A Sequential Matching Framework for Multi-turn Response Selection in Retrieval-based Chatbots

简介:针对多轮对话的response selection,关键在于如何选择上文相关信息进行建模。目前存在的模型大都单独对上文信息进行建模,忽略了response与context之间的交叉特征。作者提出了序列匹配模型(sequential matching framework (SMF)),计算context中每轮query与response的交互特征,然后通过时序模型RNN对交互特征进行建模,最后将时序模型的hidden state作为最终的特征用于计算模型匹配得分。实验结果证明,该模型取得了state of art的效果。
- 将用户历史所有query通过表征函数进行编码,候选答案通过另一个表征函数进行编码
- 用户多轮对话过程是一个时序过程,因此可以通过时序模型对历史query进行编码
- 最后通过匹配函数融合时序模型输出和答案编码向量
Unified Framework Of Matching Model
匹配模型可以通过如下公式进行定义
Deep Learning To Respond (DL2R) Architecture
代表词向量矩阵,因此句子的表示可以通过如下公式获得
首先通过启发式的方法将context转换为
-
启发式的方法
- no context,
- whole context,
- add-one,
- drop-out, ,表示从context中排出
代表胶状向量,拼接向量为一个长向量
Multi-View匹配模型
其中,和分别表示词粒度的特征和句子粒度的特征
同理,可以通过如下公式计算
context特征可以通过如下公式计算
其中,词粒度的特征和句子粒度的特征可以通过如下公式计算
模型的完整计算公式如下
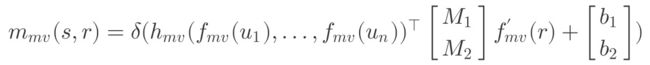
其中,M1和M2代表特征的线性变化
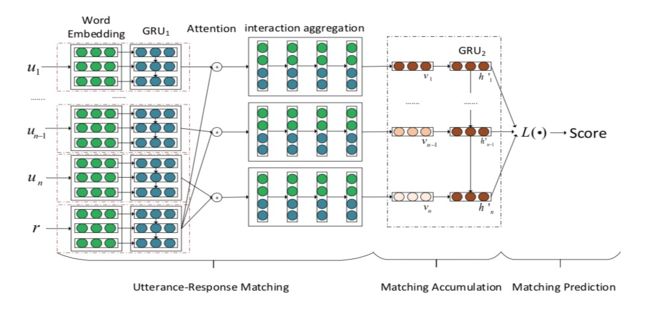
SMF

简介:SMF模型与之前模型的主要区别:1.在模型的底层计算context中query与response的交叉信息;2.采用query与response交互作用的特征进行时序建模,这两个区别克服了现有模型的缺点。
将context中每一个query与answer做线性变换
将线性变换之后的输出做为时序模型的输入
-
最后通过匹配函数融合时序模型输出
SMF模型可以通过如下公式进行总结
Utterance-Response Matching
SCN

计算query和answer之间的词级相似度矩阵
计算句子间的相似度矩阵。分别将context和response输入时序模型进行编码
然后,将和输入2D卷积神经网络
其中,在卷积神经网络之后,接一层max-pooling
最后,将max-pooling之后的特征进行拼接,并投影到低维特征空间
SAN
权重矩阵计算如下
其中,和是训练参数。代表context与response之间的相关程度。
和之间的交叉矩阵计算公式
其中,代表Hadamard product。
同理,可以对句子粒度的特征执行相似处理得到
在获得词粒度和句子粒度的特征之后,将这两类特征进行拼接输入时序模型
Matching Accumulation
SCN和SAN模型都采用GRU作为时序模型对特征进行编码,通过标准时序模型的门函数加强重要特征的权值,减少不重要信息带来的影响。-
Matching Prediction
Last State
第一个方法就是直接取时序模型的最后一个状态做为匹配得分。该方式基于上下文的重要特征通过GRU门函数之后,被编码在向量
其中,和为参数向量Static Average
第二个方法通过所有hidden states的位置进行加权,如下:
是第个hidden state的权值,一旦确定,对于任何都是固定的,因此我们称之为static average。与第一种方式相比,static average可以利用更多的信息,避免信息的损失。Dynamic Average
与static average相似,我们同样采用所有hidden states来计算匹配得分。不同之处在于,由hidden state和query向量通过attention机制动态计算。不同的上下文,将会计算得到不同的权值,因此称之为dynamic average。
其中,是训练中学习的虚拟上下文向量。
Multi-Turn Response Selection for Chatbots with Deep Attention Matching Network
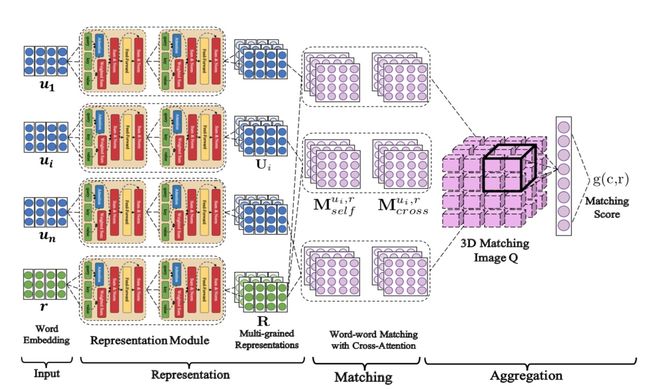
简介:受Transformer的启发,作者从2个方面扩展了attention mechanism:1)通过叠加self-attention,作者构建了不同粒度的文本片段表示;2)通过context与response利用attention抽取真正匹配的文本片段。实验结果证明,该模型的效果远远优于目前的state-of-the-art模型。
-
Attentive Module
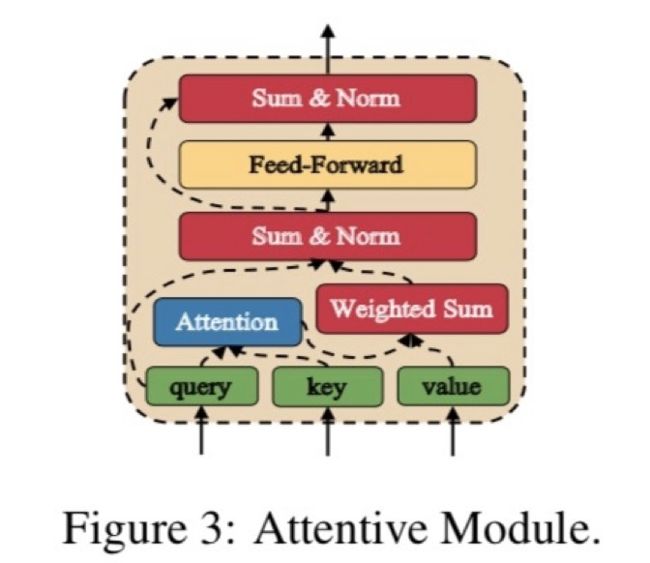
Attentive Module有三个输入:query sentence、key sentence和value sentence。Attentive Module首先计算query sentence与key sentence的相似矩阵,然后将attention结果应用在value sentence中
其中,、和代表句子中词的个数,代表维的embedding向量,和相等。
融合了词之间的语义信息之后,将和相加,从而得到一个新的词表示。为了避免梯度消失和梯度爆炸的问题,模型接了一层layer normalization;然后,输入前馈神经网络FFN,激活函数为
参考residual network,将与相加(与维度相同)作为最终的特征。
Representation
其中,。至此得到了不同粒度的表示和。Utterance-Response Matching
根据不同层之间的词粒度表示,通过如下公式计算context与response之间相关性
cross-attention顾名思义,即是在attention计算阶段就计算context与response之间的相关性
Aggregation
至此,我们得到了一个三维的特征表示
其中,表示Attentive Modulue的深度,表示context中第i轮utterance词的个数,表示response词的个数。每一个pixel的定义如下
其中,表示concatenation。接着,作者通过2层3D的CNN抽取文本的匹配的特征,然后flatten特征之后将其输入单层的多层感知机
其中,代表sigmoid函数,表示该是否为正确的答案。DAM模型的损失函数为负对数损失函数
A Context-aware Attention Network for Interactive Question Answering
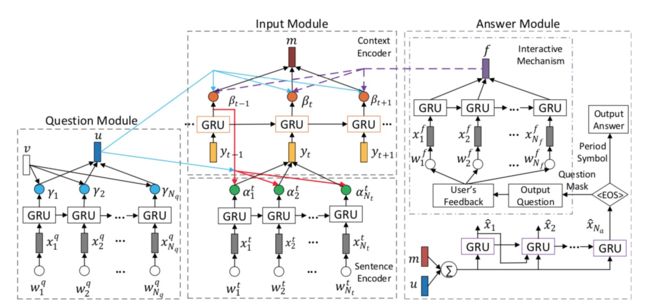
简介:该论文对多轮问答的建模与其他工作稍有不同,网络结构分为三部分:Question Module、Input Module和Answer Module。Question Module负责对当前问题进行特征编码;Input Module负责对上文信息进行特征编码;Answer Module负责对答案进行编码。同时为了获得上文信息与当前问题的关联性,通过Question Module计算得到特征与Input Module计算相关矩阵,保留相关信息,忽略不相关信息。同时为了更好的回答用户的问题,对于不确定的问题,模型并不直接给出答案,而是通过反问的方式,让用户明确自己的问题,然后加入该用户反馈之后再进行回答。实验结果证明,该模型取得了比目前state-of-art更好的效果。
Question Module
首先,对question采用时序模型GRU进行特征编码
然后,通过self-attention对每个词的输出进行加权,获得最终的question表示。
Input Module
对上文句子的每个词采用时序模型GRU进行特征编码
为了添加上句特征,这里采用2层的FFN对上句特征输出和当前GRU状态进行投影
在获得每个词的表示之后,通过question的特征对当前句子进行attention计算,统计句子每个词的相关度,然后通过加权求和的方式获得句子的特征表示。
现在我们得到了上文每个句子的特征表示,接下来我们需要对所有上文句子表示进行处理。因为用户的问题都是具有时序关系的,因此这里采用时序模型GRU对上文所有句子进行编码,然后通过question进行attention计算,并加权求和得到最后的上文特征输出。
-
Answer Module
答案生成模块分为两部分:Answer Generation和Interactive Mechanism。- Answer Generation:根据当前question的特征输出和上文特征输出直接生成答案;
- Interactive Mechanism:则是在不确定Answer Generation能很好回答用户问题时,给出问题的补充问法,从而让用户说的更加完整。
Answer Generation
答案生成模块相对比较简单,对和相加然后通过一个时序模型GRU进行decoder。
Interactive Mechanism
对用户反馈的文本进行时序编码,然后直接求和(这里假设所有词具有同等重要权重)
最后将计算获得的反馈表征用于生成答案。通过用户反馈我们可以判断上文不同句子的重要程度,因此可以通过该反馈表征更新上文权重。
Enhanced Sequential Representation Augmented with Utterance-level Attention for Response Selection
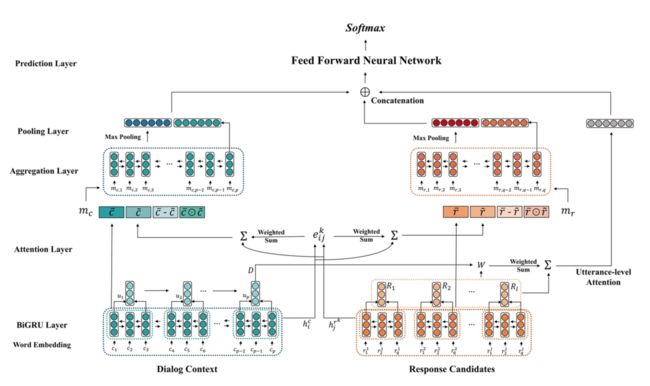
简介:基于检索的聊天机器人,针对多轮问答场景,充分利用句子粒度的表征和词粒度的表征是非常重要的。句子的特征表示包括:通过句子粒度attention获得的Sentence Embedding、位置信息表示和用户信息表示。接着通过sentence-level attention判断最相关的utterances。实验结果证明,该模型的效果优于baseline model。
Dual Encoder
context的特征表示为,response的特征表示为。context与response共享时序模型,因此有
其中,。然后对前后向的输出进行concat
Attention Layer
在对词进行编码之后,通过dot attention计算context与response之间词的相似矩阵
对重要的词赋于更高的权重,词权重的计算如下
至此,我们获得了各自的词对齐特征,因此我们对词编码之后的特征进行增广
Aggregation Layer
由于词之间包含了词上下文关系,因此这里采用了双向的GRU模型来对词粒度的上下文进行建模
Pooling Layer
由于我们最终需要的是句子的表示,因此一个必然的操作就是pooling,这里选择了max-pooling和last hidden组成了pooling layer
Utterance-level Attention Layer
-
utterance embeddings

Sentence Embedding
句子表示由2部分组成:word embedding求平均和时序模型的句子编码Position Embedding
多轮对话中,utterances的位置信息是非常重要的特征。最近的utterances与response有更高的相关性,因此作者将Sentence Embedding和Position Embedding进行拼接来丰富句子的特征。User Embedding
针对2个用户的多轮对话,每个用户都有自己的角色和目的。因此作者对参与者的角色进行one-hot,然后与Sentence Embedding进行拼接。
将utterance embedding输入时序模型(GRU)对句子进行编码获得多轮表示,然后通过bilinear attention对context与response进行匹配
Prediction Layer
词粒度表示和句子粒度表示拼接到一个向量中,然后输入一层的前馈神经网络,激活函数为。
Sequential Attention-based Network for Noetic End-to-End Response Selection

简介:目前处理上下文的模型大部分都是hierarchy-based methods,因此不可避免的问题就是需要选择加入上文的轮数。如果轮数设置较大,上文相对较短的会话不可避免就会大量补零;同时如果设置太小,可能会因为上文信息不够,而导致语义不清。
针对上述问题,本文作者直接将上文信息拼接到一个段文本中,因此将上下文匹配的问题转化为单句匹配问题了。由于把所有的上文信息都拼接到了一段文本中,从而该段文本不可避免会引入大量的噪声,因此如果提取文本中的关键信息,然后与response进行匹配是本文的关键所在。
Input Encoding
文章采用了各种不同的word embedding,然后对每个词的word embedding进行concatenate得到一个维度较高,信息量较大的词向量;最后通过一个前馈神经网络进行降维。
将context向量拼接为一个长文本,response向量为。为了获得上下文信息,文章采用了双向的时序模型(BILSTM)对向量进行编码
Local Matching
context与response的交叉特征是判断两者之间匹配度的重要因子,cross-attention计算公式如下
首先,通过cross-attention可以得到soft alignment,对齐向量包含了context与response的局部相关性
然后,通过可以获得增广特征
其中,是一层的前馈神经网络,激活函数为。Matching Composition
通过时序模型组合匹配特征
然后,通过max-pooling和mean-pooling抽取时序特征
最后,将特征输入MLP计算匹配得分,MLP为一层的前馈神经网络,激活函数为tanh,最后对输出取softmax。
Sentence-encoding based methods
在处理大量候选response的任务时,直接使用ESIM模型耗时过高,因此作者采用了相对简单的孪生网络对response进行粗筛,之后再对粗筛的结果使用ESIM进行rerank。

采用ESIM模型相同的输入编码方式,然后对时序模型的输出进行加权求和
其中,,是权重矩阵,是一个可调的多头参数。
句子向量可以通过权重矩阵对时序模型输出加权求和计算得到
最后,通过concat、difference和 the element-wise products对特征进行增广
Multi-level Context Response Matching in Retrieval-Based Dialog Systems
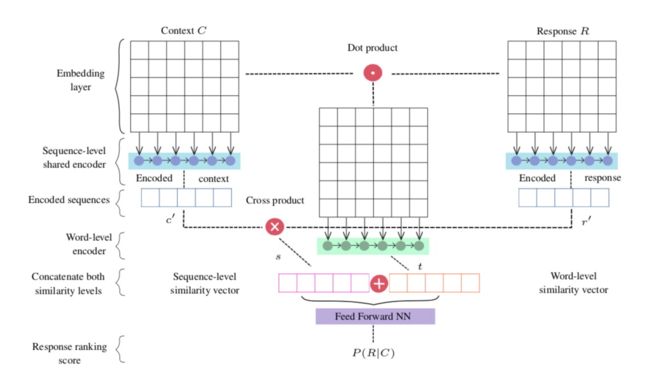
简介:本文对比的基线是Dual Encoder和SMN模型,从word-level和sentence-level两个角度进行建模。该工作的出发点更多的是simplicity 和 efficiency,因此在结构上并未突出特别的创新点。
Sequence Encoding
首先,将context concatenate到一个向量。然后,对context与response进行embedding稠密化,然后通过时序模型LSTM进行编码,这里取时序模型的last hidden作为最终输出,即和。Sequence Level Similarity
其中,代表向量叉积。代表和之间的相似度。Word Level Similarity
其中,代表dot product。至此,得到了一个相似矩阵,作者通过另一个时序模型将相似矩阵转换为向量(代表隐藏层的维度,代表last hidden)。Response Score
其中,代表concatenation。
Deep Hybrid Networks Based Response Selection Fro Multi-Turn Dialogue Systems

简介:作者提出了deep hybrid network (DHN)抽取上下文信息。首先,通过每个utterance与response计算相似矩阵;然后,将多个相似矩阵进行concatenation得到一个大mathing matrix。最后,通过若干层的深度卷积block抽取高维matching feature。本文的创新点更多的是将CliqueNet模型应用到multi-turn dialogue中,其他无太大创新点。
Multi-turn Context Representation
首先,计算每个utterance与response的匹配矩阵
其中,和。
另外,通过时序模型RNN编码句子中词的上下文关系,然后再次计算utterance与response之间的匹配矩阵
其中,。最终,多轮context的特征表示为
其中,。-
Context-aware Matching

本文Matching Module完全参考CliqueNet网络的设计结构,Matching Module包含若干卷积block,每个block分为2阶段。第一阶段,跟DenseNet就是相同的前馈结构,每一层都将合并来自前面所有层的输出。第二个阶段,每个卷积层需要合并的内容包含:比自己深的卷积层第一阶段的特征图,比自己浅的卷积层第二阶段的特征图。
其中,是一个非线性变换函数,包含了,表示卷积,表示concatenation。
作者这里叠加了三层block,每一层block包含了原始输入和第二阶段获得的特征。每个block第二部分的输出经过transition layer(,其中是一个average pooling层)处理之后作为下一个block的输入。将所有block输出特征池化之后,构成了最终的匹配向量。 -
Aggregation
获得匹配向量之后,通过一层全连接层,然后softmax获得匹配概率。最后利用交叉墒作为模型的损失函数
Knowledge-incorporating ESIM models for Response Selection in Retrieval-based Dialog Systems

简介:论文参考ESIM模型结构,将多轮utterance拼接到一段文本中,然后做单轮匹配。本文另一个重要的点在于融合进外部信息来丰富匹配的特征,比如:Ubuntu手册页的命令描述。通过结合更多的外部信息来获得更有的结果。
Word Representation Layer
word representation由两部分组成:word embedding和character-composed embedding。其中,word embedding包含了Glove word embedding和word2vec向量(在训练数据上预训练得到);另外,character-composed embedding通过拼接BiLSTM前向和后向的final state。Context representation layer
输入包含三部分:context、response和外部知识(ubuntu手册页的命令描述)。采用BiLSTM模型对文本进行编码,三部分输入共享模型参数
-
Attention matching layer
- Attention Matching Layer同样分为三部分:
- response与外部信息
- context与外部信息
- context与response
对context与response编码向量计算attention,然后加权求和得到对齐表示
其中,计算context与response之间的相似度。
有了对齐向量之后,一个通用的做法就是通过concatenation、difference和element-wise product对特征进行增广
最后,我们得到 - Attention Matching Layer同样分为三部分:
Matching aggregation layer
Aggregation Layer采用另一个BiLSTM模型对向量进行编码
Pooling layer
池化层采用max-pooling和final state组合得到最终的向量,最后将输入全连接层得到最终的相似度
End-to-end Gated Self-attentive Memory Network for Dialog Response Selection
简介:作者提出了Gated Self-attentive Memory Network用于在模型训练中融合历史会话和外部领域知识,通过self-attention加强utterance与对话历史(或外部领域知识)的联系。论文的出发点在于通过end-to-end的方式,更好的融合外部的知识提升模型的效果;同时借鉴transformer的网络结构,利用self-attention加强utterance的表征能力。
-
Bi-RNN based Utterance Encoding

特征编码层为BiRNN,并且对时序模型正向和反向的last hidden进行concatenate。
-
Memory Attention
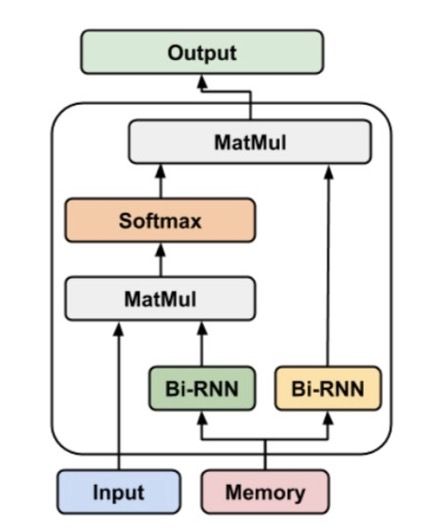
输入向量为,memory向量为,其中。输出向量为
其中,和是不同的。
-
Gated Memory Attention

参考前人的工作,作者采用gating mechanism对输入和memory输出进行融合
其中,是激活函数为sigmoid的全连接神经网络层。
-
End-to-end GSMN
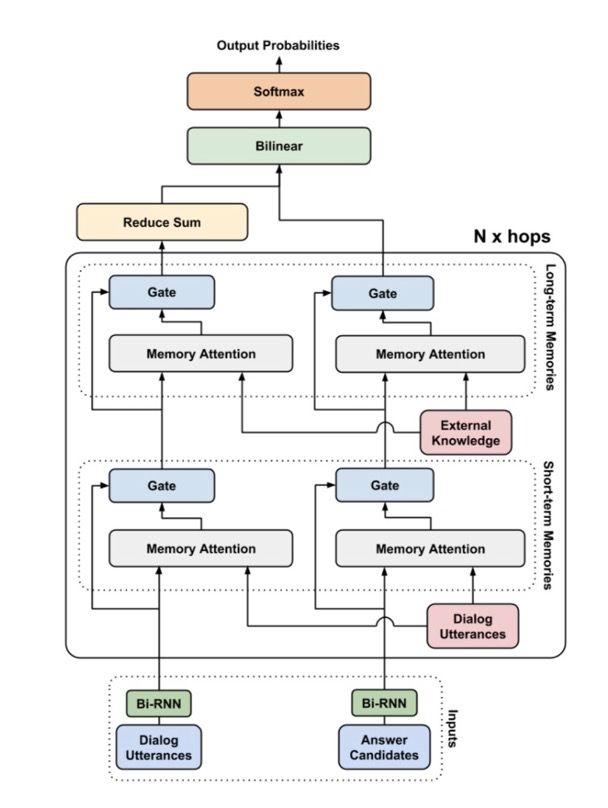
论文设计了多个hop,并且每个hop参数独立。对多个utterance进行求和得到最后的向量
External Knowledge Encoding
作者通过向量表示外部领域知识的key-value pair。例如: 代表key中的第个token,代表value中的第个token。最终的向量表示为word embedding求平均Dialog History and Response Relevance
获得context的特征和response的特征之后,通过双线性变化计算匹配度
其中,是训练参数。在获得context与response的相似匹配向量之后,通过softmax转换为概率分布。
Interactive Matching Network for Multi-Turn Response Selection in Retrieval-Based Chatbots

简介:作者提出了一种新的神经网络框架:IMN(interactive matching network),用于多轮对话的答案选择。模型同时使用了字符向量和词向量用于解决问答系统常见的OOV(out-of-vocabulary)问题,参考ELMO模型作者设计了multi-layer RNNs,然后将context中所有query拼接为单句,并计算与response之间的交叉信息,以此丰富模型的特征,最后通过一个时序模型聚合文本特征。实验结果证明,该模型获得了state-of-the-art的效果。
Word Representation Layer
参考前人经验,作者同时采用word-level embedding和character-level embedding(采用cnn模型对字符特征进行编码得到词粒度的特征)Sentence Encoding Layer
参考ELMO模型的设计,本文采用BILSTM作为block抽取句子特征,在L个block之后,对每个block的输出进行加权求和作为词的编码特征。
其中,为attention权值,在模型训练过程中学习得到。-
Matching Layer
之前大量的论文已经证明,response与context之间的交叉特征是一个非常重要的特征。基于多轮对话的answer selection最重要的一个点就是如何选择相关信息,并且过滤不相关的噪声。
首先,将历史所有会话按照词粒度特征进行拼接
然后,计算response与context的相似矩阵
获得相似矩阵之后,我们就可以分别计算response和context的对齐特征。
最后,通过concat、differences 和 the element-wise products对特征进行增广。
至此,交叉特征计算完成。下一步就是将context特征转换回单句格式。
Aggregation Layer
聚合层常见的设计是在RNN之后接一个pooling层,文章这里稍作修改,采用max-pooling和last hidden的拼接特征作为输出。需要注意,这里context和response共享BILSTM模型。
在获得各个句子的输出特征之后,通过一个时序模型抽取最终的聚合特征。
最后,将context聚合特征和response特征拼接作为prediction layer的输入特征。
Prediction Layer
这里采用multi-layer perceptron (MLP)作为最后一层,返回匹配得分。Training Criteria
最后通过计算交叉墒对模型进行迭代计算
总结
- 目前多轮问答已经被广泛的研究并应用于生产。大体可以总结为如下几类
- 多轮utterance拼接到一个utterance,将多轮问题转换为单轮匹配问题
- 分层建模:先得到句子的表示,然后在通过时序模型对多轮进行建模
- 将问题分为三部分:历史会话、当前会话和response
- 加入外部信息丰富模型的特征
- 模型结构可以总结为
- Transformer替换Bi-LSTM或者Bi-GRU
- 参考Residual-net和Dense-net,将模型的层数由单层扩展到多层
Future work
- reinforcement learning
- multi-task
- deep network
- adversarial learning