Redis的数据结构,其本身大方向是键值对
【0】大概特点
相关产品:Redis、Riak、SimpleDB、Chordless、Scalaris、Memcached
形式:Key 指向 Value 的键值对,通常用hash table来实现
应用:内容缓存
优点:扩展性好、灵活性好、大量写操作时性能高
缺点:无法存储结构化信息、条件查询效率较低
使用者:百度云(Redis)、GitHub(Riak)、BestBuy(Riak)、Twitter(Ridis和Memcached)
【1】五种数据类型
(1)String:字符串 (2)List:字符串列表
(3)sorted set:有序字符串集合 (4)set :字符串集合
(5)Hash:哈希
【2】Key定义的注意点
(1)不要过长
(2)不要过短
(3)统一的命名规范
【3】基本用法
目录:
【3.1】String
【3.2】Hash
【3.3】List
【3.4】set
【3.5】Sorted-Set
【3.6】Keys的通用操作
正文:
【3.1】String
【3.1.1】String的存储
(1)二进制安全存储,存入和获取的数据相同
(2)单个Value最多可以容纳512M以上数据
【3.1.2】常用命令
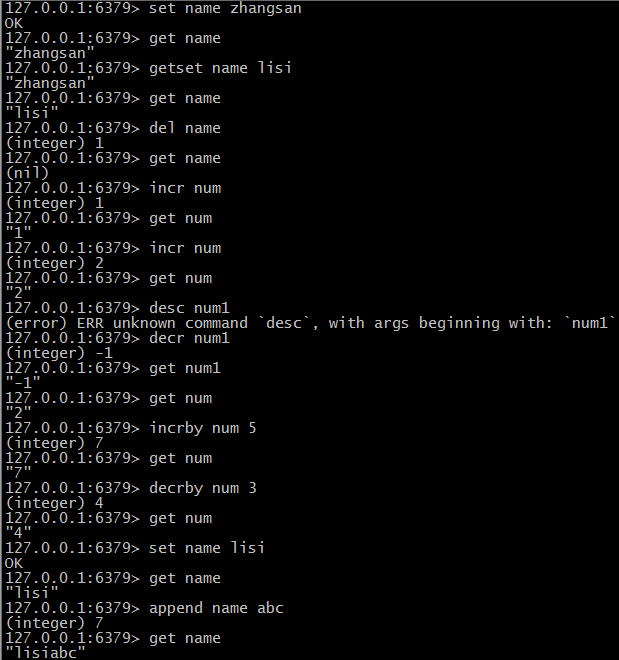
(1)set 赋值:set key value =》set name zhangsan
(2)get 取值:get key =》get name
(3)getset 取值并重新复制:getset key value =》get name lisi
(4)del 删除:delete key =》del name =》del name1 name2 name3(批量删除)
(5)incr/decr 数值递增递减:《1,递增》incr key =》incr num 《2,递减》decr key =》decr key
如果num不存在,则默认值为0,如果操作在字符串上则报错
(6)incrby/decrby 加减运算:《1,加》incrby key addnum =》incrby num 5 -- 给num key对应的 value 数字 +5
《2,减》decrby key subnum =》decrby num 3 -- 给num key对应的 value 数字 -3
(7)append 拼接字符串:append key =》append name abc -- 如果 name 是 lisi ,则结果应该是 lisiabc -- 如果key不存在,则新建该key,且value为 abc
(8)查看所有key:keys *
【3.2】Hash
【3.2.1】Hash 的存储
String Key 和 String Value 的 map 容器
每一个 Hash 可以存储 4294967295 一个无符号4字节的 键值对
一个hashkey 中可以包含多个 key value 键值对
【3.2.2】常用命令
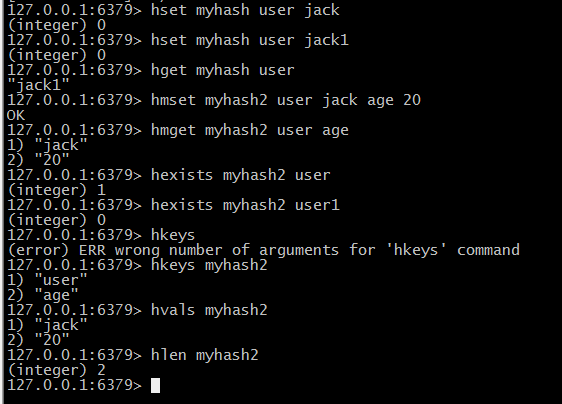
(1)hset 赋值:hset hashkey key value =》hset myhash user jack,其实这也可以多个 hset hashkey key1 value1 key2 value2 key3 value3
(2)hmset 批量赋值:hmset hashkey key1 value1 key2 value2 =》hmset myhash2 user jack age 20
(3)hget 取值:hget hashkey key =》hget myhash user
(4)hmget 批量取值:hmget hashkey key1 key2 =》hmget myhash2 user age
(5)hgetall 获取所有key value:hgetall myhash2
(6)hdel 删除:hdel hashkey key1 key2
(7)del 删除hashkey:del hashkey
(8)hincrby/hdecrby 加减运算:hincrby hashkey key addnum
(9)hexists 存在判断:hexists hashkey key -- 返回 1 代表存在,0代表不存在
(10)hlen 获取key数量:hlen hashkey
(11)hkeys 获取hashkey中的所有Key:hkeys hashkey
(12)hvals 获取所有value:hvals hashkey
(13)hsetnx 创建hashkey中的key,如果不存在则创建,如果存在则不创建:hsetnx hashkey key value
【3.3】List
【3.3.1】存储形式
《1》ArrayList 使用数组存储方式 《2》LinkedList 使用双向链表方式
ArrayList:根据索引,查询非常快,新增和删除节点的时候慢(特别是中间节点,因为要移动数据);
LinkedList:增删节点非常快
【3.3.2】List 的常用命令
理论:
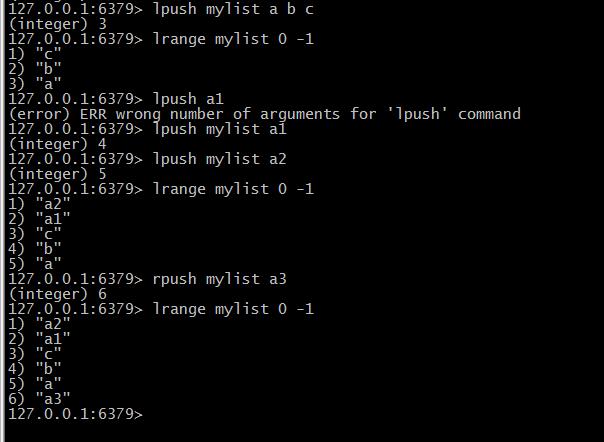
(1)两端添加节点(lpush/rpush):lpush listkey value3 value2 value1(这里的顺序是从右到左),rpush是从左到右。
(2)查看列表(lrange ):lrange listkey begin_pos end_pos(0表示第一个元素下标,-1表示最后一个元素下标)
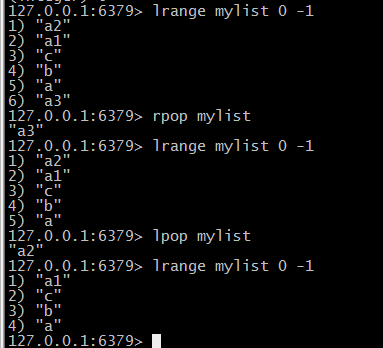
(3)两端删除/取出节点(lpop/rpop)
《1》lpop listkey :如果listkey存在,则删除list的第1个元素
《2》rpop listkey :如果listkey存在,则删除list的最后个元素
(4)获取列表元素个数(llen listkey):
(5)判断listkey是否存在,存在则添加(lpushx/rpushx)
(6)根据value删除(lrem)
lrem listkey count value :从listkey 中删除 count个 值为value的元素
其中,count为正数的时候正序删除,count为负数的时候,倒叙删除,count为0的时候全部删除。
(7)修改list下标所在值(lset):lset listkey 下标号 value
(8)在某个value之前插入newvalue:linsert keylist before/after value newvalue
(9)将A listkey中的最后一个下标value 转移到B listkey中的0下标(rpoplpush):rpoplpush listkeyA listkeyB 。
用途:当消费者从队列中pop时做一个备份,以便当消费者已经取出信息但还没有来得及处理就崩溃导致该数据丢失,保证了数据的一致性。
实践:
(1)两端添加节点(lpush/rpush):lpush listkey value3 value2 value1(这里的顺序是从右到左),rpush是从左到右。
(2)查看列表(lrange ):lrange listkey begin_pos end_pos(0表示第一个元素下标,-1表示最后一个元素下标)
(3)两端删除/取出节点(lpop/rpop)
《1》lpop listkey :如果listkey存在,则删除list的第1个元素
《2》rpop listkey :如果listkey存在,则删除list的最后个元素
(4)获取列表元素个数(llen listkey):
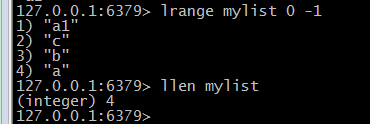
(5)判断listkey是否存在,存在则添加(lpushx/rpushx)
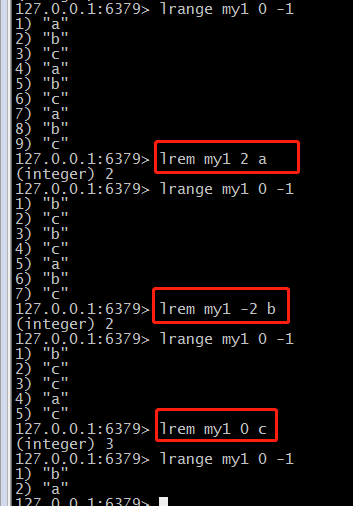
(6)根据value删除(lrem)
lrem listkey count value :从listkey 中删除 count个 值为value的元素
其中,count为正数的时候正序删除,count为负数的时候,倒叙删除,count为0的时候全部删除。
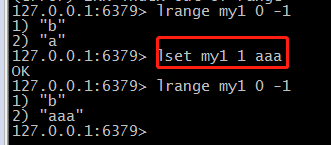
(7)修改list下标所在值(lset):lset listkey 下标号 value
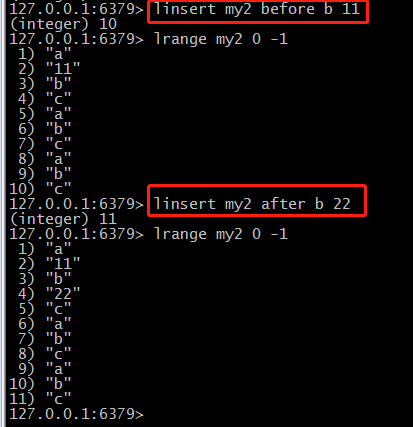
(8)在某个value之前插入newvalue:linsert keylist before/after value newvalue
(9)将A listkey中的最后一个下标value 转移到B listkey中的0下标(rpoplpush):rpoplpush listkeyA listkeyB 。用途:当消费者从队列中pop时做一个备份,以便当消费者取出信息时还没有来得及处理就崩溃导致该数据丢失,保证了数据的一致性。

【3.4】set
【3.4.1】set 的存储
Set 和 List 差不多,但Set 集合中不允许出现重复的元素。
Set 可以包含最大的元素数量是2^32 * 2
【3.4.2】set 的基本操作
(1)sadd(添加):sadd setkey value1 value2 value3
(2)srem(删除):srem setkey value1 value2
(3)smembers(查看):smembers setkey
(4)(修改)
(5)sismember(判断 value 是否存在于 setkey,存在返回1,否则0):sismember setkey value
(6)sdiff(差集运算):sdiff setkey1 setkey2
(7)sinter(交集运算):sinter setkey1 setkey2
(8)sunion(并集运算):sunion setkey1 setkey2
(9)scard(元素数量):scard keyset
(10)srandmember(随机获取1个value):srandmember setkey
(11)sdiffstore(把两个setkey的差集存到一个新的setkey):sdiffkey key1 key2 stroekey
sinterstore key1 key2 stroekey 把两个 setkey 的交集存到一个新的setkey
sunionstore key1 key2 storekey 把两个 setkey 的并集存到一个新的setkey
【3.5】Sorted-Set
【3.5.1】Sorted-Set 存储
Sorted-Set 与 Set 的区别:
Sorted-Set 有一个分数与之关联,通过分数对成员进行从小到大的排序。成员是唯一的,但分数是可以重复的。
Sorted-Set中的成员在集合中的位置是有序的,所以对中部成员检索也是比较高效的。
应用场景:游戏排名、微博热搜榜 等等
【3.5.2】基本操作
(1)zadd(增加):zadd sortkey score1 value1 score2 value2
如果,已经有 70 zs 80 ls ,再进行 zadd sortkey 100 zs,那么value相同,就改变了其 value 对应的 score
(2)zrem(删除):zrem sortkey value1 value2...
zremrangebyrank sortkey 0 4 -- 删除 0~4下标对应的value and score
zrerangebyscore sortkey 80 100 -- 删除 80 ~ 100分的 value and score
(3)zscore(查看分数):zscore sortkey zs -- 结果是100(见(1)中的再次操作)
(4)zcard(查看成员数量):zcard sortkey
(5)zrange(范围查看):zrange sortkey 0 -1 -- 只显示value
zrange sortkey 0 -1 withscores -- 升序显示value and score
zrevrange sortkey 0 -1 withscores -- 降序显示 value and score
zrangebyscore sortkey 0 100 -- 升序显示 分数在0~100之间的value
zrangebyscore sortkey 0 100 with scores limit 0 2 --查询分数在0~100之间的 score(withscores) 与 对应的 value,并且从第0个开始去2个(limit 0 2)
(6)zincrby(增加分数):zincrby sortkey 3 zs -- 给 zs 对应的score +3
(7)zcount(统计个数):zcount sortkey 80 90 -- 统计80~90分存在value的个数
【3.6】Keys的通用操作
无论是什么类型的redis key,都可以使用这些命令来进行相关操作
【3.6.1】基本操作
(1)keys(查看当前所有类型的key):keys * --查看所有 keys a* --查看a开头的key
(2)del(删除任意类型的key):del andkey1 andkey2 andkey3
(3)rename(重命名):rename anykey1 andkey2
(4)expire (过期时间):expire andkey 1000 --单位为秒
(5)ttl(查看有效期):ttl andkey --结果为当前有效的时间,单位为秒
(6)type(查看 anykey 的数据类型):type anykey