我的结果
爬取“深圳赶集二手——二手商品——个人——真实个人”,链接28195条,详情28159条
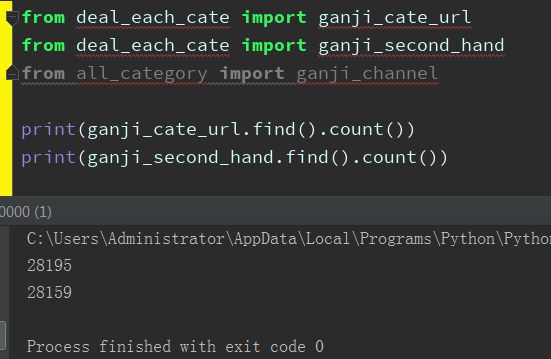
结果.png
我的代码

模块.png
说明:
all_category:从首页获取所有子项链接
deal_each_cate:包含两个重要函数:①提取商品链接;②提取商品详情
counts:计数器
main.py
from multiprocessing import Pool
from deal_each_cate import get_all_urls, get_goods_info
from all_category import ganji_channel
from deal_each_cate import ganji_cate_url
from deal_each_cate import ganji_second_hand
# step1
if __name__ == '__main__':
# 断点程序
# ganji_channel这个collection里面包含所有频道1至80页的链接
all_channel = [page['channel'] for page in ganji_channel.find()]
# ganji_cate_url里除了包含商品的链接,也包含了这个链接出现页面的链接
channel_done = [page['channel'] for page in ganji_cate_url.find()]
# 挑出还没有爬的频道页面
rest_of_channel = set(all_channel) - set(channel_done)
print(len(rest_of_channel))
pool = Pool(processes=4)
pool.map(get_all_urls, rest_of_channel)
# step2
if __name__ == '__main__':
# 断点程序
db_urls = [item['url'] for item in ganji_cate_url.find()]
info_urls = [item['url'] for item in ganji_second_hand.find()]
x = set(db_urls)
y = set(info_urls)
rest_of_urls = x - y
print(len(rest_of_urls))
# print(len(rest_of_urls)) 29693
# 4个进程
if rest_of_urls:
pool = Pool(processes=4)
pool.map(get_goods_info, rest_of_urls)
else:
print('It\'s done')
all_category.py
from bs4 import BeautifulSoup
import requests, time, pymongo
client = pymongo.MongoClient('localhost', 27017)
walden = client['walden']
ganji_channel = walden['ganji_channel']
# cate_list = []
# def get_all_cates():
# wu_page = 'http://sz.ganji.com/wu/'
# time.sleep(1)
# web_data = requests.get(wu_page)
# soup = BeautifulSoup(web_data.text, 'lxml')
# for category in soup.select('.fenlei dt a'):
# category = category.get('href')
# cate_list.append(category)
# # print(len(cate_list))
# # print(cate_list)
cate_list = ['/jiaju/', '/rirongbaihuo/', '/shouji/', '/bangong/', '/nongyongpin/', '/jiadian/',
'/ershoubijibendiannao/', '/ruanjiantushu/', '/yingyouyunfu/', '/diannao/', '/xianzhilipin/',
'/fushixiaobaxuemao/',
'/meironghuazhuang/', '/shuma/', '/laonianyongpin/', '/xuniwupin/', '/qitawupin/', '/ershoufree/',
'/wupinjiaohuan/']
# for item in cate_list:
# for i in range(1, 81):
# channel_page = 'http://sz.ganji.com{}o{}/'.format(item, i)
# ganji_channel.insert_one({'channel':channel_page})
# print(ganji_channel.find().count())
deal_each_cate.py
# -*- coding:'utf-8' -*-
from bs4 import BeautifulSoup
import requests, time, pymongo, random
client = pymongo.MongoClient('localhost', 27017)
walden = client['walden']
ganji_cate_url = walden['ganji_cate_url']
ganji_second_hand = walden['ganji_second_hand']
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36'}
# spider1
def get_all_urls(url):
try:
web_data = requests.get(url, headers=headers, timeout=7)
soup = BeautifulSoup(web_data.text, 'lxml')
# 直到某一页开始没有个人信息就停止
if soup.find(text='真实个人'):
# 获取链接
for info_url in soup.select('.zz-til a'):
info_url = info_url.get('href').split('&')[0]
# 处理链接,否则不能顺利爬取商品详情
useful_url = 'http://zhuanzhuan.58.com/detail/' + info_url.split('=')[-1] + 'z.shtml'
# 查重, 把ganji_cate_url打开,取出每一条记录的url组成set
if useful_url not in set(map(lambda x: x['url'], ganji_cate_url.find())):
ganji_cate_url.insert_one({'url': useful_url, 'channel': url})
print(useful_url)
else:
pass
else:
print('nothing')
# 没有个人信息了
pass
except Exception as e:
print(e)
# spider2
def get_goods_info(url):
try:
web_data = requests.get(url, headers=headers, timeout=6)
soup = BeautifulSoup(web_data.text, 'lxml')
print(url)
if soup.find(id='fail'):
print('fail')
elif soup.find(text='商品已下架'):
print('商品已下架')
else:
# 提取信息
title = soup.select('.info_titile')[0].get_text()
price = soup.select('.price_now i')[0].get_text()
region = soup.select('.palce_li i')[0].get_text() if soup.find(class_='palce_li') else None
desc = soup.select('.baby_kuang p')[0].get_text()
# 写入数据库
ganji_second_hand.insert_one(
{'title': title, 'price': price, 'region': region, 'describe': desc, 'url': url})
print({'title': title, 'price': price, 'region': region, 'describe': desc, 'url': url})
except Exception as e:
print(e)
counts.py
# -*- coding:'utf-8' -*-
import time
from deal_each_cate import ganji_cate_url
from deal_each_cate import ganji_second_hand
# step1
while True:
print(ganji_cate_url.find().count())
time.sleep(5)
# step2
while True:
print(ganji_second_hand.find().count())
time.sleep(5)
我的感想:
- 完成时间:从昨天到今天早上(实际上我真的不想回忆昨天,好深的坑啊)
- 昨天应该是网络有问题,老是报错,今早上一次性完成(详情页面大约每秒15个)
- 断点程度,实际上就是用减法排除那些不再需要爬取的部分,重点在于构建减数和被减数(在不同的数据库中保留相同格式的部分,比如 url,作为类似标记)
- 计数器挺有意思的,写一个小模块单独运行(开两个cmd)
- “真实个人”的商品链接点进去其实是“转转”,链接格式如:
url = 'http://m.zhuanzhuan.58.com/Mzhuanzhuan/zzWebInfo/zzganji/zzpc/detailPc.html?infoId=762113121520779268'
必须要转成为另外的格式,才能爬到商品详情(关键在 id):
url = 'http://zhuanzhuan.58.com/detail/762113121520779268z.shtml'