参考书籍
《JavaScript高级语言程序设计》—— Nicholas C.Zakas
《你不知道的JavaScript》 —— KYLE SIMPSON
在JS的面向对象编程中,我们最为关注的是两种行为,一是创建对象,二是类继承
JS创建对象
一.构造函数模式创建对象
第一种创建对象的方式是构造函数模式
如下所示, 将构造函数中的属性和方法赋给一个新对象
/** * description: 构造函数模式创建对象 */ function Type (p) { this.param = p; // 定义属性 this.method = function () { // 定义方法 return this.param; } } var obj1 = new Type(1); // {param:1, method: function(){...}} var obj2 = new Type(2); // {param:2, method: function(){...}} console.log(obj1.method()) // 输出1 console.log(obj2.method()) // 输出2
当一个函数被加以new操作符前缀,它就会被当成一个构造函数调用并返回一个对象。所以构造函数和普通函数在形式上没有差别,区别只是在于有没有和new操作符搭配调用而已。
一般来说,我们知道,一个方法没有明确的调用对象时候,this的指向将是window, 但在构造函数创建对象时候, new操作符改变了this的指向, 使其和新创建的对象绑定。 所以构造函数体内执行的代码相当于:
var obj = new Object; obj.param = p; obj.method = function () { ... };
二.原型模式创建对象
构造函数的缺陷与加入原型的原因
我们知道, 原型(prototype)已经不知不觉地加入到JS面向对象的大家庭里面来了, 可是他当初是如何被邀请进这个家庭里面的呢? 实际上,这个“邀请人”正是构造函数。
利用构造函数创建对象看起来并无不妥,但它有个关键的问题: 冗余的函数创建。
例如上文中我们创建obj1和obj2的过程中,method这个方法被重复创建了两次
var obj1 = new Type(1); // {param:1, method: function(){...}} var obj2 = new Type(2); // {param:2, method: function(){...}}
我们发现, 和param属性相反, method方法对不同的对象来说函数体是相同的,重复创建函数是一种对内存的浪费
this.method = function () { // 定义方法 return this.param; }
所以大家就想: 将其变成一个可以共享的方法或许更合适一些, 于是prototype就出现在JS面向对象的舞台上了。加入原型的原因,一大部分原因就是为了实现函数复用, 弥补构造函数的缺陷
构造函数和原型的关系
在JS的OO中,我们可以把对象属性分为两部分:
- 一部分是不同对象各自独有的属性, 例如上文中的param. 在需求上,我们希望不同的对象拥有不同的param
- 一部分是不同对象间共享的属性, 例如上文中的method方法,在需求上,我们希望不同的对象共同使用同一个method。
原型就是承载这一部分共享属性的载体,它是一个对象,叫做prototype。
同时这个prototype对象还是在每个函数(或构造函数)在一开始就带有的属性。
所以整体思路是: 对于共享的那部分属性,从构造函数中“搬”到prototype对象中来:
于是我们的代码从:
function Type (p) { this.param = p; // 定义属性 this.method = function () { // 定义方法 return this.param; } }
变成了:
function Type (p) { this.param = p; // 不同对象各自独有的属性 } Type.prototype.method = function () { // 不同对象共享的属性 return this.param; }
这样的话,我们在利用构造函数创建对象的时候, 就不会做重复创建method方法这个多余的行为了,而是直接根据对象和构造函数的关系,直接从构造函数(Type.prototype)中的原型对象中取得method。
那么问题来了, 怎么在某个对象中取得method方法?
原型能是个普通对象吗?(反向探究原型的工作机制)
如果你了解过JS,你当然知道原型有一系列的机制,但我现在先不讲这些,而是从“prototype如果是个普通的对象会怎样”, 反向探究原型创建对象需要哪些必要的工作机制
如果原型只是一个普通地不能再普通的对象的话——
1. 如果原型只是个普通对象,在被创建的对象中取得在原型中的属性将会很麻烦
需要通过Object.getPrototypeOf取得原型对象的引用,然后才能从原型对象中取出method方法 。。。。 而且因为this绑定丢失的问题,方法还得用call调用!
function Type (p) { this.param = p; // 不同对象各自独有的属性 } Type.prototype.method = function () { // 不同对象共享的属性 return this.param; } // 卧槽,卧槽! 要是这么麻烦我干脆别用原型了 var obj = new Type(1); // 超级麻烦! console.log(Object.getPrototypeOf(obj).method.call(obj)) // 输出1 // 也很麻烦!同时这种简化破环了我们面向对象的初衷 console.log(Type.prototype.method.call(obj)) //输出1
反向思考: 原型的机制应该使得对象中能用很简单的方式使用原型中的属性, 最好是:,对象obj能直接通过obj.method访问其构造函数的原型对象中的属性, 这样的话,无论属性在构造函数的this中,还是在prototype对象,创建的对象使用该属性的方式都是相同的! 这样,具体的实现就变成了和使用无关的“黑盒” 。
2. 如果原型只是个普通对象, 你将不得不考虑prototype对象中数据的维护问题
因为在这种假设下,prototype对象是所有对象的单一数据源, 所以对象A如果重写了该方法,对象B使用的就不是一开始prototype对象中定义的方法, 而是对象A修改过后的方法,而所有其他对象也和对象B一样。 这样的话,我们就不能在某个对象中重写原型中的方法了。
反向思考: 原型的机制应当确保prototype对象中属性的稳定性, 换句话说,就是在某个对象重写原型中具有的属性时候, 仅仅起到覆盖原型中的同名属性作用就可以了, 而不要不要修改原型中的属性!
所以,JavaScript中的“原型”当然不是一个普通的对象,它是prototype对象以及背后的一系列机制形成的一个“整体”!
其实在上面“反向思考”的描述里,我已经说明了原型的工作机制了,不过下面还是更具体地说明一下:
原型的工作机制
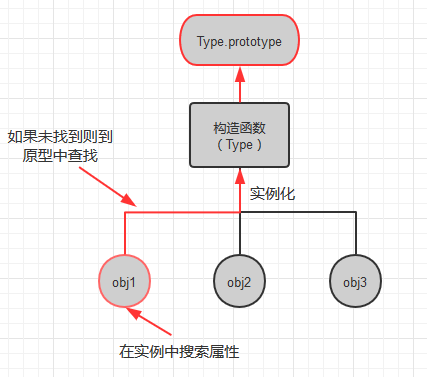
1. 在用new 操作符创建对象实例的时候, 该对象将获得一个指向其构造函数的原型对象的内部指针,因此,我们可以通过“.”运算符直接访问原型中的属性, 就和访问实例属性一样(前提是实例对象中没有同名属性)
function Type (p) { this.param = p; // 不同对象各自独有的属性 } Type.prototype.method = function () { // 不同对象共享的属性 return this.param; } var obj = new Type(1); console.log(obj); obj.method();
2. 当访问对象中的某个属性时,先在对象实例中查找该属性, 如果在实例中找到了该属性名,则返回该属性的值,如果没有找到,则继续在对应构造函数的原型对象中寻找, 如果找到则返回原型中的属性值
function Type () { this.a = '实例对象中的a'; } Type.prototype.a = 'prototype中的a'; Type.prototype.b = 'prototype中的b'; var obj = new Type(); console.log(obj); //输出 : {a: "实例对象中的a"} console.log(obj.a); //输出:实例对象中的a console.log(obj.b); //输出: prototype中的b
如代码所示, 因为对于属性a, 因为在实例对象中查找到了, 所以就直接返回实例中的属性值,而对于属性b,z在实例对象中没有查找到,所以返回原型中的属性值
上面我们说的是在实例中查找属性时,原型的作用机制,那么在添加属性的过程中会发生什么事情呢?
3.在为实例添加属性时, 只会覆盖其构造函数的原型对象中的同名属性,这种情况叫做“属性屏蔽”,也就是以后通过obj.属性名,就会读取到实例中的属性了,而不是原型中的属性, 但是! 原型对象中的属性是不会被修改的!无论这个属性是基本类型还是引用类型。这就是原型对象属性的“稳定性”
例如:
function Type () {} Type.prototype.str = '字符串' Type.prototype.num = 1; Type.prototype.arr = [1,2,3]; var obj = new Type(); console.log(obj); // {} obj.str = '覆盖后字符串'; obj.num = 2; obj.arr = [3,4,5]; console.log(obj.str); // 覆盖后字符串 console.log(obj.num); // 2 console.log(obj.arr); // [3.4.5] console.log(Type.prototype.str); // 字符串 console.log(Type.prototype.num); // 1 console.log(Type.prototype.arr); // [1, 2, 3]
直接添加基本类型的值(str, num),以及引用类型的值到实例中,是不会修改原型中的同名属性的,只会屏蔽

但是大家还需要考虑另一种情况:如果我们不添加实例属性,而是直接修改属性,这时会发生什么呢?例如在obj还是空对象,没有任何属性的时候,我们就尝试通过obj.num去增加num的值(此时只有原型对象中有num),原型对象中的num还会被修改吗?而在这个空的实例对象中又会发生什么事情呢?
让我们来看看——
4. 在实例对象中没有该属性时,直接修改其在原型中的属性值, 如果这个属性是基本类型,那么会在原型的属性值的基础上为实例对象添加修改后的属性值, 而原型对象中的属性值是不变的
function Type () {} Type.prototype.str = '字符串' Type.prototype.num = 1; var obj = new Type(); console.log(obj); // 空实例对象 {} obj.str +=',加点东西'; // 尝试直接修改属性 obj.num += 1; // 尝试直接修改属性 console.log(obj.str); // 字符串,加点东西 console.log(obj.num); // 2 console.log(Type.prototype.str); // 字符串 console.log(Type.prototype.num); // 1 console.log(obj); // {str: "字符串,加点东西", num: 2}
在这里我们做了一个看起来“荒诞”的操作: 在实例对象中还没有添加属性值的时候,就尝试修改属性值(基本类型)。而且修改完后,我们发现obj已经从控对象{ }变成了 {str: "字符串,加点东西", num: 2}, 修改属性变成了一种“变相”的添加属性
- 在实例中没有该属性时,直接修改基本类型的实例属性等同于为其添加属性,而且添加的属性值是在原型对象属性值的基础上进行的
- 在直接修改基本类型的实例属性时, 原型对象中的属性仍然没有变化! 这进一步证明了原型对象中的数据具有一定的“稳定性”

也许你能猜到接下来的内容是什么了。。。因为我在<点4>中强调了两点:“直接修改的值是基本类型”和原型对象具有'一定'的稳定性。
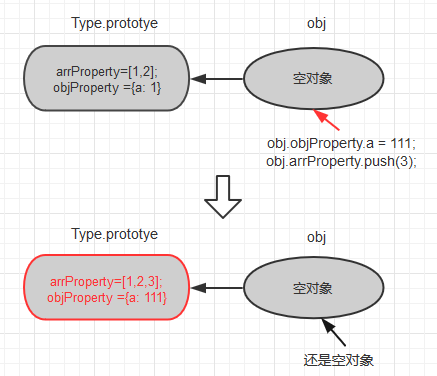
没错, 如果被直接修改的属性是属性是对象或者数组这类引用类型的数据的话, 原型对象中的数据也变得“不稳定”了
5.在实例对象中没有该属性时,直接修改其在原型中的属性值, 如果这个属性是引用类型的,那么! 原型中的属性值会被修改!也就是说,在这种情况下。 原型中的属性值是“不稳定”的! 可能会被某个对象直接篡改。
function Type () {} Type.prototype.objProperty = {a: 1}; Type.prototype.arrProperty = [1,2]; var obj = new Type(); console.log(obj.objProperty) // {a: 1} console.log(obj.arrProperty) // [1, 2] obj.objProperty.a = 111; // 直接修改引用类型的属性值 obj.arrProperty.push(3); // 直接修改引用类型的属性值 // 原型对象中的属性值被修改了 console.log(Type.prototype.objProperty) // {a: 111} console.log(Type.prototype.arrProperty) // [1, 2, 3] console.log(obj); // 输出 {} obj还是空的!!
可以看到, 在实例中尚无该属性,就直接修改属性值时, 对于基本类型和引用类型的属性, 情况是截然相反的。不仅没有在实例对象obj中生成属性, 还直接地把原型对象中的属性篡改了。 这种“不稳定”并不是我们想要的。
所以,一般来说,我们不能把数组或纯对象的数据放到原型中
(不能这样做:)
总结下上面说的1~5点:
在原型机制下:——
1. 在获取原型对象的属性值时,其方式可以和获取实例属性的方式相同。(嗯嗯,挺好的~~)
2. 在查找属性值时,实例对象中没有该属性则可以由原型对象提供属性默认值,如果实例对象有该属性,则屏蔽原型中的属性(嗯嗯,挺好的~)
3. 为实例属性添加属性值时, 无论该值是基本类型还是引用类型, 都不会修改原型对象中的同名属性,而是仅起到屏蔽作用(嗯嗯,挺好的~)
4. 直接修改某属性值(在实例对象中没有,而在原型中有),如果这个属性是基本类型(字符串,数字,布尔型),那么也不会修改原型中的属性,同时在实例对象中会生成修改后的属性值(嗯嗯,挺好的~)
5. 直接修改某属性值(在实例对象中没有,而在原型中有),如果这个属性是引用类型(对象,数组),那么原型中属性会被实例对象直接篡改!同时实例对象并没有添加该属性!(这是什么鬼!!!)
原型在OO体系中暴露的缺陷
大凡了解JS的同学,大概也都知道原型是一个矛盾综合体: 强大却也脆弱, 让人高兴却也让人烦恼。而第5点揭示的就是这种矛盾的集中爆发点。
1到4点都告诉我们:"哎呀protoType在JS面向对象里是多好的一个东西啊! 你看创建实例对象后, 它会提供默认的属性值,而且还赋予实例重写属性这种充分的自由,而且最重要的是——原型看起来很稳定嘛!" 嗯,看起来
可是在第5点中,我们看到,在这种情况下,protoType中的数据一点也不稳定, 这种不稳定性甚至直接让人质疑它是否有理由存在在面向对象的世界中
例如紧接上面第5点中的代码
如下:
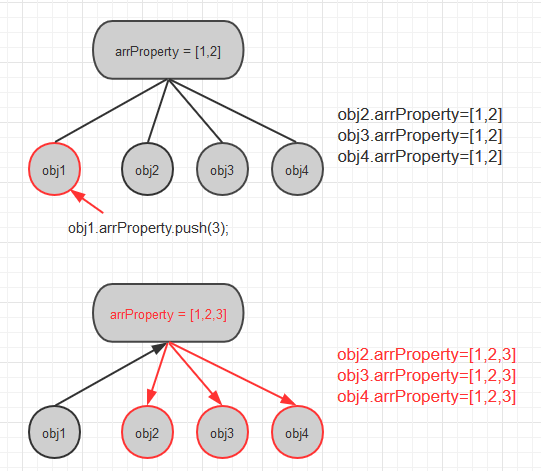
function Type () {} Type.prototype.arrProperty = [1,2]; var obj1 = new Type(); var obj2 = new Type(); console.log(obj2.arrProperty) // [1, 2] obj1.arrProperty.push(3); console.log(obj2.arrProperty); // [1, 2, 3] 我怎么被修改了???
可以看到, 由于引用了prototype对象中的arrProperty, obj2.arrProperty一开始是[1,2],但由于另一个对象obj1直接修改了obj1.arrProperty,而很不巧的是, arrProperty是引用类型, 所以像上面第5点描述的那样,原型对象中的arrProperty属性被篡改了, 所以obj2.arrProperty也被改成了[1, 2, 3]
此时的obj2可谓是一脸"黑人问号脸":为什么我会平白无故地被修改了?? 而且修改我的居然还是和我平起平坐的obj1,这是什么道理呀?
在类和对象的概念中, 我们一般会把类想象成一个静态的模板,而且类才是拥有"控制权"的
在原型模式下, prototype对象就是这个模板, 但我们发现,在上述的某个实例对象直接修改原型的属性值时, prototype这个"类"模板居然会被动态地修改, 而且修改它的是某个对象, 这让它完全丧失了"控制权",而落到了下面的所有对象当中。这是在面向对象中无法让人接受的
所以,一般来说,我们不能把数组或纯对象的数据放到原型中
对原型模式的评价
评价:原型模式是不完善的OO模式, 所以整体上看,它无法独立地完成面向对象设计的各种工作,而需要和构造函数模式配合使用
从作用上看: 原型是对构造函数模式的一种辅助和补充, 或者说某些不足的优化(解决冗余的函数创建的问题)
从地位上看: 构造函数仍然是OO的核心,而原型则在其次
正因如此, 我们大多数时候将原型模式和构造函数模式配合使用来创建对象,这一模式被称为——
三.组合模式创建对象
如果我们将方法和共享的属性放入原型中,而将需要实例化的属性放入构造函数的函数体中,我们就可以既能实现函数复用,同时又能通过构造函数向实例属性传递参数,可以说是集两者之长,而避两者之短, 这就是组合模式
如下所示
function Person (name, age) { this.name = name; this.age = age; this.friends = ['Wang','Li']; } Person.prototype.sayName = function () { return this.name; } var person1 = new Person('Zhang',13); var person2 = new Person('Huang',15); person1.friends.push('Peng') console.log(person1.friends); // ["Wang", "Li", "Peng"] console.log(person2.friends); // ["Wang", "Li"] console.log(person1.sayName()) // Zhang console.log(person2.sayName()) // Huang console.log(person1.sayName == person2.sayName) // true
上面的代码中,因为name, age,friends是实例属性,不同的对象是各不相同的,所以我们把它们放在构造函数中,而sayName方法应该是由不同的对象共享的,所以我们把它放在prototype对象中。
从person1.friends和person2.friends可以看出,创建对象时,实例属性被拷贝了多份不同的副本,它们互不影响,而由person1.sayName == person2.sayName为true可知, 方法调用的是同一个, 这种效果正是我们想的。
哪些属性应该(或可以)被放入原型中?
1. 函数: 应该尽量被放入原型中。
虽然是它引用类型,但在JS里我们一般是没有办法在原来的基础上修改函数的(像array.push())那样,而只能为函数重新赋值,所以不用担心会修改原型中的函数属性
2. 不变的共享属性: 可以被放入原型中
如果一个属性是共享的, 而且确定它在将来也一定不会被修改,那它也可以放入原型中
3. 可能被修改的基本类型的属性: 被放入原型中也不会有问题,但最好不要这样做
没有必要,并且这种写法难以让人理解
JS中的继承
继承是JS面向对象设计的另一大重点, 你会发现,下面我关于继承的分析,和上文创建对象的分析思路是完全相同的
一.借用构造函数实现继承
在JS中,要让一个子类继承父类, 需要在子类的构造函数中通过call方法调用父类的构造函数,同时传入this作为第一个参数,表示将
函数执行的作用域绑定到当前作用域, 如下:
/** * description: 借用构造函数实现继承 */ function superType () { // "父类"构造函数 this.name = "aaa"; this.sayName = function () { return this.name } } function subType () { // "子类"构造函数 superType.call(this); // 调用“父类“的构造函数 } var obj = new subType(); console.log(obj.name); // 输出 aaa console.log(obj.sayName()); // 输出 aaa
向父类的构造函数中写入参数的继承
如果我们想要向父类的构造函数写入参数的话,可以使用call方法的第二个参数:
function superType (name) { // "父类"构造函数 this.name = name; this.sayName = function () { return this.name } } function subType (name) { // "子类"构造函数 superType.call(this,name); // 调用“父类“的构造函数,并传递参数 } var obj = new subType("XXX") console.log(obj.name); // 输出XXX console.log(obj.sayName()); // 输出XXX
但是,同样的问题又出现了, 如果多个子类继承同一个父类, 可能会出现父类构造函数的方法被重复拷贝多次的情况。
于是,为了减少这种冗余的函数拷贝的问题,以节约内存, 原型又特么登场了,这次它带上了它的大舅妈——“原型链”
二.利用原型和原型链实现继承
如下所示:
/** * description: 利用原型和原型链实现继承 */ function superType () { // "父类"构造函数 this.name = 'XXX' } superType.prototype.sayName = function () { return this.name; } function subType () { } // "子类"构造函数 // 创建父类构造函数的实例,并赋给子类的原型 subType.prototype = new superType(); var obj = new subType(); console.log(obj.sayName()); // 输出 XXX
最关键的一句代码是:
subType.prototype = new superType(); // {name: "XXX"}
它具有两个方面的作用:
1. 创建superType的实例{name: "XXX"}, 并作为subType构造函数的原型对象
2. 创建原型链
回顾之前说的:“被创建的实例都有一个指向其构造函数的原型对象的内部指针”,所以结合
subType.prototype = new superType();// #1 var obj = new subType(); // #2
可知, superType实例有一个指向superType.prototype的内部指针,并且通过#1将其赋给了subType.prototype,所以subType.prototype就有了一个指向superType.prototype指针了
而通过#2处的代码使得obj也有了一个指向subType.prototype的内部指针
综上: 现在内部指针的指向是: obj -> subType.prototype -> superType.prototype
这一条内部指针指向形成的链接, 就叫做原型链
原型链下属性的搜索机制
在原型的工作机制下,搜索属性的步骤是:
1> 在实例对象中搜索
2> 在实例对象的构造函数的原型中搜索
而在原型的基础上构造了原型链后, 这个步骤变成了:
1> 在实例对象中搜索 (obj)
2> 在当前的构造函数的原型中搜索 (subType.prototype)
3> 在当前的构造函数的"父类"构造函数的原型中搜索(superType.prototype)
在上述代码中obj.sayName()的调用过程是这样的:
1. 在obj中搜索有无sayName方法——无,向下搜索
2. 在subType.prototype中搜索有无sayName方法—— 无,向下搜索
3. 在superType.prototype中搜索有无sayName方法—— 找到了!,调用该方法返回name属性
(继续。。)
4. 在obj中搜索有无name属性—— 无,向下搜索
5. 在subType.prototype中搜索有无name属性—— 找到了! 返回name的值“XXX”
仅仅使用原型链实现继承的缺点
仅使用原型链实现继承的缺点,和原型模式创建对象的缺点一样:
1. 你无法向父类构造函数中传递参数
2. 依然存在对象篡改原型对象属性,进而影响所有其他对象的问题
function superType () { // "父类"构造函数 this.arr = [1,2] } function subType () { } // "子类"构造函数 subType.prototype = new superType(); var obj1 = new subType(); var obj2 = new subType(); console.log(obj2.arr); // 输出 [1, 2] obj1.arr.push(3); console.log(obj2.arr); // 输出 [1, 2, 3] 卧槽,我又被乱改了!
三.组合继承
故名思义, 组合继承就是指将原型链继承和借用构造函数继承组合在一起,从而发挥两者之长的一种继承模式
具体的思路是: 用原型链实现对方法和共享属性的继承; 而通过借用构造函数实现对实例属性的继承。
这样,既能实现函数复用, 同时又能保证每个属性有它自己的属性
/** * description: 组合继承的例子 */ function SuperType (name) { this.name = name; this.colors = ['red','blue','green']; } SuperType.prototype.sayName = function () { console.log(this.name) } function SubType(name, age) { SuperType.call(this,name); // 继承实例属性 this.age = age; } SubType.prototype = new SuperType(); // 继承方法 SubType.prototype.sayAge = function () { // 写入新的方法 console.log(this.age) } var obj1 = new SubType('Wang', 20); obj1.colors.push('black'); console.log(obj1.colors); // ["red", "blue", "green", "black"] obj1.sayName(); // Wang obj1.sayAge(); // 20 var obj2 = new SubType('Zhang', 23); console.log(obj2.colors); // ["red", "blue", "green"] obj2.sayName(); // Zhang obj2.sayAge(); // 23
要注意的是, 通过SuperType.call(this,name); 拷贝到SubType中的属性,是会覆盖SubType.prototype中的属性的(属性屏蔽) 所以这个时候SubType.prototype = new SuperType();的主要作用是取得对原型链中SuperType.prototype的引用
面向对象中的原型——OO体系和OLOO体系的碰撞和融合
饶了一圈我们还是讲一讲原型吧, 从JS创建对象和继承这两大任务上看, 你已经大体了解到了原型在OO中的重要性, 但却总觉原型的各种原理和表现难以让人理解, 就好像一个外来人进入了一个群体里, 尽管他尽量中规中矩,但看起来却总和周围人事格格不入。
这很正常,因为这个外来人本来就不在这个群体(OO)里面, 而是来自另外一个群体(OLOO)。
实际上,我们可以把面向对象看作一种设计模式(OO), 而把原型所体现的设计模式归结为另外一种设计模式(OLOO)。
OO设计模式
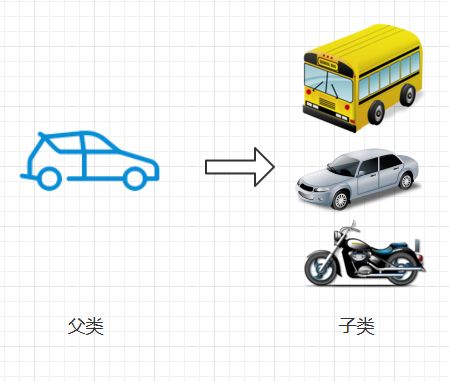
OO,也即面向对象, 在它的世界里, 有一个父类和一堆子类, 父类是定义通用的行为, 而子类在父类的基础上定义更为细化的行为。
一般来说,希望子类的结构和父类大体相同,并鼓励子类通过重写实现多态
举个例子:
我们最常见的交通工具和车子的比喻, 交通工具类Vehicle是一个通用的父类,而car,bus等子类是在父类的基础上细化出来的子类
以下为伪代码
class Vehicle { setColor (color) { this.color = color } setWheels (num) { this.wheels = num } setEngine (num) { this.engine = num } } class Car extends Vehicle { // 继承 setWheels () { this.wheels = 4 } // 方法重写 setEngine (1) { this.engine = 1 } // 方法重写 }
如图
OLOO设计模式
全称是Object linked to Other Object,即对象关联设计模式, 在它的设计里面, 由一个主对象负责提供其他衍生对象所需要调用的方法或属性,其他衍生对象需要某些基础的方法,就
到这个主对象中来“拿”,这个拿的过程,就是方法的委托
例如:
以下为伪代码
// 工具对象 VehicleParts = { setWheels: function (num) { ... } // 安装车轮 setEngine: function (num) { ... } // 安装引擎 } // 衍生对象 Car.protoType = VehicleParts; // 委托 Car.build = function () { setWheels(4); // 4轮子 setEngine(1); // 1引擎 } Bike.protoType = VehicleParts; // 委托 Bike.build = function () { setWheels(2); // 2轮子 setEngine(0); // 0引擎 }
如图
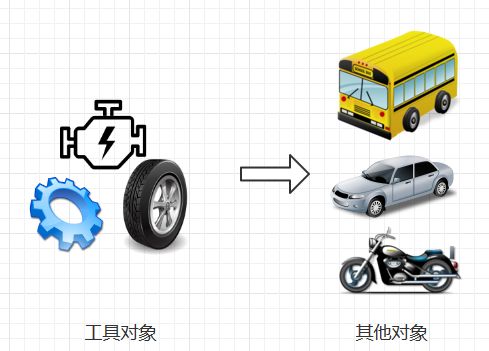
而原型,就是一个来自于OLOO的世界而进入OO的世界的人物
对原型恰当的认知方式
原型一直以来难以让人理解的原因是, 我们竭尽全力想要把它纳入JS面向对象设计的一部分,但是又不得不面对它在使用中诸多不满足面向对象要求的表现, 例如我上面提到的创建对象和继承中它存在的问题。
也许最恰当的认知方式就是: 不要把它看作面向对象体系的一部分。
它是OO体系和OLOO体系的碰撞,也是OLOO体系对于OO的补充,但并它不是OO体系的延伸,从来也不是
