CUDA编程结构
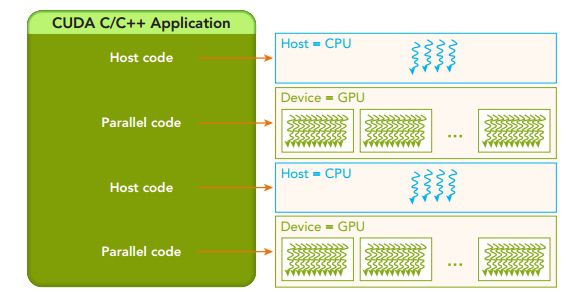
CUDA显存管理
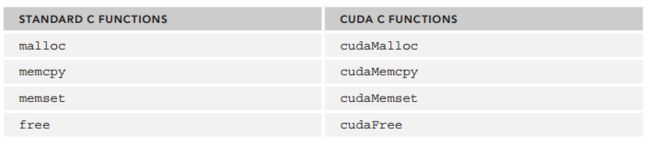
- 分配显存
cudaError_t cudaMalloc ( void** devPtr, size_t size )
- 传输数据
cudaError_t cudaMemcpy ( void* dst, const void* src, size_t count, cudaMemcpyKind kind )
//传输方向:
cudaMemcpyHostToHost
cudaMemcpyHostToDevice
cudaMemcpyDeviceToHost
cudaMemcpyDeviceToDevice
Example:
- 返回类型
cudaSuccess
cudaErrorMemoryAllocation
CUDA内存模型
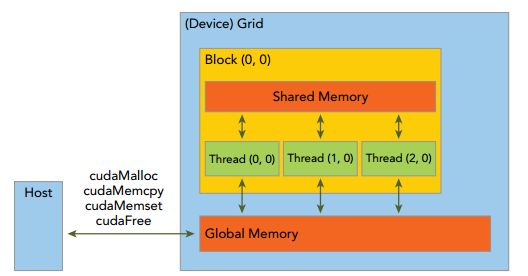
线程
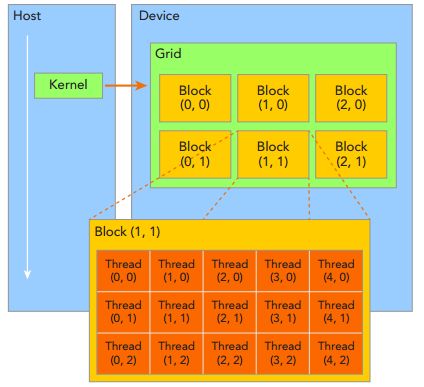
核函数在CPU端创立,在GPU端执行。thread组织成block,block组成grid,一个核函数对应一个grid。block可以一维,二维,三维,grid也可以是一维,二维,三维组织。
block:同一个block内共享内存,同一block中的thread可以彼此进行通信。
block:block-local synchronization。同一个块内的线程可以同步。
线程,可以根据blockIdx和threadIdx唯一的指定。
blockIdx (block index within a grid)
threadIdx (thread index within a block)
blockIdx和threadIdx都是GPU中的内置变量,unit3,blockIdx和threadIdx有3个维度,x,y,z。
threadIdx.x、threadIdx.y、threadIdx.z
blockIdx.x、blockIdx.y、blockIdx.z
➤ blockDim (block dimension, measured in threads)
➤ gridDim (grid dimension, measured in blocks)
另外我们要特别注意,GPU中线程的内置变量定义类型是unit3,在程序中设置block和grid的类型是dim3。dim3在CPU端使用,unit3在GPU中使用。
➤ Decide the block size.定义数据量大小
➤ Calculate the grid dimension based on the application data size and the block size.设置block的大小,再设置grid的大小。
确定block的维度的因素:
➤ Performance characteristics of the kernel(kernel的特性)
➤ Limitations on GPU resources(GPU上的资源)
example 定义block和grid
#include "../common/common.h"
#include
#include
/*
* Display the dimensionality of a thread block and grid from the host and
* device.
*/
__global__ void checkIndex(void)
{
printf("threadIdx:(%d, %d, %d)\n", threadIdx.x, threadIdx.y, threadIdx.z);
printf("blockIdx:(%d, %d, %d)\n", blockIdx.x, blockIdx.y, blockIdx.z);
printf("blockDim:(%d, %d, %d)\n", blockDim.x, blockDim.y, blockDim.z);
printf("gridDim:(%d, %d, %d)\n", gridDim.x, gridDim.y, gridDim.z);
}
int main(int argc, char **argv)
{
// define total data element
int nElem = 6;
// define grid and block structure
dim3 block(3);
dim3 grid((nElem + block.x - 1) / block.x);
// check grid and block dimension from host side
printf("grid.x %d grid.y %d grid.z %d\n", grid.x, grid.y, grid.z);
printf("block.x %d block.y %d block.z %d\n", block.x, block.y, block.z);
// check grid and block dimension from device side
checkIndex<<>>();
// reset device before you leave
CHECK(cudaDeviceReset());
return(0);
}
launching a CUDA Kernel
kernel_name <<>>(argument list);
//根据设置的grid和block可以确定kernel的总线程数,kernel的层次结构。

** 关键点**
1.数据在global memory中是线性存储的,我们可以根据内置变量blickIdx和threadIdx可以唯一的确定某个线程。
2.建立一种映射关系,线程和数据的映射方式。
3.kernel Call 是异步执行的,我理解的异步是kernel中的线程不是同时执行结束的,当核函数创建了以后控制权就返回到host端了。
//强制host端等待所有的线程都完成执行。
cudaError_t cudaDeviceSynchronize(void);
//注意cudaMemcpy函数是同步的,将等待kernel中所有线程都完成了执行,再执行数据的拷贝。
编写kernel函数
__global __void kernel_name(argument list)
//1. kernel返回值必须是void
//2. __global__标识符号

The following restrictions apply for all kernels:
➤ Access to device memory only
➤ Must have void return type
➤ No support for a variable number of arguments
➤ No support for static variables
➤ No support for function pointers
➤ Exhibit an asynchronous behavior
Example:两个数组相加
#include "../common/common.h"
#include
#include
/*
* This example demonstrates a simple vector sum on the GPU and on the host.
* sumArraysOnGPU splits the work of the vector sum across CUDA threads on the
* GPU. Only a single thread block is used in this small case, for simplicity.
* sumArraysOnHost sequentially iterates through vector elements on the host.
*/
void checkResult(float *hostRef, float *gpuRef, const int N)
{
double epsilon = 1.0E-8;
bool match = 1;
for (int i = 0; i < N; i++)
{
if (abs(hostRef[i] - gpuRef[i]) > epsilon)
{
match = 0;
printf("Arrays do not match!\n");
printf("host %5.2f gpu %5.2f at current %d\n", hostRef[i],
gpuRef[i], i);
break;
}
}
if (match) printf("Arrays match.\n\n");
return;
}
void initialData(float *ip, int size)
{
// generate different seed for random number
time_t t;
srand((unsigned) time(&t));
for (int i = 0; i < size; i++)
{
ip[i] = (float)(rand() & 0xFF) / 10.0f;
}
return;
}
void sumArraysOnHost(float *A, float *B, float *C, const int N)
{
for (int idx = 0; idx < N; idx++)
C[idx] = A[idx] + B[idx];
}
__global__ void sumArraysOnGPU(float *A, float *B, float *C, const int N)
{
int i = threadIdx.x;
if (i < N) C[i] = A[i] + B[i];
}
int main(int argc, char **argv)
{
printf("%s Starting...\n", argv[0]);
// set up device
int dev = 0;
CHECK(cudaSetDevice(dev));
// set up data size of vectors
int nElem = 1 << 5;
printf("Vector size %d\n", nElem);
// malloc host memory
size_t nBytes = nElem * sizeof(float);
float *h_A, *h_B, *hostRef, *gpuRef;
h_A = (float *)malloc(nBytes);
h_B = (float *)malloc(nBytes);
hostRef = (float *)malloc(nBytes);
gpuRef = (float *)malloc(nBytes);
// initialize data at host side
initialData(h_A, nElem);
initialData(h_B, nElem);
memset(hostRef, 0, nBytes);
memset(gpuRef, 0, nBytes);
// malloc device global memory
float *d_A, *d_B, *d_C;
CHECK(cudaMalloc((float**)&d_A, nBytes));
CHECK(cudaMalloc((float**)&d_B, nBytes));
CHECK(cudaMalloc((float**)&d_C, nBytes));
// transfer data from host to device
CHECK(cudaMemcpy(d_A, h_A, nBytes, cudaMemcpyHostToDevice));
CHECK(cudaMemcpy(d_B, h_B, nBytes, cudaMemcpyHostToDevice));
CHECK(cudaMemcpy(d_C, gpuRef, nBytes, cudaMemcpyHostToDevice));
// invoke kernel at host side
dim3 block (nElem);
dim3 grid (1);
sumArraysOnGPU<<>>(d_A, d_B, d_C, nElem);
printf("Execution configure <<<%d, %d>>>\n", grid.x, block.x);
// copy kernel result back to host side
CHECK(cudaMemcpy(gpuRef, d_C, nBytes, cudaMemcpyDeviceToHost));
// add vector at host side for result checks
sumArraysOnHost(h_A, h_B, hostRef, nElem);
// check device results
checkResult(hostRef, gpuRef, nElem);
// free device global memory
CHECK(cudaFree(d_A));
CHECK(cudaFree(d_B));
CHECK(cudaFree(d_C));
// free host memory
free(h_A);
free(h_B);
free(hostRef);
free(gpuRef);
CHECK(cudaDeviceReset());
return(0);
}

__global__ void sumArraysOnGPU(float *A, float *B, float *C, const int N)
{
int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < N) C[i] = A[i] + B[i];
}
linux 计算kernel的运行时间
#include
double cpuSeconds()
{
struct timeval tp;
gettimeofday(&tp, NULL);
return ((double)tp.tv_sec + (double)tp.tv_usec * 1.e-6);
}
//计算kernel的时间
double iStart = cpuSecond();
kernel_name<<>>(argument list);
cudaDeviceSynchronize();
double iElaps = cpuSecond() - iStart;
Timing with nvprof
$ nvprof [nvprof_args] [application_args]
$ nvprof --help
$ nvprof ./sumArraysOnGPU-timer
//我的电脑Ubuntu16.04+CUDA8.0报错:
Error:unified memory profiling failed.
//为什么会出现这种情况我还不清楚,但是可以做如下处理
$ nvprof --unified-memory-profiling off ./sumArraysOnGPU-timer
线程的组织形式
不同的block和grid会对kernel性能有很大的影响,下面以矩阵相加为例。
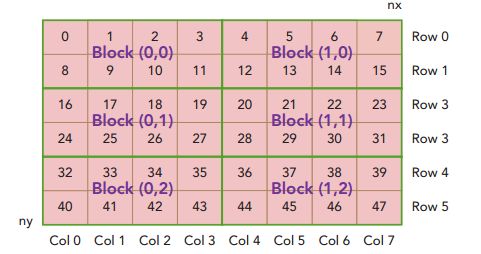
① 以2D的grid和2D的block组织线程,每个thread处理一个数据。
通常而言,矩阵中的元素是线性存储的,是以行为主进行线性的存储。

在一个kernel函数中,可以采用一个thread处理一个位置的元素相加。首先要考虑如下3个问题:
➤线程的索引和块索引
➤矩阵中给定点的坐标
➤线性全局存储器中的偏移量
对于给定的线程,您可以从块索引和线程索引中获取全局内存中的偏移量
将线程索和块索引映射到矩阵中的坐标,然后映射这些矩阵
坐标到全局内存位置。
➤1.将线程索引和块索引映射到矩阵中的坐标。
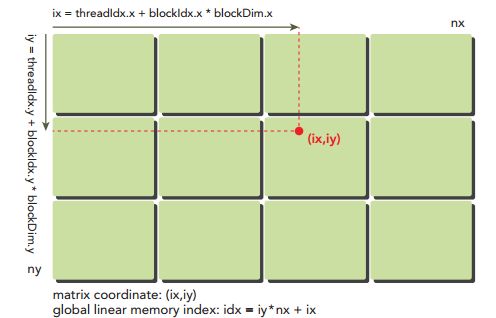
ix=threadIdx.x+blockIdx.x*blockDim.x
iy=threadIdx.y+blockIdx.y*blockDim.y
➤2.根据矩阵中的坐标计算偏移量(行为主)
idx=ix*nx+iy
注意:这里的x指的是横坐标,y指的纵坐标,一定要和矩阵的行列区分开来
➤3.设置block和grid
dim3 blcok(32,32);
dim3 grid((nx+block.x-1)/block.x,(ny+block.y-1)/block.y);
sumMatrixOnGPU2D<<>>(d_MatA, d_MatB, d_MatC, nx, ny)
__global__ void sumMatrixOnGPU2D(float *MatA, float *MatB, float *MatC,
int nx, int ny) {
unsigned int ix = threadIdx.x + blockIdx.x * blockDim.x;
unsigned int iy = threadIdx.y + blockIdx.y * blockDim.y;
unsigned int idx = iy*nx + ix;
if (ix < nx && iy < ny)
MatC[idx] = MatA[idx] + MatB[idx];
}
②1D的grid和1D的block,,每个thread处理多个数据。
如果grid和block都是一维的,但是grid和block每一维有最大的限制,当数据量比较大时,一个线程不能只处理一个数据,可以一个线程处理多个数据。比如可以将一个线程处理ny个数据。
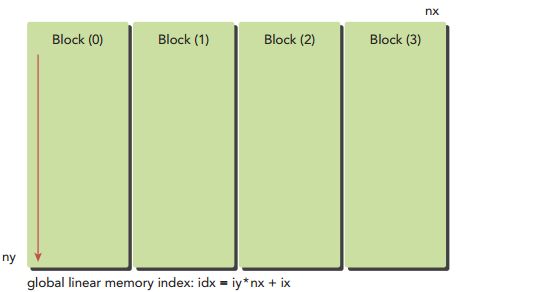
dim3 blcok(32,1);
dim3 grid((nx+block.x-1)/block.x,1);
__global__ void sumMatrixOnGPU1D(float *MatA, float *MatB, float *MatC,int nx, int ny) {
unsigned int ix = threadIdx.x + blockIdx.x * blockDim.x;
if (ix < nx ) {
for (int iy=0; iy③2D的grid和1D的block,每个thread处理一个数据。
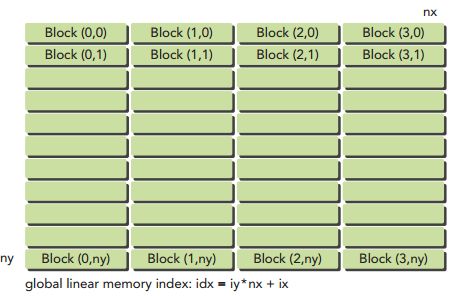
ix=threadIdx.x+blockIdx.x*blockDim.x;
iy=blockIdx.y;
__global__ void sumMatrixOnGPUMix(float *MatA, float *MatB, float *MatC,int nx, int ny)
{
unsigned int ix = threadIdx.x + blockIdx.x * blockDim.x;
unsigned int iy = blockIdx.y;
unsigned int idx = iy*nx + ix;
if (ix < nx && iy < ny)
MatC[idx] = MatA[idx] + MatB[idx];
}
查询GPU设备信息
➤ CUDA runtime API functions
cudaGetDeviceProperties(cudaDeviceProp*prop,int device);
➤ nvidia-smi