1. 导入
这是语言表示系列的第1篇,主要讲述了分布式表示里的Word2vec方法。该系列目前暂定有4篇语言的分布式表示(Distributed Representations)学习,分别是Word2Vec、Doc2Vec、字符级别的Word2Vec和Glove;几篇词语的分布式表示(Distributional Representations),分别是:潜在语义分词模型(LSA)、潜在地理克雷分配模型(LDA)和随机索引(random indexing);还有几篇是文本特征,分别讲了:VSM、n-gram、词袋和TF-IDF等。
参考[1] 提到:词语的离散表示一般独热编码(one-hot encode),句子或篇章一般用词袋模型、TF-IDF模型、N元模型等进行转换(我的理解:这就是文本的特征工程),这些方法还需要引入人工知识库,比如同义词词典、上下位词典等,才能有效地进行后续的语义计算。对这种方法的改进有基于聚类的词表示,比如Brown聚类算法,通过聚类得到词的类别簇来改进词的表示。词语除了离散表示外还有分布式表示(Distributional Representations)和分散式表示(Distributed Representations):分布式表示基于Harris的分布式假设:如果两个词的上下文相似,那么这两个词也是相似的;而分散式表示也称为分布式表示,分散式表示将词语的潜在语法或语义特征分散式地存储在一组神经元中(该层就是基于文本的深度学习网络中的Embedding lookup 层),用稠密、低维、连续的向量表示,也称为嵌入(Embedding)。上述两种表示有一定的区别。 分散式表示是指一种语义分散存储的表示形式,而分布式表示是通过分布式假设获得的表示。 但这两者并不对立,比如 Skip-Gram、 CBOW 和 glove等模型得到词向量,即是分散式表示,又是分布式表示。(我的理解:1、分布式表示得到的向量在使用的时候是不变的。分散式表示得到的向量是随着训练过程而更新的;2、在Encoder-Decoder神经网络中,得到的中间语义向量就是分散式表示的一种;3、基于文本的深度学习网络对Embedding层训练的1个Trick是在模型训练的开始阶段不更新Embedding层参数,到模型微调的时候再更新,防止过拟合)
2. Word Embedding的一种实现:Word2Vec
根据维基百科的概念,Word embedding是指把一个维数为所有词的数量的高维空间嵌入到一个维数低得多的连续空间向量中,每个单词或词组被映射为实数域上的向量。其实就是把One-hot表示的词转化成分布式表示的词,好处当然是可以消除词的语义鸿沟。关于分布式表示确实地降低了维度,但是能不能化简计算这个问题,在这篇苏剑林同学的博文里有提到,并不会维度降低可以减少计算量。下面我会搬运其中一部分进来。
搬运中 ...
搬运中 ...
Word2Vec还有一个有趣的特性,Word Analogy,这里有一个Word Analogy的讨论。
Word2Vec就是Word Embedding的一种方法,而且是目前为止效果最好的词向量表示方法。
3. Word2Vec的原理
Word2Vec可以看做是通过神经网络来训练N-gram语言模型,并在训练过程中求出word所对应的vector的方法,根据语言模型的不同,可以分为CBOW(连续词袋模型)和Skip-gram两种模型,而根据两种降低训练复杂度的方法又可以分为Hierarchical Softmax和Negative Sampling,根据排列组合,Word2Vec有4种实现方式。
3.1 连续词袋模型(Continuous Bag-of-Word Model / CBOW)
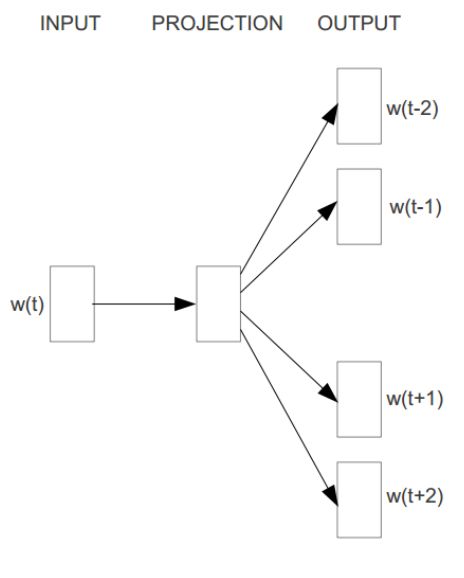
CBOW也被称为连续词袋模型,是一个3层神经网络,如下图所示,神经网络的输入层是当前单词w(t)的前n-1个词w(t-n+1) ~ w(t-1) 和后n-1个词w(t+1) ~ w(t+n-1),与n-gram不同,n-gram是前n-1个词预测第n个词,神经网络的输出层是当前单词w(t)。CBOW是神经网络语言模型(Neural Network Language Model / NNLM)的一种,NNLM的介绍参见Deep Learning in NLP (一)词向量和语言模型,参考文献[3] 提到,区别有3点:1、(从输入层到投影层的操作)NNLM是通过拼接,CBOW是通过累加求和 2、(隐藏层)NNLM有隐藏层,CBOW没有隐藏层 3、(输出层)NNLM是线性结构,CBOW是树形结构。

CBOW在Hierarchical Softmax下的加速在3.3.1。
3.2 Skip-gram Model
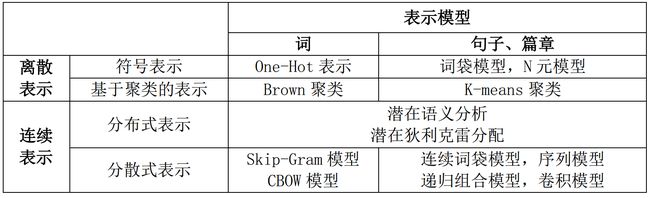
Skip-gram模型刚好是CBOW模型反过来,如下图所示:Skip-gram模型的输入时当前词w(t),输出是当前词的前n-1个词w(t-n+1) ~ w(t-1) 和当前词的后n个词 w(t+1) ~ w(t+n-1)。 其中投影层其实是多余的,只是方便比较,是一个恒等投影。
3.3 Hierarchical Softmax
3.3.1 CBOW + Hierarchical Softmax
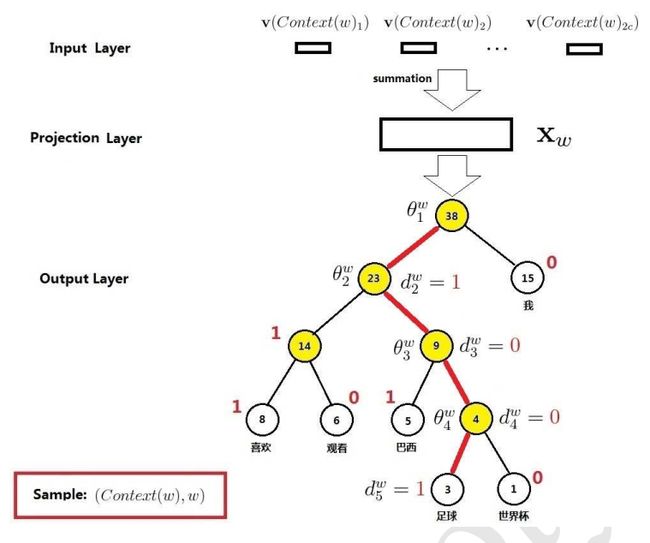
3.3.2 Skip-gram + Hierarchical Softmax
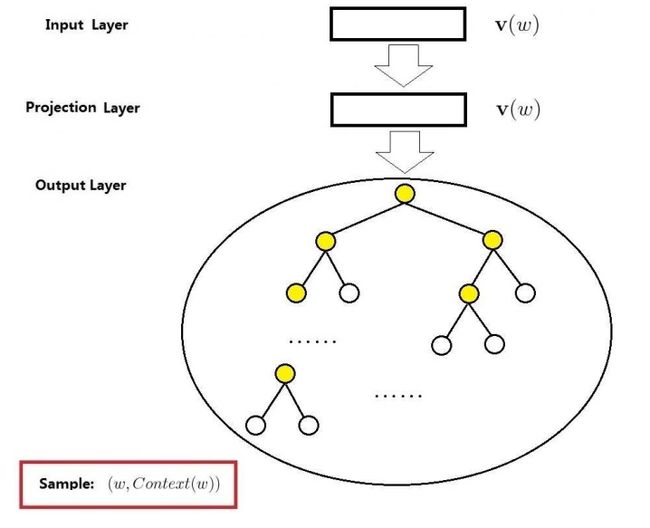
3.4 Negative Sampling
4. Word2Vec的实现和技巧
4.1 哈夫曼树的构造
4.2 负采样
5. Word2Vec的Tricks
5.1 n-gram的n如何设置
6. Word2Vec的使用:gensim.models.Word2Vec
6.1 输入、输出和流程
输入:已经分词好的语料,标准的格式为句子的序列,每个句子是一个单词列表。
输出:Word2Vec模型
流程:
1、建立一个空的模型对象:model = gensim.model2.Word2Vec()
2、遍历一次语料库建立词典:model.build_vocab(sentences)
3、第2次遍历语料库简历神经网络模型:model.train(sentences)
6.2 相关参数
gensim.models.Word2Vec(sentences=None, size=100, alpha=0.025, window=5, min_count=5, max_vocab_size=None, sample=1e-3, seed=1, workers=3, min_alpha=0.0001,
sg=0, hs=0, negative=5, cbow_mean=1, hashfxn=hash, iter=5, null_word=0,
trim_rule=None, sorted_vocab=1, batch_words=MAX_WORDS_IN_BATCH, compute_loss=False)
sentences:可迭代对象,提供了BrownCorpus和Text8Corpus两个语料库的可迭代对象,同时提供了如果分词好的语料是一行一个句子,单词之间用空格隔开,使用gensim.models.word2vec.LineSentence(corpus_file_path)可以帮忙处理得到标准的输入格式
sg:训练方式:CBOW或Skip-gram
size:词向量维度
alpha:初始学习率,会慢慢降到min_alpha
windows:n-gram里的n
min_count:忽略出现次数少于min_count的单词
max_vocab_size:限制词典大小,超出这个数时会把出现次数最少的数去掉
sample:
seed:
workers:worker threads个数
hs:是否使用Hierarchical Softmax
negative:负采样的个数:通常5-20
cbow_mean:if 0, use the sum of the context word vectors. If 1 (default), use the mean. Only applies when cbow is used.
hashfxn:hash function to use to randomly initialize weights, for increased training reproducibility. Default is Python's rudimentary built in hash function.
iter:在语料库上的迭代次数
build_vocab(sentences, keep_raw_vocab=False, trim_rule=None, progress_per=10000, update=False)
trim_rule:vocabulary trimming rule, specifies whether certain words should remain in the vocabulary, be trimmed away, or handled using the default (discard if word count < min_count). Can be None (min_count will be used), or a callable that accepts parameters (word, count, min_count) and returns either utils.RULE_DISCARD, utils.RULE_KEEP or utils.RULE_DEFAULT. Note: The rule, if given, is only used to prune vocabulary during build_vocab() and is not stored as part of the model.
keep_raw_vocab:
update:If true, the new provided words in word_freq dict will be added to model's vocab.
model.train(sentences, total_examples=None, total_words=None, epochs=None, start_alpha=None, end_alpha=None, word_count=0, queue_factor=2, report_delay=1.0, compute_loss=None)
total_examples:To support linear learning-rate decay from (initial) alpha to min_alpha, and accurate progres-percentage logging, either total_examples (count of sentences) or total_words (count of raw words in sentences) MUST be provided. 如果和上一步骤的语料库一样,设置为corpus_count
epochs:必须设置。To avoid common mistakes around the model's ability to do multiple training passes itself, an explicit epochs argument MUST be provided. In the common and recommended case, where train() is only called once, the model's cached iter value should be supplied as epochs value.
6.3 模型的使用
模型的保存:
模型的加载:
获取词向量:
计算1个词的最近似词,倒排序:
计算2个词之间的余弦相似度:
计算2个集合之间的余弦相似度:
选出集合中不同类的词语:
7. 连词成句和连词成篇
8.1 连词成句
8.2 连词成篇
7. 后记
1、Sentence2Vec和Doc2Vec
2、语言模型其实就是看一句话是不是正常人说出来的。这玩意很有用,比如机器翻译、语音识别得到若干候选之后,可以利用语言模型挑一个尽量靠谱的结果。语言模型形式化的描述就是给定一个字符串,看它是自然语言的概率 P(w1,w2,…,wt)。w1 到 wt 依次表示这句话中的各个词。有个很简单的推推论:
P(w1,w2,…,wt) = P(w1)×P(w2|w1)×P(w3|w1,w2)×…×P(wt|w1,w2,…,wt−1)
常用的语言模型都是在近似地求 P(w1,w2,…,wt)。比如 n-gram 模型就是用 P(wt|wt−n+1,…,wt−1) 近似表示前者。NNLM就是用神经网络来近似计算n-gram。
参考
[1] 中文信息处理发展报告:http://202.119.24.249/cache/10/03/cips-upload.bj.bcebos.com/6707f4dec86696713877d94afa2fab44/cips2016.pdf
[2] 词向量和Embedding究竟是怎么回事?: http://kexue.fm/archives/4122/
[3] Word2Vec中的数学:https://spaces.ac.cn/usr/uploads/2017/04/2833204610.pdf
[4] Deep Learning实战之Word2Vec:https://spaces.ac.cn/usr/uploads/2017/04/146269300.pdf