参考文章:
Apache Storm 官方文档中文版
storm Tutorial 的解读 + 个人理解
官方文档组件概念
Nimbus和Supervisor
Strom集群中有一个主控节点和一个工作节点。主控节点中运行一个叫"Nimbus"的守护进程;而工作节点中运行一个"Supervisor"的守护进程。
Nimbus主控节点
Nimbus是作为调度器角色,它负责在集群内分发代码,为每个工作结点指派任务和监控失败的任务;用于响应分布在集群中的节点,分配任务和监测故障。这个很类似于Hadoop中的Job Tracker。
Supervisor工作结点
Supervisor 作为worker的代理角色,用于收听工作(Worker)指派并基于要求运行工作进程。每个工作节点都是topology中一个子集的实现。而Nimbus和Supervisor之间的协调则通过Zookeeper系统或者集群
Zookeeper
zookeeper作为整个系统的协调者,协调Supervisor和Nimbus之间的服务。Nimbus和Supervisor之间的所有协调工作都是通过一个Zookeeper集群来完成。并且,nimbus进程和supervisor都是快速失败(fail-fast)和无状态的。所有的状态要么在Zookeeper里面,要么在本地磁盘上。这也就意味着你可以用kill-9来杀死nimbus和supervisor进程,然后再重启它们,它们可以继续工作,就好像什么都没有发生过似的。这个设计使得storm不可思议的稳定。
Topology拓扑的构成
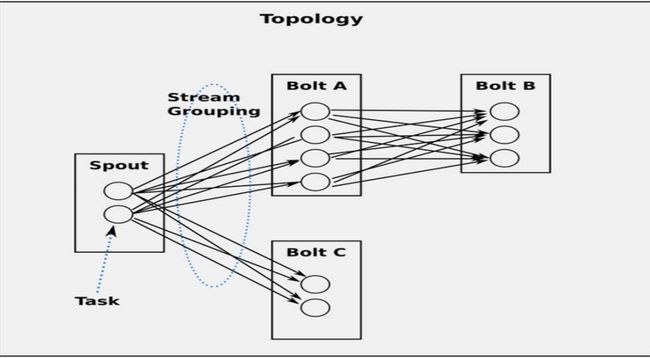
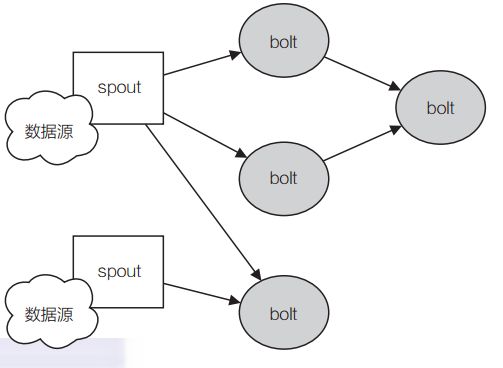
1、Storm 分布式计算结构称为 topology(拓扑),由 stream(数据流),spout(数据流的生成者), bolt(运算)组成。各个组件间的消息流动形成逻辑上的一个拓扑结构。
2、一个topology是spouts和bolts组成的图, 通过streamgroupings将图中的spouts和bolts连接起来。
3、Storm topology 大致等同与 Hadoop 这类批处理运算中的 job。然而,批处理运算中的 job对运算的起始和终止有着明确定义, Stormtopology 会一直运行下去,除非进程被杀死或被取消部署
Tuple
1 、storm使用tuple来作为它的数据模型。
2、tuple是 包 含 了 一 个 或 者 多 个 键 值 对 的 列 表;每个值有一个名字,并且每个值可以是任何类型, 在我的理解里面一个tuple可以看作一个没有方法的java对象。总体来看,storm支持所有的基本类型、字符串以及字节数组作为tuple的值类型。你也可以使用你自己定义的类型来作为值类型, 只要你实现对应的序列化器(serializer)。
3、一个Tuple代表数据流中的一个基本的处理单元,例如一条cookie日志,它可以包含多个Field,每个Field表示一个属性
4、Tuple本来应该是一个Key-Value的Map,由于各个组件间传递的tuple的字段名称已经事先定义好了,所以Tuple只需要按序填入各个Value,所以就是一个Value List。
Stream
1、Stream是storm里面的关键抽象。
2、一个没有边界的、源源不断的、连续的Tuple序列就组成了Stream
3、storm提供一些原语来分布式地、可靠地把一个stream传输进一个新的stream。比如: 你可以
把一个tweets流传输到热门话题的流。
4、提供的最基本的处理stream的原语是spout和bolt。你可以实现Spout和Bolt对应的接口以处理你的应用的逻辑。
消息源头Spout
1、是一个topology里面的消息生产者,充当采集器的角色。
2、Spout会从外部数据源(队列、数据库等)读取数据,然后封装成Tuple形式,之后发送到Strea中。
3、Spout是一个主动的角色,在接口内部有个nextTuple函数,Storm框架会不停的调用该函数。
4、开发一个 spout 的主要工作就是编写代码从数据源或者 API 消费数据,而不会用来实现具体的业务逻辑。
Blot
1、Topology中所有的处理都由Bolt完成。即所有的消息处理逻辑(具体的业务逻辑)被封装在bolts里面。 Bolt可以完成任何事,比如:过滤 tuple、连接( join)和聚合操作( aggregation)、访问文件/数据库、等等。
2、将一个或者多个Stream数据流作为输入,对数据实施运算后,选择性地输出一个或者多个新的数据流Stream
3、Bolt是一个被动的 角色,其接口中有一个execute(Tuple input)方法,在接收到消息之后会调用此函数,用户可以在此方法中执行自己的处理逻辑。
4、如果遇到复杂流的处理也可能将tuple发送给另一个Bolt进行处理。即在实时计算的项目中通常需要经过很多blots。
Stream Groupings
Stream Grouping定义了一个流在Bolt任务间该如何被切分。 这里有storm提供的9个Stream Grouping类型
1、shuffleGrouping(随机分组)
随机分发tuple到Bolt的任务,保证每个任务获得相等数量的tuple。
2、fieldsGrouping(字段分组)
根据指定字段分割数据流,并分组。例如,根据"user-id"字段,相同"user-id"的元组总是分发到同一个任务,不同“ user-id”的元组可能分发到不同的任务。
原理是 对某个或几个字段做hash,然后用hash结果求模得出目标taskId。
3、globalGrouping(全局分组)
全部流都分配到bolt的同一个任务。明确地说,是分配给ID最小的那个task。
4、allGrouping(全部分组)
tuple被复制到bolt的所有任务。这种类型需要谨慎使用。
5、directGrouping(直接分组)
这是一个特别的分组类型。元组生产者决定tuple由哪个元组处理者(Blot)任务接收。
6、noneGrouping(无分组)
目前,无分组等效于随机分组。但最终,Storm将把无分组的Bolts放到Bolts或Spouts订阅它们的同一线程去执行(如果可能)。
7、localOrShuffleGrouping(本地或随机分组)
如果目标bolt有一个或多个任务在同一个的worker进程中,tuples会随机发送给这些任务。 否则,就和普通的随机分组一样。
8、PartialKeyGrouping(部分关键字分组) after v1.0.0
这种方式与字段分组很相似,根据定义的字段来对数据流进行分组,不同的是,这种方式会考虑下游 Bolt 数据处理的均衡性问题,在输入数据源关键字不平衡时会有更好的性能。
9、自定义分组
可以实现customGrouping接口来选择出目标task。
总结
每个Topology都由Spout和Bolt组成,在Spout和Bolt传递信息的基本单位叫做Tuple,由Spout发出的连续不断的Tuple及其在相应Bolt上处理的子Tuple连起来称为一个Steam,每个Stream的命名是在其首个Tuple被Spout发出的时候,此时Storm会利用内部的Ackor机制保证每个Tuple可靠的被处理。而Tuple可以理解成键值对,其中,键就是在定义在declareStream方法中的Fields字段,而值就是在emit方法中发送的Values字段
运行中的Topology的组件
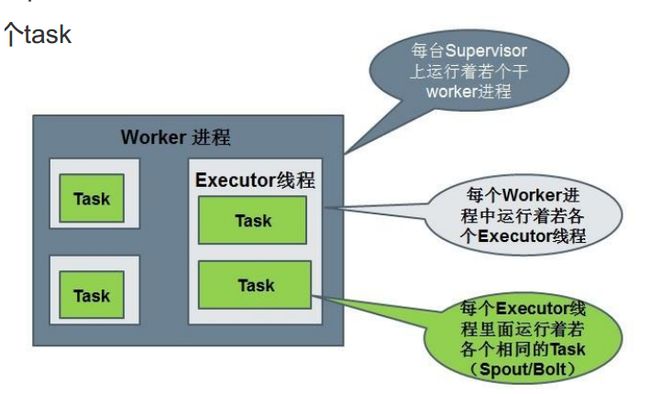
Worker processes(进程)
1、运行具体处理组件逻辑的进程
2、一个Topology可能会在一个或者多个Worker(工作进程)里面执行,每个worker是一个物理JVM并且执行整个Topology的一部分。 storm会尽量均匀地将工作分配给所有的worker。
Executors (threads)(线程)
executor:每个execcutor对应一个线程。 1个executor是1个worker进程生成的1个线程。它可能运行着1个相同的组件(spout或bolt)的1个或多个task。
Tasks
每个Spout或者Bolt 会被当做很多task在整个集群中运行,在executor这个线程中运行一个或多个task。