无意中看到一篇 COCA 语料库的介绍文章,然后自己就去 http://testyourvocab.com/ 测了下词汇,大约是 2 万多。

神奇的是,我在以前的英语学习时从没接触过这个目前可以说是最知名的英语词汇词频统计库,虽然目测词汇量尚可,但是这个也不是绝对准确的,因为我测的时候感觉差不多认识的单词我就勾了 ,所以结果肯定有不少水分,而且统计方法还因人而异吧,我感觉我目前的词汇应该在 2 万左右。根据网上的论断,这个量貌似也挺大的。虽然我从小对英语学习就非常感兴趣,但是我印象最深的集中大量词汇输入还是在准备出国的时候,当然,这之前我也都是爱背单词的,只不过都是些笨方法,主要是我比较爱看英语相关的东西,而遇到生词了也会刻意去记忆,以前更是爱拿着生词本各种记。
所以,没接触过这个语料库我还是觉得挺惊讶的,它最有意思的一点就在于它的词频统计,如果我们能很好的利用这个词频表所统计出来的词汇,那对于英语的学习是非常高效的(我现在就在通过这个词频表进行复习和查漏)。
所以,下面先简单介绍一下这个库
COCA, 全称 Corpus of Contemporary American English,网站是 https://corpus.byu.edu/ 它总结了英语国家使用频率最高的词汇,使用大数据的方法把 1990-2012 年美国最有代表性的报纸,杂志,小说,学术,口语(口语可能是用的电视剧或者脱口秀之类的节目转录的)汇集起来,每部分各占 1/5,生成 4.5 亿单词量语料库。billions of words of data: free online accessCOCA, 全称 Corpus of Contemporary American English,网站是 https://corpus.byu.edu/ 它总结了英语国家使用频率最高的词汇,使用大数据的方法把 1990-2012 年美国最有代表性的报纸,杂志,小说,学术,口语(口语可能是用的电视剧或者脱口秀之类的节目转录的)汇集起来,每部分各占 1/5,生成 4.5 亿单词量语料库。
COCA词频表,是从众多语料库(corpus)中提取,用大数据的方法从各种文体中提取单词,并按照单词出现次数高低进行排序的一个词频表。
来看一下这个数据:
掌握前 500 单词,现实生活中能认识 72% 的单词;
掌握前 1000 单词,现实生活中能认识 79% 的单词;
掌握前 2000 单词,现实生活中能认识 87% 的单词;
掌握前 3000 单词,现实生活中能认识 90% 的单词;
掌握前 4000 单词,现实生活中能认识 93% 的单词;
掌握前 5000单词,现实生活中能认识 94% 的单词;
掌握前 10000单词,现实生活中能认识 97% 的单词;
掌握前 17634 单词,现实生活中能认识 99% 的单词。
为什么学了那么多仍然不能达到 99.99%?因为英语实际使用中存在大量专有名词,比如Trump 这个单词,在其竞选前后出现频率相差极大,COCA 中除了媒体来源外的语料中出现很少,而这两年看报纸则是想绕都绕不开。掌握这 17634 词后,学习一个新领域的英文,只要多剩下的 1% 的专有名词,基本就不存在生词障碍了。
其实,不用完全把表背完,掌握频率最高的一万多词汇就已经非常够用了,在网上,背单词的边际效益是递减的(当然使用词频表来背就可以使边际效益最大化),所以,对于那些迫切希望可以看懂更多英语文章的人来说,利用词频表来进行学习就可以最大化效率。
好了,这篇文章不是来详细介绍 COCA 到底怎么用的,而是怎么利用它的词频表的。
首先,需要下载词频表,COCA 官网提供了免费的前 5000 个单词,但是再往后,还提供了 20000 和 60000 词汇量的版本,均是收费的,不过可以在淘宝上购买,或者在网上找到免费的下载链接。
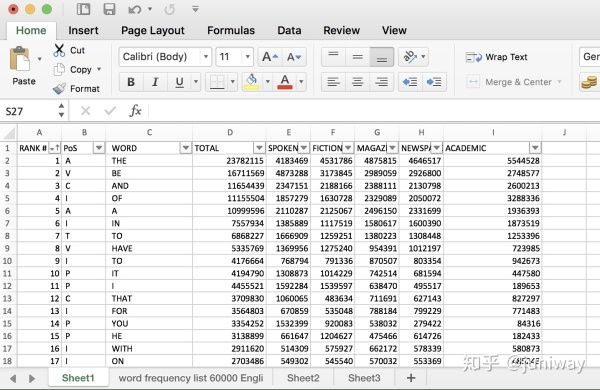
下面就基于最全的 60000 词汇量的文件,也就是 coca60000full.xlsx 这个 EXCEL 文件。它包含了所有的单词,以及词频统计,分类库等信,是信息最全的一个文件,其他所有衍生版本(比如 coca20000, coca口语等)均可由该文件生成。
文件内容预览图如下:
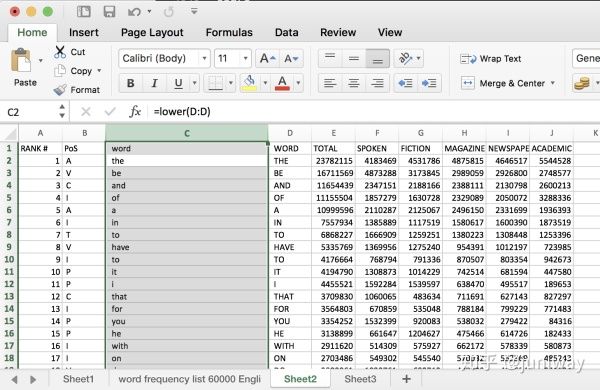
如果觉得 EXCEL 文件中显示的大写格式不适应,可以通过下面的方法变成小写:
1、先插入一个空栏(比如在原 WORD 列的左侧插入)
2、选中空栏,输入公式 =lower(D:D)
如下:

然后,按住 Ctrl + Enter 或者 Command + Enter,就会把函数应用到整列了,效果如下:
注意:这时候如果我们删除大写单词的那列,小写列会变成乱码,因为引用的是公式。
我们可以这样做,选中 C 列,然后直接在本列进行复制粘贴(Ctrl + C, Ctrl + V),在粘贴的时候,选择只拷贝值(Values Only)这一个选项。
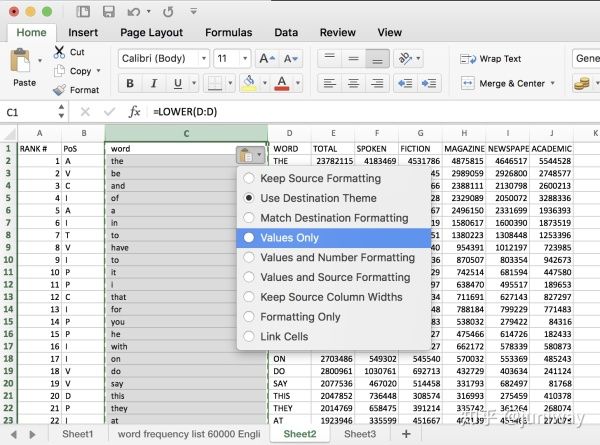
这样,我们就可以删除原列了。
好了,简单的 EXCEL 操作介绍完了,下面我们来看看,怎么继续得到我们想要的其他东西。
脚本处理
选中单词列,把它复制到 TXT 纯文本文件中,这样就得到一个包含了 6 万单词的纯文本 coca60000.txt。
我们可以继续细分这个单词本,比如分成只包含前 2 万,前 3 万或前几万的版本,由于原始单词集是包含重复单词的(COCA 根据单词的不同释义列举了多次),所以,我们还可以提取出去重的单词集。当然,根据我们个人的单词学习和记忆需求,我们还可以来进行更多处理。
因此,下面要介绍的就是用于做这些处理的脚本文件 split.py。
该脚本的大致功能解释如下:
1、去重(格式化)
对于 coca60000 这个词汇集合,原文本包含了重复词汇(coca 根据单词的不同含义,分别列举了多次,形式上出现重复)
那么,就可以用 split.py 这个脚本进行去重,总量为 60023 的集合去重之后剩余 54150 个。
另外,还可以对文本进行一些简单的格式化,比如去掉单词前后的空格。
2、分组
该脚本支持对想要记忆的单词进行不同大小的分组,比如每 100 个或者 200 个一组,具体命令如下:
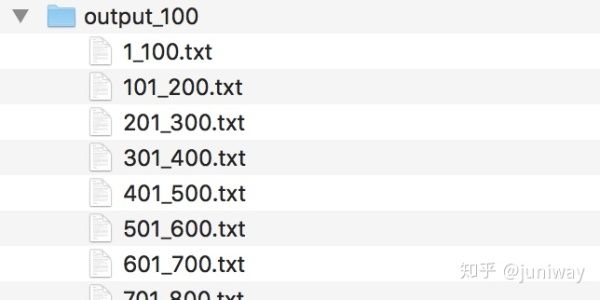
$ python split.py coca60000.txt 100
命令执行成功之后,会在 output 目录中生成许多文件,每个文件按指定分组大小来进行分组,并以数字范围的形式(xxx_yyy)命名,如下:
3、生成可导入的格式
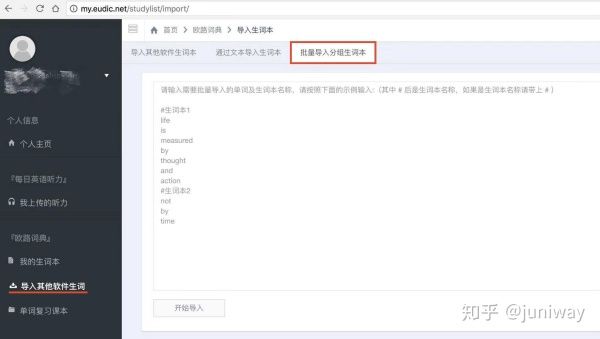
欧陆词典是一个很流行的英文词典,可以加载不同的词库文件,因此许多人都非常乐于使用它来进行词汇的学习。
这个脚本支持把原单词本格式化成欧陆词典(http://Eudic.net)所支持的导入规则,比如,欧陆词典中的 “批量导入分组生词本”,它的规则如下:
那么,只需要把 split.py 中的 batch_import() 函数打开,然后执行
$ python split.py coca60000.txt 15
就会生成一个叫 coca60000_batch_import.txt 的文件 ,然后打开该文件,就可以看到其内容如下:

复制文本内容到 http://eudic.net 中的文本框,就可以顺利导入所有分组。
好了,有了 COCA 词频表,脚本工具,以及背单词 APP,我们就可以愉快的背单词了 。