e> Hadoop大数据平台架构与实践--基础篇
目录
内容概要
Hadoop前生
Hadoop的功能与优势
Hadoop的生态系统和版本
Hadoop安装
内容概要
1、大数据技术的相关概念
2、Hadoop的架构和运行机制
3、Hadoop的安装和配置
4、Hadoop开发
Hadoop前生
大数据的存储和分析,出现系统瓶颈:存储容量、读写速度、计算效率...
Google提出了大数据技术:MapReduce、BigTable、GFS(Google File System)
(1)成本降低,不一定非得用大型机和高端存储,也可使用PC机
(2)由软件 容错 硬件故障,通过软件保证可靠性
(3)简化并行分布式计算,无需控制节点同步和数据交换,MapReduce:简化分布式计算
Google只发表了相关论文,没有公开源码;Hadoop是模仿Google大数据技术的开源实现。
Hadoop的功能与优势
开源的分布式存储、分布式计算平台
用来支撑Hadoop的两个核心:
HDFS:分布式文件系统,存储海量数据
MapReduce:并行处理框架,实现任务分解和调度;分布式数据处理模型和执行环境
Hadoop的功能:
(1)搭建大型数据仓库,PB级数据的存储、处理、分析、统计等业务:搜索引擎、商业智能、日志分析、风险评估等
Hadoop的优势:
(1)高扩展:增加硬件提升容量和性能
(2)低成本:不依赖于高端硬件、通过软件容错保证系统可靠性
(3)成熟的生态圈:工具集
- 运行方便:Hadoop是运行在由一般商用机器构成的大型集群上。Hadoop在云计算服务层次中属于PaaS(Platform-as-a- Service):平台即服务。
- 健壮性:Hadoop致力于在一般的商用硬件上运行,能够从容的处理类似硬件失效这类的故障。
- 可扩展性:Hadoop通过增加集群节点,可以线性地扩展以处理更大的数据集。
- 简单:Hadoop允许用户快速编写高效的并行代码。
Hadoop的生态系统和版本
Hadoop生态系统
HDFS(分布式文件系统)
MapReduce(分布式计算框架)
Hive(基于MapReduce的数据仓库)
Pig(数据仓库)
HBase(分布式数据库)
Mahout(数据挖掘库)
Zookeeper(分布式协作服务)
Sqoop(数据同步工具)
Flume(日志收集工具)
Oozie(作业流调度系统)
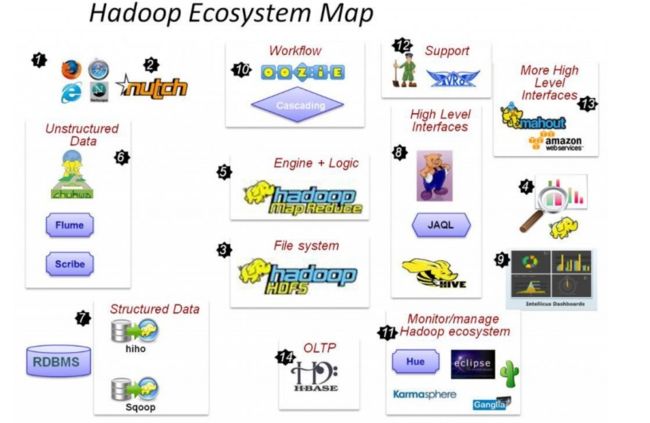
其中:
2)Nutch:互联网数据及Nutch搜索引擎应用
3)HDFS:Hadoop的分布式文件系统
5)MapReduce:分布式计算框架
6)Flume、Scribe,Chukwa:数据收集,收集非结构化数据的工具
7) Hiho、Sqoop:将关系数据库中的数据导入HDFS的工具
8) Hive:数据仓库,pig分析数据的工具
10)Oozie:作业流调度引擎
11)Hue:Hadoop自己的监控管理工具
12)Avro:数据序列化工具
13)mahout:数据挖掘工具
14)Hbase:分布式的面向列的开源数据库
Hadoop2.0时代的生态系统

Hadoop的核心
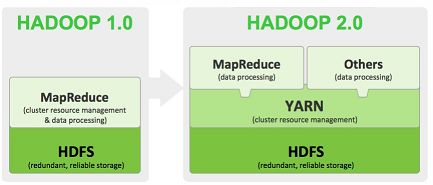
Hadoop1.0与Hadoop2.0的区别:
Hadoop1.0的核心由HDFS(Hadoop Distributed File System)和MapReduce(分布式计算框架)构成,而在Hadoop2.0中增加了Yarn(Yet Another Resource Negotiator),来负责集群资源的统一管理和调度。
HDFS(Hadoop Distributed File System,分布式文件系统)
HDFS简单入门
为什么需要HDFS呢?HDFS是一个file system,对文件进行管理。文件系统由三部分组成:与文件管理有关软件、被管理文件以及实施文件管理所需数据结构。
文件的读取和写入都需要时间,而且写文件需要更多的时间,大概是读文件的3倍;当数据集(文件)的大小超过一台独立物理计算机的存储能力时,就有必要对它进行分区并存储到若干台单独的计算机上——分布式文件存储。

** HDFS的基本原理**
- 将文件切分成等大的数据块,存储在多台机器上;
- 将数据切分、容错、负载均衡等功能透明化;
- 可将HDFS看成容量巨大、具有高容错性的磁盘
** HDFS的特点 **
- 良好的扩展性
- 高容错性
- 适合PB级以上海量数据的存储
HDFS的应用场景
- 海量数据的可靠性存储
- 数据归档
MapReduce(分布式计算框架)
Mapreduce是一个计算框架,既然是做计算的框架,那么表现形式就是有个输入(input),mapreduce操作这个输入(input),通过本身定义好的计算模型,得到一个输出(output),这个输出就是我们所需要的结果。
我们要学习的就是这个计算模型的运行规则。在运行一个mapreduce计算任务时候,任务过程被分为两个阶段:map阶段和reduce阶段,每个阶段都是用键值对(key/value)作为输入(input)和输出(output)。而程序员要做的就是定义好这两个阶段的函数:map函数和reduce函数。
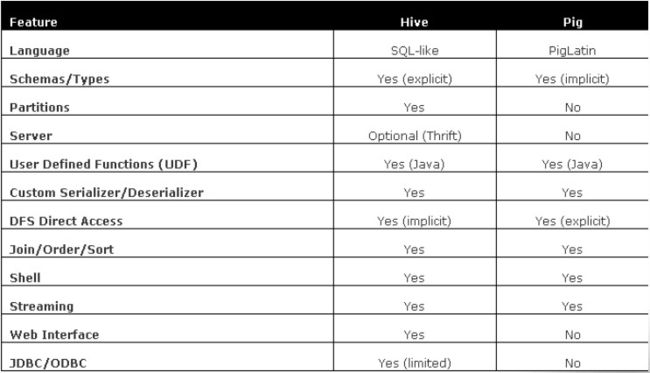
Hive(基于MapReduce的数据仓库)
Hive由facebook开源,最初用于解决海量结构化的日志数据统计问题;是一种ETL(Extraction-Transformation-Loading)工具。它也是构建在Hadoop之上的数据仓库;数据计算使用MR,数据存储使用HDFS。
Hive定义了一种类似SQL查询语言的HiveQL查询语言,除了不支持更新、索引和事务,几乎SQL的其他特征都能支持。它通常用于离线数据处理(采用MapReduce);我们可以认为Hive的HiveQL语言是MapReduce语言的翻译器,把MapReduce程序简化为HiveQL语言。但有些复杂的MapReduce程序是无法用HiveQL来描述的。
Hive提供shell、JDBC/ODBC、Thrift、Web等接口。
Hive应用场景
- 日志分析:统计一个网站一个时间段内的pv、uv ;比如百度、淘宝等互联网公司使用hive进行日志分析
- 多维度数据分析
- 海量结构化数据离线分析
- 低成本进行数据分析(不直接编写MR)
Pig(数据仓库)
Pig由yahoo!开源,设计动机是提供一种基于MapReduce的ad-hoc数据分析工具。它通常用于进行离线分析。
Pig是构建在Hadoop之上的数据仓库,定义了一种类似于SQL的数据流语言–Pig Latin,Pig Latin可以完成排序、过滤、求和、关联等操作,可以支持自定义函数。Pig自动把Pig Latin映射为MapReduce作业,上传到集群运行,减少用户编写Java程序的苦恼。
Pig有三种运行方式:Grunt shell、脚本方式、嵌入式。
HBase(分布式数据库)
Hbase原理、基本概念、基本架构
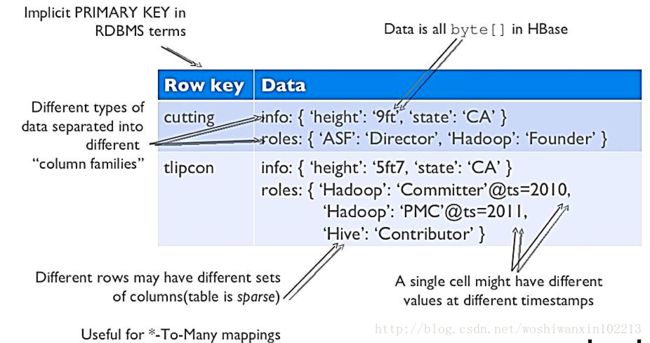
HBase是一个构建在HDFS上的分布式列存储系统,基于Google的Big Table模型开发,是典型的key/value系统,主要用于海量结构化数据存储,它是NoSQL的典型代表产品。
从逻辑上讲,HBase将数据按照表、行和列进行存储。与hadoop一样,Hbase目标主要依靠横向扩展,通过不断增加廉价的商用服务器,来增加计算和存储能力。
Hbase表的特点
- 大:一个表可以有数十亿行,上百万列;
- 无模式:每行都有一个可排序的主键和任意多的列,列可以根据需要动态的增加,同一张表中- 不同的行可以有截然不同的列;
- 面向列:面向列(族)的存储和权限控制,列(族)独立检索;
- 稀疏:空(null)列并不占用存储空间,表可以设计的非常稀疏;
- 数据多版本:每个单元中的数据可以有多个版本,默认情况下版本号自动分配,是单元格插入时的时间戳;
- 数据类型单一:Hbase中的数据都是字符串,没有类型。
Hbase使用场景
- 大数据量存储、高并发操作
- 需要对数据随机读写操作
- 读写访问都是非常简单的操作
Mahout(数据挖掘库)
Mahout是基于MapReduce的数据挖掘 / 机器学习库,充分利用了MapReduce和HDFS的扩展性和容错性,实现了聚类算法、分类算法和推荐算法

Zookeeper(分布式协作服务)
ZooKeeper 是一个分布式的,开源的协作服务,可应用于分布式应用程序。它发布了一组简单的原子操作,分布式应用程序在此基础之上可以实现更高层次的服务,如同步、配置维护、群组和命名管理 等。它为易于编程而设计,并且使用了一个类似于文件系统的目录结构风格的数据模型。ZooKeeper service运行于Java环境中,也可绑定于Java和C.
ZooKeeper 是一个用于对分布式系统进行协作管理的服务程序,它本身也是分布式的,所以不要弄混了。对于我们自己的分布式系统来说,ZooKeeper就是一个用来管理的应用程序(或者说服务)。ZooKeeper提供了一个简单易用的框架,由Service和Client两大部分组成。
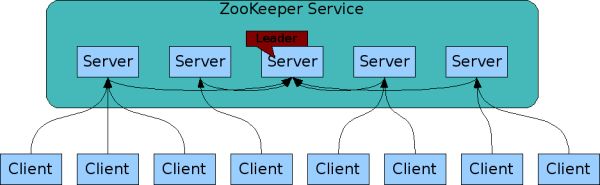
Service:由若干运行的Server组成(1个或多个),这些Server完全相同(除了可以部署在不同的机器上),每个Server都维护着相同的数据结构(类似于文件目录结构),这个树形结构中的节点叫znode,Server之间会自动同步数据。
Client:可以连接到Service,每个Client对象可以连接到一个指定(或自动分配)的Server,用户通过client可以在Server中创建并维护数据。因为不同的Server维护的是同一份数据的复制,所以,不同的client使用者之间,通过ZooKeeper Service,就可以达到共享数据(信息)的目的。
ZooKeeper还提供了Watch的功能,当一个client改变了znode中的数据,所有的client都可以得到通知。ZooKeeper提供了Java和C语言的客户端。
对于ZooKeeper的使用者来说,只需要运行Service,并且知道client的操作方法就可以了。在我们自己的分布式系统中,每个节点通过创建ZooKeeper client,就可以利用ZooKeeper service来同步,共享数据,或者实现更复杂的功能了。
Zookeeper解决分布式环境下数据管理问题:
- 统一命名
- 状态同步
- 集群管理
- 配置同步
Sqoop(数据同步工具)
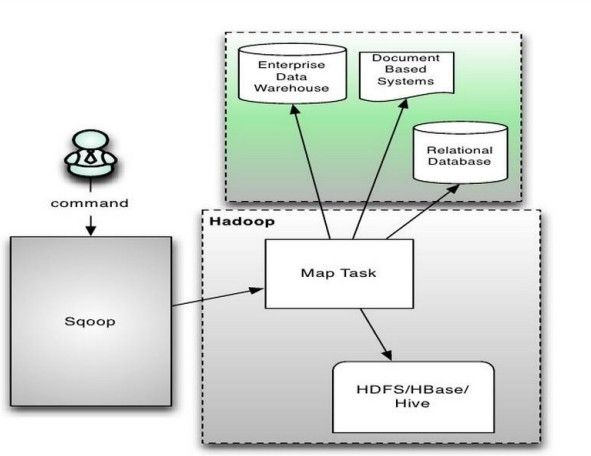
Sqoop是连接Hadoop与传统数据库之间的桥梁,它支持多种数据库,包括MySQL、DB2等;插拔式,用户可以根据需要支持新的数据库。
Sqoop实质上是一个MapReduce程序,充分利用MR并行的特点,充分利用MR的容错性。
Flume(日志收集工具)
Flume是一个分布式、可靠、和高可用的海量日志聚合的系统,支持在系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
**Fulme 的特点: **
1、可靠性
当节点出现故障时,日志能够被传送到其他节点上而不会丢失。Flume提供了三种级别的可靠性保障,从强到弱依次分别为:end-to-end(收到数据agent首先将event写到磁盘上,当数据传送成功后,再删除;如果数据发送失败,可以重新发送。),Store on failure(这也是scribe采用的策略,当数据接收方crash时,将数据写到本地,待恢复后,继续发送),Best effort(数据发送到接收方后,不会进行确认)。2、可扩展性
Flume采用了三层架构,分别为agent,collector和storage,每一层均可以水平扩展。其中,所有agent和collector由master统一管理,这使得系统容易监控和维护,且master允许有多个(使用ZooKeeper进行管理和负载均衡),这就避免了单点故障问题。3、可管理性
所有agent和colletor由master统一管理,这使得系统便于维护。多master情况,Flume利用ZooKeeper和gossip,保证动态配置数据的一致性。用户可以在master上查看各个数据源或者数据流执行情况,且可以对各个数据源配置和动态加载。Flume提供了web 和shell script command两种形式对数据流进行管理。4、功能可扩展性
用户可以根据需要添加自己的agent,collector或者storage。此外,Flume自带了很多组件,包括各种agent(file, syslog等),collector和storage(file,HDFS等)。
Oozie(作业流调度系统)
目前计算框架和作业类型种类繁多:如MapReduce、Stream、HQL、Pig等。这些作业之间存在依赖关系,周期性作业,定时执行的作业,作业执行状态监控与报警等。如何对这些框架和作业进行统一管理和调度?
解决方案有多种:
- Linux Crontab
- 自己设计调度系统(淘宝等公司)
- 直接使用开源系统(Oozie)
Oozie
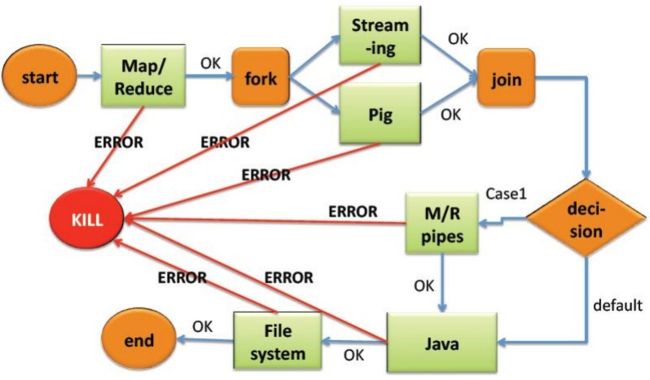
- Oozie是一个管理Hdoop作业(job)的工作流程调度管理系统。
- Oozie的工作流是一系列动作的直接周期图。
- Oozie协调作业就是通过时间(频率)和有效数据触发当前的Oozie工作流程
- Oozie是Yahoo针对Apache Hadoop开发的一个开源工作流引擎。
- 用于管理和协调运行在Hadoop平台上(包括:HDFS、Pig和MapReduce)的Jobs。Oozie是专为雅虎的全球大规模复杂工作流程和数据管道而设计。
- Oozie围绕着两个核心进行:工作流(Workflow)和协调器(Coordinator),前者定义任务拓扑和执行逻辑,后者负责工作流的依赖和触发。
Hadoop发行版(开源版)介绍
推荐使用2.x.x版本
下载地址:http://hadoop.apache.org/releases.html
Hadoop安装
参考:
安装并运行hadoop
SSH免密码登录以及失败解决方案
配置(伪分布式的配置)
Hadoop-2.5.1集群安装配置笔记
修改1个环境变量文件
- hadoop-env.sh
记录脚本要用的环境变量,以运行hadoop
export JAVA_HOME=/usr/Java/jdk1.7.0_51(设置java环境变量),即jdk的安装目录
修改3个配置文件
core-site.xml
hadoop core的配置项,例如hdfs和mapreduce常用的i/o设置等hdfs-site.xml
hadoop守护进程的配置项,包括namenode、辅助namenode和datanode等mapred-site.xml
MapReduce守护进程的配置项,包括jobtracker和tasktracker
遇到的坑
在ubuntu中配置SSH(解决connect to host localhost port 22: Connection refused问题)
为什么要安装SSH?因为在Hadoop启动以后,namenode是通过SSH(Secure Shell)来启动和停止各个节点上的各种守护进程的。
Ubuntu默认并没有安装ssh服务,如果通过ssh链接Ubuntu,需要自己手动安装openssh-server。判断是否安装ssh服务,可以通过如下命令进行:
ssh localhost
在这之前要开启 ssh-agent:
$ eval ssh-agent
添加私钥:
$ ssh-add ~/.ssh/id_rsa
告诉ssh允许 ssh-agent 转发:
# 修改全局:
$ echo "ForwardAgent yes" >> /etc/ssh/ssh_config
启动ssh service:
/etc/init.d/ssh start
启动
[root@HostName sbin]# ./start-dfs.sh
[root@HostName sbin]# ./start-yarn.sh
停止
[root@HostName sbin]# ./stop-dfs.sh
[root@HostName sbin]# ./stop-yarn.sh
验证hadoop是否安装成功
http://localhost:50030/ (MapReduce的web页面)
http://localhost:50070/ (HDFS的web页面)
跑个wordcount程序验证一下:
# 建一个input目录,作为输入
$mkdir input
$cd input
# 新建两个文本文件
$echo "hello world">test1.txt
$echo "hello hadoop">test2.txt
$cd ..
# 将input文件上传到HDFS,并重命名为in
$bin/hadoop dfs -put input in
# 调用yarn jar启动YARN applications(Use yarn jar to launch YARN applications instead.)
$bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /in/input out
# 查看分析结果
$bin/hdfs dfs -cat /user/root/out/*
输出:
