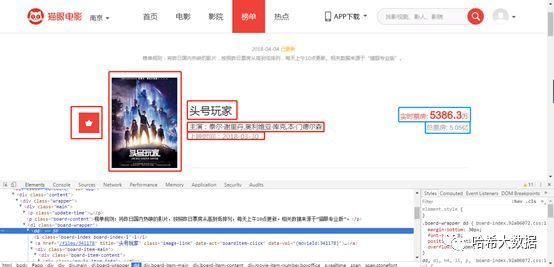
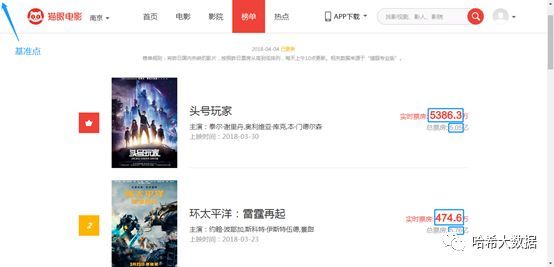
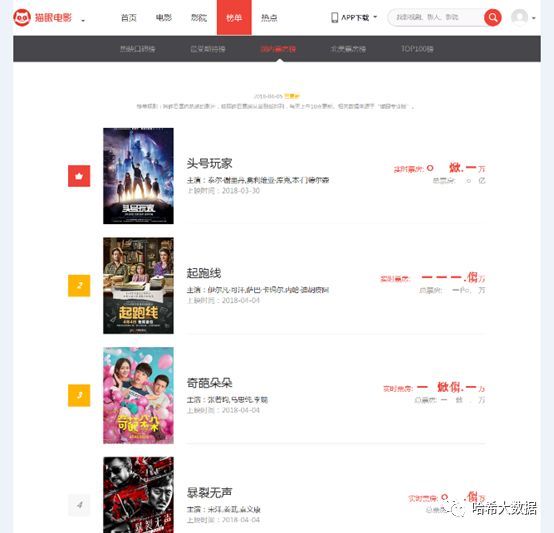
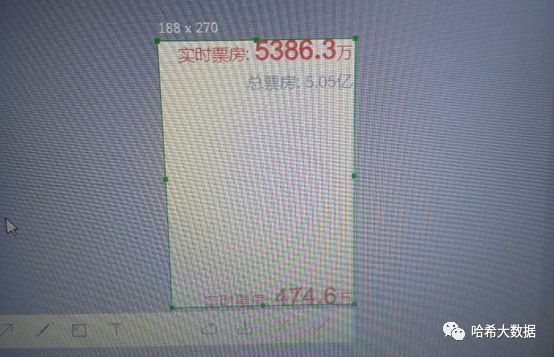
- 芦花鞋一四
许叶晗
又是在一个寒冷的夏日里,青铜和葵花决定今天一起去卖芦花鞋,奶奶亲手给他们做了一碗热乎乎的粥对他们说:“就靠你们两挣生活费了这碗粥赶紧趁热喝了吧!”于是青铜和葵花喝完了奶奶给她们做的粥,就准备去镇上卖卢花鞋,这回青铜和葵花穿着新的芦花鞋来到了镇上。青铜这回看到了很多人都在卖,用手势表达对葵花说:“这回有好多人在抢我们生意呢!我们必须得吆喝起来。”葵花点了点头。可是谁知他们也大声的叫,卖芦花喽!卖芦花
- 2020-01-25
晴岚85
郑海燕坚持分享590天2020.1.24在生活中只存在两个问题。一个问题是:你知道想要达成的目标是什么,但却不知道如何才能达成;另一个问题是:你不知道你的目标是什么。前一个是行动的问题,后一个是结果的问题。通过制定具体的下一步行动,可以解决不知道如何开始行动的问题。而通过去想象结果,对结果做预估,可以解决找不着目标的问题。对于所有吸引我们注意力,想要完成的任务,你可以先想象一下,预期的结果究竟是什
- OC语言多界面传值五大方式
Magnetic_h
iosui学习objective-c开发语言
前言在完成暑假仿写项目时,遇到了许多需要用到多界面传值的地方,这篇博客来总结一下比较常用的五种多界面传值的方式。属性传值属性传值一般用前一个界面向后一个界面传值,简单地说就是通过访问后一个视图控制器的属性来为它赋值,通过这个属性来做到从前一个界面向后一个界面传值。首先在后一个界面中定义属性@interfaceBViewController:UIViewController@propertyNSSt
- 一百九十四章. 自相矛盾
巨木擎天
唉!就这么一夜,林子感觉就像过了很多天似的,先是回了阳间家里,遇到了那么多不可思议的事情儿。特别是小伙伴们,第二次与自己见面时,僵硬的表情和恐怖的气氛,让自己如坐针毡,打从心眼里难受!还有东子,他现在还好吗?有没有被人欺负?护城河里的小鱼小虾们,还都在吗?水不会真的干枯了吧?那对相亲相爱漂亮的太平鸟儿,还好吧!春天了,到了做窝、下蛋、喂养小鸟宝宝的时候了,希望它们都能够平安啊!虽然没有看见家人,也
- 爬山后遗症
璃绛
爬山,攀登,一步一步走向制高点,是一种挑战。成功抵达是一种无法言语的快乐,在山顶吹吹风,看看风景,这是从未有过的体验。然而,爬山一时爽,下山腿打颤,颠簸的路,一路向下走,腿部力量不够,走起来抖到不行,停不下来了!第二天必定腿疼,浑身酸痛,坐立难安!
- 30天风格练习-DAY2
黄希夷
Day2(重义)在一个周日/一周的最后一天,我来到位于市中心/市区繁华地带的一家购物中心/商场,中心内人很多/熙熙攘攘。我注意到/看见一个独行/孤身一人的年轻女孩/,留着一头引人注目/长过腰际的头发,上身穿一件暗红色/比正红色更深的衣服/穿在身体上的东西。走下扶梯的时候,她摔倒了/跌向地面,在她正要站起来/让身体离开地面的时候,过长/超过一般人长度的头发被支撑身体/躯干的手掌压/按在下面,她赶紧用
- 开心
蒋泳频
从无比抗拒来上课到接受,感动,收获~看着波哥成长,晶晶幸福笑容满面。感觉自己做的事情很有意义,很开心!还有3个感召目标就是还有三个有缘人,哈哈。明天感召去明日计划:8:30-11:00小公益11:00-21点上班,感召图片发自App图片发自App图片发自App
- 我的烦恼
余建梅
我的烦恼。女儿问我:“你给学生布置什么作文题目?”“《我的烦恼》。”“他们都这么大了,你觉得他们还有烦恼吗?”“有啊!每个人都会有自己烦恼。”“我不相信,大人是没有烦恼的,如果说一定有的话,你的烦恼和我写作业有关,而且是小烦恼。不像我,天天被你说,有这样的妈妈,烦恼是没完没了。”女儿愤愤不平。每个人都会有自己的烦恼,处在上有老下有小的年纪,烦恼多的数不完。想干好工作带好孩子,想孝顺父母又想经营好自
- 放下是一段成长的修行
小莳玥
人来到这个世界上,只有两件事:生和死。一件事已经做完了,另一件你还急什么呢?是人,都有七情六欲。是心,都有喜怒哀乐,这些再正常不过了。别总抱怨自己活得累,过得辛苦。永远记住:舒坦是留给死人的。苦,才是生活;累,才是工作;变,才是命运;忍,才是历练;容,才是智慧;静,才是修养;舍,才会得到;做,才会拥有。人生,活得太清楚,才是最大的不明白。有些事,看得很清,却说不清;有些人,了解很深,却猜不透;有些
- 活给自己看,笑容才灿烂
听着了么
白岩松说“有时候,我们活得很累,并非生活过于刻薄,而是我们太容易被外界的氛围所感染,被他人的情绪所左右。”心情是自己的。若只是活在别人的眼里、嘴里,便掌握不了让自己开心的主动权。人活着,不是为了活给别人看的,唯有做最真实的自己,活给自己看,笑容才灿烂。诚然,世事纷繁复杂,人人都有一张嘴,管也管不了。永远有人欣赏你,也永远有人批评你,不可能做到让所有人都满意,开心做自己才是最重要的。人生苦短,有太多
- 每日一题——第八十四题
互联网打工人no1
C语言程序设计每日一练c语言
题目:编写函数1、输入10个职工的姓名和职工号2、按照职工由大到小顺序排列,姓名顺序也随之调整3、要求输入一个职工号,用折半查找法找出该职工的姓名#define_CRT_SECURE_NO_WARNINGS#include#include#defineMAX_EMPLOYEES10typedefstruct{intid;charname[50];}Empolyee;voidinputEmploye
- WPF中的ComboBox控件几种数据绑定的方式
互联网打工人no1
wpfc#
一、用字典给ItemsSource赋值(此绑定用的地方很多,建议熟练掌握)在XMAL中:在CS文件中privatevoidBindData(){DictionarydicItem=newDictionary();dicItem.add(1,"北京");dicItem.add(2,"上海");dicItem.add(3,"广州");cmb_list.ItemsSource=dicItem;cmb_l
- git常用命令笔记
咩酱-小羊
git笔记
###用习惯了idea总是不记得git的一些常见命令,需要用到的时候总是担心旁边站了人~~~记个笔记@_@,告诉自己看笔记不丢人初始化初始化一个新的Git仓库gitinit配置配置用户信息gitconfig--globaluser.name"YourName"gitconfig--globaluser.email"
[email protected]"基本操作克隆远程仓库gitclone查看
- 直抒《紫罗兰永恒花园外传》
雷姆的黑色童话
没看过《紫罗兰永恒花园》的我莫名的看完了《紫罗兰永恒花园外传》,又莫名的被故事中的姐妹之情狠狠地感动了的一把。感动何在:困苦中相依为命的姐妹二人被迫分离,用一个人的自由换取另一个人的幸福。之后,虽相隔不知几许依旧心心念念彼此牵挂。这种深深的姐妹情谊就是令我为之动容的所在。贝拉和泰勒分别影片开始,海天之间一个孩童凭栏眺望,手中拿着折旧的信纸。镜头一转,挑灯伏案的薇尔莉特正在打字机前奋笔疾书。这些片段
- linux中sdl的使用教程,sdl使用入门
Melissa Corvinus
linux中sdl的使用教程
本文通过一个简单示例讲解SDL的基本使用流程。示例中展示一个窗口,窗口里面有个随机颜色快随机移动。当我们鼠标点击关闭按钮时间窗口关闭。基本步骤如下:1.初始化SDL并创建一个窗口。SDL_Init()初始化SDL_CreateWindow()创建窗口2.纹理渲染存储RGB和存储纹理的区别:比如一个从左到右由红色渐变到蓝色的矩形,用存储RGB的话就需要把矩形中每个点的具体颜色值存储下来;而纹理只是一
- 关于提高复杂业务逻辑代码可读性的思考
编程经验分享
开发经验java数据库开发语言
目录前言需求场景常规写法拆分方法领域对象总结前言实际工作中大部分时间都是在写业务逻辑,一般都是三层架构,表示层(Controller)接收客户端请求,并对入参做检验,业务逻辑层(Service)负责处理业务逻辑,一般开发都是在这一层中写具体的业务逻辑。数据访问层(Dao)是直接和数据库交互的,用于查数据给业务逻辑层,或者是将业务逻辑层处理后的数据写入数据库。简单的增删改查接口不用多说,基本上写好一
- 郎朗大婚娶公主:所有光环的背后,都是十年如一日的自律
简小尘
近日,关于郎朗大婚的新闻上了热搜,看了新娘的照片,既有天使般的面容,更有魔鬼般的身材,关键是人家还身世好,又有才华,这真的是让所有男人羡慕嫉妒恨哪。有些人不禁会想,“凭什么郎朗的人生就象开挂了一样,可我却每天都活得这么狼狈!”其实,每个开挂的人生背后,都是苦行僧般的自律。01欲戴王冠,必承其重。练琴不能只靠兴趣,更需要自律!我们先来看一下朗朗在小时候的作息时间表:早晨5:45起床,练琴1小时。中午
- 四章-32-点要素的聚合
彩云飘过
本文基于腾讯课堂老胡的课《跟我学Openlayers--基础实例详解》做的学习笔记,使用的openlayers5.3.xapi。源码见1032.html,对应的官网示例https://openlayers.org/en/latest/examples/cluster.htmlhttps://openlayers.org/en/latest/examples/earthquake-clusters.
- 2020-04-12每天三百字之连接与替代
冷眼看潮
不知道是不是好为人师,有时候还真想和别人分享一下我对某些现象的看法或者解释。人类社会不断发展进步的过程,就是不断连接与替代的过程。人类发现了火并应用火以后,告别了茹毛饮血的野兽般的原始生活(火烧、烹饪替代了生食)人类用石器代替了完全手工,工具的使用使人类进步一大步。类似这样的替代还有很多,随着科技的发展,有更多的原始的事物被替代,代之以更高效、更先进的技术。在近现代,汽车替代了马车,高速公路和铁路
- 从0到500+,我是如何利用自媒体赚钱?
一列脚印
运营公众号半个多月,从零基础的小白到现在慢慢懂了一些运营的知识。做好公众号是很不容易的,要做很多事情;排版、码字、引流…通通需要自己解决,业余时间全都花费在这上面涨这么多粉丝是真的不容易,对比知乎大佬来说,我们这种没资源,没人脉,还没钱的小透明来说,想要一个月涨粉上万,怕是今天没睡醒(不过你有的方法,算我piapia打脸)至少我是清醒的,自己慢慢努力,实现我的万粉目标!大家快来围观、支持我吧!孩子
- 勇士赢了,我把掌声给了骑士
复角度的生活
今天,不参加高考,只看NBA总决赛第三场的较量。这么说有点得罪高考生了,不过我没有当他们面秀,也没有跑到考点外面得瑟,所以我内心毫无波澜。毫无疑问,考场里不乏骑士和勇士球迷,在紧张作答语文考卷同时还心系着球队,不过我希望今天的比赛不会让你们有所分心,毕竟高考不会像比赛录像那样可以再来。今天,好像起来赶考一样,我起得很早,然而事实是睡不着,挺郁闷的,又不是我高考,我紧张什么?九点我并没有准时打开浏览
- 2.0践行没有你的参与就不完美
x秀丽x
亲爱的伙伴们早上好,今天早上我们开了一次班委竞选的会议,全程只有20多个人参与,宫班本着对大家负责任的态度告诉我们,此次竞选作废,原因是这没有达到2.0的100%参会要求,如果没有大家的参与那么这个班委选出来还有什么意义,这说明选出来的人也是不一定是我们大家心目中认可的那个人,所以为了让大家的这个90天能够更好的激发出自己的的“做”的能力,那么要从第一次竞选班委的会议开始做到100%出席会议,竞选
- 有舍才有得
_清净_
为什么经常讲放下?放下就是让你要舍得、舍去。喜舍心就是把自己喜欢的,用慈悲心喜舍出去。这就锻炼了你们在人间,学会放下原本不舍得的东西或一些事物,学会舍出去,学会帮助别人,学会多付出。你今天付出了慈悲心、喜舍心,以后会得到更多的缘助力。缘助力是什么?——贵人缘啊。今天没有付出,不懂得付出,什么都只会想到自己,那你也得不到缘助力。慈悲喜舍就是用慈悲心去帮助别人,用喜舍心去付出,最后也会得到别人回报。别
- HTML网页设计制作大作业(div+css) 云南我的家乡旅游景点 带文字滚动
二挡起步
web前端期末大作业web设计网页规划与设计htmlcssjavascriptdreamweaver前端
Web前端开发技术描述网页设计题材,DIV+CSS布局制作,HTML+CSS网页设计期末课程大作业游景点介绍|旅游风景区|家乡介绍|等网站的设计与制作HTML期末大学生网页设计作业HTML:结构CSS:样式在操作方面上运用了html5和css3,采用了div+css结构、表单、超链接、浮动、绝对定位、相对定位、字体样式、引用视频等基础知识JavaScript:做与用户的交互行为文章目录前端学习路线
- libyuv之linux编译
jaronho
Linuxlinux运维服务器
文章目录一、下载源码二、编译源码三、注意事项1、银河麒麟系统(aarch64)(1)解决armv8-a+dotprod+i8mm指令集支持问题(2)解决armv9-a+sve2指令集支持问题一、下载源码到GitHub网站下载https://github.com/lemenkov/libyuv源码,或者用直接用git克隆到本地,如:gitclonehttps://github.com/lemenko
- 没有邀请码怎么注册买手妈妈?
氧惠评测
买手妈妈怎么注册小编为大家带来买手妈妈没有邀请码怎么注册。打开买手妈妈APP,点击“马上注册”,输入邀请信息“邀请码”点击下一步,没有邀请码是登录不上的,所以这个必须要填写,那我们没有怎么办?填写成功就可以登录下一步。这里面有手机登录和淘宝登录,手机登录以后也需要用淘宝授权的,所以基本上都是淘宝登录。购物、看电影、点外卖、用氧惠APP!更优惠!氧惠(全网优惠上氧惠)——是与以往完全不同的抖客+淘客
- 番茄西红柿叶子病害分类数据集12882张11类别
futureflsl
数据集分类数据挖掘人工智能
数据集类型:图像分类用,不可用于目标检测无标注文件数据集格式:仅仅包含jpg图片,每个类别文件夹下面存放着对应图片图片数量(jpg文件个数):12882分类类别数:11类别名称:["Bacterial_Spot_Bacteria","Early_Blight_Fungus","Healthy","Late_Blight_Water_Mold","Leaf_Mold_Fungus","Powdery
- 阶段总结反思
轻争
马上就要进入10月份了,今天做一下前段时间的总结和反思。前段时间,日更、英语、健身、护肤坚持的比较好。阅读、书法坚持的不好。1.中间被迫停更半个多月,其余时间一直在坚持日更挑战。偶尔也有不想写的时候,就做一下摘抄。因为阅读(输入)没跟上来,所以写作(输出)质量有待进一步加强。2.英语做到了一周至少学习5天,每次不少于30分钟,但是小班课没有跟上更新速度,下一步要争取利用零碎时间补听小班课。3.减肥
- 冬天短期的暴利小生意有哪些?那些小生意适合新手做?
一起高省
短期生意不失为创业的一个商机,不过短期生意的商机是转瞬即逝的,而且这类生意也很难作为长期的生意去做,那冬天短期暴利小生意查看更多关于短期暴利小生意的文章有哪些呢?给大家先推荐一个2023年风口项目吧,真很不错的项目,全程零投资,当做副业来做真的很稳定,不管你什么阶层的人,或多或少都网购吧?你们知道网购是可以拿提成,拿返利,拿分佣的吗?你们知道很多优惠券群里面,天天群主和管理发一些商品吗?他们其实在
- 回溯算法-重新安排行程
chirou_
算法数据结构图论c++图搜索
leetcode332.重新安排行程这题我还没自己ac过,只能现在凭着刚学完的热乎劲把我对题解的理解记下来。本题我认为对数据结构的考察比较多,用什么数据结构去存数据,去读取数据,都是很重要的。classSolution{private:unordered_map>targets;boolbacktracking(intticketNum,vector&result){//1.确定参数和返回值//2
- web前段跨域nginx代理配置
刘正强
nginxcmsWeb
nginx代理配置可参考server部分
server {
listen 80;
server_name localhost;
- spring学习笔记
caoyong
spring
一、概述
a>、核心技术 : IOC与AOP
b>、开发为什么需要面向接口而不是实现
接口降低一个组件与整个系统的藕合程度,当该组件不满足系统需求时,可以很容易的将该组件从系统中替换掉,而不会对整个系统产生大的影响
c>、面向接口编口编程的难点在于如何对接口进行初始化,(使用工厂设计模式)
- Eclipse打开workspace提示工作空间不可用
0624chenhong
eclipse
做项目的时候,难免会用到整个团队的代码,或者上一任同事创建的workspace,
1.电脑切换账号后,Eclipse打开时,会提示Eclipse对应的目录锁定,无法访问,根据提示,找到对应目录,G:\eclipse\configuration\org.eclipse.osgi\.manager,其中文件.fileTableLock提示被锁定。
解决办法,删掉.fileTableLock文件,重
- Javascript 面向对面写法的必要性?
一炮送你回车库
JavaScript
现在Javascript面向对象的方式来写页面很流行,什么纯javascript的mvc框架都出来了:ember
这是javascript层的mvc框架哦,不是j2ee的mvc框架
我想说的是,javascript本来就不是一门面向对象的语言,用它写出来的面向对象的程序,本身就有些别扭,很多人提到js的面向对象首先提的是:复用性。那么我请问你写的js里有多少是可以复用的,用fu
- js array对象的迭代方法
换个号韩国红果果
array
1.forEach 该方法接受一个函数作为参数, 对数组中的每个元素
使用该函数 return 语句失效
function square(num) {
print(num, num * num);
}
var nums = [1,2,3,4,5,6,7,8,9,10];
nums.forEach(square);
2.every 该方法接受一个返回值为布尔类型
- 对Hibernate缓存机制的理解
归来朝歌
session一级缓存对象持久化
在hibernate中session一级缓存机制中,有这么一种情况:
问题描述:我需要new一个对象,对它的几个字段赋值,但是有一些属性并没有进行赋值,然后调用
session.save()方法,在提交事务后,会出现这样的情况:
1:在数据库中有默认属性的字段的值为空
2:既然是持久化对象,为什么在最后对象拿不到默认属性的值?
通过调试后解决方案如下:
对于问题一,如你在数据库里设置了
- WebService调用错误合集
darkranger
webservice
Java.Lang.NoClassDefFoundError: Org/Apache/Commons/Discovery/Tools/DiscoverSingleton
调用接口出错,
一个简单的WebService
import org.apache.axis.client.Call;import org.apache.axis.client.Service;
首先必不可
- JSP和Servlet的中文乱码处理
aijuans
Java Web
JSP和Servlet的中文乱码处理
前几天学习了JSP和Servlet中有关中文乱码的一些问题,写成了博客,今天进行更新一下。应该是可以解决日常的乱码问题了。现在作以下总结希望对需要的人有所帮助。我也是刚学,所以有不足之处希望谅解。
一、表单提交时出现乱码:
在进行表单提交的时候,经常提交一些中文,自然就避免不了出现中文乱码的情况,对于表单来说有两种提交方式:get和post提交方式。所以
- 面试经典六问
atongyeye
工作面试
题记:因为我不善沟通,所以在面试中经常碰壁,看了网上太多面试宝典,基本上不太靠谱。只好自己总结,并试着根据最近工作情况完成个人答案。以备不时之需。
以下是人事了解应聘者情况的最典型的六个问题:
1 简单自我介绍
关于这个问题,主要为了弄清两件事,一是了解应聘者的背景,二是应聘者将这些背景信息组织成合适语言的能力。
我的回答:(针对技术面试回答,如果是人事面试,可以就掌
- contentResolver.query()参数详解
百合不是茶
androidquery()详解
收藏csdn的博客,介绍的比较详细,新手值得一看 1.获取联系人姓名
一个简单的例子,这个函数获取设备上所有的联系人ID和联系人NAME。
[java]
view plain
copy
public void fetchAllContacts() {
- ora-00054:resource busy and acquire with nowait specified解决方法
bijian1013
oracle数据库killnowait
当某个数据库用户在数据库中插入、更新、删除一个表的数据,或者增加一个表的主键时或者表的索引时,常常会出现ora-00054:resource busy and acquire with nowait specified这样的错误。主要是因为有事务正在执行(或者事务已经被锁),所有导致执行不成功。
1.下面的语句
- web 开发乱码
征客丶
springWeb
以下前端都是 utf-8 字符集编码
一、后台接收
1.1、 get 请求乱码
get 请求中,请求参数在请求头中;
乱码解决方法:
a、通过在web 服务器中配置编码格式:tomcat 中,在 Connector 中添加URIEncoding="UTF-8";
1.2、post 请求乱码
post 请求中,请求参数分两部份,
1.2.1、url?参数,
- 【Spark十六】: Spark SQL第二部分数据源和注册表的几种方式
bit1129
spark
Spark SQL数据源和表的Schema
case class
apply schema
parquet
json
JSON数据源 准备源数据
{"name":"Jack", "age": 12, "addr":{"city":"beijing&
- JVM学习之:调优总结 -Xms -Xmx -Xmn -Xss
BlueSkator
-Xss-Xmn-Xms-Xmx
堆大小设置JVM 中最大堆大小有三方面限制:相关操作系统的数据模型(32-bt还是64-bit)限制;系统的可用虚拟内存限制;系统的可用物理内存限制。32位系统下,一般限制在1.5G~2G;64为操作系统对内存无限制。我在Windows Server 2003 系统,3.5G物理内存,JDK5.0下测试,最大可设置为1478m。典型设置:
java -Xmx355
- jqGrid 各种参数 详解(转帖)
BreakingBad
jqGrid
jqGrid 各种参数 详解 分类:
源代码分享
个人随笔请勿参考
解决开发问题 2012-05-09 20:29 84282人阅读
评论(22)
收藏
举报
jquery
服务器
parameters
function
ajax
string
- 读《研磨设计模式》-代码笔记-代理模式-Proxy
bylijinnan
java设计模式
声明: 本文只为方便我个人查阅和理解,详细的分析以及源代码请移步 原作者的博客http://chjavach.iteye.com/
import java.lang.reflect.InvocationHandler;
import java.lang.reflect.Method;
import java.lang.reflect.Proxy;
/*
* 下面
- 应用升级iOS8中遇到的一些问题
chenhbc
ios8升级iOS8
1、很奇怪的问题,登录界面,有一个判断,如果不存在某个值,则跳转到设置界面,ios8之前的系统都可以正常跳转,iOS8中代码已经执行到下一个界面了,但界面并没有跳转过去,而且这个值如果设置过的话,也是可以正常跳转过去的,这个问题纠结了两天多,之前的判断我是在
-(void)viewWillAppear:(BOOL)animated
中写的,最终的解决办法是把判断写在
-(void
- 工作流与自组织的关系?
comsci
设计模式工作
目前的工作流系统中的节点及其相互之间的连接是事先根据管理的实际需要而绘制好的,这种固定的模式在实际的运用中会受到很多限制,特别是节点之间的依存关系是固定的,节点的处理不考虑到流程整体的运行情况,细节和整体间的关系是脱节的,那么我们提出一个新的观点,一个流程是否可以通过节点的自组织运动来自动生成呢?这种流程有什么实际意义呢?
这里有篇论文,摘要是:“针对网格中的服务
- Oracle11.2新特性之INSERT提示IGNORE_ROW_ON_DUPKEY_INDEX
daizj
oracle
insert提示IGNORE_ROW_ON_DUPKEY_INDEX
转自:http://space.itpub.net/18922393/viewspace-752123
在 insert into tablea ...select * from tableb中,如果存在唯一约束,会导致整个insert操作失败。使用IGNORE_ROW_ON_DUPKEY_INDEX提示,会忽略唯一
- 二叉树:堆
dieslrae
二叉树
这里说的堆其实是一个完全二叉树,每个节点都不小于自己的子节点,不要跟jvm的堆搞混了.由于是完全二叉树,可以用数组来构建.用数组构建树的规则很简单:
一个节点的父节点下标为: (当前下标 - 1)/2
一个节点的左节点下标为: 当前下标 * 2 + 1
&
- C语言学习八结构体
dcj3sjt126com
c
为什么需要结构体,看代码
# include <stdio.h>
struct Student //定义一个学生类型,里面有age, score, sex, 然后可以定义这个类型的变量
{
int age;
float score;
char sex;
}
int main(void)
{
struct Student st = {80, 66.6,
- centos安装golang
dcj3sjt126com
centos
#在国内镜像下载二进制包
wget -c http://www.golangtc.com/static/go/go1.4.1.linux-amd64.tar.gz
tar -C /usr/local -xzf go1.4.1.linux-amd64.tar.gz
#把golang的bin目录加入全局环境变量
cat >>/etc/profile<
- 10.性能优化-监控-MySQL慢查询
frank1234
性能优化MySQL慢查询
1.记录慢查询配置
show variables where variable_name like 'slow%' ; --查看默认日志路径
查询结果:--不用的机器可能不同
slow_query_log_file=/var/lib/mysql/centos-slow.log
修改mysqld配置文件:/usr /my.cnf[一般在/etc/my.cnf,本机在/user/my.cn
- Java父类取得子类类名
happyqing
javathis父类子类类名
在继承关系中,不管父类还是子类,这些类里面的this都代表了最终new出来的那个类的实例对象,所以在父类中你可以用this获取到子类的信息!
package com.urthinker.module.test;
import org.junit.Test;
abstract class BaseDao<T> {
public void
- Spring3.2新注解@ControllerAdvice
jinnianshilongnian
@Controller
@ControllerAdvice,是spring3.2提供的新注解,从名字上可以看出大体意思是控制器增强。让我们先看看@ControllerAdvice的实现:
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Component
public @interface Co
- Java spring mvc多数据源配置
liuxihope
spring
转自:http://www.itpub.net/thread-1906608-1-1.html
1、首先配置两个数据库
<bean id="dataSourceA" class="org.apache.commons.dbcp.BasicDataSource" destroy-method="close&quo
- 第12章 Ajax(下)
onestopweb
Ajax
index.html
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/
- BW / Universe Mappings
blueoxygen
BO
BW Element
OLAP Universe Element
Cube Dimension
Class
Charateristic
A class with dimension and detail objects (Detail objects for key and desription)
Hi
- Java开发熟手该当心的11个错误
tomcat_oracle
java多线程工作单元测试
#1、不在属性文件或XML文件中外化配置属性。比如,没有把批处理使用的线程数设置成可在属性文件中配置。你的批处理程序无论在DEV环境中,还是UAT(用户验收
测试)环境中,都可以顺畅无阻地运行,但是一旦部署在PROD 上,把它作为多线程程序处理更大的数据集时,就会抛出IOException,原因可能是JDBC驱动版本不同,也可能是#2中讨论的问题。如果线程数目 可以在属性文件中配置,那么使它成为
- 推行国产操作系统的优劣
yananay
windowslinux国产操作系统
最近刮起了一股风,就是去“国外货”。从应用程序开始,到基础的系统,数据库,现在已经刮到操作系统了。原因就是“棱镜计划”,使我们终于认识到了国外货的危害,开始重视起了信息安全。操作系统是计算机的灵魂。既然是灵魂,为了信息安全,那我们就自然要使用和推行国货。可是,一味地推行,是否就一定正确呢?
先说说信息安全。其实从很早以来大家就在讨论信息安全。很多年以前,就据传某世界级的网络设备制造商生产的交