斗地主的深度学习方案
原论文出处:
https://openreview.net/pdf?id=rJzoujRct7&utm_source=wechat_session&utm_medium=social&utm_oi=40
中文另外一个翻译版本
https://kknews.cc/zh-sg/news/5z8nj36.html
摘要
最近深度神经网络已经取得了超越人类的成绩,例如围棋,国际象棋,日本象棋。 与围棋相比,斗地主是一种非完美信息博奕(有不公开的信息,随机)多轮合作和竞争的游戏。它是当前国内广泛流行的游戏。我介绍一种使用卷积神经网络的玩斗地主的方法。无需任何搜索,该神经网络击败了最好的AI程序,击败了最好的业余玩家。
介绍
斗地主是一种易学难精的扑克游戏。它在腾讯游戏平台的日活量达到1.54千万。与围棋相比,斗地主属于非完美信息博奕游戏,初始手牌完全是随机的。三个人的游戏中,游戏玩家每局都拿到不同的手牌,并且他不知道另外两名玩家的手牌。三名玩家中,要确定1名地主,2名农民。农民需要互相配合才能打败地主。CNN(卷积神经网络)是比较好的一种解决AI游戏的方法,我们选用CNN是基于以下的理由:
- CNN 在完美博奕中已经超越人类。
- 斗地主中牌型有大小之分。例如上家出3,4,5,6,7; 玩家可以出4,5,6,7,8; 这是符合出牌规则的。但是反过来就不行,例如上家出4,5,6,7,8.那么玩家出3,4,5,6,7就不符合规则了。
目前为止,还没有斗地主的卷积神经网络程序。在斗地主这种非完美博奕中,CNN能否可以有比较好的表现仍然有待证明。在做决定时结局是模糊不清的,这一点上斗地主与围棋是一样的。和围棋一样,斗地主很难评估在众多选择中,哪一个选择价格最高。由于斗地主是有队友的,第一个问题是要教会神经网络如何配合,如何帮助队友打完手牌。另一个我们感兴趣的问题,神经网络是否能够以人类专家的逻辑去分析。DeepRocket是我们开发的取得相当成绩的神经网络。我们证明了这个神经网络可以配合和推理。在下一节,我们将介绍相关的神经网络。在第3节介绍论文中用到的关键述语。第4节将介绍具体组件,包括出牌网络,带牌网络。第5节展示如何做实现以及它与之前的AI和人类作比较。最后第6节描术了它有什么问题需要改善。
2 目前为止,Libratus 和DeepStack是最好的人工智能程序。(其它不重要,省略了)
3 斗地主术语
当前玩家:是指第一人称的这位玩家。
下家:是指当前玩家的下一位玩家。
上家:是指当前玩家的上一位玩家,斗地主只有3人玩,也就是下下家了。
地主:是指抢地主时抢分数最高的那位。
农民1:是指地主的下家
农民2:是指地主的上家
地主牌:是指最后三张,交给地主的牌
一轮:是指3位玩家各出一次。例如:”3,3;9,9;pass”就是一轮。
分类:是指所有合法的牌型,例如一对,三带一是合法的,33345是不合法的。
主牌和带牌:三带一张,三带一对,飞机,四带二,这些牌型才会有带牌,比如3331,三个3是主牌,1是带牌。
分组:是指不同分类分隔,例如 334567,分组成3,34567这两个分类。
主动出牌:是指玩家可以出任意的牌。例如斗地主出的第一手牌。又比如你出了王炸之后所有人都Pass, 这时你可以出手上的任何一手牌,这时称为主动出牌。
被动出牌:是指你要出什么牌,要取决于上一手的出牌。例如,上家出3,4,5,6,7;你只能出顺子或者炸弹。
4 DeepRocket 基础网络
DeepRocket系统包括三部分,抢地主模块,策略网络,带牌网络。开始游戏时,先调用抢地主模块,它输出分数用来决定是否抢地主。在出牌前调用策略网络,它将输出主牌。如果还需要带牌,那么还需要调用带牌网络。如下图所示:
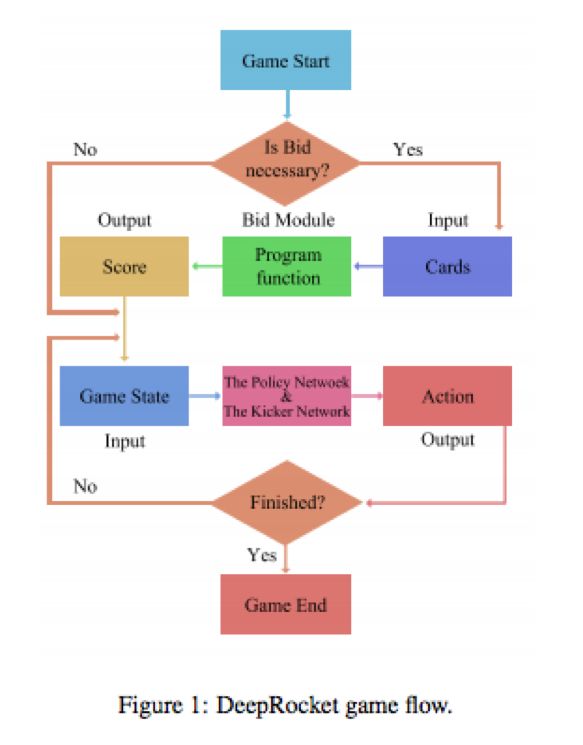
- 游戏开始
- 是否抢地主
- 不抢时进入出牌阶段。
- 抢地主时,发三张地主牌。
- 出牌时调用策略网络。
- 根据策略网络返回值决定打什么牌。
策略网络和带牌网络
4.1 抢地主模块
首先,在开始打牌之前,需要确定谁是地主,我们设计了这个模块用于决定是否抢地主。这个模块是基于代码逻辑来实现的,像人类的专家一样,主要考虑手上的控制牌例如大小王,2,A的个数,以及组合牌的情况,例如顺子,飞机多不多。
但事实上,也可以使用简单神经网络进行训练,输入数据为起手牌,标签为是否抢地主,0表示不抢,1表示抢。
从以往的打牌数据中,收集抢地主以后,打牌结果是输或者是赢。就可以训练出来。
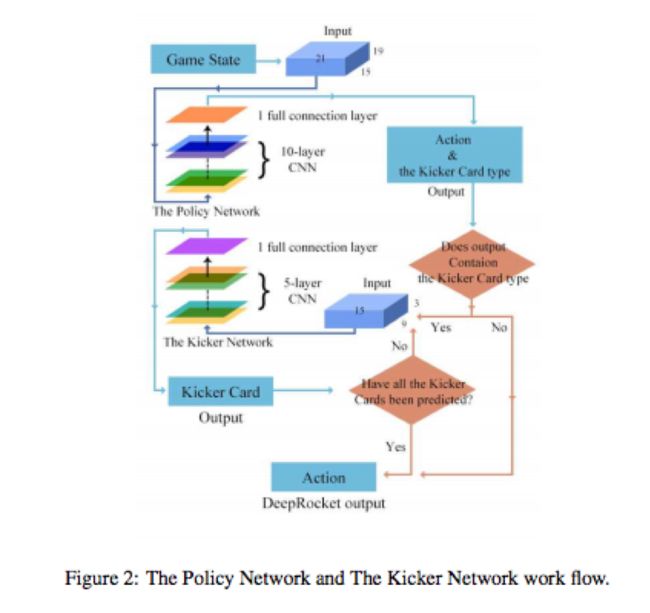
4.2 策略网络
像AlphaGo一样,我们使用监督学习来预测人类专家的行为。策略网络包含了10层CNN和1 个使用Relu激活函数的全连接层。最后一层使用Softmax激活函数来指出所有合法的出牌的概率分布。输入的数据中包括了游戏的状态,用于表示当前状态是抢地主状态还是策略出牌的状态。策略网络是基于state-action对 (s,a)样例来训练的。我们使用了8百万条数据进行策略网络进行训练。一条数据表达了一局完整的游戏,它可以分解成多个state-action对。它可能是几轮到20多轮,这个轮数取决于游戏记录的长度。例如:
扑克牌:
4456777889JKKAA2B;
335567899TTJJKAA2;
4456689TTJQQQK22S
地主牌:33Q
游戏过程:0,33;1,55;2,66,0,77,1,aa;1,6;2,T;0,j;1,k;0,2;2,S;2,44;0,KK;2,22;2,89TJQK;2,QQ;0,AA;0,56789;1,789TJ;1,3;2,5
如果我想训练地主下家的打牌习惯,打牌过程就需要分解成下表所示的state-action对。
下表显示用于训练地主下家角色的state-action对,一局牌的出牌过程:

- 第一轮:地主出一对3,这时玩家需要出一对5
- 第二轮: 地主出一对3,玩家出一对5,地主上家出一对7; 这时玩家出一对A
- 第三轮:所有人Pass之后,玩家出一张6
- 第四轮:地主下家出一张10,地主出一张J, 这时玩家出一张K
0:表示地主,1:表示地主下家,2:表示地主下家
策略网络的输入数据是一个15X19X21的三维二进制tensor.(我们使用X ,Y, Z来表示这三维数据)
X维数据表示手牌的点数,从3,4,5,6,7,8,9,T,J,Q,K,A,2,S,B 分别表示3到大王,共15位。
Y维数据表示各个牌型的情况:单张,一对,三条,四条, 连对,顺子,三带一单,三带一对,2飞机带单,2飞机带对,飞机不带牌,炸弹,王炸, 3飞机带单,3飞机带对, 4飞机带单,4飞机带对, 5飞机带单 等共19位。
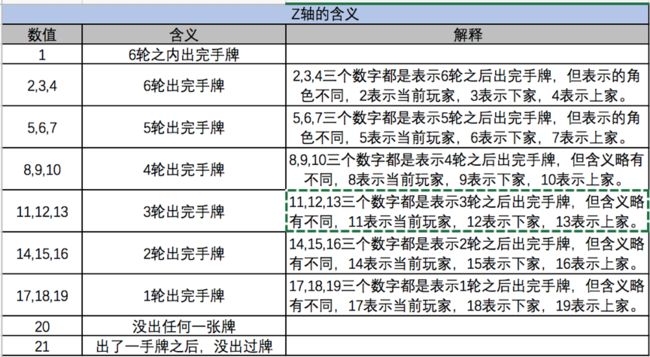
Z维数据表示每轮的顺序信息,这是用AlphaGo模型中学来的设计。为了统一长度,统一使用了21位数组, Z维数据用于表示最近的6轮的信息, 如下表所示。
经过模型测试,发现512个滤波器是最为稳定的,经过重复测试,使用不同的学习步长,发现10层CNN性能最好.
策略网络输入309种决策概率,然后我们加上带牌网络到DeepRocket中,请参考table3.
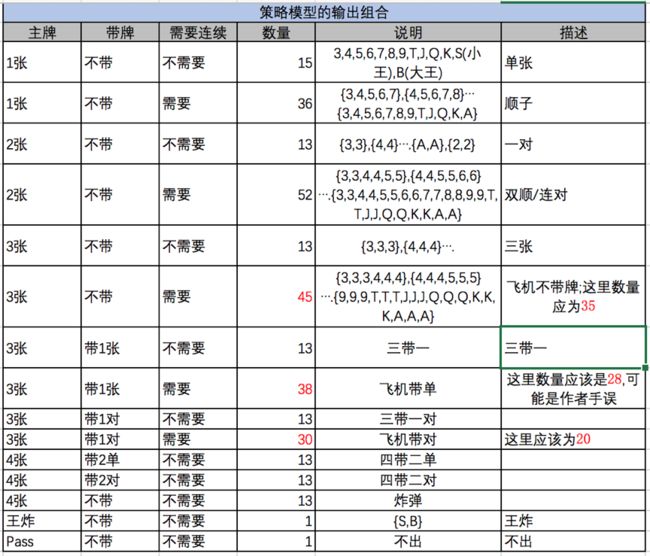
值得注意的是,一手牌出牌的数量最大为20,这个数值限制了分类的个数。
上表中,原作者可能手误,也可能把2也算进三张中去,导致数量不准确。事实上1,1,1,2,2,2
是不能构成飞机的。
为了易于理解,把上面单张,一对,三张,四张,顺子,飞机的所有牌型穷举出来。
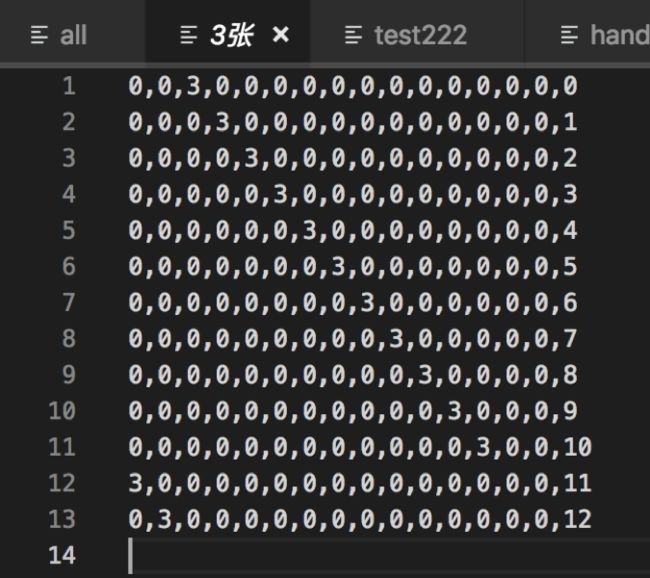

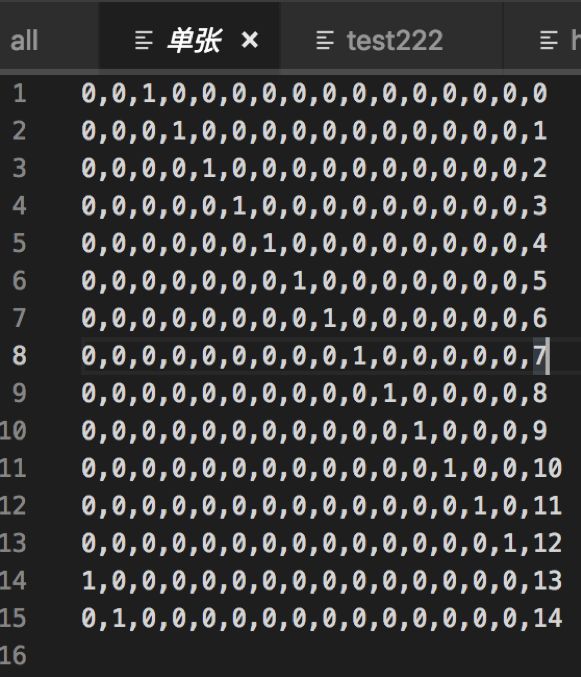
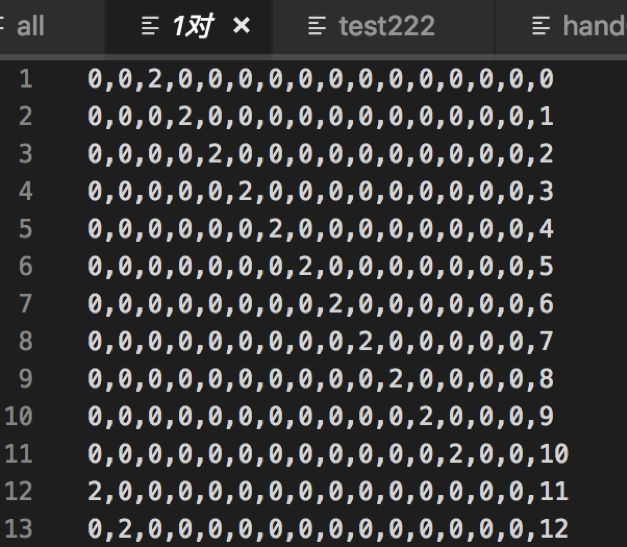

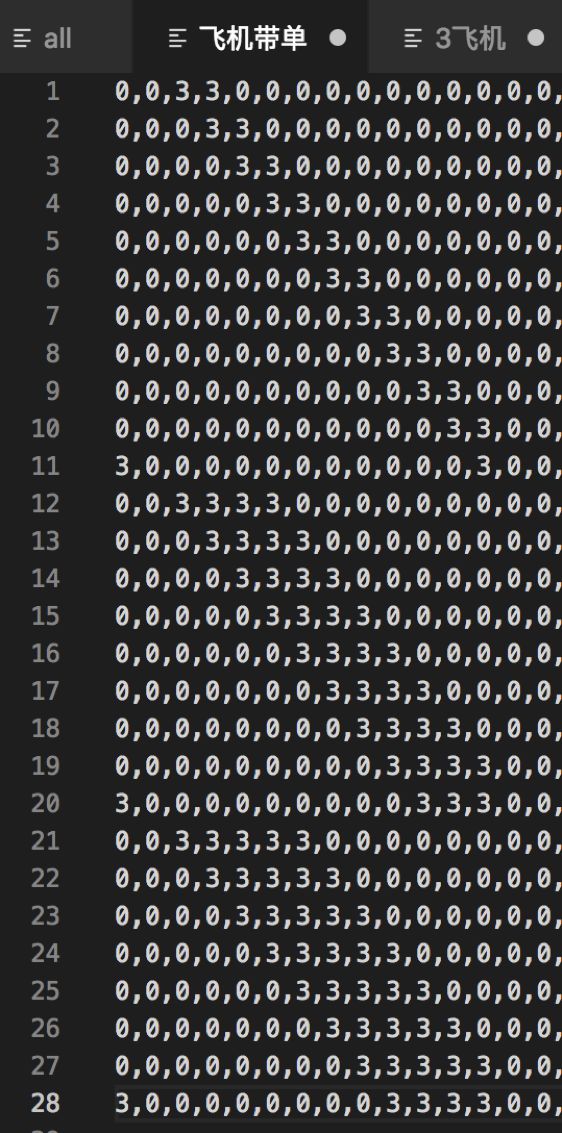

4.3 带牌网络
有了抢地主模块以及策略网络之后,原则上已经可以了。但是,怎么带牌同样是一个问题。如果主牌有n种选择,带牌有m种选择。那么总共就有m * n 种出牌的可能性。例如三带一张中,三条共有13种可能,可以带的牌有14种可能(从3到大小王,减去1), 那么出牌总共有13 * 14种可能性。在某些时候,玩家有飞机(例如333444) 飞机长度为i(例如333444飞机长度为 2), j 为可以带的牌。那么它总共有i * j 种选择。例如333444555666789J是合法的牌型,但是在8百万个游戏记录中却很少出现。所以主牌+带牌的这种牌型需要额外处理,而带牌又有不同的带牌规则,带一单张,带一对,带2单张,带2对等等;而带牌规则将由策略网络预测出来。
为了解决这个问题,我们加了这个额外的带牌网络。带牌网络的输入包括手牌以及策略网络预测出来的带牌规则,它是一个15 * 9 * 3的3维Tensor。X维表示什么牌,这个跟策略网络中定义是一样的。
Y维与Z维如表4所示

Y维与Z维,主要收集了以下信息:
- 带牌类型(单张/对子)角色(地主,地主下家,地主上家)剩余手牌,合法的单张对子。
- 游戏的记录信息(还有几轮打完)主牌长度,带牌长度
- 剩余的牌,合法的牌以及其它特征。
带入了带牌网络之后,策略网络只需要预测主牌,以及带牌类型,以及带牌长度就可以了。否则策略网络的输出标签就不止309种了,而是好几千。但是事实上带牌的组合对牌型的大小来说并不重要,例如333444555666789J和333444555666789Q大小是一样的,策略网络只需要输出的信息里包括主牌333444555666,带牌类型为带单张,飞机长度为4就可以了。然后在带牌网络中就会预测出789J或者789Q这样的组合牌出来。
带牌网络的输入包括了以下信息,剩余手牌以及从策略网络输出的信息(如主牌,带牌类型,飞机长度),它是一个15 * 9 * 3的三维 tensor.
带牌网络的输出是28个可能性,代表15个单张,13个对子。
带牌网络包含了5层的CNN和一个全连接层,每次输出一种可以带的牌。例如带牌网络预测333444带2单的情况,它会调用带牌网络2次,每次一张最有可能带出的牌,然后再调用一次。
5 实验
5.1 实验建立
我们收集了8百万条游戏数据,并且把它分出来大概8千万个state-action对。90%的数据为训练集,10%的数据为测试集。然后把数据输入到模型中进行训练,最后使用TFRecords把模型保存到硬盘上。这并不只是为了方便更改模型参数,它还可以让训练更快。大概每次花20个小时就可以训练好策略网络了。策略网络的batch size是256. 策略网络在测试集中的准确率为88左右。使用i7-7900X CPU, NVIDIA 1080TiGPS Ubuntu 16.04系统,策略网络每次计算只需要0.02秒左右。
带牌网络同样也是采用监督学习来训练的,所有样本同样来自于8百万条数据。带牌网络达到90%的准确率,它甚至比策略网络更好。
我们曾经更改过层数,滤波器,以及其他参数得到很多模型。基至使用Duplicate Mode来测试它,比较了10000局游戏中地主的积分之后,我们最终选择了最优的模型。
5.2 与其它 AI模型比较
MicroWe曾经在斗地主的人工智能比赛中赢得了多个奖项,在DeepRocket出现之前,它是最优秀的斗地主模型。
图三,图四显示了这两个模型的测试情况。我们总共测试了50000局游戏。需要特别解释的是,我们发了20张牌给一个人,然后指定他为地主。因此地主赢的机会比较少。其中 DR VS MW 表示 DeepRocket 为地主,MicroWe为地主上家。


我们可以得出结论DeepRocket 明显优于MicroWe,它曾经是最好的斗地主AI.
5.3 与人类专家比较
举行了一次测试比赛,我们邀请了4名顶尖的业余玩家参加。我们复制了多个模型,让AI玩家与人类玩家进行比赛。DeepRocket击败了人类团队以30比24胜出。请参阅后面附件。
5.4合作推理
在 DR 的游戏记录中,我们找到了一个典型的例子能够展现其良好的合作能力(T:10;B:大王;S:小王。其中冒号之前表示玩家,冒号后表示打出的牌,以分号作为某玩家出牌结束标志,0 代表地主)
牌面:
4456777889JKKAA2B;
335567899TTJJKAA2;
4456689TTJQQQK22S;
33Q;
游戏进程:
0,33;1,55;2,66;0,77;1,AA;1,6;2,T;0,J;1,K;0,2;2,S;2,44;0,KK;2,22;2,89TJQK;2,QQ;0,AA;0,56789;1,789TJ;1,3;2,5;
以上加粗部分是关键步骤,在游戏的最后 DR 打出一张“3”来帮助队友取得胜利,由此可见 DR 具有良好合作能力的。
我们也找到了一个能够展现 DR 推理能力的例子:
牌面:
33345578TTJKKA22S;
34566789TQQQKKAA2;
4456678999TJJQA2B;
78J;
游戏进程:
0,345678;1,56789T;0,6789TJ;0,QQQKK;0,AA;2,22;2,55;2,3334;2,TT;2,A;0,2;
以上加粗部分是关键步骤,虽然最后农民输了,但是他选择打“A”是一个不错的选择,因为地主只剩一张牌,而农民手里还有 (“7, 8, J, A, S”)五张牌,选择出“A”也是人类专家的正常逻辑,DR 能够从人类中学到此行为。
展望
虽然,我们已经证明了 CNN 能够预测斗地主游戏中玩家的行为,并与队友进行合作;在没有任何的 MCTS 之下能达到顶级选手的水平甚至更高。但是,我们也还有许多方面要进行完善。第一个是强化问题,直接将应用在 AlphaGo 的方法移植到 CCP 中是行不通的;第二个是关于 Monte Carlo 搜索或者 MCTS 的问题
在未来,DR 可以在以下方面进行改进:
叫地主的方式可以改进,在抢地主的过程中只有 0、1、2 和 3 是正确操作,0 代表玩家不想当地主。我们将尝试用深度神经网络去训练叫地主的方式。
我们将尝试使用随机权重训练模型。
我们将训练分别代表三个角色的三个输出模型。
笔者按:这里原作者在策略网络中,输入数据并没有很好的解释清楚。
15 * 19 * 21中,
X代表所有的牌,这个很清楚了。
但是Y代表所有的牌型,这个还不是很清楚为什么是19. 并且没有展示数据是怎么子的。
另外,当有癞子的玩法时,模型应该怎么改造也没有提及到。
最后我也预祝作者的论文被成功接收,今后在这个项目上还可以再有进展!