转自:http://lihaoquan.me/2017/1/1/Profiling-and-Optimizing-Go-using-go-torch.html
Go 代码调优利器 - 火焰图
前言
作为DevOps,我们在日常搞的项目,从开发到测试然后上线,我们基本都局限在功能的单元测试,对一些性能上的细节很多人包括我自己,往往都选择视而不见, 后果往往让工具应用产生不可预测的灾难(it’s true)。有些人说底层的东西,或者代码层面的性能调优太深入了,性能提升可以用硬件来补,但我觉得这只是自欺欺人的想法,提升硬件配置这种土豪方法不能一直长存的,更何况 现在我们的工具哪个不是分布式的,哪个不是集群上跑的,为了冗余也好,为了易于横向扩展也罢,不可能保证所有的服务器都具备高性能的,我们不能让某些低配的服务器运行我们有性能缺陷的代码产生短板,成为瓶颈。
我记得2016年参与了一些通用服务agent的开发,由于要运行于公司全网几乎所有服务器中,生产上的环境复杂程度超乎我们想象。
一个问题到达很深入的时候,就已经是共同的问题
更何况Go语言已经为开发者内置配套了很多性能调优监控的好工具和方法,这大大提升了我们profile分析的效率,除了编码技巧,不断在实战项目中磨炼自己 对性能问题分析的能力,对日后我们在项目的把控力和一些功能布局都是很有帮助。
Golang的性能调优手段
Go语言内置的CPU和Heap profiler
Go强大之处是它已经在语言层面集成了profile采样工具,并且允许我们在程序的运行时使用它们,
使用Go的profiler我们能获取以下的样本信息:
CPU profiles
Heap profiles
block profile、traces等
Go语言常见的profiling使用场景
基准测试文件:例如使用命令go test . -bench . -cpuprofile prof.cpu 生成采样文件后,再通过命令 go tool pprof [binary] prof.cpu 来进行分析。
import _ net/http/pprof:如果我们的应用是一个web服务,我们可以在http服务启动的代码文件(eg: main.go)添加 import _ net/http/pprof,这样我们的服务 便能自动开启profile功能,有助于我们直接分析采样结果。
通过在代码里面调用 runtime.StartCPUProfile或者runtime.WriteHeapProfile
更多调试的使用,建议可以阅读The Go Blog的 Profiling Go Programs
go-torch
在没有使用go-torch之前,我们要分析一分profile文件的时候,遇到结构简单的还好,但遇到一些调用关系复杂的,我相信大部分程序员都觉得无从下手,如下图:

这样的结构,带给我们的是晦涩难懂的感觉,我们需要寻求更直观,更简单的分析工具。
go-torch是Uber
公司开源的一款针对Go语言程序的火焰图生成工具,能收集 stack traces,并把它们整理成火焰图,直观地程序给开发人员。
go-torch是基于使用BrendanGregg创建的火焰图工具生成直观的图像,很方便地分析Go的各个方法所占用的CPU的时间, 火焰图是一个新的方法来可视化CPU的使用情况,本文中我会展示如何使用它辅助我们排查问题。
go-torch项目首页
下图是火焰图的一个事例展示:

这样的展示方式相比之前的树状的,有了更直观的表现,
好,我们了解应该差不多了,可以开始安装并使用go-torch了
安装
1.首先,我们要配置FlameGraph
的脚本
FlameGraph 是profile数据的可视化层工具,已被广泛用于Python和Node
git clone https://github.com/brendangregg/FlameGraph.git
2.检出完成后,把flamegraph.pl
拷到我们机器环境变量$PATH的路径中去,例如:
cp flamegraph.pl /usr/local/bin
3.在终端输入 flamegraph.pl -h
是否安装FlameGraph成功
$ flamegraph.pl -hOption h is ambiguous (hash, height, help)USAGE: /usr/local/bin/flamegraph.pl [options] infile > outfile.svg --title # change title text --width # width of image (default 1200) --height # height of each frame (default 16) --minwidth # omit smaller functions (default 0.1 pixels) --fonttype # font type (default "Verdana") --fontsize # font size (default 12) --countname # count type label (default "samples") --nametype # name type label (default "Function:") --colors # set color palette. choices are: hot (default), mem, io, # wakeup, chain, java, js, perl, red, green, blue, aqua, # yellow, purple, orange --hash # colors are keyed by function name hash --cp # use consistent palette (palette.map) --reverse # generate stack-reversed flame graph --inverted # icicle graph --negate # switch differential hues (blue<->red) --help # this message eg, /usr/local/bin/flamegraph.pl --title="Flame Graph: malloc()" trace.txt > graph.svg
4.安装go-torch
有了flamegraph的支持,我们接下来要使用go-torch展示profile的输出,而安装go-torch很简单,我们使用下面的命令即可完成安装
go get -v github.com/uber/go-torch
5.使用go-torch命令
$ go-torch -hUsage: go-torch [options] [binary]
按照上面的几个步骤,我们基本可以具备生成我们的火焰图的前提条件了,但生成火焰图并不是这篇文章所要表达的目的,记住,我们的目的是: 找出问题,分析问题,解决问题!
下面我们就结合案例,介绍如何使用火焰图辅助性能调优吧
调优实例
demo代码
demo是一个web的服务端程序,对外提供了两个用于我们演示的HTTP接口
我们先阅读 main.go
func main() { flag.Parse() //高级接口 http.HandleFunc("/advance", handler.WithAdvanced(handler.Simple)) //简单接口 http.HandleFunc("/simple", handler.Simple) http.HandleFunc("/", index) fmt.Println("Starting Server on", hostPort) if err := http.ListenAndServe(hostPort, nil); err != nil { log.Fatalf("HTTP Server Failed: %v", err) }}
启动服务后, 浏览器访问 http://localhost:9090/simple 和 http://localhost:9090/advance
正常都会输出
Hello VIP!
虽然输出的内容是一样的,但 /advance 接口附加了一些统计功能,我们可以在终端上启动web服务时,多增加printStats参数:
$ go run main.go -printStats
当我们刷新接口地址的时候,终端都会把访问信息打印出来,如下:
IncCounter: handler.received.lihaoquantekiMacBook-Pro.advance.Mac-OS.Chrome = 1RecordTimer: handler.latency.lihaoquantekiMacBook-Pro.advance.Mac-OS.Chrome = 418.07µsIncCounter: handler.received.lihaoquantekiMacBook-Pro.advance.Mac-OS.Chrome = 1RecordTimer: handler.latency.lihaoquantekiMacBook-Pro.advance.Mac-OS.Chrome = 71.084µsIncCounter: handler.received.lihaoquantekiMacBook-Pro.advance.Mac-OS.Chrome = 1RecordTimer: handler.latency.lihaoquantekiMacBook-Pro.advance.Mac-OS.Chrome = 93.233µsIncCounter: handler.received.lihaoquantekiMacBook-Pro.advance.Mac-OS.Chrome = 1RecordTimer: handler.latency.lihaoquantekiMacBook-Pro.advance.Mac-OS.Chrome = 88.246µsIncCounter: handler.received.lihaoquantekiMacBook-Pro.advance.Mac-OS.Chrome = 1RecordTimer: handler.latency.lihaoquantekiMacBook-Pro.advance.Mac-OS.Chrome = 99.305µsIncCounter: handler.received.lihaoquantekiMacBook-Pro.advance.Mac-OS.Chrome = 1RecordTimer: handler.latency.lihaoquantekiMacBook-Pro.advance.Mac-OS.Chrome = 82.383µsIncCounter: handler.received.lihaoquantekiMacBook-Pro.advance.Mac-OS.Chrome = 1RecordTimer: handler.latency.lihaoquantekiMacBook-Pro.advance.Mac-OS.Chrome = 86.55µsIncCounter: handler.received.lihaoquantekiMacBook-Pro.advance.Mac-OS.Chrome = 1RecordTimer: handler.latency.lihaoquantekiMacBook-Pro.advance.Mac-OS.Chrome = 109.914µs
OK, 例子很简单而且表面上看起来web服务都很正常,但背后真的是风平浪静吗?毕竟我们的并发量还没真正上去,cpu和内存都还没经受考验呢!
我们继续保持web服务处于工作状态,然后输入以下命令:
kapok -d=35 -c=1000 http://localhost:9090/advance
kapok 是我自己开发用于压测的工具,除此之外,可使用go-wrk 或者 vegeta等http压测工具代替
在上面的压测过程中,我们再新建一个终端窗口输入以下命令,生成我们的profile文件:
$ go tool pprof --seconds 25 http://localhost:9090/debug/pprof/profile
命令中,我们设置了25秒的采样时间,当看到(pprof)的时候,我们输入 web
, 表示从浏览器打开
Fetching profile from http://localhost:9090/debug/pprof/profile?seconds=25Please wait... (25s)Saved profile in /Users/lihaoquan/pprof/pprof.localhost:9090.samples.cpu.014.pb.gzEntering interactive mode (type "help" for commands)(pprof) web
这样我们可以得到一个完整的程序调用性能采样profile的输出,如下图:

就像评分报告一样,模块间的调用耗时都能从图中得到展现,但是, 这种图有个缺点,就是层次很深的话,这周发散性的层级关系有点不友好,我们可能需要换一种展示方式来告诉我们应用是否有问题
好,我们回调终端上,依旧调用压力测试工具:
kapok -d=35 -c=1000 http://localhost:9090/advance
不过,我们决定使用go-torch来生成采样报告:
go-torch -u http://localhost:9090 -t 30
大概等三十秒后,go-torch完成采用后,会输出以下信息:
Writing svg to torch.svg
torch.svg
是go-torch采样结束后自动生成的profile文件,我们也照旧用浏览器进行打开:

嗯,这样体验好多了,接下来我们可以基于这个火焰图诊断一下我们的web服务是否是“健康”的!
火焰图的y轴表示cpu调用方法的先后,x轴表示在每个采样调用时间内,方法所占的时间百分比,越宽代表占据cpu时间越多
我们发现
os.Hostname
这个地方很明显有可疑,因为按正常理解一个回去hostname的方法,不应该占据这么多的资源啊,我们先去代码里看下:
func getStatsTags(r *http.Request) map[string]string { userBrowser, userOS := parseUserAgent(r.UserAgent()) stats := map[string]string{ "browser": userBrowser, "os": userOS, "endpoint": filepath.Base(r.URL.Path), } host, err := os.Hostname() if err == nil { if idx := strings.IndexByte(host, '.'); idx > 0 { host = host[:idx] } stats["host"] = host } return stats}
getStatsTags
这个方法会在每次访问 /advance接口的时候都会被调用,而代码里也很明显的使用了 os.Hostname()
。 一般情况下我们的机器的hostname不应该是频繁变化的,所以 我们应该把这个获取hostname的代码单独拿出来,作为一个全局性的处理,这样每次接口调用就不用再新调用它一次了:
改进后的代码:
var _hostName = getHost()func getHost() string { host, err := os.Hostname() if err != nil { return "" } if idx := strings.IndexByte(host, '.'); idx > 0 { host = host[:idx] } return host}func getStatsTags(r *http.Request) map[string]string { userBrowser, userOS := parseUserAgent(r.UserAgent()) stats := map[string]string{ "browser": userBrowser, "os": userOS, "endpoint": filepath.Base(r.URL.Path), } if _hostName != "" { stats["host"] = _hostName } return stats}
为了检验我们的诊断是否正确,我们重启我们的web服务再来调试一下,继续同时运行以下命令
$ kapok -d=35 -c=1000 http://localhost:9090/advance
依旧在压测的同时,我们并行采样:
$ go-torch -u http://localhost:9090 -t 30
生成新的profile后,浏览器打开

可以看到,之前的os.Hostname在火焰图上没有了,我们解决了一个bug~
想必这里我们一定认为安枕无忧了,但是俗语说祸不单行,bug一般不会轻易显露出来的,我们最好还是 深入挖掘它。
我们发现下图的一个地方(绿色框中的地方):

从统计数据看到,绿色框标识的地方,采用数只有140,而这个函数应该也是每次调用/advance的时候都会被调用一次的,也就是说这里出现问题了。
我们在火焰图上再点进去,发现了可疑的地方了:
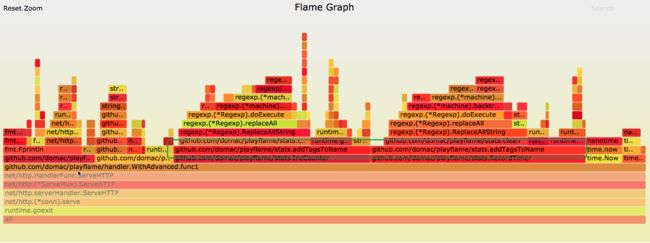
绿色标识的地方所示,addTagsToName这个方法调用,为什么会出现两次呢?
知道可能出现问题的地方,但百思不得其解!要怎么样才能具体定位问题所在呢?
我们这个时候应该针对addTagsToName,尝试对症下药。
我们矛头指向addTagsToName,做一次基准测试
测试文件如下:
reporter_test.go
package statsimport "testing"func BenchmarkAddTagsToName(b *testing.B) { tags := map[string]string{ "host": "myhost", "endpoint": "hello", "os": "OS X", "browser": "Chrome", } for i := 0; i < b.N; i++ { addTagsToName("recv.calls", tags) }}func TestAddTagsToName(t *testing.T) { tests := []struct { name string tags map[string]string expected string }{ { name: "recvd", tags: nil, expected: "recvd.no-endpoint.no-os.no-browser", }, { name: "recvd", tags: map[string]string{ "endpoint": "hello", "os": "OS X", "browser": "Chrome", }, expected: "recvd.hello.OS-X.Chrome", }, { name: "r.call", tags: map[string]string{ "host": "my-host-name", "endpoint": "hello", "os": "OS{}/\tX", "browser": "Chro\:me", }, expected: "r.call.my-host-name.hello.OS----X.Chro--me", }, } for _, tt := range tests { got := addTagsToName(tt.name, tt.tags) if got != tt.expected { t.Errorf("addTagsToName(%v, %v) got %v, expected %v", tt.name, tt.tags, got, tt.expected) } }}
我们执行一下benchmark测试
先是cpu的性能分析
$ go test -bench . -benchmem -cpuprofile prof.cpuBenchmarkAddTagsToName-4 500000 3172 ns/op 480 B/op 16 allocs/opPASSok github.com/domac/playflame/stats 1.633s
使用go tool分析一下:
$ go tool pprof stats.test prof.cpuEntering interactive mode (type "help" for commands)(pprof) top10930ms of 1420ms total (65.49%)Showing top 10 nodes out of 85 (cum >= 60ms) flat flat% sum% cum cum% 130ms 9.15% 9.15% 420ms 29.58% regexp.(machine).tryBacktrack 120ms 8.45% 17.61% 120ms 8.45% regexp/syntax.(Inst).MatchRunePos 120ms 8.45% 26.06% 300ms 21.13% runtime.mallocgc 100ms 7.04% 33.10% 100ms 7.04% regexp.(bitState).push 90ms 6.34% 39.44% 300ms 21.13% runtime.growslice 90ms 6.34% 45.77% 90ms 6.34% runtime.memmove 80ms 5.63% 51.41% 530ms 37.32% regexp.(machine).backtrack 80ms 5.63% 57.04% 80ms 5.63% runtime.heapBitsSetType 60ms 4.23% 61.27% 850ms 59.86% regexp.(*Regexp).replaceAll 60ms 4.23% 65.49% 60ms 4.23% sync/atomic.CompareAndSwapUint32(pprof)
从排行榜看到,大概regexp很大关系,但这不好看出真正问题,需要再用别的招数
我们在(pprof)后,输入list addTagsToName
, 分析基准测试文件中具体的方法
(pprof) list addTagsToNameTotal: 1.42sROUTINE ======================== github.com/domac/playflame/stats.addTagsToName in /Users/lihaoquan/GoProjects/Playground/src/github.com/domac/playflame/stats/reporter.go 20ms 1.37s (flat, cum) 96.48% of Total . . 31: } . . 32:} . . 33: . . 34:func addTagsToName(name string, tags map[string]string) string { . . 35: var keyOrder []string . 10ms 36: if _, ok := tags["host"]; ok { . 20ms 37: keyOrder = append(keyOrder, "host") . . 38: } . 30ms 39: keyOrder = append(keyOrder, "endpoint", "os", "browser") . . 40: . . 41: parts := []string{name} . . 42: for _, k := range keyOrder { 20ms 40ms 43: v, ok := tags[k] . . 44: if !ok || v == "" { . . 45: parts = append(parts, "no-"+k) . . 46: continue . . 47: } . 1.12s 48: parts = append(parts, clean(v)) . . 49: } . . 50: . 150ms 51: return strings.Join(parts, ".") . . 52:} . . 53: . . 54:var specialChars = regexp.MustCompile([{}/\\:\s.]) . . 55: . . 56:func clean(value string) string {(pprof)
OK, 我们找到一个耗时比较多的功能调用了
1.12s 48: parts = append(parts, clean(v))
这个地方就是耗时最多的地方了,也就是接下来我们应该去调优的代码区域了。我们先别急,因为这个代码段内嵌了一次clean方法的调用。
继续在(pprof) 后输入 list clean
,看是不是在clean出问题
(pprof) list cleanTotal: 1.42sROUTINE ======================== github.com/domac/playflame/stats.clean in /Users/lihaoquan/GoProjects/Playground/src/github.com/domac/playflame/stats/reporter.go 0 950ms (flat, cum) 66.90% of Total . . 52:} . . 53: . . 54:var specialChars = regexp.MustCompile([{}/\\:\s.]) . . 55: . . 56:func clean(value string) string { . 950ms 57: return specialChars.ReplaceAllString(value, "-") . . 58:}
没出意外的话,应该是 clean 方法使用不正确导致的,而且不正确的地方应该是下面的代码段:
specialChars.ReplaceAllString(value, "-")
这段代码引起了性能问题!我们着手调优吧。
代码修复前
var specialChars = regexp.MustCompile([{}/\\:\s.])func clean(value string) string { return specialChars.ReplaceAllString(value, "-")}
这段代码是把指定的特殊字符替换成‘-’,正则模块虽然灵活正则表达式比纯粹的文本匹配效率低,只是做简单文本替换的话,干脆自己写一个替换方法算了
改进后
func clean(value string) string { newStr := make([]byte, len(value)) for i := 0; i < len(value); i++ { switch c := value[i]; c { case '{', '}', '/', '\', ':', ' ', '\t', '.': newStr[i] = '-' default: newStr[i] = c } } return string(newStr)}
我们再观察基准测试报告的cpu调用分析:
$ go test -bench . -benchmem -cpuprofile prof.cpuBenchmarkAddTagsToName-4 1000000 1063 ns/op 448 B/op 15 allocs/opPASSok github.com/domac/playflame/stats 1.087s
对比上一次的测试,性能有了很大的提升:
(pprof) list cleanTotal: 1.02sROUTINE ======================== github.com/domac/playflame/stats.clean in /Users/lihaoquan/GoProjects/Playground/src/github.com/domac/playflame/stats/reporter.go 10ms 110ms (flat, cum) 10.78% of Total . . 48: } . . 49: . . 50: return strings.Join(parts, ".") . . 51:} . . 52: 10ms 10ms 53:func clean(value string) string { . 60ms 54: newStr := make([]byte, len(value)) . . 55: for i := 0; i < len(value); i++ { . . 56: switch c := value[i]; c { . . 57: case '{', '}', '/', '\', ':', ' ', '\t', '.': . . 58: newStr[i] = '-' . . 59: default: . . 60: newStr[i] = c . . 61: } . . 62: } . 40ms 63: return string(newStr) . . 64:}(pprof)
但我们还不能放松,我们看到其中一项指标: 15 allocs/op
我们功能调用的速度上去了,但对象内存分配好像也没得到改善啊,这怎么办?
我们继续深入下去, 既然源码分析不行,试试汇编代码:
(pprof)disasm......... . . a4cfb: MOVQ $0x0, 0(SP) . . a4d03: MOVQ 0x70(SP), AX . . a4d08: MOVQ AX, 0x8(SP) . . a4d0d: MOVQ 0x40(SP), AX . . a4d12: MOVQ AX, 0x10(SP) . . a4d17: MOVQ 0x48(SP), AX . . a4d1c: MOVQ AX, 0x18(SP) . 60ms a4d21: CALL runtime.slicebytetostring(SB) . . a4d26: MOVQ 0x20(SP), AX . . a4d2b: MOVQ 0x28(SP), CX . . a4d30: MOVQ AX, 0xb8(SP) . . a4d38: MOVQ CX, 0xc0(SP) . . a4d40: MOVQ 0x80(SP), BP . . a4d48: ADDQ $0x88, SP . . a4d4f: RET.........
我们在这里定位到 runtime.slicebytetostring(SB) 这里可能是引起内存分配问题的所在
runtime.slicebytetostring函数正是被函数bytes.(*Buffer).String函数调用的。它实现的功能是把元素类型为byte的切片转换为字符串
我们再详细看下代码究竟哪里涉及到字符串的转换行为
(pprof) list addTagsToNameTotal: 1.02sROUTINE ======================== github.com/domac/playflame/stats.addTagsToName in /Users/lihaoquan/GoProjects/Playground/src/github.com/domac/playflame/stats/reporter.go 40ms 770ms (flat, cum) 75.49% of Total . . 30: } . . 31:} . . 32: . . 33:func addTagsToName(name string, tags map[string]string) string { . . 34: var keyOrder []string . 10ms 35: if _, ok := tags["host"]; ok { . 10ms 36: keyOrder = append(keyOrder, "host") . . 37: } . 30ms 38: keyOrder = append(keyOrder, "endpoint", "os", "browser") . . 39: . . 40: parts := []string{name} 10ms 10ms 41: for _, k := range keyOrder { 10ms 40ms 42: v, ok := tags[k] . . 43: if !ok || v == "" { . . 44: parts = append(parts, "no-"+k) . . 45: continue . . 46: } 10ms 520ms 47: parts = append(parts, clean(v)) . . 48: } . . 49: 10ms 150ms 50: return strings.Join(parts, ".") . . 51:} . . 52: . . 53:func clean(value string) string { . . 54: newStr := make([]byte, len(value)) . . 55: for i := 0; i < len(value); i++ {(pprof)
留意上面的代码,为了拼接字符串,我们原方案是采用slice存放字符串元素,最后通过string.join()来拼接, 我们多次调用了append方法,而在go里面slice其实如果容量不够的话,就会触发分配,所以 针对这个思路,我们需要对代码的slice预分配容量,减少动态分配:
func addTagsToName(name string, tags map[string]string) string { keyOrder := make([]string, 0, 4) if _, ok := tags["host"]; ok { keyOrder = append(keyOrder, "host") } keyOrder = append(keyOrder, "endpoint", "os", "browser") parts := make([]string, 1, 5) parts[0] = name for _, k := range keyOrder { v, ok := tags[k] if !ok || v == "" { parts = append(parts, "no-"+k) continue } parts = append(parts, clean(v)) } return strings.Join(parts, ".")}
我们执行又一次的基准测试
$ go test -bench . -benchmem -cpuprofile prof.cpuBenchmarkAddTagsToName-4 3000000 527 ns/op 144 B/op 10 allocs/opPASSok github.com/domac/playflame/stats 2.142s
可以看到对象分配的性能上去了,但不明显,而且,耗时好像比上一次还多了。唉~~ 问题还没彻底解决。
再分析profile:
$ go tool pprof stats.test prof.cpuEntering interactive mode (type "help" for commands)(pprof) list addTagsToNameTotal: 1.86sROUTINE ======================== github.com/domac/playflame/stats.addTagsToName in /Users/lihaoquan/GoProjects/Playground/src/github.com/domac/playflame/stats/reporter.go 140ms 1.76s (flat, cum) 94.62% of Total . . 34:} . . 35: . . 36:func addTagsToName(name string, tags map[string]string) string { . . 37: // The format we want is: host.endpoint.os.browser . . 38: // if there's no host tag, then we don't use it. . 30ms 39: keyOrder := make([]string, 0, 4) 10ms 30ms 40: if _, ok := tags["host"]; ok { . . 41: keyOrder = append(keyOrder, "host") . . 42: } 10ms 10ms 43: keyOrder = append(keyOrder, "endpoint", "os", "browser") . . 44: . . 45: parts := make([]string, 1, 5) . . 46: parts[0] = name . . 47: for _, k := range keyOrder { 40ms 240ms 48: v, ok := tags[k] . . 49: if !ok || v == "" { . . 50: parts = append(parts, "no-"+k) . . 51: continue . . 52: } 50ms 820ms 53: parts = append(parts, clean(v)) . . 54: } . . 55: 30ms 630ms 56: return strings.Join(parts, ".") . . 57:} . . 58: . . 59:// clean takes a string that may contain special characters, and replaces these . . 60:// characters with a '-'. . . 61:func clean(value string) string {(pprof)
可以看到 return strings.Join(parts, “.”) 这里的时间比之前的还长!!这就是问题之一
parts = append(parts, clean(v)) 这里也是耗时比较多的,也是问题之一
我们一个一个来:
既然知道拼接字符串,除了把字符串装在数组里,再使用join的确很方便把字符串元素拼接,但调用次数很大的时候,可能会导致对象分配低效的问题。 这里我们决定采用缓存buffer来优化字符串拼接:
func addTagsToName(name string, tags map[string]string) string { keyOrder := make([]string, 0, 4) if _, ok := tags["host"]; ok { keyOrder = append(keyOrder, "host") } keyOrder = append(keyOrder, "endpoint", "os", "browser") buf := &bytes.Buffer{} buf.WriteString(name) for _, k := range keyOrder { buf.WriteByte('.') v, ok := tags[k] if !ok || v == "" { buf.WriteString("no-") buf.WriteString(k) continue } writeClean(buf, v) } return buf.String()}func writeClean(buf *bytes.Buffer, value string) { for i := 0; i < len(value); i++ { switch c := value[i]; c { case '{', '}', '/', '\', ':', ' ', '\t', '.': buf.WriteByte('-') default: buf.WriteByte(c) } }}
我们引入buff缓冲的支持,看下优化的效果
$ go test -bench . -benchmem -cpuprofile prof.cpuBenchmarkAddTagsToName-4 3000000 488 ns/op 160 B/op 2 allocs/opPASSok github.com/domac/playflame/stats 1.981s
不错。性能指标继续上去了,而且执行耗时下降了,CPU的问题算是解决了
我们多一个心眼,上面我们关注都是CPU调用性能,很有必要看看内存情况:
$ go test -bench . -benchmem -memprofile prof.memBenchmarkAddTagsToName-4 3000000 479 ns/op 160 B/op 2 allocs/opPASSok github.com/domac/playflame/stats 1.939s
生成prof.mem后,分析查看top10内存消耗排行榜:
$ go tool pprof --alloc_objects stats.test prof.memEntering interactive mode (type "help" for commands)(pprof) top107594956 of 7594956 total ( 100%) flat flat% sum% cum cum% 7594956 100% 100% 7594956 100% github.com/domac/playflame/stats.addTagsToName 0 0% 100% 7594956 100% github.com/domac/playflame/stats.BenchmarkAddTagsToName 0 0% 100% 7594956 100% runtime.goexit 0 0% 100% 7594956 100% testing.(B).launch 0 0% 100% 7594956 100% testing.(B).runN(pprof)
又是addTagsToName引起内存分配问题,只好列出那里消耗多:
(pprof) list addTagsToNameTotal: 7594956ROUTINE ======================== github.com/domac/playflame/stats.addTagsToName in /Users/lihaoquan/GoProjects/Playground/src/github.com/domac/playflame/stats/reporter.go 7594956 7594956 (flat, cum) 100% of Total . . 40: if _, ok := tags["host"]; ok { . . 41: keyOrder = append(keyOrder, "host") . . 42: } . . 43: keyOrder = append(keyOrder, "endpoint", "os", "browser") . . 44: 3848310 3848310 45: buf := &bytes.Buffer{} . . 46: buf.WriteString(name) . . 47: for _, k := range keyOrder { . . 48: buf.WriteByte('.') . . 49: . . 50: v, ok := tags[k] . . 51: if !ok || v == "" { . . 52: buf.WriteString("no-") . . 53: buf.WriteString(k) . . 54: continue . . 55: } . . 56: . . 57: writeClean(buf, v) . . 58: } . . 59: 3746646 3746646 60: return buf.String() . . 61:} . . 62: . . 63:// writeClean cleans value (e.g. replaces special characters with '-') and . . 64:// writes out the cleaned value to buf. . . 65:func writeClean(buf *bytes.Buffer, value string) {(pprof)
问题定为在buf := &bytes.Buffer{}
,我们之前用它优化了我们的字符串拼接,cpu是优化了,但每次调用都新建一个buf的话,内存其实没改善,还有什么其它的解决手段呢?
我们尝试使用对象池,把buffer对象池话
var bufPool = sync.Pool{ New: func() interface{} { return &bytes.Buffer{} },}func addTagsToName(name string, tags map[string]string) string { keyOrder := make([]string, 0, 4) if _, ok := tags["host"]; ok { keyOrder = append(keyOrder, "host") } keyOrder = append(keyOrder, "endpoint", "os", "browser") buf := bufPool.Get().(*bytes.Buffer) defer bufPool.Put(buf) buf.Reset() buf.WriteString(name) for _, k := range keyOrder { buf.WriteByte('.') v, ok := tags[k] if !ok || v == "" { buf.WriteString("no-") buf.WriteString(k) continue } writeClean(buf, v) } return buf.String()}
调试一下:
$ go test -bench . -benchmem -memprofile prof.memBenchmarkAddTagsToName-4 3000000 564 ns/op 48 B/op 1 allocs/opPASSok github.com/domac/playflame/stats 2.272s
调用也在正常了
(pprof) list addTagsToNameTotal: 4008802ROUTINE ======================== github.com/domac/playflame/stats.addTagsToName in /Users/lihaoquan/GoProjects/Playground/src/github.com/domac/playflame/stats/reporter.go 4008802 4008802 (flat, cum) 100% of Total . . 67: } . . 68: . . 69: writeClean(buf, v) . . 70: } . . 71: 4008802 4008802 72: return buf.String() . . 73:} . . 74: . . 75:// writeClean cleans value (e.g. replaces special characters with '-') and . . 76:// writes out the cleaned value to buf. . . 77:func writeClean(buf *bytes.Buffer, value string) {(pprof)
我们再生产新的火焰图:

从火焰图看到,我们的性能采用报告也在合理正常的范围!
总结
经过上面的一系列分析,我们日常开发应用程序后,一定要做好测试:千里之堤毁于蚁穴
代码中一个看起来很普通的地方,可能就是我们性能的瓶颈了。
日常开发原则
避免过早优化
尽量用快速迭代的方式进行开发,毕竟Go让我们在基准测试还是生产上对代码进行profile分析变得容易。加上go-torch极大帮助 我们快速定位有问题的代码。过早优化相对片面,建议先有功能,再不断完善。
避免在热点区域进行大量对象分配
对热点区域编写基准测试用例,可以使用 -benchmem 和 memory profile来观察是否我们频繁进行内存分配,因为分配的潜台词是会发生 GC,GC会很大程度上会有服务延迟的风险。
切忌对汇编代码谈虎色变
一般情况下,对象分配或者调用耗时的细节会体现在汇编出来的代码上,我们也不需要对汇编太惧怕,掌握基本的指令和操作符知识,我们很大程度 能把一些隐藏的问题揪出来。