 P001 9 246 39 16 0
6 Producer 1 P000 1 60 0 0 0
1 P001 1 60 0 0 0
Consumer 1 QC 2 120 1 0 0
So let’s work our way through the execution plan – if you want to put the plan and my comments side by side, this link will re-open this article in a second window.
Given the set of hints, and the intent I expressed at the start of the series, we hope to see Oracle building an in-memory hash table from each of t3, t2 and t1 in that order, following which it will scan t4, probe t1, t2, and t3 in that order, and then aggregate the result. Let’s check that using the parallel plan rule of “follow the table queues”.
Table queue 0 covers lines 26 – 28, we scan t1 and distribute it by hash. We can see from the A-Rows column we found 3 rows and distributed them and if we look at the output from v$pq_tqstat we find it matches – slaves 2 and 3 produced 3 rows, slaves 0 and 1 consumed 3 rows. Table queue 1 covers lines 30 – 33, we scan t4 and distribute it by hash. We can see from the A-rows column we found 14,700 rows and distributed them, and again we can see the match in v$pq_tqstat – slaves 2 and 3 produced 14,700 rows and distributed them to slaves 0 and 1. But there’s an oddity here, and things start to get messy: from the predicate section we can see that we applied a Bloom filter on the ID1 column on the data we got from the tablescan, and the plan itself shows a Bloom filter (:BF0002) being used at line 31, but that Bloom filter is created at line 24 of the plan and line 24 has been associated with table queue 3. Now I know (because I constructed the data) that a perfect filter has been created and used at that point because 14,700 rows is exactly the volume of data that should eventually join between tables t1 and t4. It’s reasonable, I think, to say that the boundary between table queues 0 and 3 is a little blurred at lines 24/25 – the slaves that are going to populate table queue 3 are the ones that created the Bloom filter, but they’re not going to populate table queue 3 just yet.
So let’s move on to table queue 2. This covers lines 17-19 (looking at the TQ column) except I’m going to assume the same blurring of boundaries I claimed for table queue 0 – I’m going to say that table queue 2 expands into lines 15-19 (bringing in the PX RECEIVE and JOIN FILTER CREATE (:BF001). So our next step is to scan and distribute table t2, and build a Bloom filter from it. Again we look at v$pq_tqstat and see that in this case it’s slaves 0 and 1 which scan the table and distribute 3 rows to slaves 2 and 3, and we assume that slaves 2 and 3 will send a Bloom filter back to salves 0 and 1.
Now we can move on to table queue 3: line 21 writes to table queue 3 by using lines 22, 23, 24, 25, and 29 according to the TQ column (but thanks to the blurring of the boundaries lines 24 and 25 were used “prematurely” to create the Bloom filter :BF002 describing the results from table t1). So lines 24/25 read table queue 0 and built an in-memory hash table, simultaneously creating a Bloom filter and sending it back to slaves 2 and 3; then line 23 did a HASH JOIN BUFFERED, which means it copied the incoming data from table queue 1 (slaves 2 and 3, table t4) into a buffer and then used that buffer to probe its in-memory hash table and do the join; then line 22 applied a Bloom filter (:BF001) to the result of the hash join although the filter won’t appear in the predicate section until version 12.1.0.1. Notice that line 23 (the join) produced 14,700 rows, demonstrating that our previous filter was a perfect filter, and then line 22 filtered out all but 632 rows. (Again, because I constructed the data I can tell you that the second Bloom filter has also worked with 100% accuracy – although v$pq_tqstat seems to show an extra 2 rows which I can’t account for and which don’t appear in the trace file).
So here’s another problem – we’re using another Bloom filter that we haven’t yet (apparently) created unless we accept my assumption of the blurring of the boundary at lines 15 and 16, where the plan shows two lines associated with table queue 5 even though I need them to be associated with table queue 2 so that they can produce the Bloom filter needed by table queue 3. Again, by the way, we can do the cross-check with the TQ_ID 3 of v$pq_tqstat abnd see slaves 0 and 1 produced 632 rows and sent them to slaves 2 and 3.
Before continuing, lets rewrite the action so far as a series of bullet points:
- Slaves 2,3 scan t1 and distribute to slaves 0,1
- Slaves 0,1 build an in-memory hash table and a Bloom filter (:BF002) for t1, and send the filter to slaves 2,3
- Slaves 2,3 scan t4, use the Bloom filter (:BF002) to eliminate data (luckily 100% perfectly) and distribute the remaining rows to slaves 0,1
- Slaves 0,1 buffer the incoming data
- Slaves 0,1 scan t2 and distribute to slaves 2,3
- Slaves 2,3 build an in-memory hash table for the results from t2 and a Bloom filter (:BF001) for t2, and send the filter to slaves 0,1
- Slaves 0,1 use the buffered t4 to probe the in-memory hash of t1 to do the join, testing join results against the Bloom filter (:BF001) for t2, and distributing the surviving rows to slaves 2,3
The pattern of the last four steps will then repeat for the next hash join – and for longer joins the patten will repeat up to, but excluding, the last join.
- Slaves 2,3 buffer the incoming data (the result of joining t4 and t1) – the buffering is implied by line 14 (which is labelled as an input for table queue 5)
- Slaves 2,3 scan t3 and distribute to slaves 0,1 (reading lines 8,9,10 of the plan), cross-checking with TQ_ID 4 of v$pq_tqstat
- Slaves 0,1 build an in-memory hash table for the results from t3 and a Bloom filter (:BF000) for t3, and send the filter to * slaves 2,3 (“sharing” lines 6 and 7 from table queue 6)
- Slaves 2,3 use the buffered results from (t4/t1) to probe the in-memory hash to t2 to do the join, testing join results against the Bloom filter (:BF000) for t3, and distributing the surviving rows to slaves 0,1.
Again, we can check row counts – the hash join buffered at line 14 shows 630 rows coming from the hash join (i.e. the previous Bloom filter was perfect), and line 13 shows 27 rows surviving the final Bloom filter. Again my knowledge of the data tells me that the Bloom filter was a perfect filter. Cross-checking to TQ_ID 5 of v$pq_tqstat we see slaves 2 and 3 producing 27 rows and slaves 0 and 1 consuming them.
So at this point slaves 0,1 have an in-memory hash table for t3, and are receiving the filtered results of the join between t4, t1, and t2; the slaves have to join and aggregate the the two data sets before forwarding a result to the query co-ordinator. Since the aggregation is a blocking operation (i.e. slaves 0,1 can’t start to send data to the co-ordinator until they’ve finished emptying virtual table 5 and have aggregated all the incoming data) they don’t have to use the “hash join buffered” mechanism, so the pattern for the final part of the plan changes.
Lines 5, 6, 7, 11 show us the hash join (not buffered) with its two inputs (although lines 6 and 7 have, of course, been mentioned once already as the source of the Bloom filter used at line 13). Then line 4 shows slaves 0 and 1 aggregating their results; line 3 shows them forwarding the results to the query co-ordinator, line 2 shows the query co-ordinator receiving the results and line 1 shows it aggregating across the slave results ready to send to the end-user.
It’s a bit complicated, and the constant jumping back and fore through the execution plan lines (especially for the “shared” usage of the Bloom filter creation lines) makes it quite hard to follow, so I’ve drawn up a Powerpoint slide to capture the overall picture:
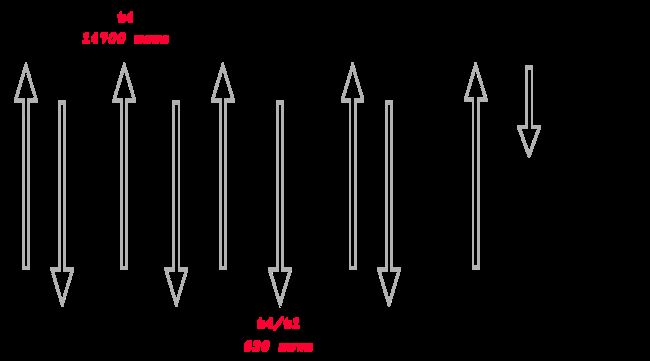
I’ve put the slaves 0 and 1 at the top of the picture, slaves 2 and 3 at the bottom, with the query co-ordinator in the middle at the right hand side. Time reads across the page from left to right, and that gives you the order in which data moves through table queues (and back, for Bloom filters). The annotation give you some idea of what data is moving. Note that I’ve used B1 to refer to the Bloom filter on table T1 (and ignored the numbering on Oracle’s :BFnnn entries). I’ve used red to highlight the data sets that are buffered, and put in curved arrows to show where the buffered data is subsequently brought back into play. I did try to add the various plan line numbers to the picture, but the volume of text made the whole thing incomprehensible – so I’ve left it with what I think is the best compromise of textual information and graphical flow.
I’ll just leave one final warning – if you want to reproduce my results, you’ll have to be careful about versions. I stuck with 11.2.0.4 as that’s the latest version of the most popular general release. There are differences in 12.1.0.1, and there are differences again if you try to emulate 11.2.0.4 by setting the optimizer_features_enable parameter in 12.1.0.1 back to the earlier version.