说明:本机是在win10系统下,安装用的是VMware15, centOS7, JDK1.8, spark-2.4.0,hadoop-2.7.7, apache-hive-2.3.4, scala-2.12.8。在VMware里创建了node01, node02, node03, node04四个节点(或者叫四个虚拟机)。注意
在使用vm14版本的时候出现黑屏,情况如下:
在vm上安装好4个节点后,用管理员身份打开VM,启动节点有时候会碰到启动的节点是黑屏的情况,一直挂起,解决方法:
以管理员身份运行cmd控制台程序
输入命令netsh winsock reset
作用是重置winsock网络规范,然后重启系统,在打开VMware就可以了。vm15目前没有出现过黑屏。
安装好CentOS7后
关闭防火墙:
查看防火墙状态命令: systemctl status firewalld.service
关闭防火墙命令: systemctl stop firewalld.service
禁用防火墙命令: systemctl disable firewalld.service
查看ip地址命令: ip addr
设置网络为静态Ip
命令: vi /etc/sysconfig/network-scripts/ifcfg-ens33
修改: BOOTPROTO = dhcp 改为 BOOTPROTO = static
添加下面内容:
IPADDR = 用ip addr命令查的ip地址
NETMASK=255.255.255.0
GATEWAY=用ip addr命令查的ip地址的网关
DNS1=119.29.29.29
重启网卡: systemctl restart network.service
测试外网: ping –c 4 www.baidu.com
安装好CentOS7后,网络配置配好,并且能ping通百度,固定IP
一:安装SSH
- 检查SSH是否开启
命令: yum list installed | grep openssh-server
此处显示已经安装了openssh-server, 如果没有任何输出显示表示没有安装openssh-server,通过输入 yum install openssh-server来安装openssh-server - 找到/etc/ssh/目录下的sshd服务配置文件sshd_config,用vi编辑打开。将文件中,关于监听端口,监听地址前的#号去掉
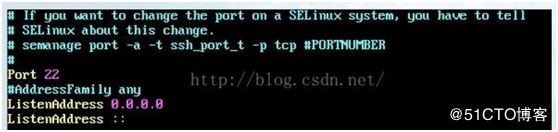
然后开启允许远程登陆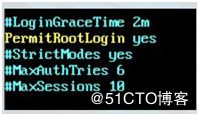
开启使用用户密码来作为连接登录
保持文件,退出 - 开启sshd服务,输入sudo service sshd start
检查sshd服务是否已经开启,输入ps –e | grep sshd
或者输入netstat –an | grep 22 检查22号端口是否开启监听
- 生成访问密钥
cd ~/
ssh-keygen –t rsa –P ‘’ –f ~/.ssh/id_rsa
cd .ssh
cat id_rsa.pub >> authorized_keys
查看SSH服务是否启动: ps aux | grep ssh
检查是否安装SSH: which ssh 或者 which sshd
二:安装JDK
本机安装的是JDK1.8
在/usr下建java文件夹(mkdir java),上传jdk的安装包![]()
命令: tar –xzvf jdk-8u191-linux-x64.tar.gz 解压jdk到当前目录/usr/java中,解压后目录为jdk1.8.0_191,给解压后的JDK赋最大权限(命令: chmod 777 jdk1.8.0_191)
配置jdk的环境变量
命令: vi ~/.bashrc
添加:export JAVA_HOME=/usr/java/jdk1.8.0_191
export PATH=$PATH:$JAVA_HOME/bin
保存退出 后执行命令: source ~/.bashrc
用命令检查是否安装成功: java –version
删除压缩安装包: rm –f jdk-8u191-linux-x64.tar.gz
三:安装scala(如果不是用scala语言写的可以不用装)本机安装的是scala-2.12.8, 同时也是安装在目录/usr/java下的
解压命令: tar –xzvf scala-2.12.8.tgz, 解压后给scala-2.12.8赋权限 chmod 777 scala-2.12.8
配置scala的环境变量
命令: vi ~/.bashrc
添加: export SCALA_HOME=/usr/java/scala-2.12.8
export PATH=$PATH:$SCALA_HOME/bin
保存退出,执行命令: source ~/.bashrc
用命令检查是否安装成功: scala -version
删除压缩安装包: rm –f scala-2.12.8.tgz
四:按照上面的步骤分别安装4个节点,本机起名为node01,node02,node03,node04
本机每个节点对应IP地址:
node01: 192.168.213.128 node02 : 192.168.213.129 node03 : 192.168.213.130
node04 : 192.168.213.131
配置每个节点的hostname:
分别在node01 到 node04 四个节点 /etc/hosts文件中把每个ip对于的hostname配置上,后面在配置hadoop的配置文件时候可以直接使用hostname

配置SSH在节点中互相免密切换:
同样的需要分别在四个节点都配置,把其他三个节点的 ~/.ssh/authorized_keys拷贝到本节点中即可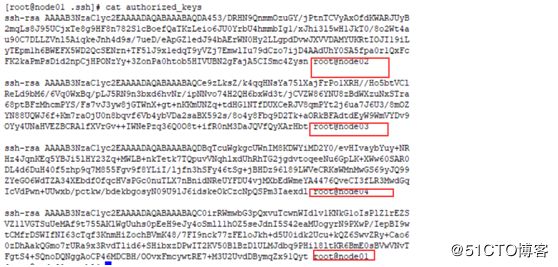
五:在node02,node03, node04 上安装zookeeper,zookeeper必须保证是奇数个![]()
解压命令: tar –xzvf zookeeper-3.4.12.tar.gz, 解压后给zookeeper-3.4.12赋权限 chmod 777 zookeeper-3.4.12
配置zookeeper的环境变量
命令: vi ~/.bashrc
添加: export ZOOKEEPER_HOME=/usr/java/ zookeeper-3.4.12
export PATH=$PATH:$ZOOKEEPER_HOME/bin
保存退出,执行命令: source ~/.bashrc
修改zookeeper的配置文件
-
先在/usr目录下建一个zookeeperData文件夹,zookeeperData文件夹里再建tmp文件夹,tmp文件夹里建个myid文件
在/usr路径下执行命令: mkdir zookeeperData ;
在/usr/zookeeperData路径下执行: mkdir tmp;
在/usr/zookeeperData/tmp路径下执行命令:touch myid
Node02节点在 /usr/zookeeperData/tmp路径下执行: echo 1 > myid 往myid文件里写标识
Node03节点在 /usr/zookeeperData/tmp路径下执行: echo 2 > myid 往myid文件里写标识
Node04节点在 /usr/zookeeperData/tmp路径下执行: echo 3 > myid 往myid文件里写标识 - 在zookeeper安装目录/zookeeper-3.4.12/conf目录下,执行命令: cp zoo_sample.cfg zoo.cfg ; (node02, node03, node04 三个节点都要改)
- 修改zoo.cfg文件(node02, node03, node04 三个节点都要改)

修改dataDir的路径,和添加server
测试zookeeper是否配置正确:
node02中在路径/usr/java/zookeeper/bin执行命令./zkServer.sh start
node03中在路径/usr/java/zookeeper/bin执行命令./zkServer.sh start
node04中在路径/usr/java/zookeeper/bin执行命令./zkServer.sh start
查看节点状态:
node02中在路径/usr/java/zookeeper/bin执行命令./zkServer.sh status
node03中在路径/usr/java/zookeeper/bin执行命令./zkServer.sh status
node04中在路径/usr/java/zookeeper/bin执行命令./zkServer.sh status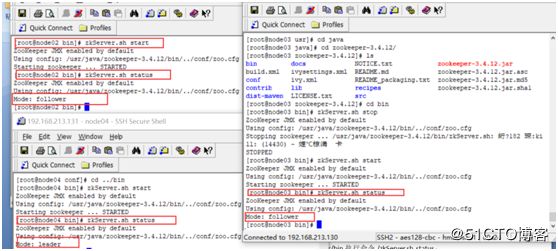
六:安装hadoop
分别在node01, node02, node03, node04四个节点上配置hadoop的环境变量
解压命令: tar –xzvf hadoop-2.7.7.tar.gz, 解压后给hadoop-2.7.7赋权限 chmod 777 hadoop-2.7.7
配置hadoop的环境变量
命令: vi ~/.bashrc
添加: export HADOOP_HOME=/usr/java/ hadoop-2.7.7
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
保存退出,执行命令: source ~/.bashrc
修改hadoop中的配置文件:
1.在路径/usr/java/hadoop-2.7.7/etc/hadoop 执行命令 vi hadoop-env.sh
修改hadoop-env.sh配置文件中jdk的路径:
#修改JAVA_HOME
export JAVA_HOE=/usr/java/jdk1.8.0_191
-
node01节点上在路径/usr/java/hadoop-2.7.7/etc/hadoop/core-site.xml, 修改core-site.xml
core-site.xml内容如下:fs.defaultFS hdfs://mycluster hadoop.tmp.dir /var/testHadoop/haTest ha.zookeeper.quorum node02:2181,node03:2181,node04:2181
-
node01节点上在路径/usr/java/hadoop-2.7.7/etc/hadoop/hdfs-site.xml, 修改hdfs-site.xml
修改内容如下:dfs.replication 2 dfs.nameservices mycluster dfs.ha.namenodes.mycluster nn1,nn2 dfs.namenode.rpc-address.mycluster.nn1 node01:8020 dfs.namenode.rpc-address.mycluster.nn2 node02:8020 dfs.namenode.http-address.mycluster.nn1 node01:50070 dfs.namenode.http-address.mycluster.nn2 node02:50070 dfs.namenode.shared.edits.dir qjournal://node01:8485;node02:8485;node03:8485/mycluster
- node01节点上在路径/usr/java/hadoop-2.7.7/etc/hadoop/yarn-site.xml, 修改yarn-site.xml
修改内容如下:
yarn.nodemanager.aux-services
mapreduce_shuffle
-
node01节点上在路径/usr/java/hadoop-2.7.7/etc/hadoop/mapred-site.xml, 修改mapred-site.xml
修改内容如下:mapreduce.framework.name yarn
- node01节点上在路径/usr/java/hadoop-2.7.7/etc/hadoop修改slaves配置文件
node02
node03
node04
在node02节点上配置hadoop的配置文件
也是在路径/usr/java/hadoop-2.7.7/etc/hadoop下修改
修改core-site.xml:
修改hdfs-site.xml配置文件:
修改mapred-site.xml配置文件:
修改slaves配置文件
node02
node03
node04
修改yarn-site.xml的配置:
yarn.nodemanager.aux-services
mapreduce_shuffle
node03, node04节点的配置和node02一样
第一次启动顺序(初次启动):
a) 在node01, node02, node03 上路径/usr/java/hadoop-2.7.7/sbin执行./hadoop-daemon.sh start journalnode
b) 在node01上路径/usr/java/hadoop-2.7.7/sbin下执行命令:
命令: ./hadoop-daemon.sh start namenode
c) 在node01上路径/usr/java/hadoop-2.7.7/bin下执行格式化命令:
命令: ./hdfs namenode –format
c ) 在node02上路径/usr/java/hadoop-2.7.7/bin下执行命令:
命令: ./hdfs namenode -bootstrapStandby
d) 在node01上路径/usr/java/hadoop-2.7.7/bin下执行格式化命令:
命令: ./hdfs zkfc –formatZK
注意: 第一次如果不格式化的访问http://node01:50070/,http://node02:50070/ 两个的页面的状态都是standby
e) 在node01上路径/usr/java/hadoop-2.7.7/sbin下执行命令:
命令: ./ start-dfs.sh
命令:./ start-yarn.sh
f) 在node03, node04上在路径 /usr/java/hadoop-2.7.7/sbin下执行命令:
命令: ./yarn-daemon.sh start resourcemanager
g) 在node03上路径 /usr/java/hadoop-2.7.7/sbin执行命令:
命令: mr-jobhistory-daemon.sh start historyserver
访问页面:
http://node01的ip地址:50070 状态为active(yarm)
http://node02的ip地址:50070 状态为standby
http://node03的ip地址: 8088/cluster/cluster 状态为active(hdfs)
http://node04的ip地址: 8088/cluster/cluster 状态为standby
http://192.168.180.130:19888/jobhistory 历史日志查询
第二次之后的启动顺序就可以按
node02, node03, node04节点上的 zookeeper启动如果hadoop的hdfs已经装好了,并且有元数据得时候,重启的方式按道理讲直接start-all.sh 就可以,千万不能格式化,但本机重启的时候 可以用下面方式:
node01, node02, node03 执行命令: ./hadoop-daemon.sh start journalnode
node01执行: ./ Hadoop-daemon.sh start namenode
node02执行: ./hdfs namenode -bootstrapStandby
node01执行: ./start-dfs.sh
node01上执行命令: ./start-yarn.sh
node03, node04上执行 ./yarn-daemon.sh start resourcemanager
node03执行:mr-jobhistory-daemon.sh start historyserver
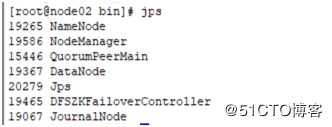
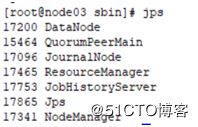
完成后用jps查询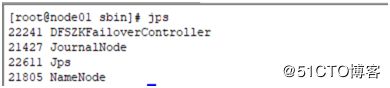
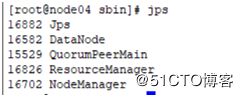
七:安装spark集群:
Spark集群安装在node01, node02, node03, node04四个节点上, 其中node01为spark主节点,node02为spark的备用主节点,node02,node03,node04为worker节点
命令tar-zxvf spark-2.4.0-bin-hadoop2.7.tgz
在宿主机~/.bashrc添加scala的参数(命令: vi ~/.bashrc)
export SPARK_HOME=/usr/java/spark-2.4.0-bin-hadoop2.7
export PATH=PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
修改Spark的配置文件:
在路径/usr/java/spark-2.4.0-bin-hadoop2.7/conf路径下,执行命令: cp spark-env.sh.template spark-env.sh
修改spark-env.sh配置文件,在此配置文件中添加:
export SPARK_MASTER_IP=node01
export SPARK_WORKER_MEMORY=1G
export SPARK_MASTER_PROT=7077
export SPARK_WORKER_CORES=2
export SPARK_WORKER_INSTANCES=1
export SPARK_MASTER_WEBUI_PORT=8888
export JAVA_HOME=/usr/java/jdk1.8.0_191
export HADOOP_CONF_DIR=/usr/java/hadoop-2.7.7/etc/hadoop
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=node02:2181,node03:2181,node04:2181 -Dspark.deploy.zookeeper.dir=/var/testSpark/data"
export SPARK_WORKER_OPTS="-Dspark.worker.cleanup.enabled=true -Dspark.worker.cleanup.interval=1800 -Dspark.worker.cleanup.appDataTtl=3600"
在路径下/usr/java/spark-2.4.0-bin-hadoop2.7/conf下,修改slaves文件,此文件是配置worker节点的
配置内容如下:
node02
node03
node04
hadoop集群启动下,在命令行先执行命令: hdfs dfs –mkdir –p /spark/log 创建sparklog目录
在路径/usr/java/spark-2.4.0-bin-hadoop2.7/conf路径下,执行命令: cp spark-defaults.conf.template spark-defaults.conf
修改spark-defaults.conf配置文件,添加内容如下:
spark.eventLog.enabled true
spark.eventLog.dir hdfs://mycluster/spark/log
spark.history.fs.logDirectory hdfs://mycluster/spark/log
spark.eventLog.compress true
把之前配置好的hadoop文件,路径/usr/java/hadoop2.7.7/etc/hadoop 下的core-site.xml,hdfs-site.xml,yarn-site.xml拷贝到路径/usr/java/spark-2.4.0-bin-hadoop2.7/conf下
Node02, node03, node04节点分别按上述执行,注意node02节点的spark-env.sh配置文件,要把SPARK_MASTER_IP改成node02,其他节点不用变。
Spark启动顺序:
Node01在路径/usr/java/spark-2.4.0-bin-hadoop2.7/sbin下执行命令:
命令:./start-master.sh
./start-all.sh
Node02在路径/usr/java/spark-2.4.0-bin-hadoop2.7/sbin下执行命令:
命令: ./start-master.sh
Node03在路径/usr/java/spark-2.4.0-bin-hadoop2.7/sbin下执行命令:
命令: ./start-history-server.sh (日志服务)
Jps查看进程: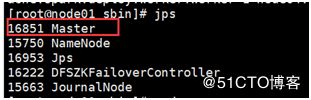
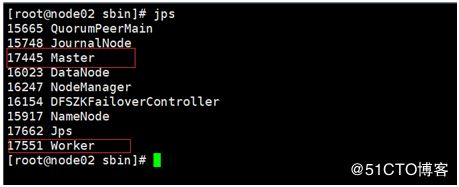
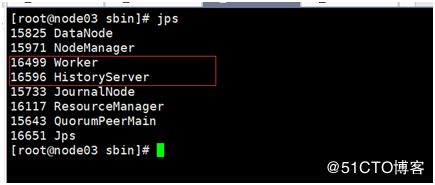
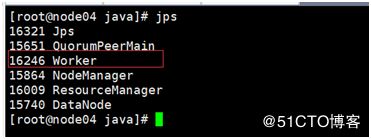
访问页面地址:http://node01节点IP地址:8888/ 状态:active
http:// node02节点IP地址:8888/ 状态:standby
http:// node03节点IP地址:18080/ 日志查询页面
八安装hive
8.1 先安装mysql在node01上
1.CentOS7上如果没有wget命令,可执行命令: yum -y install wget 安装wget命令
2.下载mysql源安装包
命令:wget http://dev.mysql.com/get/mysql57-community-release-el7-8.noarch.rpm
3.安装mysql源:
yum localinstall mysql57-community-release-el7-8.noarch.rpm
4.查看mysql源是否安装成功
yum repolist enabled | grep "mysql.-community."
- 如果想修改mysql版本的话:修改 vim /etc/yum.repos.d/mysql-community.repo源 ,改变默认安装的mysql版本。比如要安装5.6版本,将5.7源的enabled=1改成enabled=0。然后再将5.6源的enabled=0改成enabled=1即可。
6.安装mysql:
yum install mysql-community-server
7.启动mysql服务:
systemctl start mysqld
8.开机启动:
shell>systemctl enable mysqld
shell>systemctl daemon-reload- 修改root本地登录密码
1)查看mysql密码
shell> grep 'temporary password' /var/log/mysqld.log
2)连接mysql
shell> mysql -uroot -p
3)修改密码[注意:后面的分号一定要跟上]
mysql> ALTER USER 'root'@'localhost' IDENTIFIED BY 'MyNewPass4!';
或者:
mysql> set password for 'root'@'localhost'=password('MyNewPass4!');
- 修改root本地登录密码
mysql> show variables like '%password%';
3.1: 首先需要设置密码的验证强度等级,设置validate_password_policy的全局参数为 LOW 即可,
输入设值语句 “ set global validate_password_policy=LOW; ” 进行设值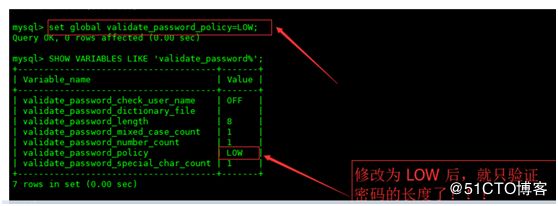
当前密码长度为 8 ,如果不介意的话就不用修改了,按照通用的来讲,设置为 6 位的密码,设置validate_password_length的全局参数为 6 即可,设置长度是4的话root就可以
输入设值语句 “ set global validate_password_length=6; ” 进行设值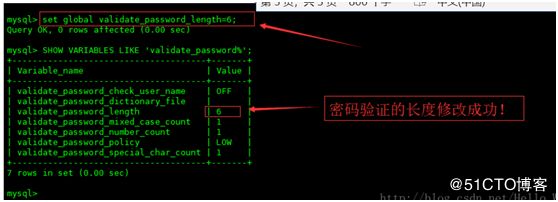
10:添加远程登陆用户
mysql> GRANT ALL PRIVILEGES ON . TO 'root'@'%' IDENTIFIED BY 'root' WITH GRANT OPTION;
mysql> flush privileges; ---刷新我本机没有执行此命令
11.查看数据库字符集
mysql> show variables like '%character%';
12.修改数据库字符集:
退出mysql,在 /etc/my.cnf
命令: vi my.cnf
在[mysqld]下面添加:
character-set-server=utf8 --设置字符集
sql_mode=STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION --设置支持groupby预计
default-time_zone = '+8:00' --设置时区为东八区
然后重启mysql,命令: systemctl restart mysqld
- 查看数据库权限 use mysql ==> desc user ==》select user,host,password from user;
8.2 安装hive,本机安装的是apache-hive-2.3.4-bin.tar.gz,此处安装的是hive多用户模式,在node01节点安装
1.上传hive包到node01,解压,配置环境变量,node01是服务端
解压命令: tar –xzvf apache-hive-2.3.4-bin.tar.gz
赋权限: chmod 777 apache-hive-2.3.4-bin
配置环境变量: vi ~/.bashrc
添加: export HIVE_HOME=/usr/java/apache-hive-2.3.4-bin
export PATH=$PATH:$HIVE_HOME/bin
保存,并执行命令: source ~/.bashrc 生效
在node01上路径/usr/java/apache-hive-2.3.4-bin/conf 下执行:
命令: scp hive-default.xml.template hive-site.xml
编辑修改hive-site.xml文件,修改内容如下:hive.metastore.warehouse.dir /user/hive/warehouse
把mysql的驱动包添加到node01节点上 /usr/java/ apache-hive-2.3.4-bin/lib 路径下;
检查/usr/java/apache-hive-2.3.4-bin/lib 路径下的jlinejar包和hadoop中路径:${HADOOP_HOME}/share/hadoop/yarn/lib目录下jline.jar包版本是否一致,如果两个不一致的话启动会报:
[ERROR] Terminal initialization failed; falling back to unsupported
java.lang.IncompatibleClassChangeError: Found class jline.Terminal, but interface was expected
at jline.TerminalFactory.create(TerminalFactory.java:101)
保存hive和hadoop中jline.jar包版本一致,把hive中的jline.jar拷贝到hadoop中;
(选择配置)如果找不到hadoop的配置话,在conf路径下有个hive-env.sh里配置;
在hdfs里添加 /user/hive/warehouse目录
创建这个目录命令:hdfs dfs -mkdir /user
hdfs dfs -mkdir /user/hive
hdfsd fs -mkdir /user/hive/warehouse
在node02上安装hive客户端:
- 和node01一样,上传安装包,解压,配置环境变量
- 修改${HIVE_HOME}/conf路径下的hive-site.xml文件内容:
内容为;hive.metastore.warehouse.dir /user/hive/warehouse hive.metastore.local false hive.metastore.uris thrift://node01:9083 hive.support.sql11.reserved.keywords false - 把mysql的驱动包添加到node02节点上 /usr/java/ apache-hive-2.3.4-bin/lib 路径下;
检查/usr/java/apache-hive-2.3.4-bin/lib 路径下的jlinejar包和hadoop中路径:${HADOOP_HOME}/share/hadoop/yarn/lib目录下jline.jar包版本是否一致,如果两个不一致的话启动会报 - 在node02 路径/usr/java/apache-hive-2.3.4-bin/conf下执行命令: cp hive-env.sh.template hive-env.sh, 修改hive-env.sh配置文件,在文件中添加HADOOP_HOME=/usr/java/hadoop-2.7.7.
启动hive顺序:
在node01路径/usr/java/ apache-hive-2.3.4-bin/bin 下执行命令: ./schematool -dbType mysql –initSchema 进行初始化,初始化后在mysql中就有一个hive的数据库
在node01路径下/usr/java/apache-hive-2.3.4-bin/bin下执行命令:
[root@node01 bin]# ./hive --service metastore 启动hive
./hive --service metastore& 后台运行方式
查看端口号:ss –nal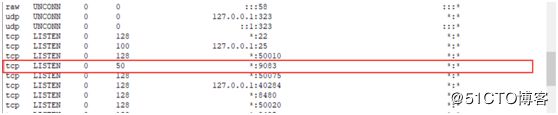
在node02路径/usr/java/apache-hive-2.3.4-bin/bin 执行命令: hive 就可以进入
Hive进入后在node02上进行测试,create table testPsn(id int, age int);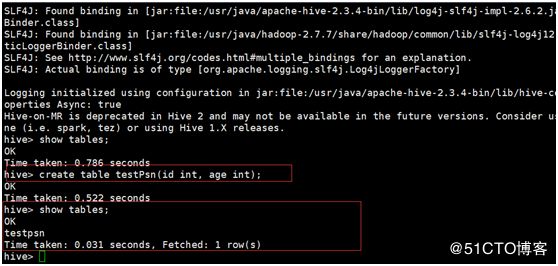
在hdfs中(http://node01IP地址:50070) /user/hive/warehouse中也可以看到创建的testPsn表
九:SPARK整合HIVE
把hive路径/usr/java/ apache-hive-2.3.4-bin/hive-site.xml文件放到/usr/java/ spark-2.4.0-bin-hadoop2.7/conf 路径下,此路径下的hive-site.xml的内容如下:
node01,node02, node03,node04四个节点都要在/usr/java/ spark-2.4.0-bin-hadoop2.7/conf路径下放置hive-site.xml