本文有一定的深度,如果有看不懂,或者费解,可以私信我或者留言,我会一一解答
正文
本文有三篇文章
1:让任何对象都处于安全线程
2:灵活使用std::shared_mutex让响应速度快10倍
3:线程安全的std :: map与无锁映射的速度最大化
介绍
在这三篇文章中,我将详细介绍原理操作,内存障碍和线程之间数据的快速交换,以及“sequence-points”示例中的“execute-around-idiom”。同时,我们将尝试一起做一些有用的事情。
标准C ++库中没有线程安全的容器(数组,列表,映射...),可以在多个线程中使用它们而无需附加锁。在使用标准容器进行多线程交换的情况下,可能会忘记使用互斥锁保护其中一个代码段,或者错误地使用另一个互斥锁来保护它。
显然,如果开发人员使用自己的解决方案而不是标准的解决方案,则会犯更多的错误。而且,如果任务很复杂,以至于没有任何标准解决方案,那么开发人员在尝试寻找解决方案时将充满错误。
依靠“实践大于理论”的原则,我们将努力创造出一个解决这个问题的最佳方法,而不是纸上谈兵。
在本文中,我们将实现使所有对象成为线程安全对象的智能指针,其性能与优化的无锁容器相同。
使用此类指针的简化,非优化示例:
1 int main() { 2 contfree_safe_ptr< std::map< std::string, int > > safe_map_string_int; 3 4 std::thread t1([&]() { safe_map_string_int->emplace("apple", 1); }); 5 std::thread t2([&]() { safe_map_string_int->emplace("potato", 2); }); 6 t1.join(); t2.join(); 7 8 std::cout << "apple = " << (*safe_map_string_int)["apple"] << 9 ", potato = " << (*safe_map_string_int)["potato"] << std::endl; 10 return 0; 11 }
我们将引用标准的线程,以保证算法每一步的必要行为。
我们将详细考虑C ++内存模型以及线程之间的同步和数据交换的不同版本。
在本文中,我们将开发一个线程安全的指针safe_ptr<>。在第二篇文章中,我们将实现优化的“无争用共享互斥体”和contfree_safe_ptr<>基于其的优化指针。在第三篇文章中,我们将展示最佳利用示例contfree_safe_ptr<>并提供性能测试,并将其与高度优化的无锁容器进行比较。
背景
我们将从开发一个safe_ptr智能指针模板开始,该模板对于任何类型的T都是线程安全的,并且将在优化的无锁算法级别上显示多线程性能。
此外,这将使我们能够同时与几个不同的对象,同步工作,其中甚至对于无锁的数据结构,也将不得不使用锁,并且会出现永久死锁的风险。但是,我们将开发一个特殊的互斥锁类来解决死锁的情况。然后,我们将实现自己的高性能无争用共享互斥体,它比标准速度快得多std::shared_mutex。并且,在此基础上,我们将创建安全指针的优化版本safe_ptr
结果,为了使您的任何类线程安全,
contfree_safe_ptr ptr_thread_safe; 性能几乎与您在之前的类方法中开发无锁算法一样。另外,有可能一次更改多个contfree_safe_ptr <>。除了std :: shared_ptr <>,我们的智能指针还将包含一个引用计数。可以复制它,并在删除最后一个副本后,将自动释放动态分配的内存。
最后,将提供1个safe_ptr.h文件,该文件足以通过#include“ safe_ptr.h”进行连接,以使您可以使用此类。
多线程数据交换的基本原理
如您所知,只有在以下4种情况下,我们才能从不同的线程读取和更改同一对象:
- 基于锁。该对象受锁保护:自旋锁,std(互斥锁,recursive_mutex,timed_mutex,shared_timed_mutex,shared_mutex ...):http://en.cppreference.com/mwiki/index.php?title=Special%3ASearch&search=mutex
- 原子的。该对象的类型为std :: atomic
,其中T是指针,布尔型或整数类型(std :: is_integral :: value == true),并且仅当T类型存在原子操作时在CPU级别:http : //en.cppreference.com/w/cpp/atomic/atomic (2 + 1)-(Lock-based-Atomic)否则,如果T类型是平凡可复制的类型,即满足条件std :: is_trivially_copyable :: value == true,然后std :: atomic 用作基于锁的-锁会自动在其中使用。 - 交易安全。为与对象一起工作而实现的功能可提供线程安全保证transaction_safe(事务内存TS(ISO / IEC TS 19841:2015)-实验性C ++):http : //en.cppreference.com/w/cpp/语言/交易记忆
- 无锁。用于对象的功能是在无锁算法的基础上实现的,即它们提供了无锁线程安全保证。
如果了解确保线程安全的所有4种方法,则可以跳过本章。
让我们考虑相反的顺序:
(4)无锁算法非常复杂,创建每种复杂算法通常需要数项计算工作。可在容器中使用的无锁算法示例-unordered_map,ordered_map,队列等等...
这些是非常快速且可靠的多线程数据结构
(3)交易安全性计划包含在C ++标准的实验部分中,并且已经在以下位置提供了ISO / IEC TS 19841:2015草案:http : //www.open-std.org/jtc1/sc22 /wg21/docs/papers/2015/N4514.pdf。
但是,即使并非所有STL容器都计划成为交易安全的。例如,甚至没有计划将std :: map容器设置为事务安全的,因为仅将以下功能定义为事务安全的:begin,end,size,max_size,空。但是以下函数未定义为线程安全的:查找,修改,插入。而且,使用事务安全的成员函数来实现自己的对象根本不容易,否则可以使用std :: map来实现。
(2)原子。这种方法已经在C ++ 11中进行了标准化,您可以轻松地使用它。例如,声明变量std :: atomic
成员功能,专业成员功能:http : //en.cppreference.com/w/cpp/atomic/atomic
重要的是要理解,如果执行几个原子变量操作(这无关紧要,如果它发生在一个表达式或多个表达式中),则它们之间的另一个线程可以更改该变量的值。因此,对于几个操作的原子执行,我们使用基于CAS函数(Compare-And-Swap)compare_exchange_weak()的无锁方法-即:我们将原子变量中的值读入局部变量(old_local_val),执行许多必要的操作并将结果写入局部变量(new_local_val),最后,我们通过CAS函数将原子变量的当前值与初始值(old_local_val)进行比较;如果它们不相等,那么我们重新执行循环,如果它们相等,则表示在此期间另一个线程未做任何更改,然后我们用新值(new_local_val)更改了原子变量值。那时,比较和赋值是通过一个操作完成的:compare_exchange_weak()-它是一个原子函数,在完全执行之前,没有人可以更改变量的值:[4]http://coliru.stacked-crooked.com/a/aa52b45150e5eb0a。
这种带有循环的方法称为乐观锁。悲观锁有:自旋锁,互斥锁...
而且,如果在没有悲观锁的情况下执行了该循环的所有操作,则这种算法称为无锁。更准确地说,这种算法可以保证:无障碍,无锁,无等待或无写入。
通常,原子CAS函数会替换指针,即:分配新的内存,将修改后的对象复制到该内存,并获得指向该内存的指针;在此副本上执行许多操作,最后,如果在这段时间内另一个线程未更改旧指针,则CAS函数将旧指针替换为新对象指针。但是,如果指针已被另一个线程更改,则将再次重复所有操作。
所谓的“ABA”一个可能的问题可能会出现在这里-
https://en.wikipedia.org/wiki/ABA_problem
当其他线程有时间两次更改指针,然后指针第二次更改为初始值时,但是在该地址,其他线程已经能够删除该对象并创建一个新对象。也就是说,指针的值已经指示了另一个对象,但是我们看到该值没有改变,并认为该对象尚未被替换。解决此问题的方法有很多,例如:LL / SC,RCU,hazard_pointer,垃圾收集器...
原子是在线程之间交换数据的最快方法。此外,对于所有原子操作,可以使用不太严格和更快的存储保护,这将在后面详细讨论。默认情况下,使用最安全和严格的重新排序障碍:std :: memory_order_seq_cst。但是如上所述,您需要付出很多努力才能通过使用原子变量来实现复杂的逻辑。
(2)-(1)基于原子和锁定。
但是,如果您需要一次读取或更改几个变量-std :: atomic
在C ++标准中,如果std :: atomic
C ++标准说明了什么:http : //www.open-std.org/jtc1/sc22/wg21/docs/papers/2016/n4606.pdf
§29.5/ 1
1 引用: 2 有一个通用的类模板atomic。模板参数T的类型应是可复制的(3.9)。[注意:不能静态初始化的类型参数可能很难使用-尾注]
§3.9/ 9
1 引用: 2 标量类型,普通可复制类类型(第9章),此类类型的数组以及这些类型的cv限定版本(3.9.3)统称为普通可复制类型
但是,如果CPU原子CAS函数可以检查是否仅更改了一个最大宽度为64位的变量,并且我们具有三个32位变量,那么CAS函数将如何在std :: atomic
要原子地更改几个变量,我们可以使用变量结构struct T {int price,count,total; }; 作为std :: atomic
示例:[5] http://coliru.stacked-crooked.com/a/bdfb3dc440eb6e51
输出示例:10、7、70
在此示例中,在任何时候,最后的值70将等于前两个值p-10 * 7的乘积-即整个结构仅发生原子变化。
用于x86的gcc和clang中的代码将使用-latomic标志进行编译。
在这种情况下,每次调用std :: atomic
也就是说,在全局范围内,当处理原子变量时,我们使用了乐观锁(周期),并在本地使用了2个悲观锁:获取旧值并调用CAS函数。
(1)基于锁定。
但是我们不能将std :: atomic
在这种情况下,您必须自己创建互斥对象,并在每次使用共享对象之前锁定它们,然后再解锁。概念:http : //en.cppreference.com/w/cpp/concept/Mutex
在C ++中,存在以下互斥对象:std :: mutex,std :: recursive_mutex,std :: timed_mutex,std :: recursive_timed_mutex,std :: shared_timed_mutex,std :: shared_mutex。有关更多信息,请参见:http : //en.cppreference.com/w/cpp/thread
例如,我们创建了线程之间共享的任何std :: map
我们使用RAII惯用语执行锁定:
std :: lock_guard
但是仍然存在4个主要问题:
- 死锁-如果您以这样的方式编写代码:线程1锁定mtx1,线程2锁定mtx2,并且在持有该锁的同时,线程1尝试捕获mtx2,线程2尝试捕获mtx1,则这些线程将永远彼此等待。无锁算法不存在此问题,但是无锁算法无法实现任何逻辑-我们将通过对多个容器进行原子更改的示例来演示此问题。
- 如果您以这样的方式编写代码,即互斥锁被锁定时,您将共享对象链接分配给指针,其寿命比std :: lock_guard锁的寿命更长,那么在解锁后,您可以引用共享对象通过此指针-这将导致数据争用问题,即,它将导致共享对象的状态不一致以及操作不正确或程序崩溃。如果在解锁互斥锁之后使用迭代器,则会发生相同的情况。
- 您可以与互斥锁混淆,并锁定保护另一个对象的互斥锁-数据竞争。
- 您可能只是忘记将互斥锁锁定在正确的位置-数据争用。
围绕指针习语执行
除了RAII惯用语外,还有另一个有趣的惯用语-围绕指针执行(Execute Around Pointer),它有助于解决最后两个问题:
- 互斥锁将与您的对象融合在一起,您将能够锁定对象本身,但不能锁定单独的互斥锁。
- 当寻址到受保护对象类的任何成员时,互斥锁将自动锁定-在此,它将在表达式执行期间被锁定。
因此,您不能忘记锁定互斥锁,也不能与互斥锁混淆。
我们使任何对象线程安全。
围绕指针成语执行是众所周知的成语,具有严格定义的执行顺序,从可视化到日志记录,它用于多种目的:
https://zh.wikibooks.org/wiki/More_C%2B%2B_Idioms/Execute-Around_Pointer
范例:[7] http://coliru.stacked-crooked.com/a/4f3255b5473c73cc
1 execute_around< std::vector< int > > vecc(10, 10); 2 int res = my_accumulate(vecc->begin(), vecc->end(), 0);
首先,将创建代理类型的临时对象。他们将互斥锁锁定在execute_around内,然后将由begin()和end()函数返回的迭代器传递给该函数,然后将执行my_accumulate()函数,并且只有在完成后,代理类型的临时对象才会被执行。被删除,其析构函数将解锁互斥体。
有关更多详细信息,请参见文章:围绕序列执行的C ++模式。凯夫琳·亨尼(Kevlin Henney):http : //hillside.net/europlop/HillsideEurope/Papers/ExecutingAroundSequences.pdf
在C ++中,有两个定义严格定义了C ++ Standard§1.9(13)的操作顺序:先于顺序和后于顺序。在标准的以下引用中,您将看到两次“之前排序”。
标准中严格描述了“在指针周围执行”习语中所有动作的执行原理和顺序。首先,我们将引用C ++标准中的五个引号,然后向您展示每个引号如何解释Execute Around Pointer Idiom的行为。
从C ++标准,工作草案,编程语言标准C ++ N4606 2016-07-12中引用了五句话:http ://www.open-std.org/jtc1/sc22/wg21/docs/papers/2016/n4606.pdf
1.对于不同于原始指针的所有类型:x-> m解释为(x.operator->(())-> m。即表达式(x-> m)将反复扩展((x.operator->(()。operator->())-> m,直到得到原始指针。示例),其三个表达式的含义相同:[8 ] http://coliru.stacked-crooked.com/a/dda2474024b78a0b
引用:
1 第13.5.6节 2 operator->应该是不带参数的非静态成员函数。它实现了使用->的类成员访问语法。 3 postfix-expression->模板opt id-expression 4 postfix-expression->伪析构函数名称 5 如果T :: operator->()存在并且如果选择运算符作为最佳匹配函数,则表达式T-的类对象x的表达式x-> m解释为(x.operator->())-> m。通过过载解析机制(13.3)。
2.调用一个函数时,即使它是“内联”的,也绝不会在函数主体开始执行之前就执行任何计算表达式和评估函数自变量的结果。
引用:
§1.9 / 16
1 在调用函数时(无论函数是否为内联),与任何参数表达式或指定所调用函数的后缀表达式相关联的每个值计算和副作用都将在执行主体中的每个表达式或语句之前进行排序。称为函数。
3.在销毁一个临时对象之前,该表达式已完全执行。
引用:
1 §1.9 / 10 2 void f() { 3 if (S(3).v()) // full-expression includes lvalue-to-rvalue and 4 // int to bool conversions, performed before 5 // temporary is deleted at end of full-expression 6 { } 7 }
4.整个表达式完全执行后,临时对象按照其创建顺序的相反顺序销毁。
引用:
1 §1.9脚注8 2 3 如第12.2节所述,在评估了完整表达式之后,通常会以与每个临时对象相反的顺序对临时对象进行一系列零次或更多次调用析构函数的调用。
5.三种情况,当临时对象在另一个点处被销毁,然后在完整表达式的末尾销毁–初始化数组元素时发生2种情况,第三种情况–当创建对临时对象的引用时。
引用:
第12.2条临时对象
1 §12.2 / 5 2 3 在三种情况下,临时变量在与完整表达式末尾不同的位置被破坏。第一个上下文是在调用默认构造函数以初始化没有对应的初始化程序(8.6)的数组元素时。第二种情况是在复制整个数组时调用复制构造函数复制数组的元素(5.1.5,12.8)。在任何一种情况下,如果构造函数具有一个或多个默认参数,则在构造下一个数组元素(如果有)之前,将对在默认参数中创建的每个临时变量的销毁顺序进行排序。第三种情况是引用绑定到临时项时。
例如,我们有一个简化的类:execute_around<>
1 template< typename T, typename mutex_type = std::recursive_mutex > 2 class execute_around { 3 std::shared_ptr< mutex_type > mtx; 4 std::shared_ptr< T > p; 5 6 void lock() const { mtx->lock(); } 7 void unlock() const { mtx->unlock(); } 8 public: 9 class proxy { 10 std::unique_lock< mutex_type > lock; 11 T *const p; 12 public: 13 proxy (T * const _p, mutex_type& _mtx) : lock(_mtx), p(_p) { std::cout << "locked \n";} 14 proxy(proxy &&px) : lock(std::move(px.lock)), p(px.p) {} 15 ~proxy () { std::cout << "unlocked \n"; } 16 T* operator -> () {return p;} 17 const T* operator -> () const {return p;} 18 }; 19 20 template< typename ...Args > 21 execute_around (Args ... args) : 22 mtx(std::make_shared< mutex_type >()), p(std::make_shared< T >(args...)) {} 23 24 proxy operator->() { return proxy(p.get(), *mtx); } 25 const proxy operator->() const { return proxy(p.get(), *mtx); } 26 template< class Args > friend class std::lock_guard; 27 };
然后,我们通过以下方式使用模板类execute_around <>,例如:[45] http://coliru.stacked-crooked.com/a/d2e02b61af6459f5
1 int main() { 2 typedef execute_around< std::vector< int > > T; 3 T vecc(10, 10); 4 int res = my_accumulate(vecc->begin(), vecc->end(), 0); 5 return 0; 6 }
然后,经过几次转换,最后一个表达式可以简化为以下形式。
1.根据标准的第一引号,x-> m解释为(x.operator->(())-> m:
1 int res = my_accumulate( 2 (vecc.operator->())->begin(), 3 (vecc.operator->())->end(), 4 0);
2.当vecc.operator->()返回临时对象T :: proxy()时,我们收到:
1 int res = my_accumulate( 2 T::proxy(vecc.p.get(), *vecc.mtx)->begin(), 3 T::proxy(vecc.p.get(), *vecc.mtx)->end(), 4 0);
3.此外,根据引用2、3和4,将在函数开始执行之前创建临时代理类型的对象,并在函数结束后(整个表达式的结尾)将其销毁:
1 T::proxy tmp1(vecc.p.get(), *vecc.mtx); // lock-1 std::recursive_mutex 2 T::proxy tmp2(vecc.p.get(), *vecc.mtx); // lock-2 std::recursive_mutex 3 int res = my_accumulate(tmp1->begin(), tmp2->end(), 0); 4 5 tmp2.~T::proxy(); // unlock-2 std::recursive_mutex 6 tmp1.~T::proxy(); // unlock-1 std::recursive_mutex
据第一个报价:
1 tmp1-> begin()等效于(tmp1.operator->())-> begin() 2 tmp1.operator->()返回p
结果,我们得到,其中p是指向类型std :: vector
1 typedef execute_around< std::vector< int > > T; 2 T vecc(10, 10); 3 T::proxy tmp1(vecc.p.get(), *vecc.mtx); // lock-1 std::recursive_mutex 4 T::proxy tmp2(vecc.p.get(), *vecc.mtx); // lock-2 std::recursive_mutex 5 6 int res = my_accumulate(tmp1.p->begin(), tmp2.p->end(), 0); 7 8 tmp2.~T::proxy(); // unlock-2 std::recursive_mutex 9 tmp1.~T::proxy(); // unlock-1 std::recursive_mutex
在4个步骤中,我们描述了所有习语动作的严格顺序。注意,该标准不保证创建临时变量tmp1和tmp2的顺序相反,即,首先可以创建tmp2,然后创建-tmp1; 但这不会改变我们程序的逻辑。
请注意,我们没有引用该标准的第5条引文,因为它描述了3种情况下某个对象的移除时间可能不同于给定的情况,并且正如我们所看到的,这些情况都不能与我们的情况相对应。标准引用中的前两种情况是数组的初始化或复制,它们缩短了临时对象的寿命,而第三种情况是由于存在其链接而延长了临时对象的寿命。
使用代码
线程安全的关联数组。
同意,拥有这样的模板类safe_ptr <>会很方便,您可以向其传递任何类型,结果接收到线程安全的结果类型?
1 safe_ptr
此外,您可以将此对象与指向关联数组的指针一起使用:
1 std::shared_ptr
但是现在我们可以从不同的线程安全地使用它,并且每个单独的表达式都是线程安全的:
1 (*safe_map_strings)["apple"].first = "fruit"; 2 3 (*safe_map_strings)["potato"].first = "vegetable"; 4 5 6 7 safe_map_strings->at("apple").second = safe_map_strings->at("apple").second * 2; 8 9 safe_map_strings->find("potato")->second.second++;
让我们看一个线程安全关联的案例研究: std::map<>
[9] http://coliru.stacked-crooked.com/a/5def728917274b22
1 #include < iostream > 2 #include < string > 3 #include < vector > 4 #include < memory > 5 #include < mutex > 6 #include < thread > 7 #include < map > 8 9 template< typename T, typename mutex_t = std::recursive_mutex, typename x_lock_t = 10 std::unique_lock< mutex_t >, typename s_lock_t = std::unique_lock < mutex_t > > 11 class safe_ptr { 12 typedef mutex_t mtx_t; 13 const std::shared_ptr< T > ptr; 14 std::shared_ptr< mutex_t > mtx_ptr; 15 16 template< typename req_lock > 17 class auto_lock_t { 18 T * const ptr; 19 req_lock lock; 20 public: 21 auto_lock_t(auto_lock_t&& o) : ptr(std::move(o.ptr)), lock(std::move(o.lock)) { } 22 auto_lock_t(T * const _ptr, mutex_t& _mtx) : ptr(_ptr), lock(_mtx){} 23 T* operator -> () { return ptr; } 24 const T* operator -> () const { return ptr; } 25 }; 26 27 template< typename req_lock > 28 class auto_lock_obj_t { 29 T * const ptr; 30 req_lock lock; 31 public: 32 auto_lock_obj_t(auto_lock_obj_t&& o) : 33 ptr(std::move(o.ptr)), lock(std::move(o.lock)) { } 34 auto_lock_obj_t(T * const _ptr, mutex_t& _mtx) : ptr(_ptr), lock(_mtx){} 35 template< typename arg_t > 36 auto operator [] (arg_t arg) -> decltype((*ptr)[arg]) { return (*ptr)[arg]; } 37 }; 38 39 void lock() { mtx_ptr->lock(); } 40 void unlock() { mtx_ptr->unlock(); } 41 friend struct link_safe_ptrs; 42 template< typename mutex_type > friend class std::lock_guard; 43 //template< class... mutex_types > friend class std::lock_guard; // C++17 44 public: 45 template< typename... Args > 46 safe_ptr(Args... args) : ptr(std::make_shared< T >(args...)), mtx_ptr(std::make_shared< mutex_t >()) {} 47 48 auto_lock_t< x_lock_t > operator-> () { return auto_lock_t< x_lock_t >(ptr.get(), *mtx_ptr); } 49 auto_lock_obj_t< x_lock_t > operator* () { return auto_lock_obj_t< x_lock_t >(ptr.get(), *mtx_ptr); } 50 const auto_lock_t< s_lock_t > operator-> () const { return auto_lock_t< s_lock_t >(ptr.get(), *mtx_ptr); } 51 const auto_lock_obj_t< s_lock_t > operator* () const { return auto_lock_obj_t< s_lock_t >(ptr.get(), *mtx_ptr); } 52 }; 53 // --------------------------------------------------------------- 54 55 56 safe_ptr< std::map< std::string, std::pair< std::string, int > > > safe_map_strings_global; 57 58 59 void func(decltype(safe_map_strings_global) safe_map_strings) 60 { 61 //std::lock_guard< decltype(safe_map_strings) > lock(safe_map_strings); 62 63 (*safe_map_strings)["apple"].first = "fruit"; 64 (*safe_map_strings)["potato"].first = "vegetable"; 65 66 for (size_t i = 0; i < 10000; ++i) { 67 safe_map_strings->at("apple").second++; 68 safe_map_strings->find("potato")->second.second++; 69 } 70 71 auto const readonly_safe_map_string = safe_map_strings; 72 73 std::cout << "potato is " << readonly_safe_map_string->at("potato").first << 74 " " << readonly_safe_map_string->at("potato").second << 75 ", apple is " << readonly_safe_map_string->at("apple").first << 76 " " << readonly_safe_map_string->at("apple").second << std::endl; 77 } 78 79 80 int main() { 81 82 std::vector< std::thread > vec_thread(10); 83 for (auto &i : vec_thread) i = std::move(std::thread(func, safe_map_strings_global)); 84 for (auto &i : vec_thread) i.join(); 85 86 std::cout << "end"; 87 int b; std::cin >> b; 88 89 return 0; 90 }
输出:
1 引用: 2 3 土豆是蔬菜65042,苹果是水果65043 4 5 土豆是蔬菜81762,苹果是水果81767 6 7 土豆是蔬菜84716,苹果是水果84720 8 9 土豆是蔬菜86645,苹果是水果86650 10 11 土豆是蔬菜90288,苹果是水果90291 12 13 土豆是蔬菜93070,苹果是水果93071 14 15 土豆是蔬菜93810,苹果是水果93811 16 17 土豆是蔬菜95788,苹果是水果95790 18 19 土豆是蔬菜98951,苹果是水果98952 20 21 土豆是蔬菜100000,苹果是水果100000 22 23 结束
因此,我们有2个结论:
- 结果值100,000表示以线程安全的方式在10个线程中的每个线程中进行了每次加法。确实,更改我们的代码足以使它
operator->返回指向对象本身的指针,而不是返回auto_lock_t和auto_lock_obj_t类型,如我们将看到的,如果代码不是线程安全的代码,则将发生什么-数据争用:[10] http://coliru.stacked-crooked.com/a/45d47bcb066adf2e - 中间值为10,000,表示线程是并行执行的还是伪并行执行的,即,它们在任何操作的中间都被中断,并且此时正在执行另一个线程。即,在每次
operator++增量之前,互斥锁都被锁定,并且在增量之后立即将其解锁,然后该互斥锁可以被另一个执行增量的线程锁定。通过使用std::lock_guard<>,我们可以立即在每个线程的开始处锁定互斥锁,直到线程功能执行结束为止。如果按顺序执行线程,但不是以伪并行方式执行线程,我们将看到会发生什么:[11] http://coliru.stacked-crooked.com/a/cc252270fa9f7a78
这两个结论都证实了我们的safe_ptr聪明的指针类模板自动确保了类型T的受保护对象的线程安全性。
多个对象的线程安全性,原子性和一致性。
我们将演示如何一次原子地更改多个对象,从而保持它们的一致性。我们将演示在必要时如何做以及如果不做会发生什么。
让我们给出一个简化的示例,假设我们有2个表:
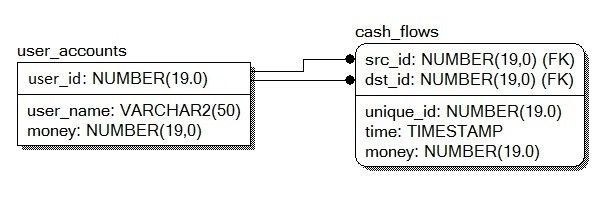
user_accounts(INT user_id, STRING user_name, INT money)-包含每个客户的金额的表-按user_id字段排序cash_flows(INT unique_id, INT src_id, INT dst_id, INT time, INT money)–显示资金流量的表格-每个条目均由两个关联数组引用,这些数组进行了排序:按字段src_id和按字段dst_id
1 // 1-st table 2 struct user_accounts_t { 3 std::string user_name; int64_t money; 4 user_accounts_t(std::string u, int64_t m) : user_name(u), money(m) {} 5 }; 6 7 std::map< uint64_t, user_accounts_t > user_accounts; 8 9 // 2-nd table 10 struct cash_flows_t { uint64_t unique_id, src_id, dst_id, time; int64_t money; }; 11 12 std::atomic< uint64_t > global_unique_id; // SQL-sequence 13 std::multimap< uint64_t, std::shared_ptr< cash_flows_t > > cash_flows_src_id; 14 std::multimap< uint64_t, std::shared_ptr< cash_flows_t > > cash_flows_dst_id;
在RDBMS方面:
- 具有user_id字段索引的第一张表-它是索引组织表(Oracle)或具有聚集索引的表(MS SQL)。
- 第二表-它是一个具有两个索引的表,分别由一个src_id字段和一个dst_id字段组织。
在实际任务中,一个表可以包含数百万个客户条目和数十亿个货币流量条目,在这种情况下,按字段(user_id,src_id,dst_id)创建的索引可以使搜索速度提高数十万倍,因此这是非常必要的。
让我们假设执行三个任务的请求来自三个并行线程中的三个用户:
1.- move_money()线程将资金从一个客户转移到另一个客户
- 从一个客户那里拿钱
- 它向另一个客户增加了相同的金额
- id-source字段索引添加了一个指向金钱条目的指针
- id-destination字段索引添加了一个指向相同金钱条目的指针(在实际任务中,这不是必需的,但我们将作为示例)
2.- show_total_amount()显示所有客户的金额
一种。在周期中,我们遍历每个客户并总结所有资金
3. show_user_money_on_time()-显示的客户的资金量相对于在时间点指定的USER_ID
incoming-汇总从该时间点及以后到达客户的所有资金(通过使用id-source字段索引)outcoming-汇总从该时间点及以后从客户那里获得的所有资金(通过使用id-destination字段索引)user_money-从客户那里获得当前资金user_ user_money-收入+收入-这是客户在该时间点的金额
我们知道,任何线程都可以在任何时候被操作系统中断,例如,以便将CPU-Core分配给另一个线程。最危险的事情是这种情况极少发生,也许您在调试期间将永远不会面对它,但是有一天它会在客户端发生。而且,如果这导致了数据争用,那么金钱就可以简单地从金融系统中消失。
因此,我们故意添加了等待函数,这些函数将使线程在最关键的位置休眠数毫秒,以便立即看到错误。
我们将使用来使表(user_accounts,cash_flows_src_id,cash_flows_dst_id)safe_ptr<>成为线程安全的,但是之后整个程序将变为线程安全的吗?
[12] http://coliru.stacked-crooked.com/a/5bbba59b63384a2b
让我们看一下程序输出中的«基本行»,这些行用<<<标记:
引用:
1 初始化表safe_user_accounts: 2 at time = 0 <<< 3 1 => John Smith,100 4 2 => John Rambo,150- 5 开始交易... show_total_amount() 6 1 => John Smith,100 7 2 => John Rambo,100 8 结果:所有帐户total_amount = 200 <<< 9 -开始交易... show_user_money_on_time() 10 1 => John Smith,150,时间= 0 <<<
立即出现两个错误:
- 最初,所有(两个)用户总共拥有250笔钱,而该功能
show_total_amount()仅显示200笔钱,等于50的其余钱消失在某个地方。 - 在时间= 0时,用户1拥有100块钱,但
show_user_money_on_time()功能显示错误的结果–用户1在时间= 0处具有150块钱
问题在于,原子性仅在单个表和索引的级别上被观察到,而在总表中则没有,因此,其一致性被破坏了。解决方案是在必须原子执行的所有操作期间锁定所有使用的表和索引-这将保持一致性。
添加的行以黄色突出显示。差异:

正确的示例:[13] http://coliru.stacked-crooked.com/a/c8bfc7f5372dfd0c
让我们看一下程序输出中的«基本行»,这些行用<<<标记:
引用:
1 初始化表safe_user_accounts: 2 在时间= 0 <<< 3 1 =>约翰·史密斯,100 4 2 => John Rambo,150岁 5 结果:所有帐户total_amount = 250 <<< 6 1 => John Smith,100,时间= 0 <<<
现在一切都正确了,在时间点0,所有客户的金额为250,客户1的金额为100。
也就是说,我们不仅可以原子地对一个对象执行操作,而且一次可以对3个对象执行操作,从而为任何操作保持数据的一致性。
但是这里还有另一个问题。如果您(或另一位开发人员)在其中一个函数中以不同的顺序锁定容器的互斥锁,则可能发生死锁情况-当2个线程永远挂在一起等待时。
在上面的正确示例中,我们以相同的顺序锁定了两个函数(move_money()和show_user_money_on_time())中的互斥锁:
1 lock1(safe_user_accounts)
2 lock2(safe_cash_flows_src_id)
3 lock3(safe_cash_flows_dst_id)
现在让我们看看如果我们以不同的顺序锁定每个函数中容器中的互斥锁会发生什么:
1 1个. move_money() 2 lock2(safe_cash_flows_src_id) 3 lock3(safe_cash_flows_dst_id) 4 lock1(safe_user_accounts) 5 2。 show_user_money_on_time() 6 lock3(safe_cash_flows_dst_id) 7 lock2(safe_cash_flows_src_id) 8 lock1(safe_user_accounts)
函数move_money()锁定lock2并等待,直到释放lock3以对其进行锁定。函数show_user_money_on_time()锁定lock3,并等待直到释放lock2来对其进行锁定。他们将永远等待对方。
例如:[14] http://coliru.stacked-crooked.com/a/0ddcd1ebe2be410b
例:
1 引用: 2 初始化表safe_user_accounts: 3 在时间= 0 <<< 4 1 =>约翰·史密斯,100 5 2 => John Rambo,150岁 6 7 -开始交易... move_money() 8 -开始交易... show_total_amount() 9 10 1 =>约翰·史密斯,100 11 2 => John Rambo,150岁
也就是说,函数move_money()和show_user_money_on_time()永远不会完成,并且永远死锁。
有4个解决方案:
- 所有开发人员始终以相同的顺序锁定所有功能中的互斥锁,并且永远不会出错-这是一个非常不可靠的假设
- 最初,您将所有对象(将在原子上使用)组合在一个结构中,并使用具有此结构类型的安全指针:
struct all_t { std::mapsafe_ptr–但是,如果最初使用这两个容器,则只有单独的容器safe_all_obj; safe_ptr且yu已经编写了很多代码,之后您决定将它们组合成一个受单个互斥锁保护的结构,那么您将不得不重写所有使用它们的位置,例如,而不是m2->at(5);您需要编写safe_all_obj->m2.at(5);。重写很多代码不是很方便。 - 一次,您可以将在一起使用的safe_ptr <>组合在一起,以使它们使用相同的递归互斥量,此后锁定的顺序无关紧要;这些对象的一致性将始终保持不变,并且永远不会死锁。为此,您只需要添加1行-这非常方便。但这会降低性能,因为现在锁定其中一个容器始终会导致锁定所有关联的容器。即使不需要,您也将获得一致性-以降低性能为代价。范例:[15] http://coliru.stacked-crooked.com/a/2a6f1535e0b95f7b
代码中的所有更改仅一行:
static link_safe_ptrs tmp_link(safe_user_accounts, safe_cash_flows_src_id, safe_cash_flows_dst_id);结论–基本行如下所示:
引用:
1 初始化表safe_user_accounts: 2 在时间= 0 <<< 3 1 =>约翰·史密斯,100 4 2 => John Rambo,150岁 5 结果:所有帐户total_amount = 250 <<< 6 1 => John Smith,100,时间= 0 <<<
您可以通过超时设置一次将锁用于多个不同类型的互斥锁,以锁定每个互斥锁。如果在此期间您无法锁定至少一个互斥锁,则所有先前锁定的互斥锁都将被解锁,线程将等待一段时间,然后尝试一次又一次锁定所有互斥锁。为此,在每次使用容器之前添加一行就足够了
lock_timed_any_infinitylock_all(safe_cash_flows_src_id, safe_cash_flows_dst_id, safe_user_accounts); 锁定容器的互斥锁的顺序无关紧要。例如:[16] http://coliru.stacked-crooked.com/a/93206f216ba81dd6
也就是说,即使我们以不同的顺序锁定互斥锁:
- 然后在使用的情况下,
lock_timed_any_infinity不会发生死锁:[17] http://coliru.stacked-crooked.com/a/a281f90299771434 - 在类似的示例中,如果使用
lock_guard<>–会发生死锁:[18] http://coliru.stacked-crooked.com/a/7ac7640918228090

因此,在锁的帮助下,我们解决了可组合性问题,并保证了不会出现永久死锁:https://en.wikipedia.org/wiki/Lock_(computer_science)#Lack_of_composability
您可以通过本文顶部的链接获取适用于Windows / Linux的示例。
经过测试:
- Windows x86_64(MSVS 2013和2015)
- Linux x86_64(g ++ 6.3.0和clang 3.8.0)
此代码在在线编译器中:http : //coliru.stacked-crooked.com/a/a97a84ff26c6e9ee
将safe_ptr <>与rw-lock一起使用。
要将安全指针与rw-lock而不是unique-lock一起使用,只需 #include 编写so shared_mutex_safe_ptr而不是即可 safe_ptr。或者更好地编写contfree_safe_ptr使用更快的共享互斥量的方法,我们将在第二篇文章中对其进行描述。然后,使用 slock_safe_ptr(ptr)->find(5);或auto const& ptr_read = ptr; ptr_read->find(5); 称为只读共享锁-我们将在第三篇文章中介绍这些方式。
其他背景
可组合性和僵局。
由于我们在上文中将锁用于线程安全,因此我们的算法称为基于锁。
在无锁容器中没有死锁,基于事务性内存的算法方面是否真的还不错,并且现代RDBMS中是否存在死锁:MSSQL(基于锁的IL)和Oracle(多版本并发控制)?
无锁算法不允许一次原子地更改多个容器。RDBMS的死锁问题与基于锁的算法相同,它们通常通过锁超时或锁图来解决。并且C ++标准中新的事务安全部分不允许您安全使用复杂算法,例如std :: map <>。
无锁算法不具有可组合操作的属性-几种无锁算法的联合原子使用。也就是说,无法一次更改或读取多个无锁数据结构。例如,您可以使用来自libCDS的关联数组的无锁容器,它们将分别是线程安全的。但是,如果您想一次用几个无锁容器自动执行操作并保持一致性,则不能这样做,因为它们的API不能同时在多个容器上提供无锁操作的功能。当您更改或读取一个容器时,那时将已经更改另一个容器。为避免这种情况,您将需要使用锁,在这种情况下,它将是基于锁的容器,这意味着它们将具有基于锁的算法的所有问题,即可能出现死锁的问题。另外,有时仅在使用一个容器的情况下使用锁:
- http://libcds.sourceforge.net/doc/cds-api/namespacecds_1_1sync.html
- https://github.com/khizmax/libcds/tree/master/cds/lock
- https://github.com/khizmax/libcds/tree/master/cds/sync
在事务性RDBMS中,例如MSSQL(基于锁)和Oracle(多版本并发控制),也使用锁,这就是死锁存在问题的原因,例如,可以通过构建锁来自动解决死锁问题。图形并找到循环等待,或通过设置锁定等待时间,从tbl中选择col,其中(....)中的id用于更新等待30;如果经过了潜在时间或在锁定图中发现了死锁,则发生事务之一的回滚-也就是说,取消该事务已经进行的所有更改,解锁所有已锁定的事务; 然后您可以尝试从一开始就执行事务(如此多次):
- Oracle数据库在线文档11g第1版(11.1)-死锁:https : //docs.oracle.com/cd/B28359_01/server.111/b28318/consist.htm#i5337
Oracle锁:https : //docs.oracle.com/cd/B28359_01/server.111/b28318/consist.htm#i5249
如您所见,任何表达式都使用排他的不兼容锁:Insert / Update / Delete / Select-For-Update
- MSSQL检测和结束死锁:https ://technet.microsoft.com/zh-cn/library/ms178104( v=sql.105).aspx
MS SQL锁:https://technet.microsoft.com/zh-cn/library/ms186396(v = sql.105).aspx
反过来,与无锁容器不同,事务性内存可以自动处理许多容器/数据。也就是说,事务性内存具有可组合操作功能。在内部,使用了悲观锁(具有死锁冲突可能性)或乐观锁(更可能是具有竞争性修改的冲突修改)。并且在发生任何冲突的情况下,交易从一开始就自动取消并重复,这需要多次重复执行所有操作-这会导致高昂的间接费用。他们正在尝试通过在CPU级别上创建硬件事务性存储器来降低开销成本,但是到目前为止,尽管英特尔已经在Haswell CPU中添加了硬件事务性存储器,但仍没有实现令人满意的性能的实现。他们还承诺将事务性内存包含在C ++标准中,但仅在将来,到目前为止,它仅用作实验性,不支持使用std :: map。也就是说,到目前为止,一切仅在理论上是好的。但是在将来,这很可能会取代通常的同步方法。
最终:
- 如果在实现时未提供这样的选项,则不构成基于锁的算法。但是可以实现此选项,我们在前面的部分中已成功实现。
- 无锁算法不是组合的,没有锁的组合是非常复杂的任务。但是使用锁时,这种算法将不再是无锁的,并且存在永久死锁的风险。
- RDBMS:MSSQL(基于锁的IL)和Oracle(MVCC)-可能存在死锁,可以通过锁图或超时来消除死锁。
- 到目前为止,来自C ++标准实验部分的事务性内存仅限于仅在最简单的算法中使用,并且不允许在std :: map <>方法或更复杂的算法中使用算法。
结论:死锁问题存在于表现出高性能的所有类型的算法和系统中,其中一次调用多个数据结构。因此,我们提供了2种解决方案来解决safe_ptr <>
静态link_safe_ptrs tmp_link(safe_user_accounts,safe_cash_flows_src_id,safe_cash_flows_dst_id); -将一个互斥锁用于多个容器
lock_timed_any_infinity lock_all(safe_cash_flows_src_id,safe_cash_flows_dst_id,safe_user_accounts); -使用锁超时;时间到期后,解锁所有内容并尝试再次锁定它如果只有一个容器和一个递归互斥锁用于safe_ptr <>,则在safe_ptr <>中不会发生死锁,因为我们至少需要2个递归互斥锁来进行死锁(或1个非递归锁)。
基于锁的算法的可组合性
通常,认为基于锁的程序是不可组合的,即,如果仅采用2个基于锁的数据结构并逐个原子地对其进行更改,则在任何时间点都不会获得一致的状态。
但是在上面,我们很容易地组成了三个基于锁的容器。我们是怎么做的?在这方面有一点澄清-粗体字:
也许最根本的反对意见是基于锁的程序不能组成:正确的片段在组合时可能会失败。例如,考虑具有线程安全插入和删除操作的哈希表。现在假设我们要从表t1中删除一项A,然后将其插入表t2中。但是中间状态(两个表都不包含项目)必须对其他线程不可见。除非哈希表的实现者预料到了这一需求,否则根本无法满足这一需求。简而言之,不能将单独正确的操作(插入,删除)组成更大的正确操作。
— Tim Harris等人,“可组合内存事务”,第2节:背景,第2页
https://www.microsoft.com/zh-cn/research/wp-content/uploads/2005/01/2005-ppopp-composable.pdf
事实是,除非在实现时提供了这种功能,否则就无法构成基于锁的算法。也就是说,基于锁的数据结构不能自动组成,但是可以手动组成。例如,就像我们在lock_timed_any_infinity类的帮助下所做的那样,如果在外部,则可以访问其互斥量以进行合成操作。
我们实现了基于锁的模板类safe_ptr
那么,为什么我们选择锁及其悲观选择呢?
- 锁是确保线程安全的操作系统和C ++语言的标准机制
- 通过锁,我们可以实现多个数据结构的可组合性和一致性
- 如果您忘记正确组成锁,则悲观锁中可能会出现死锁。很难找到这样的僵局,但是它很容易解决并且很少发生。在任何情况下,在乐观锁中,可能会有冲突的修改。它们很容易找到,但是它们需要附加的C ++代码来解决,而且出现频率更高。
- Tom Kyte是Oracle服务器技术部门的高级技术架构师 -他是Oracle DB(多版本并发控制)中悲观锁的支持者:https : //asktom.oracle.com/pls/asktom/f?p=100 :11:0 :::: P11_QUESTION_ID:5771117722373
关于悲观锁可能导致锁定和死锁的情况,他写道:
我是所谓的悲观锁定的忠实拥护者。用户已经非常清楚地宣布了他们更新数据的意图。他们所指的锁定很容易通过会话超时(琐碎)来处理,并且死锁是如此罕见,并且肯定是一个应用程序错误(在Oracle和RDB中)。
- 死锁是一个错误。如果您认为减慢一些线程比在修复错误时完全停止线程更好,请使用lock_timed_any_infinity。否则,如果要永久停止程序,请使用:link_safe_ptrs和std :: lock_guard <>。
- 也不需要自动升级锁。例如,Oracle DB永远不会这样做:https : //docs.oracle.com/cd/B28359_01/server.111/b28318/consist.htm#CIHCFHGE
Oracle数据库从不升级锁。锁升级大大增加了出现死锁的可能性。
在以下文章中实现我们的算法时,我们将继续定期参考工业RDBMS的广泛经验。
兴趣点
结论:我们证明了自动执行从不同线程进行安全访问的“围绕指针成语执行”的正确性-严格对应于C ++标准。我们展示了其可组合性的一个例子。此外,我们还展示了使用悲观锁定来确保线程安全的优势