
这是菜鸟学Python的第75篇原创文章
阅读本文大概需要7分钟
Python常见的数据文件处理有5种,我们已经讲了3种:CSV 文件的处理近20年五粮液股价分析|CSV文件实战处理,JSON文件的处理GitHub上最火的开源项目是啥|JSON文件实战处理,XML的文件的处理如何用Python获取知乎头条精选| XML处理实战运用。还剩2个没有讲,一个是HTML文件,还有一个就是非常常见的excel文件,特别是在日常的工作中经常使用,所以我们很有必要学习一下,那么Python是如何处理excel呢,下面就来讲讲~~
因为有同学抱怨前面几讲,讲的太快了,内容不够细,所以我把excel分上两篇来讲今天这一篇是知识的梳理,下一篇是1000名儿童excel表的数据的分析.
而且把繁杂的知识点整理成脑图,方便大家查阅,是不是很贴心 哈哈
底部留言,获取本篇源码
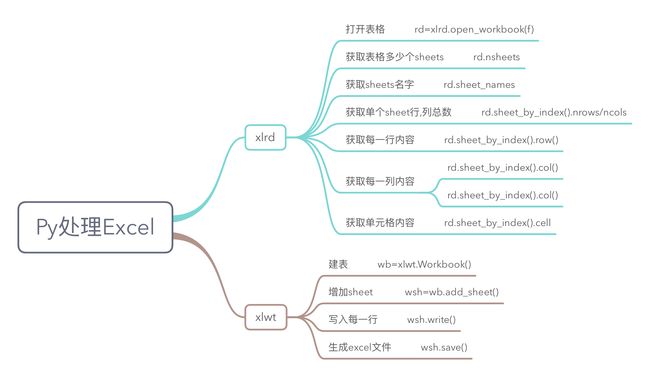
1.两大库xlrd,xlwt
1).Python操作excel主要用到xlrd和xlwt这两个库
即xlrd是读excel,xlwt是写excel的库,名字也蛮好记得,xl是excel的缩写,rd是read,wt是write.xlrd可以解析微软的.xls and .xlsx两种各种的电子表格
2).如何安装
用pip install xlrd就可以安装xlrd模块
用pip install xlwt就可以安装xlwt模块
如果小伙伴是用Pycharm的话更简单,直接打开File/Setting/Project/Project Interpreter,然后选择左边的绿色加号安装
2.如何读一个excel文件
比如有这样一个"user_data.xlsx"表格,第一个sheet叫"data",内容如下:
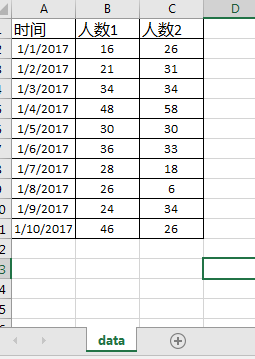
1).打开表格
file_name='user_data.xlsx'
excel_file=os.getcwd()+'\\'+file_name
rdata=xlrd.open_workbook(excel_file)
print type(rdata)
>>
我们用open_workbook这个函数打开一个excel文件,并返回一个rdata对象,有同学好奇这个rdata是啥,我们type一下
发现data是:xlrd这个模块下面的book文件下面的Book类的实例对象
有点拗口,但确实是这样的,不信可以看源码
2).获取表格的基本信息
print 'sheets nums:',rdata.nsheets#excel sheets 个数
>>
sheets nums: 1
3).每个sheets名字
print 'sheets names:',rdata.sheet_names()#excel sheets 每个名字
>>
sheets names: [u'data']
4).每个sheet的行列总数,比如第一个sheet
sheet1=rdata.sheet_by_index(0)
print 'rows:',sheet1.nrows
print 'clos',sheet1.ncols
>>rows=11,cols=3
5),获取行,列的对象
获取第一行的内容
sh1=rdata.sheet_by_index(0)
print sh1.row(0)
>>
[text:u'\u65f6\u95f4', text:u'\u4eba\u6570']
print sh1.row_values(1)
>>
[u'\u65f6\u95f4', u'\u4eba\u6570']
#返回的是列表对象,中文会转成的unicode显示
获取第二列的内容
print sh1.col(1)
>>
[text:u'\u4eba\u6570', number:16.0, number:21.0,
number:34.0, number:48.0, number:30.0, number:36.0,
number:28.0, number:26.0, number:24.0, number:46.0]
#返回的是列表对象,text表示是文本对象,number是数字
>>print sh1.col_values(1)
[u'\u4eba\u6570', 16.0, 21.0, 34.0, 48.0, 30.0,
36.0, 28.0, 26.0, 24.0, 46.0]
我们可以利用列表切片访问:第二列到第5列
>>print sh1.col_values(1)[1:5]
[16.0, 21.0, 34.0, 48.0]
也可以利用默认的col_values参数
col_values(self, colx, start_rowx=0, end_rowx=None)
print sh1.col_values(1,1,5)
>>
[16.0, 21.0, 34.0, 48.0]
6).获取单元格cell的内容
xlrd对excel里面内容分成下面7种的,是枚举类型
(
XL_CELL_EMPTY,
XL_CELL_TEXT,
XL_CELL_NUMBER,
XL_CELL_DATE,
XL_CELL_BOOLEAN,
XL_CELL_ERROR,
XL_CELL_BLANK, # for use in debugging, gathering stats, etc
) = range(7)
我们来看一下,第一行第一列的单元格是个字符串
sh1=rdata.sheet_by_index(0)
cell_0_0=sh1.cell(0,0)
print cell_0_0
print cell_0_0.ctype
print cell_0_0.value
>>
text:u'\u65f6\u95f4'
1
时间
#1确实对应的是文本
我们来看一下,第二行第一列的单元格:日期
cell_1_0=sh1.cell(1,0)
print cell_1_0
print cell_1_0.ctype
print cell_1_0.value
>>
xldate:42736.0
3
42736.0
#3确实对应的是日期 (有小伙伴问日期怎么变成这个数字,
#因为日期被转换成了xldate对象,一会我们会转换回来,后面会详细讲)
我们来看一下,第二行第二列的单元格:数字
cell_1_1=sh1.cell(1,1)
print cell_1_1
print cell_1_1.ctype
>>
number:16.0
2
16.0
#2确实对应的是日期 (有小伙伴问日期怎么变成这个数字,不急后面会讲)
3.如何写数据进表格
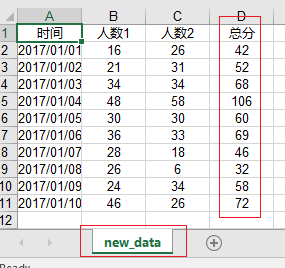
主要是用xlwt模块,现在我们要把上面的'data.xlsx'表格中人数1和人数2相加等于总数列,并写入到一个新的excel文件中去.
1).读取'data.xlsx'中sheet1的数据
import xlrd
import os
file_name='data.xlsx'
excel_file=os.getcwd()+'\\'+file_name
rdata=xlrd.open_workbook(excel_file)
sh1=rdata.sheet_by_index(0)
2).创建一个wbook对象,生成一个新的sheet
import xlwt
wbook=xlwt.Workbook()
wsheet=wbook.add_sheet(sh1.name)
3).在写入第一行,标题栏
wsheet这个函数(row,col,value,style),这个style其实就是这个内容单元格的格式
style=xlwt.easyxf('align: vertical center, horizontal center')
wsheet.write(0,0,u'时间',style)
wsheet.write(0,1,u'人数1',style)
wsheet.write(0,2,u'人数2',style)
wsheet.write(0,3,u'总分',style)
4).写入时间列的数据,需要转化数据格式
上面读表格的时候,我们遗留了一个问题,就是第一列的日期
为啥打印出来,会变成奇怪的数据
其实那个是xldate对象,我们需要把sheet1里面的内容提取处理,然后转成日期数
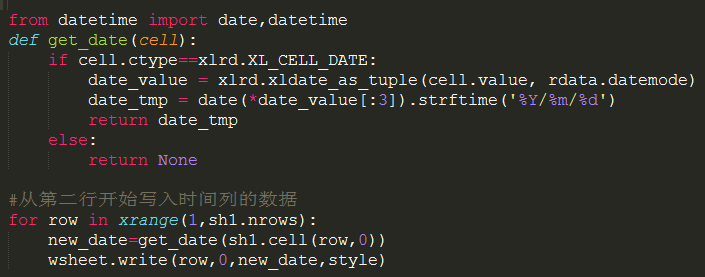
5).计算第二列和第三列的数据,得到总分

6).把sheet1里面的第二列,第三列和总分的数据写入excel文件

7).写成文件new_data.xls
try:
wbook.save('new_data.xls')
except Exception as e:
print e
else:
print 'write excel file successful
运行一下,打开新的表格new_data.xls
更多精彩内容,源码分享,请关于微信公众号"菜鸟学python"