字典树介绍
Paste_Image.png
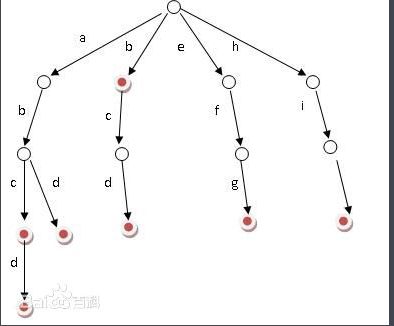
- 又称单词查找树,Trie树,是一种树形结构,是一种哈希树的变种。典型应用是用于统计,排序和保存大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是:利用字符串的公共前缀来减少查询时间,最大限度地减少无谓的字符串比较,查询效率比哈希树高。
特性
- 根节点不包含字符,除根节点外每一个节点都只包含一个字符
- 从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串
- 每个节点的所有子节点包含的字符都不相同。
显然面对大量文本和大量敏感词,利用字典树过滤敏感词是明智而有效的,可以大量的减少重复的抖动,从而降低时间复杂度。
算法描述
- 通过读入的一个个敏感词来构造我们自己的字典树,可以将敏感词放到配置文件中...
- 首先创建字典树的结点。
- 我们可以定义一个boolean成员变量isEnd来标识当前结点是否是敏感词的结尾字,即该节点连上其上面的结点可以构成一个敏感词。
- 定义一个Map成员变量来存储当前结点的所有子节点(一层)(根节点不包含字符)
- 对外提供一些方法如:添加、获得结点。以方便构造字典树
- 结点的类定义代码如下:
private class TrieNode{
/**
* 标识当前结点是否是一个“关键词”的最后一个结点
* true 关键词的终结 false 继续
*/
private boolean isEnd = false;
/**
* 用map来存储当前结点的所有子节点,非常的方便
* key 下一个字符 value 对应的结点
*/
private Map subNodes = new HashMap<>();
/**
* 向指定位置添加结点树
* @param key
* @param node
*/
public void addSubNode(Character key , TrieNode node){
subNodes.put(key , node);
}
/**
* 根据key获得相应的子节点
* @param key
* @return
*/
public TrieNode getSubNode(Character key){
return subNodes.get(key);
}
//判断是否是关键字的结尾
public boolean isKeyWordEnd(){
return isEnd;
}
//设置为关键字的结尾
public void setKeyWordEnd(boolean isEnd){
this.isEnd = isEnd;
}
}
2.构造字典树
/**
* 核心算法一:构建字典树
* 根据输入的字符串,逐步构建字典树
* @param textLine
*/
private void addDirTreeNode(String textLine){
//边界处理
if(textLine == null)
return;
//临时结点指向根结点
TrieNode tempNode = root;
for(int i = 0; i < textLine.length(); i++){
char charWord = textLine.charAt(i);
//直接跳过非法文字
if (isSymbol(charWord))
continue;
TrieNode node = tempNode.getSubNode(charWord);
if (node == null){
//说明tempNode第一次碰到该关键字结点
node = new TrieNode();
tempNode.addSubNode(charWord , node);
}
//tempNode指向下一个结点,开始下一次循环
tempNode = node;
//到敏感词的最后一个字时,标记为红色(关键词结尾)
if (i == textLine.length() - 1)
tempNode.setKeyWordEnd(true);
}
}
3.过滤算法
- 定义三个指针
- tempNode : 指向字典树的根节点。
- position :当前比较的位置,开始下标0
- begin : begin总是不断向前,position匹配失败的时候,需要回滚。开始下标为0.
- position所在位置的字符,字典树的根节点的所有子节点中没有该字符,则说明该字符不可能构成敏感词,因此begin、position均可前进一位,同时tempNode回溯到根节点。
if (tempNode == null){
//以begin开始的字符串不存在敏感词
results.append(text.charAt(begin));
position = begin + 1;
begin = position;
tempNode = root;
}
- position向前不断移动,并且和字典树中的敏感词一一对应,最终到tempNode指向isEnd为true的结点时,匹配成功,需要替换敏感词,并且position需要前进一位,begin移动到和position相同的位置。
else if (tempNode.isKeyWordEnd()){
results.append(DEFAULT_REPLACE_SENSITIVE);
position = position + 1;
begin = position;
tempNode = root;
}
- 过滤算法详细代码
/**
* 核心算法二:
* 过滤文本中的敏感词汇
* @param text
* @return
*/
public String filterWords(String text){
if (StringUtils.isBlank(text))
return text;
StringBuilder results = new StringBuilder();
TrieNode tempNode = root;
int begin = 0;//回滚数
int position = 0;//当前比较的位置
while (position < text.length()){
char word = text.charAt(position);
if (isSymbol(word)){
if (tempNode == root){
results.append(word);
++begin;
}
++position;
continue;
}
tempNode = tempNode.getSubNode(word);
if (tempNode == null){
//以begin开始的字符串不存在敏感词
results.append(text.charAt(begin));
position = begin + 1;
begin = position;
tempNode = root;
}else if (tempNode.isKeyWordEnd()){
results.append(DEFAULT_REPLACE_SENSITIVE);
position = position + 1;
begin = position;
tempNode = root;
}else {
++position;
}
}
results.append(text.substring(begin));
return results.toString();
}
算法实现
优化点
- 过滤非法字符(颜文字、空格...)即不可能组成敏感词的字符,提高算法准确性、性能...。
/**
* 判断是否是非法字符(即不可能存在敏感词汇的字)
* @param character
* @return true:非法字符
*/
private boolean isSymbol(Character character){
int ic = (int)character;
//东亚文字 0x2e80 —— 0x9fff
return !CharUtils.isAsciiAlphanumeric(character) && (ic < 0x2e80 || ic > 0x9fff);
}
全部源码
import java.util.HashMap;
import java.util.Map;
public class Test {
//默认敏感词替换符
private static final String DEFAULT_REPLACEMENT = "敏感词";
//根节点
private TrieNode rootNode = new TrieNode();
private class TrieNode {
/**
* true 关键词的终结 ; false 继续
*/
private boolean end = false;
/**
* key下一个字符,value是对应的节点
*/
private Map subNodes = new HashMap();
/**
* 向指定位置添加节点树
*/
void addSubNode(Character key, TrieNode node) {
subNodes.put(key, node);
}
/**
* 获取下个节点
*/
TrieNode getSubNode(Character key) {
return subNodes.get(key);
}
boolean isKeywordEnd() {
return end;
}
void setKeywordEnd(boolean end) {
this.end = end;
}
}
//判断是否是一个符号
private boolean isSymbol(char c) {
int ic = (int) c;
// 0x2E80-0x9FFF 东亚文字范围
return !((c >= '0' && c <= '9') || (c >= 'a' && c <= 'z')|| (c >= 'A' && c <= 'Z')) && (ic < 0x2E80 || ic > 0x9FFF);
}
/**
* 过滤敏感词
*/
public String filter(String text) {
if (text.trim().length() == 0) {
return text;
}
String replacement = DEFAULT_REPLACEMENT;
StringBuilder result = new StringBuilder();
TrieNode tempNode = rootNode;
int begin = 0; // 回滚数
int position = 0; // 当前比较的位置
while (position < text.length()) {
char c = text.charAt(position);
// 空格直接跳过
if (isSymbol(c)) {
if (tempNode == rootNode) {
result.append(c);
++begin;
}
++position;
continue;
}
tempNode = tempNode.getSubNode(c);
// 当前位置的匹配结束
if (tempNode == null) {
// 以begin开始的字符串不存在敏感词
result.append(text.charAt(begin));
// 跳到下一个字符开始测试
position = begin + 1;
begin = position;
// 回到树初始节点
tempNode = rootNode;
} else if (tempNode.isKeywordEnd()) {
// 发现敏感词, 从begin到position的位置用replacement替换掉
result.append(replacement);
position = position + 1;
begin = position;
tempNode = rootNode;
} else {
++position;
}
}
result.append(text.substring(begin));
return result.toString();
}
/**
* 构造字典树
* @param lineTxt
*/
private void addWord(String lineTxt) {
TrieNode tempNode = rootNode;
// 循环每个字节
for (int i = 0; i < lineTxt.length(); ++i) {
Character c = lineTxt.charAt(i);
// 过滤空格
if (isSymbol(c)) {
continue;
}
TrieNode node = tempNode.getSubNode(c);
if (node == null) { // 没初始化
node = new TrieNode();
tempNode.addSubNode(c, node);
}
tempNode = node;
if (i == lineTxt.length() - 1) {
// 关键词结束, 设置结束标志
tempNode.setKeywordEnd(true);
}
}
}
public static void main(String[] argv) {
Test s = new Test();
s.addWord("sb");
s.addWord("zz");
System.out.print(s.filter("klsfjkzzlsO(∩_∩)Odjflksbj"));
}
}
- 运行结果
klsfjk敏感词lsO(∩_∩)Odjflk敏感词j