前言:本篇是TextCNN系列的第二篇,分享TextCNN的代码
前两篇可见:
文本分类算法TextCNN原理详解(一)
一、textCNN 整体框架
1. 模型架构
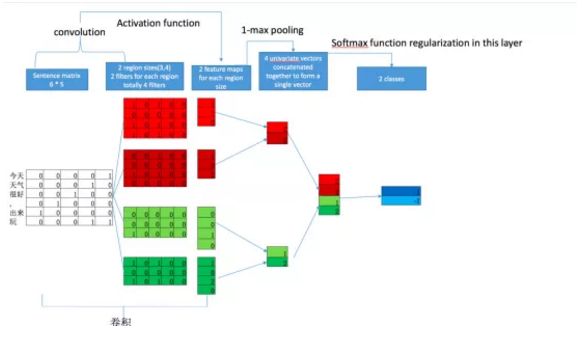
图一:textCNN 模型结构示意
2. 代码架构
 图二: 代码架构说明
图二: 代码架构说明
-
text_cnn.py 定义了textCNN 模型网络结构
-
model.py 定义了训练代码
-
data.py 定义了数据预处理操作
-
data_set 存放了测试数据集合. polarity.neg 是负面情感文本, polarity.pos 是正面情感文本
-
train-eval.sh 执行脚本
3.代码地址
项目地址
部分代码参考了 此处代码
4.训练效果说明:
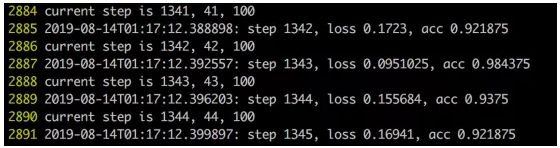
图三:训练效果展示
二、textCNN model 代码介绍
2.1 wordEmbedding
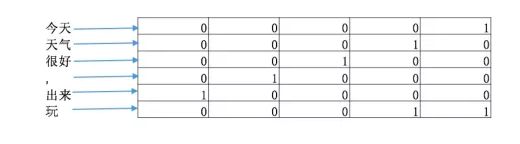
图四:WordEmbedding 例子说明
简要说明:
vocab_size: 词典大小18758
embedding_dim: 词向量大小 为128
seq_length: 句子长度,设定最长为56
embedding_look: 查表操作 根据每个词的位置id 去初始化的w中寻找对应id的向量. 得到一个tensor :[batch_size, seq_length, embedding_size] 既 [?, 56, 128], 此处? 表示batch, 即不知道会有多少输入。
# embedding layer with tf.name_scope("embedding"): self.W = tf.Variable(tf.random_uniform([self._config.vocab_size, self._config.embedding_dim], -1.0, 1.0), name="W") self.char_emb = tf.nn.embedding_lookup(self.W, self.input_x) self.char_emb_expanded = tf.expand_dims(self.char_emb, -1) tf.logging.info("Shape of embedding_chars:{}".format(str(self.char_emb_expanded.shape)))
举例说明:我们有一个词典大小为3的词典,一共对应三个词 “今天”,“天气” “很好“,w =[[0,0,0,1],[0,0,1,0],[0,1,0,0]]。
我们有两个句子,”今天天气“,经过预处理后输入是[0,1]. 经过embedding_lookup 后,根据0 去查找 w 中第一个位置的向量[0,0,0,1], 根据1去查找 w 中第二个位置的向量[0,0,1,0] 得到我们的char_emb [[0,0,0,1],[0,0,1,0]]
同理,“天气很好”,预处理后是[1,2]. 经过经过embedding_lookup 后, 得到 char_emb 为[[0,0,1,0],[0,1,0,0]]
因为, 卷积神经网conv2d是需要接受四维向量的,故将char_embdding 增广一维,从 [?, 56, 128] 增广到[?, 56, 128, 1]
2.2 Convolution 卷积 + Max-Pooling
 图五:卷积例子说明
图五:卷积例子说明
简要说明:
filter_size= 3,4,5. 每个filter 的宽度与词向量等宽,这样只能进行一维滑动。
每一种filter卷积后,结果输出为[batch_size, seq_length - filter_size +1,1,num_filter]的tensor。
# convolution + pooling layer pooled_outputs = [] for i, filter_size in enumerate(self._config.filter_sizes): with tf.variable_scope("conv-maxpool-%s" % filter_size): # convolution layer filter_width = self._config.embedding_dim input_channel_num = 1 output_channel_num = self._config.num_filters filter_shape = [filter_size, filter_width, input_channel_num, output_channel_num] n = filter_size * filter_width * input_channel_num kernal = tf.get_variable(name="kernal", shape=filter_shape, dtype=tf.float32, initializer=tf.random_normal_initializer(stddev=np.sqrt(2.0 / n))) bias = tf.get_variable(name="bias", shape=[output_channel_num], dtype=tf.float32, initializer=tf.zeros_initializer) # apply convolution process # conv shape: [batch_size, max_seq_len - filter_size + 1, 1, output_channel_num] conv = tf.nn.conv2d( input=self.char_emb_expanded, filter=kernal, strides=[1, 1, 1, 1], padding="VALID", name="cov") tf.logging.info("Shape of Conv:{}".format(str(conv.shape))) # apply non-linerity h = tf.nn.relu(tf.nn.bias_add(conv, bias), name="relu") tf.logging.info("Shape of h:{}".format(str(h))) # Maxpooling over the outputs pooled = tf.nn.max_pool( value=h, ksize=[1, self._config.max_seq_length - filter_size + 1, 1, 1], strides=[1, 1, 1, 1], padding="VALID", name="pool" ) tf.logging.info("Shape of pooled:{}".format(str(pooled.shape))) pooled_outputs.append(pooled) tf.logging.info("Shape of pooled_outputs:{}".format(str(np.array(pooled_outputs).shape))) # concatenate all filter's output total_filter_num = self._config.num_filters * len(self._config.filter_sizes) all_features = tf.reshape(tf.concat(pooled_outputs, axis=-1), [-1, total_filter_num]) tf.logging.info("Shape of all_features:{}".format(str(all_features.shape)))
由于我们有三种filter_size, 故会得到三种tensor
第一种 tensor, filter_size 为 3处理后的,[?,56-3+1,1, 128] -> [?,54,1, 128]
第二种 tensor, filter_size 为 4处理后的,[?,56-4+1,1, 128] -> [?,53,1, 128]
第三种 tensor, filter_size 为 5处理后的,[?,56-5+1,1, 128] -> [?,52,1, 128]
再用ksize=[?,seq_length - filter_size + 1,1,1]进行max_pooling,得到[?,1,1,num_filter]这样的tensor. 经过max_pooling 后
第一种 tensor, [?,54,1, 128] –> [?,1,1, 128]
第二种 tensor, [?,53,1, 128] -> [?,1,1, 128]
第三种 tensor, [?,52,1, 128] -> [?,1,1, 128]
将得到的三种结果进行组合,得到[?,1,1,num_filter*3]的tensor.最后将结果变形一下[-1,num_filter*3],目的是为了下面的全连接
[?,1,1, 128], [?,1,1, 128], [?,1,1, 128] –> [?, 384]
2.3 使用softmax k分类
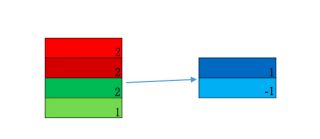
图六:softmax 示意
简要说明:
label_size 为 文本分类类别数目,这里是二分类,然后得到输出的结果scores,以及得到预测类别在标签词典中对应的数值predicitons。使用交叉墒求loss.
with tf.name_scope("output"): W = tf.get_variable( name="W", shape=[total_filter_num, self._config.label_size], initializer=tf.contrib.layers.xavier_initializer()) b = tf.Variable(tf.constant(0.1, shape=[self._config.label_size]), name="b") l2_loss += tf.nn.l2_loss(W) l2_loss += tf.nn.l2_loss(b) self.scores = tf.nn.xw_plus_b(all_features, W, b, name="scores") self.predictions = tf.argmax(self.scores, 1, name="predictions") # compute loss with tf.name_scope("loss"): losses = tf.nn.softmax_cross_entropy_with_logits(logits=self.scores, labels=self.input_y) self.loss = tf.reduce_mean(losses) + self._config.l2_reg_lambda * l2_loss
三、 textCNN 训练模块
简要说明:利用数据预处理模块加载数据,优化函数选择adam, 每个batch为64. 进行处理
def train(x_train, y_train, vocab_processor, x_dev, y_dev, model_config): with tf.Graph().as_default(): sess = tf.Session() with sess.as_default(): cnn = TextCNNModel( config=model_config, is_training=FLAGS.is_train ) # Define Training proceduce global_step = tf.Variable(0, name="global_step", trainable=False) optimizer = tf.train.AdamOptimizer(1e-3) grads_and_vars = optimizer.compute_gradients(cnn.loss) train_op = optimizer.apply_gradients(grads_and_vars, global_step=global_step) # Checkpoint directory, Tensorflow assumes this directioon already exists so we need to create it checkpoint_dir = os.path.abspath(os.path.join(FLAGS.output_dir, "checkpoints")) checkpoint_prefix = os.path.join(checkpoint_dir, "model") if not os.path.exists(checkpoint_dir): os.makedirs(checkpoint_dir) saver = tf.train.Saver(tf.global_variables(), max_to_keep=FLAGS.keep_checkpoint_max) # Write vocabulary vocab_processor.save(os.path.join(FLAGS.output_dir, "vocab")) # Initialize all variables sess.run(tf.global_variables_initializer()) def train_step(x_batch, y_batch): """ A singel training step :param x_batch: :param y_batch: :return: """ feed_dict = { cnn.input_x: x_batch, cnn.input_y: y_batch } _, step, loss, accuracy = sess.run( [train_op, global_step, cnn.loss, cnn.accuracy], feed_dict) time_str = datetime.datetime.now().isoformat() tf.logging.info("{}: step {}, loss {:g}, acc {:g}".format(time_str, step, loss, accuracy)) def dev_step(x_batch, y_batch, writer=None): """ Evaluates model on a dev set """ feed_dict = { cnn.input_x: x_batch, cnn.input_y: y_batch } step, loss, accuracy = sess.run( [global_step, cnn.loss, cnn.accuracy], feed_dict) time_str = datetime.datetime.now().isoformat() tf.logging.info("{}: step {}, loss {:g}, acc {:g}".format(time_str, step, loss, accuracy)) # Generate batches batches = data.DataSet.batch_iter(list(zip(x_train, y_train)), FLAGS.batch_size, FLAGS.num_epochs) # Training loop, For each batch .. for batch in batches: x_batch, y_batch = zip(*batch) train_step(x_batch, y_batch) current_step = tf.train.global_step(sess, global_step) if current_step % FLAGS.save_checkpoints_steps == 0: tf.logging.info("\nEvaluation:") dev_step(x_dev, y_dev) if current_step % FLAGS.save_checkpoints_steps == 0: path = saver.save(sess, checkpoint_prefix, global_step=current_step) tf.logging.info("Saved model checkpoint to {}\n".format(path))
四、textCNN 数据预处理
简要说明:处理输入数据
class DataSet(object): def __init__(self, positive_data_file, negative_data_file): self.x_text, self.y = self.load_data_and_labels(positive_data_file, negative_data_file) def load_data_and_labels(self, positive_data_file, negative_data_file): # load data from files positive_data = list(open(positive_data_file, "r", encoding='utf-8').readlines()) positive_data = [s.strip() for s in positive_data] negative_data = list(open(negative_data_file, "r", encoding='utf-8').readlines()) negative_data = [s.strip() for s in negative_data] # split by words x_text = positive_data + negative_data x_text = [self.clean_str(sent) for sent in x_text] # generate labels positive_labels = [[0, 1] for _ in positive_data] negative_labels = [[1, 0] for _ in negative_data] y = np.concatenate([positive_labels, negative_labels], 0) return [x_text, y] def clean_str(self, string): """ Tokenization/string cleaning for all datasets except for SST. Original taken from https://github.com/yoonkim/CNN_sentence/blob/master/process_data.py """ string = re.sub(r"[^A-Za-z0-9(),!?\'\`]", " ", string) string = re.sub(r"\'s", " \'s", string) string = re.sub(r"\'ve", " \'ve", string) string = re.sub(r"n\'t", " n\'t", string) string = re.sub(r"\'re", " \'re", string) string = re.sub(r"\'d", " \'d", string) string = re.sub(r"\'ll", " \'ll", string) string = re.sub(r",", " , ", string) string = re.sub(r"!", " ! ", string) string = re.sub(r"\(", " \( ", string) string = re.sub(r"\)", " \) ", string) string = re.sub(r"\?", " \? ", string) string = re.sub(r"\s{2,}", " ", string) return string.strip().lower() def batch_iter(data, batch_size, num_epochs, shuffle=True): """ Generates a batch iterator for a dataset. """ data = np.array(data) data_size = len(data) num_batches_per_epoch = int((len(data) - 1) / batch_size) + 1 for epoch in range(num_epochs): # Shuffle the data at each epoch if shuffle: shuffle_indices = np.random.permutation(np.arange(data_size)) shuffled_data = data[shuffle_indices] else: shuffled_data = data for batch_num in range(num_batches_per_epoch): start_index = batch_num * batch_size end_index = min((batch_num + 1) * batch_size, data_size) yield shuffled_data[start_index:end_index]
五、模型训练
简要说明:修改code_dir , 执行train-eval.sh 即可执行
#!/bin/bash export CUDA_VISIBLE_DEVICES=0 #如果运行的话,更改code_dir目录 CODE_DIR="/home/work/work/modifyAI/textCNN" MODEL_DIR=$CODE_DIR/model TRAIN_DATA_DIR=$CODE_DIR/data_set nohup python3 $CODE_DIR/model.py \ --is_train=true \ --num_epochs=200 \ --save_checkpoints_steps=100 \ --keep_checkpoint_max=50 \ --batch_size=64 \ --positive_data_file=$TRAIN_DATA_DIR/polarity.pos \ --negative_data_file=$TRAIN_DATA_DIR/polarity.neg \ --model_dir=$MODEL_DIR > $CODE_DIR/train_log.txt 2>&1 &
六、总结
-
介绍了textCNN基本架构,代码架构,项目地址,训练效果
-
详细说明textCNN 用tensorflow如何实现
-
介绍了textCNN 模型训练代码以及数据预处理模块
-
详细说明如何运行该项目
-
下一次会介绍如何调优textCNN 模型