1. Glusterfs简介
GlusterFS是Scale-Out存储解决方案Gluster的核心,它是一个开源的分布式文件系统,具有强大的横向扩展能力,通过扩展能够支持数PB存储容量和处理数千客户端。GlusterFS借助TCP/IP或InfiniBandRDMA网络将物理分布的存储资源聚集在一起,使用单一全局命名空间来管理数据。GlusterFS基于可堆叠的用户空间设计,可为各种不同的数据负载提供优异的性能。
2. Glusterfs特点
2.1 扩展性和高性能
GlusterFS利用双重特性来提供几TB至数PB的高扩展存储解决方案。Scale-Out架构允许通过简单地增加资源来提高存储容量和性能,磁盘、计算和I/O资源都可以独立增加,支持10GbE和InfiniBand等高速网络互联。Gluster弹性哈希(ElasticHash)解除了GlusterFS对元数据服务器的需求,消除了单点故障和性能瓶颈,真正实现了并行化数据访问。
2.2 高可用性
GlusterFS可以对文件进行自动复制,如镜像或多次复制,从而确保数据总是可以访问,甚至是在硬件故障的情况下也能正常访问。自我修复功能能够把数据恢复到正确的状态,而且修复是以增量的方式在后台执行,几乎不会产生性能负载。GlusterFS没有设计自己的私有数据文件格式,而是采用操作系统中主流标准的磁盘文件系统(如EXT3、ZFS)来存储文件,因此数据可以使用各种标准工具进行复制和访问。
2.3全局统一命名空间
全局统一命名空间将磁盘和内存资源聚集成一个单一的虚拟存储池,对上层用户和应用屏蔽了底层的物理硬件。存储资源可以根据需要在虚拟存储池中进行弹性扩展,比如扩容或收缩。当存储虚拟机映像时,存储的虚拟映像文件没有数量限制,成千虚拟机均通过单一挂载点进行数据共享。虚拟机I/O可在命名空间内的所有服务器上自动进行负载均衡,消除了SAN环境中经常发生的访问热点和性能瓶颈问题。
2.4 弹性哈希算法
GlusterFS采用弹性哈希算法在存储池中定位数据,而不是采用集中式或分布式元数据服务器索引。在其他的Scale-Out存储系统中,元数据服务器通常会导致I/O性能瓶颈和单点故障问题。GlusterFS中,所有在Scale-Out存储配置中的存储系统都可以智能地定位任意数据分片,不需要查看索引或者向其他服务器查询。这种设计机制完全并行化了数据访问,实现了真正的线性性能扩展。
2.5 弹性卷管理
数据储存在逻辑卷中,逻辑卷可以从虚拟化的物理存储池进行独立逻辑划分而得到。存储服务器可以在线进行增加和移除,不会导致应用中断。逻辑卷可以在所有配置服务器中增长和缩减,可以在不同服务器迁移进行容量均衡,或者增加和移除系统,这些操作都可在线进行。文件系统配置更改也可以实时在线进行并应用,从而可以适应工作负载条件变化或在线性能调优。
2.6基于标准协议
Gluster存储服务支持NFS,CIFS, HTTP, FTP以及Gluster原生协议,完全与POSIX标准兼容。现有应用程序不需要作任何修改或使用专用API,就可以对Gluster中的数据进行访问。这在公有云环境中部署Gluster时非常有用,Gluster对云服务提供商专用API进行抽象,然后提供标准POSIX接口。
3、部署安装-服务器端(Centos7.2)
一、yum源安装:
1、先安装yum源,search支持的glusterfs的yum源,然后直接安装即可:#yum install -y centos-release-gluster38.noarch

2、安装glusterfs:#yum install glusterfs-server glusterfs -y
3、启动服务,并设置为开机自启:#systemctl enable glusterd.service && systemctl start glusterd.service
4、配置hosts文件,添加ip和服务名称的映射:#vim /etc/hosts
192.168.72.201 glusterfs1
192.168.72.202 glusterfs2
5、创建存储路径:#mkdir /data ----2个节点上都需要执行
6、将机器添加进集群:#gluster peer probe 192.168.72.202 ----随便哪台机器上执行都可以(此处是201上执行)
7、查看集群信息:#gluster peer status
8、创建分布式复制卷:#gluster volume create img replica 2 192.168.72.201:/data 192.168.72.202:/data
注:create后面跟的第一个参数ima是名字,第二个replica是卷类型,2是数量。
启动:#gluster volume start img
9、下载安装客户端软件:#yum install -y glusterfs
10、创建挂载点:#mkdir /mnt/data
11、挂载:#mount -t glusterfs 192.168.72.201:/img /mnt/data ----IP可以设置为上面任意一个IP
12、测试:#dd if=/dev/zore of=./test bs=1M count=100 # 在挂载客户端生成测试文件,#cp test /mnt/data
在存储节点上便可以看到此test文件了
注:2个节点系统会提示产生脑裂问题,至少需要3个节点,另外如果只有一块硬盘,直接使用根节点下面的当存储节点,在8创建分布式复制卷那里最后需要加上参数force才行,至此,部署完毕
二、编译安装
1、安装依赖:#yum install automake autoconf libtool flex bison openssl-devel libxml2-devel python-devel libaio-devel libibverbs-devel librdmacm-devel readline-devel lvm2-devel glib2-devel userspace-rcu-devel libcmocka-devel libacl-devel sqlite-devel fuse-devel redhat-rpm-config git
2、下载glusterfs:#git clone https://github.com/gluster/glusterfs.git
3、正式安装:#cd glusterfs
./autogen.sh
./configure --prefix=/usr/local/glusterfs
make
make install
4、创建启动文件:#vim /usr/lib/systemd/system/glusterd.service
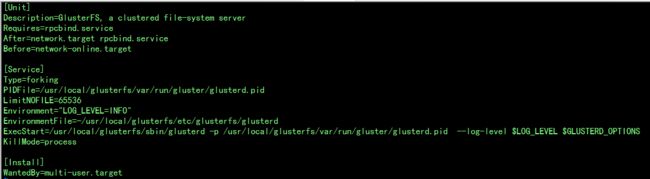
注:确保文件中的pidfile目录存在:#mkdir /usr/local/glusterfs/var/run/gluster -p
第二个文件:#vim /usr/lib/systemd/system/glusterfsd.service

5、启动服务并设置开机自启:
#systemctl daemon-reload && systemctl start glusterd.service && systemctl enable glusterd.service
其他设置同上!
其他补充:
一、常用命令
建立卷(Create Volume)
如果你打算使用gluster分布式存储,那么首要的步骤是建立卷。建立卷的模式有很多种,具体模式可以参见官方网站。我们这里来建立一个复制卷(类似raid1)。
1.将所有服务器加入存储池
gluster peer probe HOSTNAME
2.创建卷
gluster volume create NEWVOLNAME [stripe COUNT | replica COUNT] [transport [tcp | rdma | tcp,rdma]]NEWBRICK1 NEWBRICK2 NEWBRICK3...
3.启动卷
gluster volume start VOLNAME
删除卷(Delete Volume)
当然你也可以删除你创建的卷。
1.停止卷
gluster volume stop VOLNAME
2.删除卷
gluster volume delete VOLNAME
扩展卷(Expanding Volume)
你可能在使用gluster的过程中想在线扩展卷的大小,比如给分布式的卷中添加brick,以增加卷的容量。如果你的卷是分布式复制卷或者分布式条带卷,你新增的brick的数量必须是复制或者条带数目的倍数。比如你建立的卷replica为2,那么新增的brick的数量必须是2,4,6,8等。
1. 把新增的存储服务器加入存储池
gluster peer probe HOSTNAME
2. 把brick加入卷中
gluster volume add-brick VOLNAME NEWBRICK
3. 查看卷信息
gluster volume info
4. 重新平衡卷
gluster volume rebalance VOLNAME start | stop | status
缩小卷(Shrinking Volume)
你可能在使用gluster过程中想在线缩小卷的大小,比如当服务器故障或网络故障时,你想移除卷中相关的brick。同样需要注意的是如果你建立的是分布式复制卷或分布式条带卷,你删除的brick数量必须是复制或条带数目的倍数。
1. 把brick从卷中移除
gluster volume remove-brick VOLNAME BRICK
2. 查看卷信息
gluster volume info
3. 重新平衡卷
gluster volume rebalance VOLNAME start | stop | status
在线迁移数据(Migrating Data)
你可能想在线迁移一个brick中的数据到另一个brick中,首先确保相应存储服务器已加入存储池中。
1.迁移数据到另一个brick中
gluster volume replace-brick VOLNAME BRICK NEWBRICK start
2.查看迁移进度状态
gluster volume replace-brick VOLNAME BRICK NEWBRICK status
3.提交迁移数据
gluster volume replace-brick VOLNAME BRICK NEWBRICK commit
二、常见错误
1、[root@localhost ~]# gluster peer status
Connection failed. Please check if gluster daemon is operational.
原因:未开启glusterd服务
解决方法:开启glusterd服务#systemctl start glusterd
2、[root@localhost ~]# gluster peer probe 192.168.230.130
peer probe: failed: Probe returned with unknown errno 107
原因:防火墙没开启24007端口
解决方法:开启24007端口或者关掉防火墙
firewall-cmd --add-port=24007/tcp --zone=public --permanent
firewall-cmd --reload
三、Glusterfs调优
# 开启 指定 volume 的配额
$ gluster volume quota img enable
# 限制 指定 volume 的配额
$ gluster volume quota img limit-usage / 1TB
# 设置 cache 大小, 默认32MB
$ gluster volume set img performance.cache-size 4GB
# 设置 io 线程, 太大会导致进程崩溃
$ gluster volume set img performance.io-thread-count 16
# 设置 网络检测时间, 默认42s
$ gluster volume set img network.ping-timeout 10
# 设置 写缓冲区的大小, 默认1M
$ gluster volume set img performance.write-behind-window-size 1024MB