分区里的inode号是0号和1号的block
我相信大家在使用Linux的时候都遇到过误删文件系统数据的情况,不管是自己误删还是帮人家恢复误删
现在用的比较多的恢复工具大概是ext3grep 、extundelete 这两个
当然本文不是要说这两个工具的使用方法,而是介绍每个分区里的inode号为0或1号的block到底是什么
在使用ext3grep 、extundelete 的时候,基本上都会有这样一个步骤
在Linux下可以通过“ls-id”命令来查看某分区目录的inode值,可以输入:
[root@localhost /]#ls –id / 2 / [root@steven ~]# ls -id /boot 2 /boot
可以看到,无论是哪个分区,它的inode值都是2,而不是0,也不是1
并且当你用find命令来搜索一下0或1号inode的时候也是什么也找不到
find / -inum 0 find: `/proc/1461/task/1461/fd/5': No such file or directory find: `/proc/1461/task/1461/fdinfo/5': No such file or directory find: `/proc/1461/fd/5': No such file or directory find: `/proc/1461/fdinfo/5': No such file or directory
那么inode为0或1的block去哪里了?
boot sector 与 superblock 的关系
block 为 1024 bytes (1K) 时:
如果 block 大小刚好是 1024 的话,那么 boot sector 与 superblock 各会占用掉一个 block , 也表示boot sector 是独立于 superblock 外面的。
[root@www ~]# dumpe2fs /dev/hdc1 dumpe2fs 1.39 (29-May-2006) Filesystem volume name: /boot ....(中间省略).... First block: 1 Block size: 1024 ....(中间省略).... Group 0: (Blocks 1-8192) Primary superblock at 1, Group descriptors at 2-2 Reserved GDT blocks at 3-258 Block bitmap at 259 (+258), Inode bitmap at 260 (+259) Inode table at 261-511 (+260) 511 free blocks, 1991 free inodes, 2 directories Free blocks: 5619-6129 Free inodes: 18-2008
看到最后一个特殊字体的地方吗? Group0 的 superblock 是由 1 号 block 开始的
上面结果可以发现 0 号 block 是保留下来留给 boot sector 用的

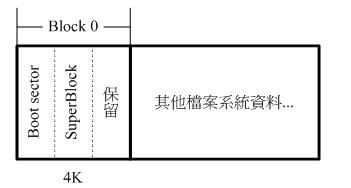
block 大于 1024 bytes (2K, 4K) 时:
如果 block 大于 1024 的话,那么 superblock 将会在 0 号!
[root@www ~]# dumpe2fs /dev/hdc2 dumpe2fs 1.39 (29-May-2006) ....(中间省略).... Filesystem volume name: /1 ....(中间省略).... Block size: 4096 ....(中间省略).... Group 0: (Blocks 0-32767) Primary superblock at 0, Group descriptors at 1-1 Reserved GDT blocks at 2-626 Block bitmap at 627 (+627), Inode bitmap at 628 (+628) Inode table at 629-1641 (+629) 0 free blocks, 32405 free inodes, 2 directories Free blocks: Free inodes: 12-32416
可以发现 superblock 就在第一个 block (第 0 号) 上,但是 superblock 其实就只有 1024bytes
为了怕浪费更多空间,因此第一个 block 内就含有 boot sector 与 superblock
上面结果显示,因为每个 block 占有 4K ,但是 superblock 其实就只有 1024bytes
因此在第一个 block 内 superblock 仅占有 1024-2047 ( 由 0 号起算的话),而 0-1023 就保留给 boot sector 来使用。
而后面的2048bytes 的空间保留
现在也明白了为什麽df命令这麽快了吧,它是读取每个分区inode为0的superblock里面的信息,
而superblock里面就保存了分区文件系统类型、大小、已使用大小、可用大小

我们可以使用tune2fs命令查看某一分区的块大小等信息
tune2fs -l /dev/sdb1 tune2fs 1.41.12 (17-May-2010) Filesystem volume name:Last mounted on: Filesystem UUID: 4814e6f2-6550-4ac5-bf2d-33109fc53061 Filesystem magic number: 0xEF53 Filesystem revision #: 1 (dynamic) Filesystem features: has_journal ext_attr resize_inode dir_index filetype needs_recovery extent flex_bg sparse_super large_file huge_file uninit_bg dir_nlink extra_isize Filesystem flags: signed_directory_hash Default mount options: (none) Filesystem state: clean Errors behavior: Continue Filesystem OS type: Linux Inode count: 65280 Block count: 261048 Reserved block count: 13052 Free blocks: 252525 Free inodes: 65269 First block: 0 Block size: 4096 Fragment size: 4096 Reserved GDT blocks: 63 Blocks per group: 32768 Fragments per group: 32768 Inodes per group: 8160 Inode blocks per group: 510 Flex block group size: 16 Filesystem created: Thu Jun 2 12:23:23 2016 Last mount time: Thu Jun 2 12:24:06 2016 Last write time: Thu Jun 2 12:24:06 2016 Mount count: 1 Maximum mount count: 20 Last checked: Thu Jun 2 12:23:23 2016 Check interval: 15552000 (6 months) Next check after: Tue Nov 29 12:23:23 2016 Lifetime writes: 32 MB Reserved blocks uid: 0 (user root) Reserved blocks gid: 0 (group root) First inode: 11 Inode size: 256 Required extra isize: 28 Desired extra isize: 28 Journal inode: 8 Default directory hash: half_md4 Directory Hash Seed: fad5ad24-52ef-482c-a54b-367a5bb4f122 Journal backup: inode blocks
通过上面的信息就可以知道superblock是在block 0还是block 1
那么上面的信息又是从哪里读取出来的
答案是:还是superblock
superblock如此重要,所以系统也对superblock做了一些保护措施
文件系统会有一些备用超级块,备用超级块一般创建于块 8193、16384 或 32768
ext类文件系统会把block分成一组一组来管理简称为块组,可以看到Blocks per group这一行,就是每个group都包含了32768个block
每个group都会有一个备用superblock,所以备用超级块一般创建于块 8193、16384 或 32768,根据格式化时的block size而定
tune2fs -l /dev/sda4 |grep group
Blocks per group: 32768
Fragments per group: 32768
Inodes per group: 8192
Inode blocks per group: 512
Flex block group size: 16
Reserved blocks gid: 0 (group root)
注意:非ext类文件系统是不能用tune2fs命令的,而且原理和内部格式跟ext类文件系统不相同!!
tune2fs -l /dev/sdb1 tune2fs 1.41.12 (17-May-2010) tune2fs: Bad magic number in super-block while trying to open /dev/sdb1 Couldn't find valid filesystem superblock.
参考资料:http://bbs.chinaunix.net/forum.php?mod=viewthread&tid=4250473&extra=page%3D1%26filter%3Dauthor%26orderby%3Ddateline%26orderby%3Ddateline
EXT4是Linux kernel 自 2.6.28 开始正式支持的新的文件系统,目前已经广泛应用在新发行的LINUX版本中。移动终端方面的Android默认系统分区也已成为EXT4。随着LINUX系统的不断更新,相信EXT4将很快替代EXT3,成为下一代LINUX上的标准文件系统。
相比EXT3而言,EXT4最大的改动是文件系统的空间分配模式。默认情况下,EXT4不再使用EXT3的block mapping分配方式 ,而改为Extent方式分配。从专业的数据恢复理论看,基于block mapping的EXT3在数据删除后就很难恢复,如果基于Extent,可参考的信息就更少,如何有效的恢复EXT4误删除的数据,是个公认的技术难题。
近日,我公司经过不断地尝试和改进,终于完成了对EXT4数据误删除恢复的技术攻关,形成了一套完整的技术解决方案,并成功开发出了基于EXT4的专业数据恢复系统。
下面为北亚数据恢复中心对EXT4误删除数据的恢复方案简介。
1、关于EXT4的结构特征:
EXT4在总体结构上与EXT3相似,大的分配方向都是基于相同大小的块组,每个块组内分配固定数量的INODE,可能的超级块(或备份),及可能的块组描述表。
EXT4的INODE 结构做了重大改变,为增加新的信息,大小由EXT3的128字节增加到默认的256字节,同时块索引不再使用EXT3的12直接块+1个1次间接块+1个2次间接块+1个3次间接块的索引模式,而改为4个Extent片断流,每个片断流设定片断的起始块号及连续的块数量(有可能直接指向数据区,也有可能指向索引块区)。
2、EXT4删除数据的结构更改:
EXT4删除数据后,会依次释放文件系统bitmap空间位、更新目录结构、释放inode空间位。而INODE空间的释放不像WINDOWS NTFS或FAT一样保留数据的全部或部分索引,一个更彻底的操作是直接清除所有节点中的索引项。
清除了文件的存储索引,意味着即使可以得到文件的名称、日期等元信息,也无法直接知道文件原来存储在什么位置,而基于Extent的存储方式更紧凑,删除之后,很难保证可以很容易还原原先的存储索引。
块组是block group
block group包含备用super block,inode,block group description
INODE 结构做了重大改变,为增加新的信息,大小由EXT3的128字节增加到默认的256字节
Inode size: 256 byte
EXT4删除数据后,会依次释放文件系统bitmap空间位
Block bitmap at 259 (+25, Inode bitmap at 260 (+259)
以上内容针对于ext类文件系统,不对的地方欢迎拍砖
部分参考了鸟哥文章:http://vbird.dic.ksu.edu.tw/linux_basic/0230filesystem_6.php