(第一部分 机器学习基础)
第01章 机器学习概览
第02章 一个完整的机器学习项目(上)
第02章 一个完整的机器学习项目(下)
第03章 分类
第04章 训练模型
第05章 支持向量机
第06章 决策树
第07章 集成学习和随机森林
第08章 降维
(第二部分 神经网络和深度学习)
第9章 启动和运行TensorFlow
第10章 人工神经网络
第11章 训练深度神经网络(上)
第11章 训练深度神经网络(下)
第12章 设备和服务器上的分布式 TensorFlow
第13章 卷积神经网络
第14章 循环神经网络
第15章 自编码器
第16章 强化学习(上)
第16章 强化学习(下)
本章中,你会作为被一家地产公司雇佣的数据科学家,完整地学习一个项目。下面是主要步骤:
- 项目概述。
- 获取数据。
- 发现并可视化数据,发现规律。
- 为机器学习算法准备数据。
- 选择模型,进行训练。
- 微调模型。
- 给出解决方案。
- 部署、监控、维护系统。
使用真实数据
学习机器学习时,最好使用真实数据,而不是人工数据集。幸运的是,有上千个开源数据集可以进行选择,涵盖多个领域。以下是一些可以查找数据的资源:
流行的开源数据仓库:
UC Irvine Machine Learning Repository
Kaggle datasets
Amazon’s AWS datasets准入口(提供开源数据列表)
http://dataportals.org/
http://opendatamonitor.eu/
http://quandl.com/
- 其它列出流行开源数据仓库的网页:
Wikipedia’s list of Machine Learning datasets
Quora.com question
Datasets subreddit
本章,我们选择的是StatLib的加州房产价格数据集(见图2-1)。这个数据集是基于1990年加州普查的数据。数据已经有点老(1990年还能买一个湾区不错的房子),但是它有许多优点,利于学习,所以假设这个数据为最新的。为了便于教学,我们添加了一个分类属性,并除去了一些属性。
项目概览
欢迎来到机器学习房地产公司!你的第一个任务是利用加州普查数据,建立一个加州房价模型。这个数据包含每个分区组的人口、收入中位数、房价中位数等指标。
分区组是美国调查局发布样本数据的最小地理单位(一个分区通常有600到3000人)。我们将其简称为“分区”。
你的模型要利用这个数据进行学习,然后根据其它指标,预测任何分区的的房价中位数。
提示:你是一个有条理的数据科学家,你要做的第一件事是拿出你的机器学习项目清单。你可以使用附录B中的清单;这个清单适用于大多数的机器学习项目,但是你还是要确认它是否满足需求。在本章中,我们会检查许多清单上的项目,但是也会跳过一些简单的,有些会在后面的章节再讨论。
划定问题
询问老板的第一个问题应该是商业目标是什么?建立模型可能不是最终目标。公司要如何使用、并从模型受益?这非常重要,因为它决定了如何划定问题,要选择什么算法,评估模型性能的指标是什么,要花多少精力进行微调。
老板告诉你,你的模型的输出(一个区的房价中位数)会传给另一个机器学习系统(见图2-2),也有其它信号会传入后面的系统。这一整套系统可以确定对某个区投资值不值。确定投资与否非常重要,它直接影响利润。
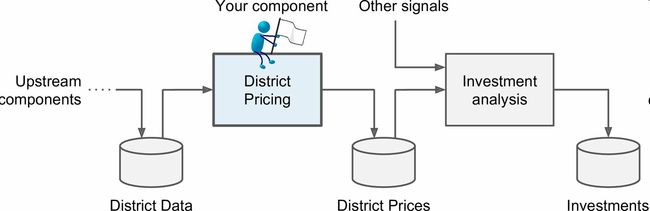
管道
一系列的数据处理组件被称为数据管道。管道在机器学习系统中很常见,因为有许多数据要处理和转换。
组件通常是异步运行的。每个组件吸纳进大量数据,进行处理,然后将数据传输到另一个数据容器中,而后管道中的另一个组件收入这个数据,然后输出,这个过程依次进行下去。每个组件都是独立的:组件间的接口只是数据容器。这样可以让系统更便于理解(记住数据流的图),不同的项目组可以关注于不同的组件。进而,如果一个组件失效了,下游的组件使用失效组件最后生产的数据,通常可以正常运行(一段时间)。这样就使整个架构相当健壮。
另一方面,如果没有监控,失效的组件会在不被注意的情况下运行一段时间。数据会受到污染,整个系统的性能就会下降。
下一个要问的问题是,现在的解决方案效果如何。老板通常会给一个参考性能,以及如何解决问题。老板说,现在分区的房价是靠专家手工估计的,专家队伍收集最新的关于一个区的信息(不包括房价中位数),他们使用复杂的规则进行估计。这种方法费钱费时间,而且估计结果不理想,误差率大概有15%。
Okay,有了这些信息,你就可以开始设计系统了。首先,你需要划定问题:监督或非监督,还是强化学习?这是个分类任务、回归任务,还是其它的?要使用批量学习还是线上学习?继续阅读之前,请暂停一下,尝试自己回答下这些问题。
你能回答出来吗?一起看下答案:很明显,这是一个典型的监督学习任务,因为你要使用的是有标签的训练样本(每个实例都有预定的产出,即分区的房价中位数)。并且,这是一个典型的回归任务,因为你要预测一个值。讲的更细些,这是一个多变量回归问题,因为系统要使用多个变量进行预测(要使用分区的人口,收入中位数等等)。在第一章中,你只是根据人均GDP来预测生活满意度,因此这是一个单变量回归问题。最后,没有连续的数据流进入系统,没有特别需求需要对数据变动作出快速适应。数据量不大可以放到内存中,因此批量学习就够了。
提示:如果数据量很大,你可以要么在多个服务器上对批量学习做拆分(使用MapReduce技术,后面会看到),或是使用线上学习。
选择性能指标
下一步是选择性能指标。回归问题的典型指标是均方根误差(RMSE)。均方根误差测量的是系统预测误差的标准差。例如,RMSE等于50000,意味着,68%的系统预测值位于实际值的50000以内。95%的预测值位于实际值的100000以内。等式2-1展示了计算RMSE的方法。
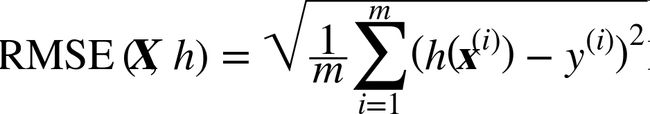
符号的含义
这个方程引入了一些常见的贯穿本书的机器学习符号:
- m是测量RMSE的数据集中的实例数量。
例如,如果用一个含有2000个分区的验证集求RMSE,则m = 2000。- x(i)是数据集第ith个实例的所有特征值(不包含标签)的矢量,y(i)是它的标签(这个实例的输出值)。
例如,如果数据集中的第一个分区位于经度–118.29°,纬度33.91°,有1416名居民,收入中位数是38372美元,房价中位数是$156400(不考虑其它特征),则有:
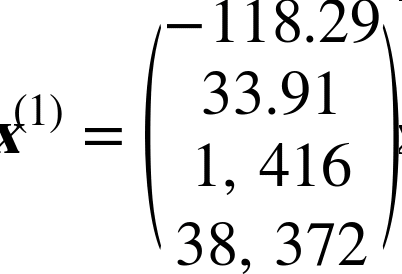
和,
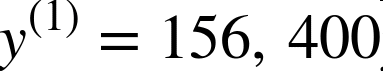
- X是包含数据集中所有实例的所有特征值(不包含标签)的矩阵。每一行是一个实例,第ith行是x(i)的转置,标记为(x(i))T。
例如,仍然是前面的第一区,矩阵X就是:

- h是系统的预测函数,也称为假设(hypothesis)。当系统收到一个实例的特征矢量x(i),就会输出这个实例的一个预测值ŷ(i) = h(x(i))(ŷ读作y-hat)。
例如,如果系统预测第一区的房价中位数是$158400,则ŷ(1) = h(x(1)) = 158400。预测误差是ŷ(1) – y(1) = 2000。
RMSE(X,h)是使用假设h在样本集上测量的损失函数。我们使用小写斜体表示标量值(例如m或y(1))和函数名(例如h),小写粗体表示矢量(例如x(i)),大写粗体表示矩阵(例如X)。(译者注:MarkDown表示粗体斜体太麻烦了,忽略字体。)
虽然大多数时候RMSE是回归任务可靠的性能指标,在有些情况下,你可能需要另外的函数。例如,假设存在许多异常的分区。此时,你可能需要使用绝对平均误差(Mean Absolute Error,也称作平均绝对偏差,见等式2-2):
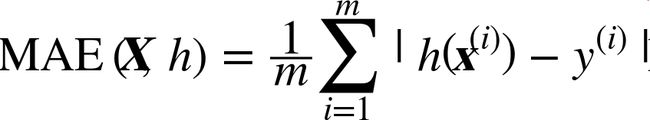
RMSE和MAE都是测量预测值和目标值两个矢量距离的方法。有多种测量距离的方法,或范数:
计算对应欧几里得范数的平方和的根(RMSE):这个距离介绍过。它也称作ℓ2范数,标记为// · //2(或只是// · //)。
计算对应于ℓ1(标记为// · //1)范数的绝对值之和(MAE)。有时,也称其为曼哈顿范数,因为它测量了城市中的两点,沿着矩形的边行走的距离。
-
更一般的,包含n个元素的矢量v的ℓk范数,定义成
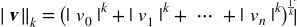
ℓ0只显示了这个矢量的基数(即,元素的个数),ℓ∞是矢量中最大的绝对值。 范数的指数越高,就越关注大的值而忽略小的值。这就是为什么RMSE比MAE对异常值更敏感。但是当异常值是指数分布的(类似正态曲线),RMSE就会表现很好。
核实假设
最后,最好列出并核对迄今(你或其他人)作出的假设。这样可以尽早发现严重的问题。例如,你的系统输出的分区房价,会传入到下游的机器学习系统,我们假设这些价格确实会被当做分区房价使用。但是如果下游系统实际上将价格转化成了分类(例如,便宜、中等、昂贵),然后使用这些分类,而不是使用价格。这样的话,获得准确的价格就不那么重要了,你只需要得到合适的分类。问题相应地就变成了一个分类问题,而不是回归任务。你可不想在一个回归系统上工作了数月,最后才发现真相。
幸运的是,在与下游系统主管探讨之后,你很确信他们需要的就是实际的价格,而不是分类。很好!整装待发,可以开始写代码了。
获取数据
开始动手。最后用Jupyter notebook完整地敲一遍示例代码。完整的代码位于https://github.com/ageron/handson-ml。
创建工作空间
首先,你需要安装Python。可能已经安装过了,没有的话,可以从官网下载https://www.python.org/。
接下来,需要为你的机器学习代码和数据集创建工作空间目录。打开一个终端,输入以下命令(在提示符$之后):
$ export ML_PATH="$HOME/ml" # 可以更改路径
$ mkdir -p $ML_PATH
还需要一些Python模块:Jupyter、NumPy、Pandas、Matplotlib和Scikit-Learn。如果所有这些模块都已经在Jupyter中运行了,你可以直接跳到下一节“下载数据”。如果还没安装,有多种方法可以进行安装(包括它们的依赖)。你可以使用系统的包管理系统(比如Ubuntu上的apt-get,或macOS上的MacPorts或HomeBrew),安装一个Python科学计算环境比如Anaconda,使用Anaconda的包管理系统,或者使用Python自己的包管理器pip,它是Python安装包(自从2.7.9版本)自带的。可以用下面的命令检测是否安装pip:
$ pip3 --version
pip 9.0.1 from [...]/lib/python3.5/site-packages (python 3.5)
你需要保证pip是近期的版本,至少高于1.4,以保障二进制模块文件的安装(也成为wheels)。要升级pip,可以使用下面的命令:
$ pip3 install --upgrade pip
Collecting pip
[...]
Successfully installed pip-9.0.1
创建独立环境
如果你希望在一个独立环境中工作(强烈推荐这么做,不同项目的库的版本不会冲突),用下面的pip命令安装virtualenv:
$ pip3 install --user --upgrade virtualenv Collecting virtualenv [...] Successfully installed virtualenv现在可以通过下面命令创建一个独立的Python环境:
$ cd $ML_PATH $ virtualenv env Using base prefix '[...]' New python executable in [...]/ml/env/bin/python3.5 Also creating executable in [...]/ml/env/bin/python Installing setuptools, pip, wheel...done.以后每次想要激活这个环境,只需打开一个终端然后哦输入:
$ cd $ML_PATH $ source env/bin/activate启动该环境时,使用pip安装的任何包都只安装于这个独立环境中,Python只会访问这些包(如果你希望Python能访问系统的包,创建环境时要使用包选项--system-site-)。更多信息,请查看virtualenv文档。
现在,你可以使用pip命令安装所有必需的模块和它们的依赖:
$ pip3 install --upgrade jupyter matplotlib numpy pandas scipy scikit-learn
Collecting jupyter
Downloading jupyter-1.0.0-py2.py3-none-any.whl
Collecting matplotlib
[...]
要检查安装,可以用下面的命令引入每个模块:
$ python3 -c "import jupyter, matplotlib, numpy, pandas, scipy, sklearn"
这个命令不应该有任何输出和错误。现在你可以用下面的命令打开Jupyter:
$ jupyter notebook
[I 15:24 NotebookApp] Serving notebooks from local directory: [...]/ml
[I 15:24 NotebookApp] 0 active kernels
[I 15:24 NotebookApp] The Jupyter Notebook is running at: http://localhost:8888/
[I 15:24 NotebookApp] Use Control-C to stop this server and shut down all
kernels (twice to skip confirmation).
Jupyter服务器现在运行在终端上,监听8888端口。你可以用浏览器打开http://localhost:8888/,以访问这个服务器(服务器启动时,通常就自动打开了)。你可以看到一个空的工作空间目录(如果按照先前的virtualenv步骤,只包含env目录)。
现在点击按钮New创建一个新的Python笔记本,选择合适的Python版本(见图2-3)。

这一步做了三件事:首先,在工作空间中创建了一个新的notebook文件Untitled.ipynb;第二,它启动了一个Jupyter的Python内核来运行这个notebook;第三,在一个新栏中打开这个notebook。接下来,点击Untitled,将这个notebook重命名为Housing(这会将ipynb文件自动命名为Housing.ipynb)。
notebook包含一组代码框。每个代码框可以放入可执行代码或格式化文本。现在,notebook只有一个空的代码框,标签是“In [1]:”。在框中输入print("Hello world!"),点击运行按钮(见图2-4)或按Shift+Enter。这会将当前的代码框发送到Python内核,运行之后会返回输出。结果显示在代码框下方。由于抵达了notebook的底部,一个新的代码框会被自动创建出来。从Jupyter的Help菜单中的User Interface Tour可以学习Jupyter的基本操作。

下载数据
一般情况下,数据是存储于关系型数据库(或其它常见数据库)中的多个表、文档、文件。要访问数据,你首先要有密码和登录权限,并要了解数据结构。但是在这个项目中,这一切要简单些:只要下载一个压缩文件,housing.tgz,它包含一个CSV文件housing.csv,含有所有数据。
你可以使用浏览器下载,运行tar xzf housing.tgz解压提取出csv文件,但是更好的办法是写一个小函数来做这件事。如果数据变动频繁,这么做是非常好的,因为可以让你写一个小脚本随时获取最新的数据(或者创建一个定时任务来做)。如果你想在多台机器上安装数据集,获取数据自动化也是非常好的。
下面是获取数据的函数:
import os
import tarfile
from six.moves import urllib
DOWNLOAD_ROOT = "https://raw.githubusercontent.com/ageron/handson-ml/master/"
HOUSING_PATH = "datasets/housing"
HOUSING_URL = DOWNLOAD_ROOT + HOUSING_PATH + "/housing.tgz"
def fetch_housing_data(housing_url=HOUSING_URL, housing_path=HOUSING_PATH):
if not os.path.isdir(housing_path):
os.makedirs(housing_path)
tgz_path = os.path.join(housing_path, "housing.tgz")
urllib.request.urlretrieve(housing_url, tgz_path)
housing_tgz = tarfile.open(tgz_path)
housing_tgz.extractall(path=housing_path)
housing_tgz.close()
现在,当你调用fetch_housing_data(),就会在工作空间创建一个datasets/housing目录,下载housing.tgz文件,提取出housing.csv。
然后使用Pandas加载数据。还是用一个小函数来加载数据:
import pandas as pd
def load_housing_data(housing_path=HOUSING_PATH):
csv_path = os.path.join(housing_path, "housing.csv")
return pd.read_csv(csv_path)
这个函数会返回一个包含所有数据的Pandas DataFrame对象。
快速查看数据结构
使用DataFrame的head()方法查看该数据集的顶部5行(见图2-5)。
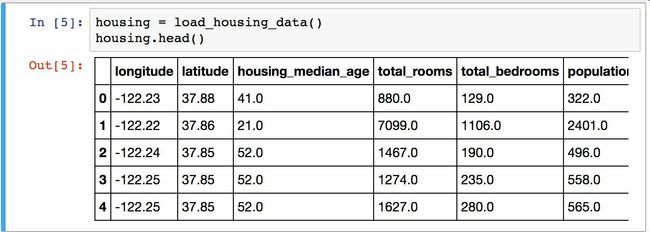
每一行都表示一个分区。共有10个属性(截图中可以看到6个):经度、维度、房屋年龄中位数、总房间数、卧室数量、人口数、家庭数、收入中位数、房屋价值中位数、大海距离。
info()方法可以快速查看数据的描述,包括总行数、每个属性的类型和非空值的数量(见图2-6)。
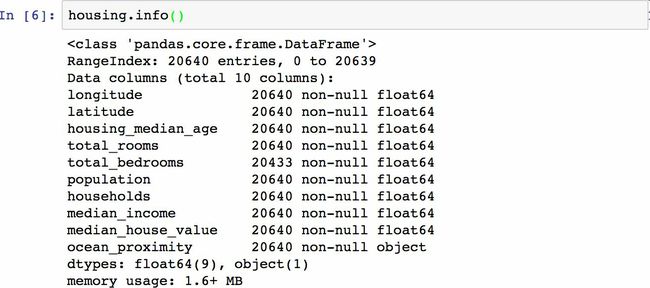
数据集中共有20640个实例,按照机器学习的标准这个数据量很小,但是非常适合入门。总房间数只有20433个非空值,意味着207个分区缺少这个值。后面要对它进行处理。
所有的属性都是数值的,除了大海距离这项。它的类型是对象,因此可以包含任意Python对象,但是因为是从CSV文件加载的,所以必然是文本。当查看顶部的五行时,你可能注意到那一列的值是重复的,意味着它可能是一个分类属性。可以使用value_counts()方法查看都有什么类型,每个类都有多少分区:
>>> housing["ocean_proximity"].value_counts()
<1H OCEAN 9136
INLAND 6551
NEAR OCEAN 2658
NEAR BAY 2290
ISLAND 5
Name: ocean_proximity, dtype: int64
再来看其它字段。describe()方法展示了数值属性的概括(见图2-7)。
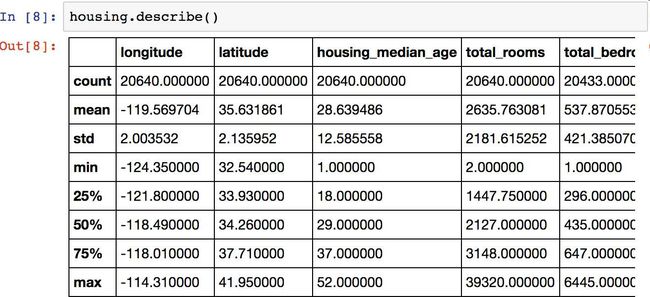
count、mean、min和max几行的意思很明了。注意,空值被忽略了(所以,卧室总数是20433而不是20640)。std是标准差(揭示数值的分散度)。25%、50%、75%展示了对应的分位数:每个分位数指明小于这个值,且指定分组的百分比。例如,25%的分区的房屋年龄中位数小于18,而50%的小于29,75%的小于37。这些值通常称为25th分位数(或1st四分位数),中位数,75th分位数(3rd四分位数)。
另一种快速了解数据类型的方法是画出每个数值属性的柱状图。柱状图(的纵轴)展示了特定范围的实例的个数。你还可以一次给一个属性画图,或对完整数据集调用hist()方法,后者会画出每个数值属性的柱状图(见图2-8)。例如,你可以看到略微超过800个分区的median_house_value值差不多等于$500000。
%matplotlib inline # only in a Jupyter notebook
import matplotlib.pyplot as plt
housing.hist(bins=50, figsize=(20,15))
plt.show()
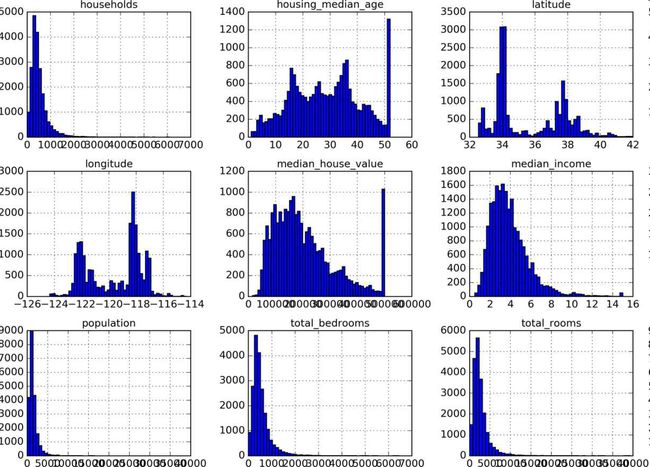
笔记:hist()方法依赖于Matplotlib,后者依赖于用户指定的图形后端以打印到屏幕上。因此在画图之前,你要指定Matplotlib要使用的后端。最简单的方法是使用Jupyter的魔术命令%matplotlib inline。它会告诉Jupyter设定好Matplotlib,以使用Jupyter自己的后端。绘图就会在notebook中渲染了。注意在Jupyter中调用show()不是必要的,因为代码框执行后Jupyter会自动展示图像。
注意柱状图中的一些点:
首先,收入中位数貌似不是美元(USD)。与数据采集团队交流之后,你被告知数据是经过缩放调整的,过高收入中位数的会变为15(实际为15.0001),过低的会变为5(实际为0.4999)。在机器学习中对数据进行预处理很正常,不一定是问题,但你要明白数据是如何计算出来的。
房屋年龄中位数和房屋价值中位数也被设了上线。后者可能是个严重的问题,因为它是你的目标属性(你的标签)。你的机器学习算法可能学习到价格不会超出这个界限。你需要与下游团队核实,这是否会成为问题。如果他们告诉你他们需要明确的预测值,即价格可以超过500000美元,你则有两个选项:
a. 对于设了上限的标签,重新收集合适的标签;
b. 将这些分区从训练集移除(也从测试集移除,因为若房价超出$500000,你的系统就会被差评)。这些属性值有不同的量度。我们会在本章后面讨论特征缩放。
最后,许多柱状图的尾巴很长:相较于左边,它们在中位数的右边延伸过远。对于某些机器学习算法,这会使检测规律变得更难些。我们会在后面尝试转换处理这些属性,使其变为正太分布。
希望你现在对要处理的数据有一定了解了。
警告:稍等!再你进一步查看数据之前,你需要创建一个测试集,放在一旁,再也不看。
创建测试集
在这个阶段就分割数据,听起来很奇怪。毕竟,你只是简单快速地查看了数据而已,你需要再仔细调查下数据以决定使用什么算法。这么想是对的,但是人类的大脑是一个神奇的发现规律的系统,这意味着大脑非常容易发生过拟合:如果你查看了测试集,就会不经意地按照测试集中的规律来选择某个特定的机器学习模型。再当你使用测试集来评估误差率时,就会导致评估过于乐观,而实际部署的系统表现就会差。这称为数据透视偏差。
理论上,创建测试集很简单:只要随机挑选一些实例,一般是数据集的20%,放到一边:
import numpy as np
def split_train_test(data, test_ratio):
shuffled_indices = np.random.permutation(len(data))
test_set_size = int(len(data) * test_ratio)
test_indices = shuffled_indices[:test_set_size]
train_indices = shuffled_indices[test_set_size:]
return data.iloc[train_indices], data.iloc[test_indices]
然后可以像下面使用这个函数:
>>> train_set, test_set = split_train_test(housing, 0.2)
>>> print(len(train_set), "train +", len(test_set), "test")
16512 train + 4128 test
这个方法可行,但是并不完美:如果再次运行程序,就会产生一个不同的测试集!多次运行之后,你(或你的机器学习算法)就会得到整个数据集,这是需要避免的。
解决的办法之一是保存第一次运行得到的测试集,并在随后的过程加载。另一种方法是在调用np.random.permutation()之前,设置随机数生成器的种子(比如np.random.seed(42)),以产生总是相同的混合指数(shuffled indices)。
但是如果获取更新后的数据集,这两个方法都会失效。一个通常的解决办法是使用每个实例的识别码,以判定是否这个实例是否应该放入测试集(假设实例有单一且不变的识别码)。例如,你可以每个实例识别码的哈希值,只保留其最后一个字节,如果值小于等于51(约为256的20%),就将其放入测试集。这样可以保证在多次运行中,测试集保持不变,即使更新了数据集。新的测试集会包含新实例中的20%,但不会有之前位于训练集的实例。下面是一种可用的方法:
import hashlib
def test_set_check(identifier, test_ratio, hash):
return hash(np.int64(identifier)).digest()[-1] < 256 * test_ratio
def split_train_test_by_id(data, test_ratio, id_column, hash=hashlib.md5):
ids = data[id_column]
in_test_set = ids.apply(lambda id_: test_set_check(id_, test_ratio, hash))
return data.loc[~in_test_set], data.loc[in_test_set]
不过,房产数据集没有识别码这一列。最简单的方法是使用行索引作为ID:
housing_with_id = housing.reset_index() # adds an `index` column
train_set, test_set = split_train_test_by_id(housing_with_id, 0.2, "index")
如果使用行索引作为唯一识别码,你需要保证新数据放到现有数据的尾部,且没有行被深处。如果做不到,则可以用最稳定的特征来创建唯一识别码。例如,一个区的维度和经度在几百万年之内是不变的,所以可以将两者结合成一个ID:
housing_with_id["id"] = housing["longitude"] * 1000 + housing["latitude"]
train_set, test_set = split_train_test_by_id(housing_with_id, 0.2, "id")
Scikit-Learn提供了一些函数,可以用多种方式将数据集分割成多个子集。最简单的函数是train_test_split,它的作用和之前的函数split_train_test很像,并带有其它一些功能。首先,它有一个random_state参数,可以设定前面讲过的随机生成器种子;第二,你可以将种子传递到多个行数相同的数据集,可以在相同的索引上分割数据集(这个功能非常有用,比如你有另一个DataFrame作为标签):
from sklearn.model_selection import train_test_split
train_set, test_set = train_test_split(housing, test_size=0.2, random_state=42)
目前为止,我们采用的都是纯随机的取样方法。当你的数据集很大时(尤其是和属性数相比),这通常可行;但如果数据集不大,就会有采样偏差的风险。当一个调查公司想要对1000个人进行调查,它们不是在电话亭里随机选1000个人出来。调查公司要保证这1000个人对人群整体有代表性。例如,美国人口的51.3%是女性,48.7%是男性。所以在美国,严谨的调查需要保证样本也是这个比例:513名女性,487名男性。这称作分层采样(stratified sampling):将人群分成均匀的子分组,称为分层,从每个分层取出合适数量的实例,以保证测试集对总人数有代表性。如果调查公司采用纯随机采样,会有12%的概率导致采样偏差:女性人数少于49%,或多余54%。不管发生那种情况,调查结果都会严重偏差。
假设专家告诉你,收入中位数是预测房价中位数非常重要的属性。你可能想要保证测试集可以代表整体数据集中的多种收入分类。因为收入中位数是一个连续的数值属性,你首先需要创建一个收入分类属性。再仔细地看一下收入中位数的柱状图(图2-9):
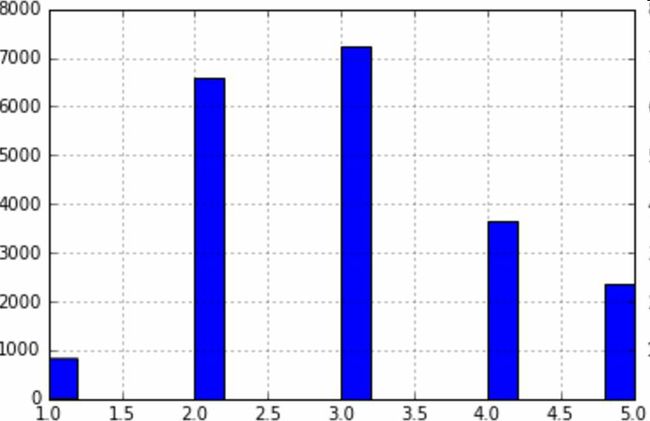
大多数的收入中位数的值聚集在2-5(一万美元),但是一些收入中位数会超过6。数据集中的每个分层都要有足够的实例位于你的数据中,这点很重要。否则,对分层重要性的评估就会有偏差。这意味着,你不能有过多的分层,且每个分层都要足够大。后面的代码通过将收入中位数除以1.5(以限制收入分类的数量),创建了一个收入分类属性,用ceil对值舍入(以产生离散的分类),然后将所有大于5的分类归入到分类5:
housing["income_cat"] = np.ceil(housing["median_income"] / 1.5)
housing["income_cat"].where(housing["income_cat"] < 5, 5.0, inplace=True)
现在,就可以根据收入分类,进行分层采样。你可以使用Scikit-Learn的StratifiedShuffleSplit类:
from sklearn.model_selection import StratifiedShuffleSplit
split = StratifiedShuffleSplit(n_splits=1, test_size=0.2, random_state=42)
for train_index, test_index in split.split(housing, housing["income_cat"]):
strat_train_set = housing.loc[train_index]
strat_test_set = housing.loc[test_index]
检查下结果是否符合预期。你可以在完整的房产数据集中查看收入分类比例:
>>> housing["income_cat"].value_counts() / len(housing)
3.0 0.350581
2.0 0.318847
4.0 0.176308
5.0 0.114438
1.0 0.039826
Name: income_cat, dtype: float64
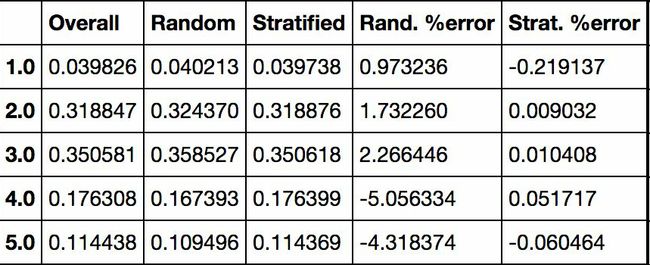
使用相似的代码,还可以测量测试集中收入分类的比例。图2-10对比了总数据集、分层采样的测试集、纯随机采样测试集的收入分类比例。可以看到,分层采样测试集的收入分类比例与总数据集几乎相同,而随机采样数据集偏差严重。
现在,你需要删除income_cat属性,使数据回到初始状态:
for set in (strat_train_set, strat_test_set):
set.drop(["income_cat"], axis=1, inplace=True)
我们用了大量时间来生成测试集的原因是:测试集通常被忽略,但实际是机器学习非常重要的一部分。还有,生成测试集过程中的许多思路对于后面的交叉验证讨论是非常有帮助的。接下来进入下一阶段:数据探索。
数据探索和可视化、发现规律
目前为止,你只是快速查看了数据,对要处理的数据有了整体了解。现在的目标是更深的探索数据。
首先,保证你将测试集放在了一旁,只是研究训练集。另外,如果训练集非常大,你可能需要再采样一个探索集,保证操作方便快速。在我们的案例中,数据集很小,所以可以在全集上直接工作。创建一个副本,以免损伤训练集:
housing = strat_train_set.copy()
地理数据可视化
因为存在地理信息(纬度和经度),创建一个所有分区的散点图来数据可视化是一个不错的主意(图2-11):
housing.plot(kind="scatter", x="longitude", y="latitude")

这张图看起来很像加州,但是看不出什么特别的规律。将alpha设为0.1,可以更容易看出数据点的密度(图2-12):
housing.plot(kind="scatter", x="longitude", y="latitude", alpha=0.1)

现在看起来好多了:可以非常清楚地看到高密度区域,湾区、洛杉矶和圣迭戈,以及中央谷,特别是从萨克拉门托到弗雷斯诺。
通常来讲,人类的大脑非常善于发现图片中的规律,但是需要调整可视化参数使规律显现出来。
现在来看房价(图2-13)。每个圈的半径表示分区的人口(选项s),颜色代表价格(选项c)。我们用预先定义的颜色图(选项cmap)jet,它的范围是从蓝色(低价)到红色(高价):
housing.plot(kind="scatter", x="longitude", y="latitude", alpha=0.4,
s=housing["population"]/100, label="population",
c="median_house_value", cmap=plt.get_cmap("jet"), colorbar=True,
)
plt.legend()
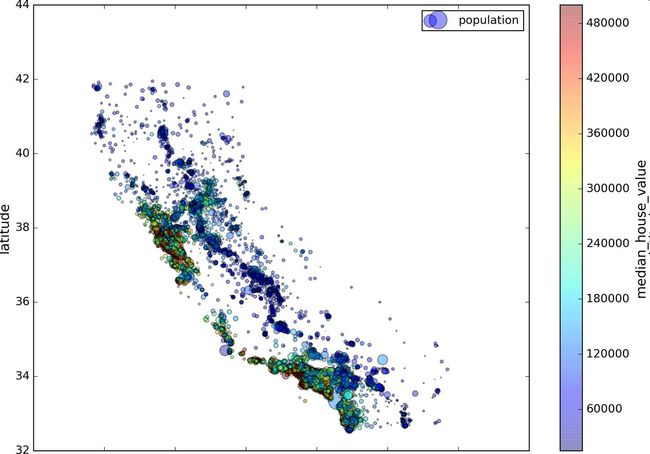
这张图说明房价和位置(比如,靠海)和人口密度联系密切,这点你可能早就知道。可以使用聚类算法来检测主要的聚集,用一个新的特征值测量聚集中心的距离。海洋距离属性也可能有用,尽管北加州海岸区域的房价并不高,所以这不是一个简单的规则。
查找关联
因为数据集并不是非常大,你可以很容易地使用corr()方法计算出每对属性间的标准相关系数(也称作皮尔逊相关系数):
corr_matrix = housing.corr()
现在来看下每个属性和房价中位数的关联度:
>>> corr_matrix["median_house_value"].sort_values(ascending=False)
median_house_value 1.000000
median_income 0.687170
total_rooms 0.135231
housing_median_age 0.114220
households 0.064702
total_bedrooms 0.047865
population -0.026699
longitude -0.047279
latitude -0.142826
Name: median_house_value, dtype: float64
相关系数的范围是-1到1。当接近1时,意味强正相关;例如,当收入中位数增加时,房价中位数也会增加。当相关系数接近-1时,意味强负相关;你可以看到,纬度和房价中位数有轻微的负相关性(即,越往北,房价越可能降低)。最后,相关系数接近0,意味没有线性相关性。图2-14展示了相关系数在横轴和纵轴之间的不同图形。
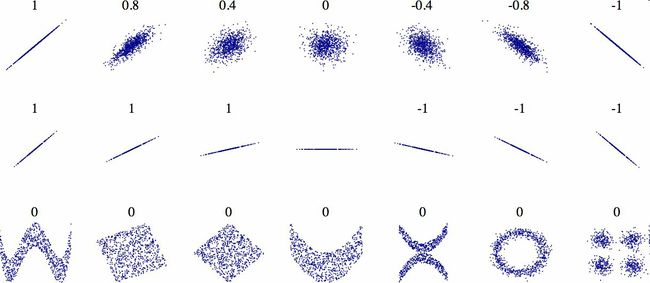
警告:相关系数只测量线性关系(如果x上升,y则上升或下降)。相关系数可能会完全忽略非线性关系(即,如果x接近0,则y值会变高)。在前面的计算结果中,底部的许多行的相关系数接近于0,尽管它们的轴并不独立:这些就是非线性关系的例子。另外,第二行的相关系数等于1或-1;这和斜率没有任何关系。例如,你的身高(单位是英寸)与身高(单位是英尺或纳米)的相关系数就是1。
另一种检测属性间相关系数的方法是使用Pandas的scatter_matrix函数,它能画出每个数值属性对每个其它数值属性的图。因为现在共有11个数值属性,你可以得到112=121张图,在一页上画不下,所以只关注几个和房价中位数最有可能相关的属性(图2-15):
from pandas.tools.plotting import scatter_matrix
attributes = ["median_house_value", "median_income", "total_rooms",
"housing_median_age"]
scatter_matrix(housing[attributes], figsize=(12, 8))

如果pandas将每个变量对自己作图,主对角线(左上到右下)都会是直线图。所以Pandas展示的是每个属性的柱状图(也可以是其它的,请参考Pandas文档)。
最有希望用来预测房价中位数的属性是收入中位数,因此将这张图放大(图2-16):
housing.plot(kind="scatter", x="median_income",y="median_house_value",
alpha=0.1)
这张图说明了几点。首先,相关性非常高;可以清晰地看到向上的趋势,并且数据点不是非常分散。第二,我们之前看到的最高价,清晰地呈现为一条位于500000美元的水平线。这张图也呈现了一些不是那么明显的直线:一条位于450000美元的直线,一条位于350000美元的直线,一条在$280000的线,和一些更靠下的线。你可能希望去除对应的分区,以防止算法重复这些巧合。
属性组合试验
希望前面的一节能教给你一些探索数据、发现规律的方法。你发现了一些数据的巧合,需要在给算法提供数据之前,将其去除。你还发现了一些属性间有趣的关联,特别是目标属性。你还注意到一些属性具有长尾分布,因此你可能要将其进行转换(例如,计算其log对数)。当然,不同项目的处理方法各不相同,但大体思路是相似的。
给算法准备数据之前,你需要做的最后一件事是尝试多种属性组合。例如,如果你不知道某个分区有多少户,该分区的总房间数就没什么用。你真正需要的是每户有几个房间。相似的,总卧室数也不重要:你可能需要将其与房间数进行比较。每户的人口数也是一个有趣的属性组合。让我们来创建这些新的属性:
housing["rooms_per_household"] = housing["total_rooms"]/housing["households"]
housing["bedrooms_per_room"] = housing["total_bedrooms"]/housing["total_rooms"]
housing["population_per_household"]=housing["population"]/housing["households"]
现在,再来看相关矩阵:
>>> corr_matrix = housing.corr()
>>> corr_matrix["median_house_value"].sort_values(ascending=False)
median_house_value 1.000000
median_income 0.687170
rooms_per_household 0.199343
total_rooms 0.135231
housing_median_age 0.114220
households 0.064702
total_bedrooms 0.047865
population_per_household -0.021984
population -0.026699
longitude -0.047279
latitude -0.142826
bedrooms_per_room -0.260070
Name: median_house_value, dtype: float64
看起来不错!与总房间数或卧室数相比,新的bedrooms_per_room属性与房价中位数的关联更强。显然,卧室数/总房间数的比例越低,房价就越高。每户的房间数也比分区的总房间数的更有信息,很明显,房屋越大,房价就越高。
这一步的数据探索不必非常完备,此处的目的是有一个正确的开始,快速发现规律,以得到一个合理的原型。但是这是一个交互过程:一旦你得到了一个原型,并运行起来,你就可以分析它的输出,进而发现更多的规律,然后再回到数据探索这步。
为机器学习算法准备数据
现在来为机器学习算法准备数据。不要手工来做,你需要写一些函数,理由如下:
函数可以让你在任何数据集上(比如,你下一次获取的是一个新的数据集)方便地进行重复数据转换。
你能慢慢建立一个转换函数库,可以在未来的项目中复用。
在将数据传给算法之前,你可以在实时系统中使用这些函数。
这可以让你方便地尝试多种数据转换,查看那些转换方法结合起来效果最好。
但是,还是先回到清洗训练集(通过再次复制strat_train_set),将预测量和标签分开,因为我们不想对预测量和目标值应用相同的转换(注意drop()创建了一份数据的备份,而不影响strat_train_set):
housing = strat_train_set.drop("median_house_value", axis=1)
housing_labels = strat_train_set["median_house_value"].copy()
(第一部分 机器学习基础)
第01章 机器学习概览
第02章 一个完整的机器学习项目(上)
第02章 一个完整的机器学习项目(下)
第03章 分类
第04章 训练模型
第05章 支持向量机
第06章 决策树
第07章 集成学习和随机森林
第08章 降维
(第二部分 神经网络和深度学习)
第9章 启动和运行TensorFlow
第10章 人工神经网络
第11章 训练深度神经网络(上)
第11章 训练深度神经网络(下)
第12章 设备和服务器上的分布式 TensorFlow
第13章 卷积神经网络
第14章 循环神经网络
第15章 自编码器
第16章 强化学习(上)
第16章 强化学习(下)