What is it?

1.0的技术介绍:https://lmax-exchange.github.io/disruptor/files/Disruptor-1.0.pdf
- 并发的复杂性:互斥与可见性,写竞争是代价最高的
- Locks锁的代价

- CAS的代价
- Developing concurrent programs using locks is difficult;
- developing lock-free algorithms using CAS operations and memory barriers is many times more complex
- it isvery difficult to prove that they are correct.
- The ideal algorithm would be one with only a single thread owning all writes to a single resource with other threads reading the results.
- To read the results in a multi-processor environment requires memory barriers to make the changes visible to threads running on other processors.
- Memory Barriers
- Cache Lines
Disruptor关键点
- Memory Allocation
RingBuffer 初始化创建分配,之后只覆盖,不删除重新创建分配,避免垃圾回收. - RingBuffer环形设计
只有一个Cursor,不像队列有Head和tail,减少竞争 - Sequencing
- Batching Effect
- Dependency Graphs
- Class Diagram
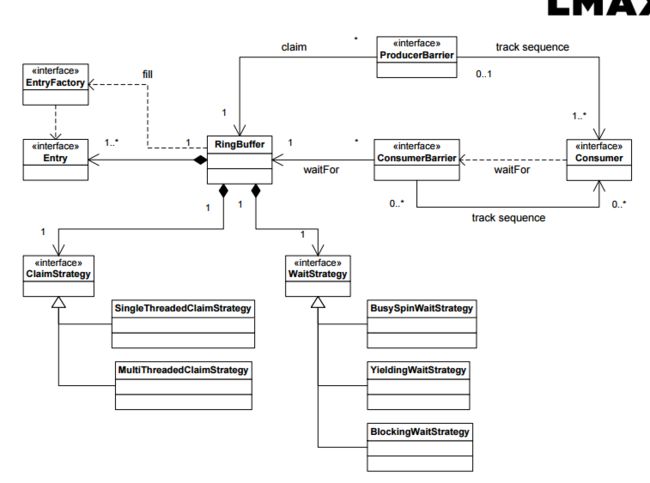
详细说明
Ref:https://www.zhihu.com/question/23235063
Where the story started...
LMAX是一个外汇交易所,每天有很多买卖交易。很多人想像的可能是有着时间戳的数据浮动(图左),而实际上是中间的order book形式(图中)。这些数据的处理因为对时间要求严格,对外汇所带来很大的压力。举简单的例子,order从client端传入,decode后进行matching,一旦存在可成交的价格,就要publish到time series,并且把trade存到local的database里。如何handle这么大数量的数据?

这并不是一个新生的问题。一个经常想到的模型是producer consumer model。

当系统的处理速度比不上导入数据的速度时,可以增加一个queue(buffer)暂存数据,等待consumer处理。数据在queue中被执行的顺序和交易策略有关。
除了handle大量数据,电子商务对数据延迟的要求也很高。首先定义一下什么是数据的延迟。

数据的延迟包括数据的处理时间和数据的移动时间。其中第二部分在编写代码时常被忽略,但在实际生产过程中常占有很大比重。
Queue的不足
Blocking queue有两种,array-based和linked list based。array-based相对更优,这里我们先对它进行一些分析。
Producer和consumer处理速度往往是不同的,这样容易形成两种情况:一种是producer速度快,queue易全满,另一种是consumer速度快,queue易全空。

Blocking queue的缺点主要有两个:一个是producer只能从head放数据,producer之间会竞争head指针,存在写竞争。consumer之间会竞争tail指针,它们之间也存在写竞争。并且很多情况下,queue是处于全空状态,head/tail指针指向同一个entry,producer和consumer之间也存在写竞争。因此需要lock来实现synchronization。另一个缺点是heal/tail指针的false sharing。
缓存行--伪共享
现在的计算机构架往往是有CPU,memory,它们之间有多层的cache。这种构架产生的原因在于CPU速度远高于memory速度。


Memory的最小单位叫block,cache的最小单位叫cache line。Memory到cache存在多对一的mapping。图中用相同颜色表示它们之间的mapping。举例说明,如果有一个integer array,里面存有10个数据。它们一一映射到cache里。



如果使用多个核,这种方法会出现问题。比如第二个核里的数据还是原来的20。
多核中对数据修改时,如果数据存在于多个核的cache里,要将其他核里数据设为invalid。
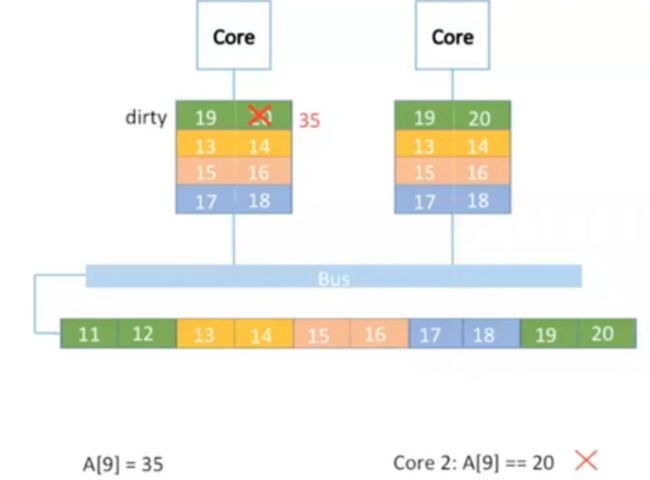


Core 1在访问a时让core 2中对应数据invalid,core 2修改时发现invalid,重新读取数据。但是core 2在读写时又把core 1对应数据invalid。Blocking queue里因为head/tail指针常是同一个,而producer和consumer在不同的core上运行,常会发生上述的false sharing,加大了数据移动的时间。
为什么使用lock会造成很多数据的移动?
Core 1里有thread 1在运行,当遇到lock后,thread 1 sleep,core 1里运行thread 2。对于thread 2,core 1里cache的数据都是无用的。
Thread 2重新加载数据运行。当thread 1醒来时,只能在core 2上运行,重新加载数据。所以当有lock的时候,出现了很多的cache miss,增加了数据移动的时间。

Design of Disruptor
- 在设计Disruptor时要避免写竞争,让数据更久的留在cache里。
- 一个写入者
- 不要Locks
- 序列号 自旋锁
- 内存屏障
- CAS
- 避免缓存行伪共享

Disruptor的核心是一个circular array,有个cursor,里面有sequence number,数据类型是long。如果不考虑consumer,只有一个producer在写,就是不停的往entry里写东西,然后增加cursor上的sequence number。为了避免cursor里的sequence number和其他variable造作false sharing,disruptor定义了7个long型,并没有给它们赋值,然后再定义cursor。这样cursor就不会和其他variable同时出现在一个cache line里。

如果producer在写的过程中,超出了原来array的长度,就不停地overwrite原来的entry,增加cursor里的sequence number。bucket里的entry都是pre-allocated,避免每次都new一个object。因为disruptor是用java写的,这样可以避免garbage collection。producer写的过程是two phase commit。



Consumer每次在访问时需要先检查sequence number是否available,如果不available,会有多种策略。latency最高的一种是盲等。producer在写的时候,需要检查最低的sequence number在哪儿。这里不需要lock的原因是sequence number是递增的。producer不需要赶在最低sequence number前面,因而没有write contention。此外,disruptor使用memory barrier通知数据的更新
Memory barrier 内存屏障
CPU认为逻辑上没有冲突的instruction可以reorder。写操作需要花很多时间,可以在schedule pipeline比较方便的时候把instruction插进去。比如core 1需要写a,b,c,d。因为这四个variable之间没有关系,它们的顺序也是可以打乱的。在disruptor中并不直接把它们写入cache中,而是写入core和cache直接的一个store buffer里,在store buffer里四个variable是reorder的。

单线程下没有任何问题,但是多线程时,core 2角度来看,c先被写,然后是d,a,b。在disruptor里producer最后update cursor里的sequence number,告诉大家这个entry已经ready,所有的consumer可以读它。但是如果写entry的顺序和写sequence number的顺序不一致,会造成一种现象:sequence number的写已经完成,consumber可以去读对应数据,但是对应的entry的写还没有ready。

在java里用volatile字段修饰。CPU在执行时,遇到这个字段把store barrier里的数据清空。
在大部分情况下,consumer是跟在producer后面的。disruptor比较理想的情况就是一个producer,多个consumer。

如果涉及到多个producer,也不需要lock。每个时刻只有一个thread可以increment这个数,保证只有一个producer能更新sequence number,实现atomicity。这里面使用了一个producer barrier类,里面有很多method做具体的实现。
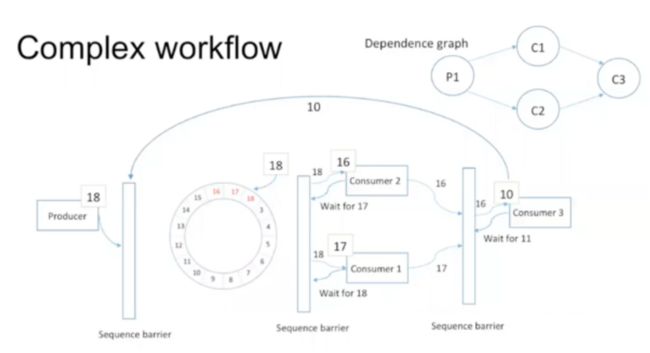
Ref:https://www.zhihu.com/question/23235063