写作不易,转载请注明出处,且用且珍惜。
- xlwt 1.3.0
- xlwt 文档
- xlrd 1.1.0
- 文档pdf下载
- python操作excel之xlrd
1.Python模块介绍 - xlwt ,什么是xlwt?
- Python语言中,写入Excel文件的扩展工具。
- 相应的有扩展包xlrd,专门用于excel读取。
- 可以实现指定表单、指定单元格的写入。
2.xlwt使用
- 导入模块
import xlwt
- 创建workbook,即创建excel,后来要进行保存
workbook = xlwt.Workbook(encoding = 'utf-8')
- 创建表
worksheet = workbook.add_sheet('My Worksheet',cell_overwrite_ok=True) ##第二参数用于确认同一个cell单元是否可以重设值。
- 往单元格内写入内容
worksheet.write(0, 0, label = 'Row 0, Column 0 Value')
- 保存
workbook.save('Excel_Workbook.xls')
- 增加单元格内容
write_merge(x, x + m, y, y + n, string, sytle)
# x表示行,y表示列,m表示跨行个数,n表示跨列个数,string表示要写入的单元格内容,style表示单元格样式。其#中,x,y,w,h,都是以0开始计算的。
#这个和xlrd中的读合并单元格的不太一样。
add_sheet #如果需要创建多个sheet,则只要f.add_sheet即可
注意:
python2.X 版本下,使用xlwt扩展包。
python3.X 版本下,需要更新到xlwt3扩展包。
3.xlwt模块使用实例
#代码来自code.py40.com
import xlwt
def write_excel():
f = xlwt.Workbook() #创建工作簿
sheet1 = f.add_sheet(u'sheet1',cell_overwrite_ok=True) #创建sheet
row0= [u'编号',u'姓名',u'性别',u'生日']
#生成第0行
for i in range(0,len(row0)):
sheet1.write(0,i,row0[i])
row1 = [u'1',u'张三',u'男']
row2 = [u'2',u'李四',u'女']
date = '1990-01-04'
#生成第一行
for i in range(0,len(row1)):
sheet1.write(1,i,row1[i])
#生成第二行
for i in range(0,len(row2)):
sheet1.write(2,i,row2[i])
#写入合并的单元格数据1990-01-04
sheet1.write_merge(1,2,3,3,date)
f.save(r'E:\python\learn\demo1.xls') #保存文件
#python写入Excel文档
if __name__ == '__main__':
#generate_workbook()
#read_excel()
write_excel()
4.enumerate()说明
- enumerate()是python的内置函数
- enumerate在字典上是枚举、列举的意思
- 对于一个可迭代的(iterable)/可遍历的对象(如列表、字符串),enumerate将其组成一个索引序列,利用它可以同时获得索引和值
- enumerate多用于在for循环中得到计数
5.爬取拉勾网招聘信息并通过xlwt存入Excel
1.分析拉勾网网页结构及数据
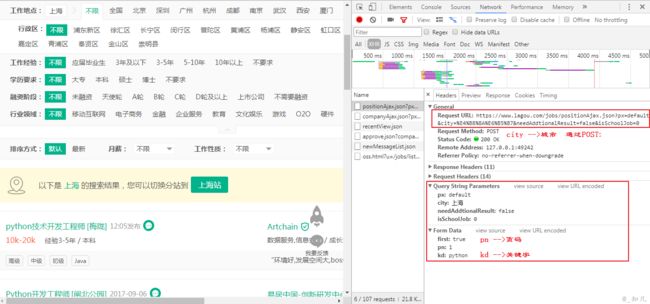
通过浏览器自带的开发者工具查看是通过Post方式提交的,数据是通过Ajax(异步加载)得到的

查看每个岗位对应的链接
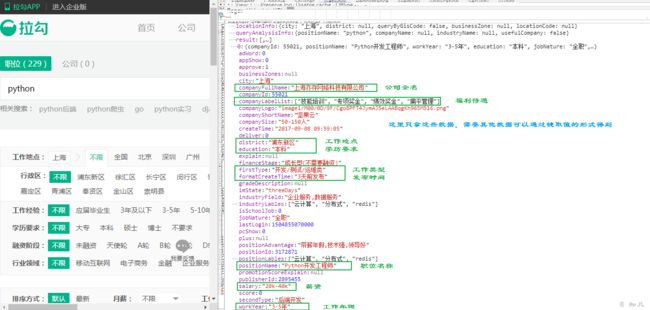
成功找到我们想要抓取的数据
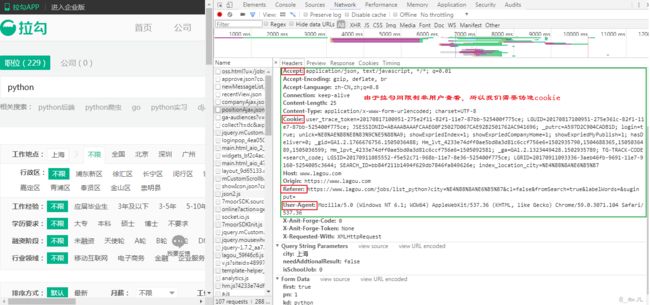
伪造cookie,请求头
代码如下:
#-*- coding:utf-8 -*-
created 2017.9.12
import json
import requests
import xlwt
import time
from lxml import etree
#解决编码的问题
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
#获取存储职位信息的json对象,遍历获得公司名、福利待遇、工作地点、学历要求、工作类型、发布时间、职位名称、薪资、工作年限
def get_json(url,datas):
my_headers = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.75 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Host': 'www.lagou.com',
'Origin': 'https://www.lagou.com',
'Referer': 'https://www.lagou.com/jobs/list_python?city=%E4%B8%8A%E6%B5%B7&cl=false&fromSearch=true&labelWords=&suginput=',
}
cookies = {
'Cookie': 'user_trace_token=20170824135842-485287de-8891-11e7-a544-525400f775ce; LGUID=20170824135842-48528e05-8891-11e7-a544-525400f775ce; JSESSIONID=ABAAABAAADEAAFI772FD1B9AABBF0C5553E874B0F860350; _putrc=B95D7C5E94F53DA8; login=true; unick=%E9%83%AD%E5%B2%A9; showExpriedIndex=1; showExpriedCompanyHome=1; showExpriedMyPublish=1; hasDeliver=3; PRE_UTM=; PRE_HOST=; PRE_SITE=; PRE_LAND=https%3A%2F%2Fwww.lagou.com%2F; _gat=1; TG-TRACK-CODE=index_search; SEARCH_ID=f0acbb8b2145433cb8fe7086f23be622; index_location_city=%E5%8C%97%E4%BA%AC; _gid=GA1.2.397092414.1504747009; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1504756944,1504761486,1504783443,1504839029; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1504839719; _ga=GA1.2.1499897355.1503554319; LGSID=20170908105032-7b45520c-9440-11e7-8aae-525400f775ce; LGRID=20170908110159-14c6e1a8-9442-11e7-8ab1-525400f775ce'
}
time.sleep(8)
content = requests.post(url=url,cookies=cookies,headers=my_headers,data=datas)
# content.encoding = 'utf-8'
result = content.json()
print result
info = result['content']['positionResult']['result']
# print info
info_list = []
for job in info:
information = []
information.append(job['positionId']) #岗位对应ID
information.append(job['companyFullName']) #公司全名
information.append(job['companyLabelList']) #福利待遇
information.append(job['district']) #工作地点
information.append(job['education']) #学历要求
information.append(job['firstType']) #工作类型
information.append(job['formatCreateTime']) #发布时间
information.append(job['positionName']) #职位名称
information.append(job['salary']) #薪资
information.append(job['workYear']) #工作年限
info_list.append(information)
#将列表对象进行json格式的编码转换,其中indent参数设置缩进值为2
print json.dumps(info_list,ensure_ascii=False,indent=2)
print info_list
return info_list
def main():
page = int(raw_input('请输入你要抓取的页码总数:'))
# kd = raw_input('请输入你要抓取的职位关键字:')
# city = raw_input('请输入你要抓取的城市:')
info_result = []
title = ['岗位id','公司全名','福利待遇','工作地点','学历要求','工作类型','发布时间','职位名称','薪资','工作年限']
info_result.append(title)
for x in range(1,page+1):
url = 'https://www.lagou.com/jobs/positionAjax.json?&needAddtionalResult=false'
datas = {
'first': True,
'pn': x,
'kd': 'python',
'city': '上海'
}
info = get_json(url,datas)
info_result = info_result+info
#创建workbook,即excel
workbook = xlwt.Workbook(encoding='utf-8')
#创建表,第二参数用于确认同一个cell单元是否可以重设值
worksheet = workbook.add_sheet('lagouzp',cell_overwrite_ok=True)
for i, row in enumerate(info_result):
# print row
for j,col in enumerate(row):
# print col
worksheet.write(i,j,col)
workbook.save('lagouzp.xls')
if __name__ == '__main__':
main()
运行程序

Excel数据展示
如果你觉得我的文章还可以,可以关注我的微信公众号:Python攻城狮

可扫描二维码,添加关注