日志操作爽歪歪
基本上每天早上到公司之后都会习惯性的看下线上的错误日志,如果错误日志有问题会根据日志是否影响业务的使用,进而决定是继续查看相关日志进行问题的定位或者解决。
其实每天重复机械的看也没啥,毕竟Chrome + Vimium+gVim+Intellij IDEA +花式快捷键全程手都不带离键盘的,好像也没有其他更好的方式,所以就这样坚持到了现在。及时前一个月的时候,小组中的小安姐姐用python写了一个查询线上error日志,然后自动发邮件通知给威哥的小工具之后,本帅依然是每天直接打开日志系统,照旧一个一个查看系统是否运行ok。只是前几天没事就用python实现了发邮件的功能,然后,功能就荒废在哪里了!(又没啥用。)代码查看
正好现在有点烦机械式的查看日志,感觉要是用程序把那些重复的日志进行去重,而且做一下简单汇总备案。感觉不是爽歪歪。遂开始日志爬取计划程序。
写代码
嗯,下面就是花了大概全程十分钟不到模拟了日志系统的请求方式:
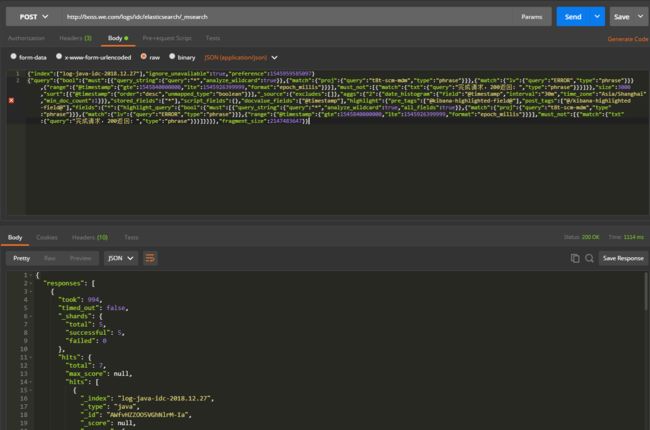
然后生成如下代码:
def listErrorLogs():
import requests
url = "http://boss.we.com/logs/idc/elasticsearch/_msearch"
payload = "{\"index\":[\"log-java-idc-2018.12.27\"],\"ignore_unavailable\":true," \
"\"preference\":1545975388333}\r\n{\"query\":{\"bool\":{\"must\":[{\"query_string\":{" \
"\"analyze_wildcard\":true,\"query\":\"*\"}},{\"match\":{\"proj\":{\"query\":\"t8t-scm-mdm\"," \
"\"type\":\"phrase\"}}},{\"match\":{\"lv\":{\"query\":\"ERROR\",\"type\":\"phrase\"}}},{\"range\":{" \
"\"@timestamp\":{\"gte\":1545840000000,\"lte\":1545926399999,\"format\":\"epoch_millis\"}}}]," \
"\"must_not\":[{\"match\":{\"txt\":{\"query\":\"完成请求,200返回:\",\"type\":\"phrase\"}}}]}},\"size\":3000," \
"\"sort\":[{\"@timestamp\":{\"order\":\"desc\",\"unmapped_type\":\"boolean\"}}],\"_source\":{" \
"\"excludes\":[]},\"aggs\":{\"2\":{\"date_histogram\":{\"field\":\"@timestamp\",\"interval\":\"30m\"," \
"\"time_zone\":\"Asia/Shanghai\",\"min_doc_count\":1}}},\"stored_fields\":[\"*\"],\"script_fields\":{}," \
"\"docvalue_fields\":[\"@timestamp\"],\"highlight\":{\"pre_tags\":[\"@kibana-highlighted-field@\"]," \
"\"post_tags\":[\"@/kibana-highlighted-field@\"],\"fields\":{\"*\":{\"highlight_query\":{\"bool\":{" \
"\"must\":[{\"query_string\":{\"analyze_wildcard\":true,\"query\":\"*\",\"all_fields\":true}}," \
"{\"match\":{\"proj\":{\"query\":\"t8t-scm-mdm\",\"type\":\"phrase\"}}},{\"match\":{\"lv\":{" \
"\"query\":\"ERROR\",\"type\":\"phrase\"}}},{\"range\":{\"@timestamp\":{\"gte\":1545840000000," \
"\"lte\":1545926399999,\"format\":\"epoch_millis\"}}}],\"must_not\":[{\"match\":{\"txt\":{" \
"\"query\":\"完成请求,200返回:\",\"type\":\"phrase\"}}}]}}}},\"fragment_size\":2147483647}}\r\n"\
headers = {
'authorization': "Basic ZGV2OnRlc3Q=",
'kbn-version': "5.3.0-SNAPSHOT",
'cache-control': "no-cache",
"content-encoding": "gzip",
}
response = requests.request("POST", url, data=payload, headers=headers)
print(response.text)
if __name__ == "__main__":
listErrorLogs()
运行一下
坐等运行正确运行结果的本帅,居然有bug!!!
一看到这个结果,顿时心情就不好了,不科学啊!
File "D:/git/pythonProject/to8to/logs/IdcLogs.py", line 15, in listErrorLogs
response = requests.request("POST", url, data=payload, headers=headers)
File "C:\Users\SHUAI.PAN\AppData\Local\Programs\Python\Python37-32\lib\site-packages\requests\api.py", line 60, in request
return session.request(method=method, url=url, **kwargs)
File "C:\Users\SHUAI.PAN\AppData\Local\Programs\Python\Python37-32\lib\site-packages\requests\sessions.py", line 533, in request
resp = self.send(prep, **send_kwargs)
File "C:\Users\SHUAI.PAN\AppData\Local\Programs\Python\Python37-32\lib\site-packages\requests\sessions.py", line 646, in send
r = adapter.send(request, **kwargs)
File "C:\Users\SHUAI.PAN\AppData\Local\Programs\Python\Python37-32\lib\site-packages\requests\adapters.py", line 449, in send
timeout=timeout
File "C:\Users\SHUAI.PAN\AppData\Local\Programs\Python\Python37-32\lib\site-packages\urllib3\connectionpool.py", line 600, in urlopen
chunked=chunked)
File "C:\Users\SHUAI.PAN\AppData\Local\Programs\Python\Python37-32\lib\site-packages\urllib3\connectionpool.py", line 354, in _make_request
conn.request(method, url, **httplib_request_kw)
File "C:\Users\SHUAI.PAN\AppData\Local\Programs\Python\Python37-32\lib\http\client.py", line 1229, in request
self._send_request(method, url, body, headers, encode_chunked)
File "C:\Users\SHUAI.PAN\AppData\Local\Programs\Python\Python37-32\lib\http\client.py", line 1274, in _send_request
body = _encode(body, 'body')
File "C:\Users\SHUAI.PAN\AppData\Local\Programs\Python\Python37-32\lib\http\client.py", line 160, in _encode
(name.title(), data[err.start:err.end], name)) from None
UnicodeEncodeError: 'latin-1' codec can't encode characters in position 413-417: Body ('完成请求,') is not valid Latin-1. Use body.encode('utf-8') if you want to send it encoded in UTF-8.
def _encode(data, name='data'):
"""Call data.encode("latin-1") but show a better error message."""
try:
return data.encode("latin-1") ## 调用 latin-1 格式编码,真实人生处处有彩蛋----有木有搞错,赤裸裸的歧视啊!!!
##没事反正歧视的不止中文,想到这里瞬间觉得稍微好一点了。
except UnicodeEncodeError as err:
raise UnicodeEncodeError(
err.encoding,
err.object,
err.start,
err.end,
"%s (%.20r) is not valid Latin-1. Use %s.encode('utf-8') "
"if you want to send it encoded in UTF-8." %
(name.title(), data[err.start:err.end], name)) from None
本来想搜为啥开发requests包童鞋要这么挑战大家,不小心看到了python requests 发送中文参数的问题,用里面只针对中文编码是没有任何问题的,只是假如中文到处分散的话,到处都要编码,不如一劳永逸如下:
def listErrorLogs():
import requests
url = "http://boss.we.com/logs/idc/elasticsearch/_msearch"
# index = '{"index": ["log-java-idc-2018.12.27"], "ignore_unavailable": true, "preference": 1545975388333}'
# query = '{"query":{"bool":{"must":[{"query_string":{"analyze_wildcard":true,"query":"*"}},{"match":{"proj":{"query":"t8t-scm-mdm","type":"phrase"}}},{"match":{"lv":{"query":"ERROR","type":"phrase"}}},{"range":{"@timestamp":{"gte":1545840000000,"lte":1545926399999,"format":"epoch_millis"}}}],"must_not":[]}},"size":3000,"sort":[{"@timestamp":{"order":"desc","unmapped_type":"boolean"}}],"_source":{"excludes":[]},"aggs":{"2":{"date_histogram":{"field":"@timestamp","interval":"30m","time_zone":"Asia/Shanghai","min_doc_count":1}}},"stored_fields":["*"],"script_fields":{},"docvalue_fields":["@timestamp"],"highlight":{"pre_tags":["@kibana-highlighted-field@"],"post_tags":["@/kibana-highlighted-field@"],"fields":{"*":{"highlight_query":{"bool":{"must":[{"query_string":{"analyze_wildcard":true,"query":"*","all_fields":true}},{"match":{"proj":{"query":"t8t-scm-mdm","type":"phrase"}}},{"match":{"lv":{"query":"ERROR","type":"phrase"}}},{"range":{"@timestamp":{"gte":1545840000000,"lte":1545926399999,"format":"epoch_millis"}}}],"must_not":[]}}}},"fragment_size":2147483647}}'
payload = "{\"index\":[\"log-java-idc-2018.12.27\"],\"ignore_unavailable\":true," \
"\"preference\":1545975388333}\r\n{\"query\":{\"bool\":{\"must\":[{\"query_string\":{" \
"\"analyze_wildcard\":true,\"query\":\"*\"}},{\"match\":{\"proj\":{\"query\":\"t8t-scm-mdm\"," \
"\"type\":\"phrase\"}}},{\"match\":{\"lv\":{\"query\":\"ERROR\",\"type\":\"phrase\"}}},{\"range\":{" \
"\"@timestamp\":{\"gte\":1545840000000,\"lte\":1545926399999,\"format\":\"epoch_millis\"}}}]," \
"\"must_not\":[{\"match\":{\"txt\":{\"query\":\"完成请求,200返回:\",\"type\":\"phrase\"}}}]}},\"size\":3000," \
"\"sort\":[{\"@timestamp\":{\"order\":\"desc\",\"unmapped_type\":\"boolean\"}}],\"_source\":{" \
"\"excludes\":[]},\"aggs\":{\"2\":{\"date_histogram\":{\"field\":\"@timestamp\",\"interval\":\"30m\"," \
"\"time_zone\":\"Asia/Shanghai\",\"min_doc_count\":1}}},\"stored_fields\":[\"*\"],\"script_fields\":{}," \
"\"docvalue_fields\":[\"@timestamp\"],\"highlight\":{\"pre_tags\":[\"@kibana-highlighted-field@\"]," \
"\"post_tags\":[\"@/kibana-highlighted-field@\"],\"fields\":{\"*\":{\"highlight_query\":{\"bool\":{" \
"\"must\":[{\"query_string\":{\"analyze_wildcard\":true,\"query\":\"*\",\"all_fields\":true}}," \
"{\"match\":{\"proj\":{\"query\":\"t8t-scm-mdm\",\"type\":\"phrase\"}}},{\"match\":{\"lv\":{" \
"\"query\":\"ERROR\",\"type\":\"phrase\"}}},{\"range\":{\"@timestamp\":{\"gte\":1545840000000," \
"\"lte\":1545926399999,\"format\":\"epoch_millis\"}}}],\"must_not\":[{\"match\":{\"txt\":{" \
"\"query\":\"完成请求,200返回:\",\"type\":\"phrase\"}}}]}}}},\"fragment_size\":2147483647}}\r\n"\
.encode("UTF-8") ## 对字符串进行`UTF-8`编码格式编码
headers = {
'authorization': "Basic ZGV2OnRlc3Q=",
'kbn-version': "5.3.0-SNAPSHOT",
'cache-control': "no-cache",
"content-encoding": "gzip",
}
response = requests.request("POST", url, data=payload, headers=headers)
print(response.text)
if __name__ == "__main__":
listErrorLogs()
运行结果
看样子是爽歪歪的
# 编码之后请求的内容会进行编码变成如下格式
"完成请求,200返回:"=编码=》"\xe5\xae\x8c\xe6\x88\x90\xe8\xaf\xb7\xe6\xb1\x82\xef\xbc\x8c200\xe8\xbf\x94\xe5\x9b\x9e\xef\xbc\x9a"
## 编码之前
{"index":["log-java-idc-2018.12.27"],"ignore_unavailable":true,"preference":1545959585097}
{"query":{"bool":{"must":[{"query_string":{"query":"*","analyze_wildcard":true}},{"match":{"proj":{"query":"t8t-scm-mdm","type":"phrase"}}},{"match":{"lv":{"query":"ERROR","type":"phrase"}}},{"range":{"@timestamp":{"gte":1545840000000,"lte":1545926399999,"format":"epoch_millis"}}}],"must_not":[{"match":{"txt":{"query":"完成请求,200返回:","type":"phrase"}}}]}},"size":3000,"sort":[{"@timestamp":{"order":"desc","unmapped_type":"boolean"}}],"_source":{"excludes":[]},"aggs":{"2":{"date_histogram":{"field":"@timestamp","interval":"30m","time_zone":"Asia/Shanghai","min_doc_count":1}}},"stored_fields":["*"],"script_fields":{},"docvalue_fields":["@timestamp"],"highlight":{"pre_tags":["@kibana-highlighted-field@"],"post_tags":["@/kibana-highlighted-field@"],"fields":{"*":{"highlight_query":{"bool":{"must":[{"query_string":{"query":"*","analyze_wildcard":true,"all_fields":true}},{"match":{"proj":{"query":"t8t-scm-mdm","type":"phrase"}}},{"match":{"lv":{"query":"ERROR","type":"phrase"}}},{"range":{"@timestamp":{"gte":1545840000000,"lte":1545926399999,"format":"epoch_millis"}}}],"must_not":[{"match":{"txt":{"query":"完成请求,200返回:","type":"phrase"}}}]}}}},"fragment_size":2147483647}}
## 编码之后
'{"index":["log-java-idc-2018.12.27"],"ignore_unavailable":true,"preference":1545975388333}\r\n{"query":{"bool":{"must":[{"query_string":{"analyze_wildcard":true,"query":"*"}},{"match":{"proj":{"query":"t8t-scm-mdm","type":"phrase"}}},{"match":{"lv":{"query":"ERROR","type":"phrase"}}},{"range":{"@timestamp":{"gte":1545840000000,"lte":1545926399999,"format":"epoch_millis"}}}],"must_not":[{"match":{"txt":{"query":"\xe5\xae\x8c\xe6\x88\x90\xe8\xaf\xb7\xe6\xb1\x82\xef\xbc\x8c200\xe8\xbf\x94\xe5\x9b\x9e\xef\xbc\x9a","type":"phrase"}}}]}},"size":3000,"sort":[{"@timestamp":{"order":"desc","unmapped_type":"boolean"}}],"_source":{"excludes":[]},"aggs":{"2":{"date_histogram":{"field":"@timestamp","interval":"30m","time_zone":"Asia/Shanghai","min_doc_count":1}}},"stored_fields":["*"],"script_fields":{},"docvalue_fields":["@timestamp"],"highlight":{"pre_tags":["@kibana-highlighted-field@"],"post_tags":["@/kibana-highlighted-field@"],"fields":{"*":{"highlight_query":{"bool":{"must":[{"query_string":{"analyze_wildcard":true,"query":"*","all_fields":true}},{"match":{"proj":{"query":"t8t-scm-mdm","type":"phrase"}}},{"match":{"lv":{"query":"ERROR","type":"phrase"}}},{"range":{"@timestamp":{"gte":1545840000000,"lte":1545926399999,"format":"epoch_millis"}}}],"must_not":[{"match":{"txt":{"query":"\xe5\xae\x8c\xe6\x88\x90\xe8\xaf\xb7\xe6\xb1\x82\xef\xbc\x8c200\xe8\xbf\x94\xe5\x9b\x9e\xef\xbc\x9a","type":"phrase"}}}]}}}},"fragment_size":2147483647}}\r\n'

总结
程序是自动生成的,算上新建.py文件,调整一下,运行以及到最后成功。整个花的时间不过20分钟,但却是一箭穿过了这一整天时间。
想想本帅的计划里面还有要把数据进行去重,分类。然后持久化数据,并生成可视化,人性化的分析结果。。。这又要穿过多少天呢?
鲁迅小哥哥说得到底是有点意思的“时间是海绵里的水,挤挤还是有的!”,只是现实生活总是如此匆忙,像这样简单的事情时间一挤就是一整天。可想而知鲁迅小哥哥在写出这名言的时候,也深感挤的无奈吧!!!
--- 致鲁迅小哥哥的名言&公司的日志系统