前言:
文章以Andrew Ng 的 deeplearning.ai 视频课程为主线,记录Programming Assignments 的实现过程。相对于斯坦福的CS231n课程,Andrew的视频课程更加简单易懂,适合深度学习的入门者系统学习!
这次的作业主要针对的是如何系统构建多层神经网络,如何实现模块化编程,从而实现程序的复用,提高使用效率,具有很高的参考价值。
1.1 Outline of the Assignment
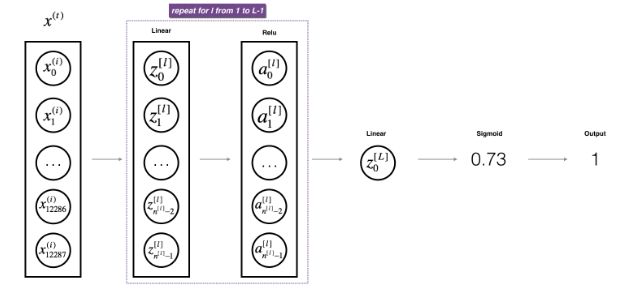
首先看一下整个神经网络的结构,涉及到前向传播和反向传播,对神经网络的训练过程有一个直观的认识:

1.2 Initialize L-layer Neural Network

下面是初始化多层神经网络参数的代码实现:
def initialize_parameters_deep(layer_dims):
np.random.seed(3)
parameters = {}
L = len(layer_dims)
for l in range(1, L):
parameters['W' + str(l)] = np.random.randn(layer_dims[l],layer_dims[l-1])*0.01
parameters['b' + str(l)] = np.zeros((layer_dims[l],1))
assert(parameters['W' + str(l)].shape == (layer_dims[l], layer_dims[l-1]))
assert(parameters['b' + str(l)].shape == (layer_dims[l], 1))
return parameters
1.3 Forward propagation module
前向过程包括:
1.3.1 LINEAR
1.3.2 LINEAR -> ACTIVATION where ACTIVATION will be either ReLU or Sigmoid.
1.3.3[LINEAR -> RELU]××(L-1) -> LINEAR -> SIGMOID (whole model)
三个部分的代码如下所示:
1.3.1
def linear_forward(A, W, b):
Z = np.dot(W,A)+b
assert(Z.shape == (W.shape[0], A.shape[1]))
cache = (A, W, b)
return Z, cache
1.3.2
def linear_activation_forward(A_prev, W, b, activation):
if activation == "sigmoid":
Z, linear_cache = linear_forward(A_prev, W, b)
A, activation_cache = sigmoid(Z)
elif activation == "relu":
# Inputs: "A_prev, W, b". Outputs: "A, activation_cache".
Z, linear_cache = linear_forward(A_prev, W, b)
A, activation_cache = relu(Z)
assert (A.shape == (W.shape[0], A_prev.shape[1]))
cache = (linear_cache, activation_cache)
return A, cache
1.3.3
def L_model_forward(X, parameters):
caches = []
A = X
L = len(parameters) // 2
for l in range(1, L):
A_prev = A
A, cache = linear_activation_forward(A_prev, parameters["W"+str(l)], parameters["b"+str(l)], "relu")
caches.append(cache)
AL, cache = linear_activation_forward(A, parameters["W"+str(L)], parameters["b"+str(L)], "sigmoid")
caches.append(cache)
assert(AL.shape == (1,X.shape[1]))
return AL, caches
1.4 Cost Function

def compute_cost(AL, Y):
m = Y.shape[1]
cost = -1/m*np.sum(Y*np.log(AL)+(1-Y)*np.log(1-AL))
cost = np.squeeze(cost) # To make sure your cost's shape is what we expect (e.g. this turns [[17]] into 17).
assert(cost.shape == ())
return cost
1.5 Backward propagation module
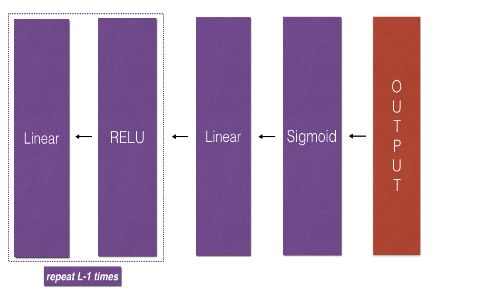
后向过程包括3个部分:Linear Backward,Linear-Activation backward 和 L-Model Backward

1.5.1 Linear Backward

def linear_backward(dZ, cache):
A_prev, W, b = cache
m = A_prev.shape[1]
dW = 1/m*np.dot(dZ,A_prev.T)
db = 1/m*np.sum(dZ,axis=1,keepdims=True)
dA_prev = np.dot(W.T,dZ)
assert (dA_prev.shape == A_prev.shape)
assert (dW.shape == W.shape)
assert (db.shape == b.shape)
return dA_prev, dW, db
1.5.2 Linear-Activation backward
计算公式为:
def linear_activation_backward(dA, cache, activation):
linear_cache, activation_cache = cache
if activation == "relu":
dZ = relu_backward(dA, activation_cache)
dA_prev, dW, db = linear_backward(dZ, linear_cache)
elif activation == "sigmoid":
dZ = sigmoid_backward(dA, activation_cache)
dA_prev, dW, db = linear_backward(dZ, linear_cache)
return dA_prev, dW, db
1.5.3 L-Model Backward
def L_model_backward(AL, Y, caches):
grads = {}
L = len(caches)
m = AL.shape[1]
Y = Y.reshape(AL.shape)
dAL = np.divide(1-Y,1-AL)-np.divide(Y,AL)
current_cache = caches[L-1]
grads["dA" + str(L)], grads["dW" + str(L)], grads["db" + str(L)] = linear_activation_backward(dAL, current_cache, "sigmoid")
for l in reversed(range(L-1)):
current_cache = caches[l]
dA_prev_temp, dW_temp, db_temp = linear_activation_backward(grads["dA"+str(l+2)], current_cache, "relu")
grads["dA" + str(l + 1)] = dA_prev_temp
grads["dW" + str(l + 1)] = dW_temp
grads["db" + str(l + 1)] = db_temp
return grads
1.6 Update Parameters
最后是update weight和bias
def update_parameters(parameters, grads, learning_rate):
L = len(parameters) // 2 # number of layers in the neural network
for l in range(L):
parameters["W" + str(l+1)] = parameters["W"+str(l+1)]-learning_rate*grads["dW"+str(l+1)]
parameters["b" + str(l+1)] = parameters["b"+str(l+1)]-learning_rate*grads["db"+str(l+1)]
return parameters
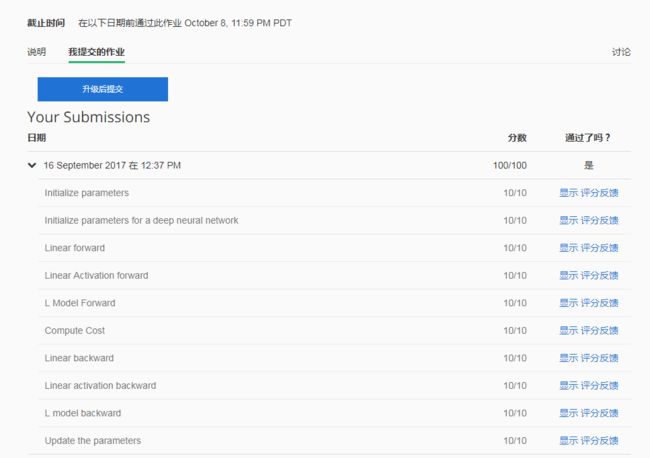
最后附上我作业的得分,表示我程序没有问题,如果觉得我的文章对您有用,请随意打赏,我将持续更新Deeplearning.ai的作业!