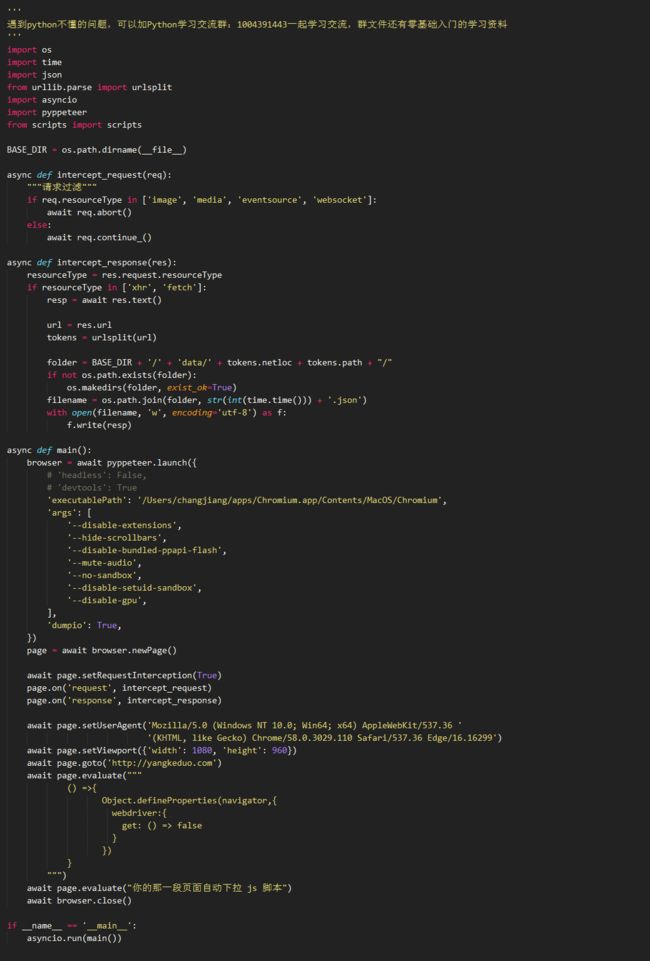
pyppeteer是对无头浏览器puppeteer的 Python 封装。无头浏览器广泛用于自动化测试,同时也是一种很好地爬虫思路。
使用 puppeteer(等其他无头浏览器)的最大优势当然是对 js 加密实行降维打击,完全无视 js 加密手段,对于一些需要登录的应用,也可以模拟点击然后保存 cookie。而很多时候前端的加密是爬虫最难攻克的一部分。当然puppeteer也有劣势,最大的劣势就是相比面向接口爬虫效率很低,就算是无头的chromium,那也会占用相当一部分内存。另外额外维护一个浏览器的启动、关闭也是一种负担。
这篇文章我们来写一个简单的 demo,爬取拼多多搜索页面的数据,最终的效果如下:
我们把所有 api 请求的原始数据保存下来:
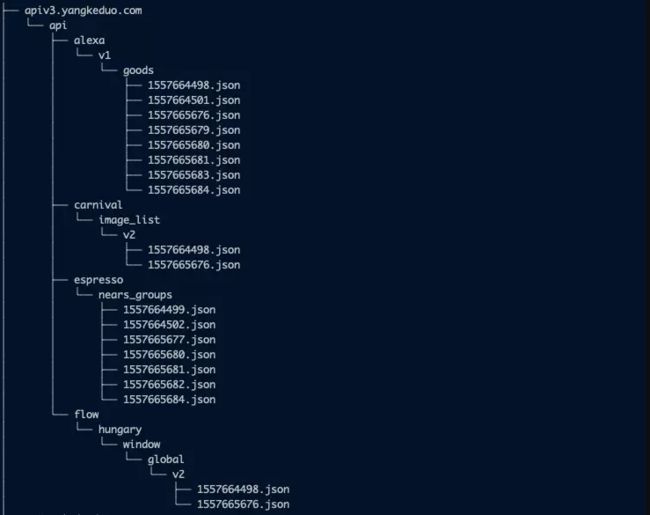
示例 json 文件如下:

开发环境
python3.6+
最好是 python3.7,因为asyncio在 py3.7中加入了很好用的asyncio.run()方法。
安装pyppeteer
如果安装有问题请去看官方文档。
python3 -m pipinstallpyppeteer
安装 chromium
你懂的,天朝网络环境很复杂,如果要用pyppeteer自己绑定的chromium,半天都下载不下来,所以我们要手动安装,然后在程序里面指定executablePath。
下载地址:www.chromium.org/getting-inv…
hello world
pyppeteer的 hello world 程序是前往exmaple.com截个图:

pyppeteer 重要接口介绍
pyppeteer.launch
launch 浏览器,可以传入一个字典来配置几个options,比如:

其中所有可选的args参数在这里:peter.sh/experiments…
dumpio的作用:把无头浏览器进程的 stderr 核 stdout pip 到主程序,也就是设置为 True 的话,chromium console 的输出就会在主程序中被打印出来。
注入 js 脚本
可以通过page.evaluate形式,例如:

我们会看到这一步非常关键,因为puppeteer出于政策考虑(这个词用的不是很好,就是那个意思)会设置window.navigator.webdriver为true,告诉网站我是一个 webdriver 驱动的浏览器。有些网站比较聪明(反爬措施做得比较好),就会通过这个来判断对方是不是爬虫程序。
这等价于在 devtools 里面输入那一段 js 代码。
还可以加载一个 js 文件:
awaitpage.addScriptTag(path=path_to_your_js_file)
通过注入 js 脚本能完成很多很多有用的操作,比如自动下拉页面等。
截获 request 和 response
awaitpage.setRequestInterception(True)page.on('request', intercept_request)page.on('response', intercept_response)
intercept_request和intercept_response相当于是注册的两个回调函数,在浏览器发出请求和获取到请求之前指向这两个函数。
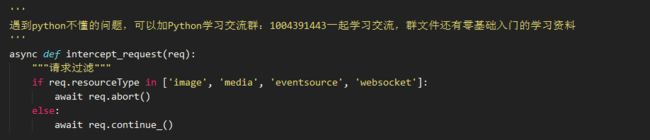
比如可以这样禁止获取图片、多媒体资源和发起 websocket 请求:
然后每次获取到请求之后将内容打印出来(这里只打印了fetch和xhr类型response 的内容):

一共有哪些resourceType,pyppeteer文档里面有:

拼多多搜索爬虫
页面自动下拉
拼多多的搜索界面是一个无限下拉的页面,我们希望能够实现无限下拉页面,并且能够控制程序提前退出,不然一直下拉也不好,我们可能并不需要那么多数据。
js 脚本

这里面有几个重要的参数:
interval : 下拉间隔时间,以毫秒为单位
maxScrollHeight : 运行页面下拉最大高度
maxScrollTimes : 最多下拉多少次(推荐使用,可以更好控制爬取多少数据)
maxTries : 下拉不成功时最多重试几次,比如有时候会因为网络原因导致没能在 interval ms 内成功下拉
把这些替换成你需要的。同时你可以打开 chrome 的开发者工具运行一下这段 js 脚本。
完整代码
这段代码一共也就只有70多行,比较简陋,情根据自己的实际需求更改。