原文地址
本文简单的介绍了数据库,以及如何在 Node/Express 中应用他们。之后展示如何使用Mongoose为一个图书网站提供数据访问。介绍了Mongoose的模式和模型的声明,主要属性类型,基础校验器。也展示了访问数据模型的几种主要方法。
概括
图书管理员将使用一个 图书管理网站 去记录书籍和借书人的信息,同时读者会使用 图书管理网站 去浏览搜索图书,去查看是不是某书全部借出,然后预约或直接借走该书。为了更有效率存储信息,这里我们需要一个数据库。
Express提供了多种数据库的支持,你有多种方式去实现增删查改操作。本文简要的概述了一些可用的选项,并详细说明一些查询的特殊机制。
使用什么数据库?
Express应用可以使用Node支持的各种数据库(Express本身对数据库并没有特殊要求)。常用的选项包括PostgreSQL,MySQL,Redis,SQLite,MongoDB。
当选择一个数据库时,我们需要考虑的常常有 时间成本,学习曲线,性能,备份和回滚的易用性,成本以及其社区支持情况。虽然并没有一个最好的数据库,但是对于我们的 图书管理网站 这样的小型网站,任何流行的数据库都是可以的。
如何更好的与数据库交互?
与数据库交互有两种方法:
- 使用数据库的自带的查询语言(比如SQL)
- 使用对象数据模型("ODM")或对象关系模型 ("ORM")。一个ODM或ORM对象代表的就是一个映射到底层数据库的数据对象比如说JSON对象。一些ORM对象是指定数据库的,一些则不然。
使用SQL语言或者其他数据库支持的语言可以获得很好的性能。ODM则相对比较慢,因为需要代码去转换映射的对象和数据库中的格式,所以他生成的查询语句可能不够高效(尤其是在ODM为了支持不同的数据库后台,这时必须对数据库功能做出极大的妥协)。
使用ODM的优势在于程序员可以一直关注与JavaScript 对象而不是数据库语义,尤其是在你需要和不同的数据库交互(可能是同一应用,或不同应用)。ODM也提供了清晰方式去校验检查数据。
使用ODM或ORM可以降低开发和维护成本,除非你非常擅长原生查询语言,或对性能要求很高,否则你都应该优先考虑使用ODM或ORM。
使用什么ODM/ORM
在npm中有许多ODM、ORM。
在本文写作时几个热门的框架
- Mongoose:Mongoose是一个用于异步环境的MongoDB的对象模型。
- Waterline:提取自基于Express的Sail框架的对象关系模型。他为众多数据库提供了统一的API接口,包括 Redis, mySQL, LDAP, MongoDB, 和 Postgres。
- Bookshelf:同时具备promise和传统回调函数的接口,提供了对事务的支持,eager/nested-eager relation loading(不知道咋翻),集成多态,支持 一对一,一对多,多对多关系。支持PostgreSQL, MySQL, 和 SQLite3。
- Objection:尽可能的简化的使用数据库和SQL的全部功能(支持SQLite3, Postgres 和 MySQL)
- Sequelize:基于promise的ORM...
在选择解决方案时一般应该考虑他们都提供哪些功能,以及他们社区的活跃度(下载,捐款,Bug报告,文档质量)。在此文写作时Mongoose当前最受欢迎的ORM,如果你在你的应用中使用MongoDB作为你的数据库,那么他是一个合理的选择。
在LocalLibrary(这篇文章中的项目名)使用MongoDB和Mongoose
在本文中我们使用Mongoose来访问我们的图书数据。Mongoose作为MongoDB的前端,MongoDB是一个开源的NoSQL,使用面向文档的对象模型的数据库。在MongoDB中 集合(collection)中的文档(documents)类似于关系数据库中的表(table)中的行(row)。
这对ODM和数据库组合在Node的社区中是非常流行的,部分原因是因为文档存储和查询起来非常类似于JSON,对于JS程序员这是非常熟悉的。
你不必为了使用Mongoose而去了解MongoDB,但是如果你已经了解MongoDB,可以更容易的使用和理解Mongoose
教程后续部分将讲解如何为LocalLibrary定义以及使用Mongoose模板和模型。
LocalLibrary的model设计
当你开始进行model编码的时候,花一些时间考虑你应该需要存储什么数据,以及不同对象之间的关系。
我们知道我们需要存储有关书籍的信息(书名,概要,作者,类型,书号),而且一种书我们可能有多本(拥有唯一的ID,可用状态),我们可能也需要存储除了姓名之外其他的作者信息,而且可能会有多个作者名是相同或相似的。我们还想能够通过 书名,作者,书的类别进行排序。
当你设计你的Model时为不同的Object(拥有一组相关的信息的对象)设置不同的Model是必要的。在当前的实例中明显的对象有 书籍,书籍实体,作者。
你可能也想为一个下拉列表选项新建一个Model。相对于硬编码,当下拉列表不确定或经常更改,这种方式更加推荐。在本例中书籍类型(科幻小说,法国诗歌)明显就是属于这种类型。
一旦我们确定了Model和相应的属性,我们就需要思考他们之间的关系。
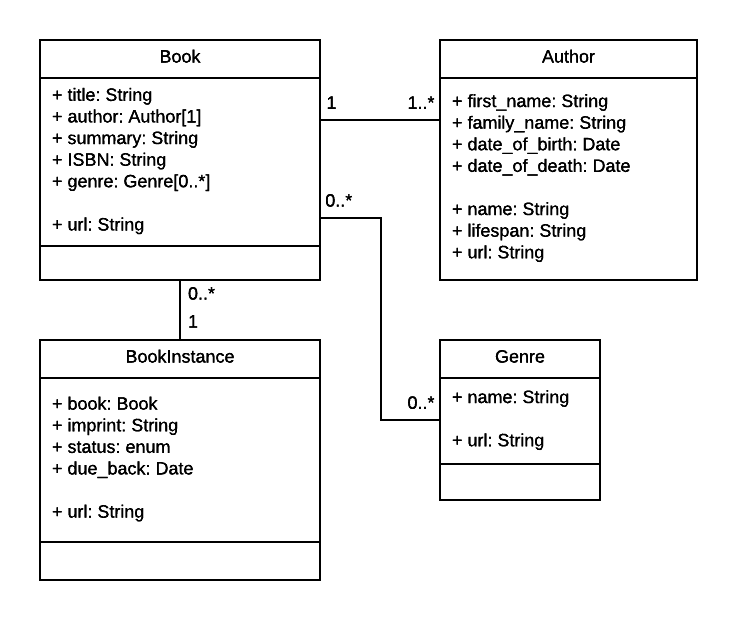
考虑到这一点,下面的UML关系图展示了当前我们定义的Model。根据上文的讨论,我们将为书籍(包含书籍的一般信息),书籍实体(包含这本书在系统中的状态),作者 创建Model。同时我们也决定为书籍的类别创建一个Model,这样书的类别就可以动态修改。书籍实体的状态并不常变化,我们不会为他单独创建Model。在每个方块中我们定义了Model的名字,以及属性名和类型,还有方法名和方法返回值的类型。
该图也展示了Model直接的关系,和他们数量的对应关系(最大和最小)。比如在Book和Genre之间的连线,在靠近Book的数字表示一本书有0或者多个Genre,而另一端的数字表示每个Genre有0或者多个Book
Mongoose入门
这部分概括了如何用Mongoose连接MongoDB,如何定义Schema(这个之前被我翻成模板,不知道对不对,后面索性不返了) 和Model,如何进行简单的查询。
安装Mongoose和MongoDB
Mongoose和其他的依赖一样被安装,使用以下命令为你的项目安装Mongoose。
npm install mongoose --save
安装Mongoose会自动加入他的依赖,例如MongoDB的驱动,但并没有安装MongoDB数据库本身。如果你想要安装MongoDB你可以从这里下载多个平台的安装包。你也可以使用云端的MongoDB实例。
提示:在本文中我们将使用mLab的云端作为数据库。这样非常适合开发,对于这个教程这样做也是有意义的,因为他使安装过程不依赖读者的操作系统。
连接到MongoDB
Mongoose会向MongoDB请求连接。你能够使用require()引入Mongoose,并使用mongoose.connect()连接到本地数据库,如下所示:
//Import the mongoose module
var mongoose = require('mongoose');
//Set up default mongoose connection
var mongoDB = 'mongodb://127.0.0.1/my_database';
mongoose.connect(mongoDB);
//Get the default connection
var db = mongoose.connection;
//Bind connection to error event (to get notification of connection errors)
db.on('error', console.error.bind(console, 'MongoDB connection error:'));
用mongoose.connection你可以获得Mongoose的默认Connection 对象。一旦连接完成,open 事件将从Connection 实例中发射。
提示:如果你需要额外的Connection,你可以使用mongoose.createConnection(),他接受一个和connect()相同格式的数据库URI(包含host,数据库名,端口,选项),返回一个Connection 实例。
定义并创建Model
Model是使用Schema 接口来定义。Schema 用来定义存储在document 中的属性,并且赋予他们校验的规则,和默认值。另外你可以定义静态 或 实体 的helper方法,使你的数据类型更加易于使用。你也可以定义像其他属性一样使用的虚拟属性,这些属性并不会被保存到数据库中(这些会在后文中讲解)。
Schema使用mongoose.model()去“编译”入Model。一旦拥有一个model ,你可以使用他用来创建,查询,删除指定的对象。
Model对应的是MongoDB中documents的collection,documents中包含在Schema中的定义的属性和属性对应的类型。
定义Schema
下面的代码展示了如何定义一个简单的Schema。首先引入mongoose,然后使用Schema的构造方法新建一个Schema的实例,在构造函数的参数对象中定义属性。
//Require Mongoose
var mongoose = require('mongoose');
//Define a schema
var Schema = mongoose.Schema;
var SomeModelSchema = new Schema({
a_string: String,
a_date: Date
});
在上面的例子中,我们只有两个属性,一个字符串,一个时间。在本文的下一段我们会展示其他属性类型,和校验器和其他方法。
创建一个Model
Model是使用mongoose.model()创建自Schema。
// Define schema
var Schema = mongoose.Schema;
var SomeModelSchema = new Schema({
a_string: String,
a_date: Date
});
// Compile model from schema
var SomeModel = mongoose.model('SomeModel', SomeModelSchema );
第一个参数是MongoDB中的集合的名,mongoose将为上面的Model创建一个名为SomeModel的集合。第二个参数是你想要用来创建Model的Schema 。
一旦你创建了Model,你可以使用他来进行增删查改,既可以查询全部记录,也可以查询特定的子集。当我们创建我们的视图时,我们会在“使用Model”段讲解如何做。
Schema 中属性的类型
Schema 可以有任意数量的属性,每一个属性都代表了在MongoDB中的字段。下面的例子展示了常用的属性类型是如何被定义的。
var schema = new Schema(
{
name: String,
binary: Buffer,
living: Boolean,
updated: { type: Date, default: Date.now },
age: { type: Number, min: 18, max: 65, required: true },
mixed: Schema.Types.Mixed,
_someId: Schema.Types.ObjectId,
array: [],
ofString: [String], // You can also have an array of each of the other types too.
nested: { stuff: { type: String, lowercase: true, trim: true } }
})
大多数属性类型的意义是显而易见的,除了以下几项:
- ObjectId:代表在数据库中的一个对象实体,比如,书本对象可以使用他来代表他的作者。实际上他包含的是对象的唯一id(_id)。我们可以在需要的时候使用populate()方法获取某些信息。
- Mixed:任意schema类型。
- []:数组对象。你可以对该对象执行JavaScript数组操作(push, pop, unshift等)。上面的实例展示了,没有指定数组对象类型的数组,和指定为String的数组。你可以指定任意类型的数组。
这段代码也展示来定义属性的两种方法:
- 属性名和属性类型作为键值对。
- 属性名后紧跟一个对象来定义属性类型,以及属性的其他选项。选项包含以下这些:
- 默认值
- 内置的校验器(min/max),或者定制的校验函数。
- 属性是否是必须的。
- 属性是否会自动大写,小写或者去除空格(e.g. { type: String, lowercase: true, trim: true })。
更多有关选项的信息,请看SchemaTypes的文档。
校验器
Mongoose提供来内置的校验器,自定义校验器,同步或者异步校验器。他用来指定可用的范围或者值,以及在校验失败时的错误信息。
内置的校验器包括:
- 所有的类型都包含required校验器。这个校验器是用来指定在保存时,属性是否是必须的。
- Numbers有min 和max校验器。
- Strings类型有:
- enum:指定这个属性所能拥有的值的集合。
- match: 指定值必须满足的正则表达式。
- maxlength 和minlength
下面的样例略微修改自Mongoose的文档,展示来如何指定校验器的类型和错误信息。
var breakfastSchema = new Schema({
eggs: {
type: Number,
min: [6, 'Too few eggs'],
max: 12
required: [true, 'Why no bacon?']
},
drink: {
type: String,
enum: ['Coffee', 'Tea', 'Water',]
}
});
详细的校验器说明,请看Mongoose的文档Validation
虚拟属性
虚拟属性是你可以get和set的对象属性,但是他们不会被保存到MongoDB中。get方法常常被用来格式化或者合并属性,set方法常用来分解单个属性并把他们保存在数据库中的多个属性中。在本例中用first name和last name属性去构造一个全名,相对于每次在使用时来构造一个全名更加清晰和简单。
备注:我们将使用虚拟属性为每条记录的_id属性和地址定义一个唯一URL。
更多信息请看Virtuals
方法和查询助手
schema可以有实体方法,静态方法和查询助手。实体方法和静态方法是类似的,他们之间明显的不同是,实例方法是关联到实际对象的,能够访问当前对象。查询助手允许你扩展mongoose的查询构造器API(比如,你可以添加“byName”查询方法去扩展find(), findOne() 和 findById())。
Model的使用
一旦你创建创建了schema,你就可以使用他来创建Model。Model代表了数据库中Document的Collection,而一个Model的实体代表了一个你可以存取的单一对象。
下面我们提供一个概述,详情请看Models 。
创建和更改document
你可以通过创建一个Model实体并调用save()方法去保存一条记录。下面的例子假设SomeModel是通过schema创建的某个对象(只有一个“name”属性)。
// Create an instance of model SomeModel
var awesome_instance = new SomeModel({ name: 'awesome' });
// Save the new model instance, passing a callback
awesome_instance.save(function (err) {
if (err) return handleError(err);
// saved!
});
注意记录的创建(以及更新,删除,查询)是异步操作,你需要传递一个回调函数,当操作完成时会执行。我们遵从错误优先的惯例,所以回调函数的第一个参数为错误信息,如果有的话。如果操作会返回结果,他将被作为第二个参数。
你也可以使用create()方法,在你定义对象的同时保存他。回调函数将返回错误信息作为第一个参数,创建的实体作为第二个参数。
SomeModel.create({ name: 'also_awesome' }, function (err, awesome_instance) {
if (err) return handleError(err);
// saved!
});
每一个Model都有一个相关的连接对象(当你使用model()方法时,会使用默认方法),你可以创建一个新的连接,并调用他的model()方法,用以在不同的数据库中创建记录。
你可以使用点语法去访问对象属性,更改属性值。你必须使用save()或update()将变更保存到数据库中。
// Access model field values using dot notation
console.log(awesome_instance.name); //should log 'also_awesome'
// Change record by modifying the fields, then calling save().
awesome_instance.name="New cool name";
awesome_instance.save(function (err) {
if (err) return handleError(err); // saved!
});
搜索数据
你可以通过查询方法去检索数据记录,并用JSON对象来指定查询条件。下面的代码展示了如何查询所有参加网球运动的运动员,并只返回姓名和年龄。这里我们只匹配了运动这一个属性,但是你们可以指定更多的检索条件,如一个正则表达式,或者不要任何条件,返回所有数据。
var Athlete = mongoose.model('Athlete', yourSchema);
// find all athletes who play tennis, selecting the 'name' and 'age' fields
Athlete.find({ 'sport': 'Tennis' }, 'name age', function (err, athletes) {
if (err) return handleError(err);
// 'athletes' contains the list of athletes that match the criteria.
})
如果你向上面一样指定了回调方法,查询会马上执行,而回调方法会在查询完成后执行。
在mongoose中所有回调函数都采用了callback(error, result)的形式。如果在查询时发生错误,error中将包含错误信息,而result将返回null。如果查询成功error是null,而result中包含查询的结果。
如果你没有传递回调方法,程序将返回一个Query对象。你可以使用这个query对象去组建你的查询,之后调用exec()方法执行他,并传入回调方法。
// find all athletes that play tennis
var query = Athlete.find({ 'sport': 'Tennis' });
// selecting the 'name' and 'age' fields
query.select('name age');
// limit our results to 5 items
query.limit(5);
// sort by age
query.sort({ age: -1 });
// execute the query at a later time
query.exec(function (err, athletes) {
if (err) return handleError(err);
// athletes contains an ordered list of 5 athletes who play Tennis
})
上面的代码中,我们在find中指定了查询条件。我们也可以使用where()方法,他能够使用(.)点语法将所有查询条件连接起来,而不用分别指定。下面的代码等同于上面的代码,但是我们添加了一个age查询条件。
Athlete.
find().
where('sport').equals('Tennis').
where('age').gt(17).lt(50). //Additional where query
limit(5).
sort({ age: -1 }).
select('name age').
exec(callback); // where callback is the name of our callback function.
find()方法会查询所有匹配的记录,但是通常我们只需要其中的一条。下面的方法用以查询一条记录:
- findById():通过id查询
- findOne():依照一定的条件查询一条记录。
- findByIdAndRemove(), findByIdAndUpdate(), findOneAndRemove(), findOneAndUpdate(): (这个自己看名字也知道了,我就不翻了)
提示:也有count()方法,获取指定条件的记录数。常常用于,你只想要知道数目而不是实际的记录时。
查询中你还可以作很多,详情请看:Queries。
处理相关的对象 -----热门
你可以使用ObjectId 属性类型创建一个索引连接两个对象,或者使用ObjectId 的数组去连接多个对象。这个属性存储着model的id。如果你需要关联对象的实际内容,你可以使用populate()方法去查询并替换id为真实数据。
例如,一下的schema定义了作者和故事。每个作者有多个故事,我们将使用ObjectId 数组来表示他们。一个故事只有一个作者。"ref"属性(高亮加粗显示的,makedown)告诉schema 连接哪个model。
var mongoose = require('mongoose')
, Schema = mongoose.Schema
var authorSchema = Schema({
name : String,
stories : [{ type: Schema.Types.ObjectId, ref: 'Story' }]
});
var storySchema = Schema({
author : { type: Schema.Types.ObjectId, ref: 'Author' },
title : String,
});
var Story = mongoose.model('Story', storySchema);
var Author = mongoose.model('Author', authorSchema);
我们可以使用_id值去保存关联对象的索引。下面我们创建一个author,之后是一个book对象,并关联author对象到author属性。
var bob = new Author({ name: 'Bob Smith' });
bob.save(function (err) {
if (err) return handleError(err);
//Bob now exists, so lets create a story
var story = new Story({
title: "Bob goes sledding",
author: bob._id // assign the _id from the our author Bob. This ID is created by default!
});
story.save(function (err) {
if (err) return handleError(err);
// Bob now has his story
});
});
我们的story对象依靠id获得了author的索引。为了获得详细的author信息我们使用populate()方法。如下:
Story
.findOne({ title: 'Bob goes sledding' })
.populate('author') //This populates the author id with actual author information!
.exec(function (err, story) {
if (err) return handleError(err);
console.log('The author is %s', story.author.name);
// prints "The author is Bob Smith"
});