编译:张雪娇 (中山大学)
Stata 连享会: 知乎 | | 码云 | CSDN
连享会计量方法专题……
前期相关推文
- 二元选择模型:Probit 还是 Logit ?
- Stata: Logit 模型简介
原文:Logit 模型评介: Logit 模型的好处
Source 1: In Defense of Logit-Part 1
Source 2: In Defense of Logit-Part 2
在最近的一篇 博文 中,Paul von Hippel 对他之前关于线性概率模型的论点进行了扩展,他认为:在很多情况下,线性概率模型(通过普通最小二乘估计)比 Logit 回归模型更可取。并且在他发表的两篇文章中,von Hippel 提出了以下三个要点:
- 在 0.20 到 0.80 的预测概率区间内,线性概率模型与 Logit 模型非常相近。即使在这个范围之外,如果区间很窄线性概率模型也可能做得很好。
- 相对于概率函数比来说,人们更容易理解概率变化之比例。
- OLS 回归比 Logit 回归运行快得多。
虽然我同意他的这些观点但是在绝大多数实际应用中,我依旧更喜欢使用Logit回归。在我2015年4月的文章中,我讨论了逻辑回归的一些特性,正因为这些特性使得它比其他非线性替代方法(如 probit 或互补对数)更具吸引力。但我没有将逻辑模型与线性概率模型进行比较。下面是我对 von Hippel 论点的看法,以及我为什么更喜欢 Logit 回归的原因。
1. Logit 模型的优点
1.1 速度
线性回归采用的最小二乘估计确实比逻辑回归的极大似然估计要快。然而考虑到当今计算机的能力,即使有一百万或更多的观测值,这种运算差异对于一个二元 Logit 回归来都是是不显著的。正如 von Hippel 所指出的,只有当你用随机效应、固定效应,空间或纵向相关性来估算一个模型时,差异才真正变得重要。
如果你正在进行有放回的重复抽样,多元运算或者你正在对一群混合变量使用某种强度变数筛选方法有时当结合 K-折交叉验证 时,速度才会很重要。在这类应用中,使用线性回归进行前期工作可能非常有用。但有一个风险是线性回归可能会发现 Logit 模型中并不需要的相互作用(或其他非线性影响作用)。(具体参见下面不变性的部分)
1.2 预测概率
即使你真的不喜欢优势比,Logit 模型在预测概率方面也有一个众所周知的优势。正如 von Hippel 提醒我们的,当你用 1-0 结果估计线性回归时,预测值可能大于1或小于0,这显然意味着它们不能被解释为概率。即使绝大多数例子中模型给出的预测概率都在他建议的0.20到0.80的范围内,但这种超出 1-0 边界的情况经常也发生。
然而在许多应用中,这不是一个问题,因为你真正感兴趣的并不是这些概率。而是获得有效的概率预测。例如,你想给骨质疏松的症患者一个未来五年髋部骨折概率的估计,你不会想告诉他们是 1.05 。即使线性概率模型只产生有界预测,概率也可以用 logistic 进行更精确地估计。
1.3 可解释性
von Hippel 说,对大多数研究人员来说,概率差异比优势比更直观,这无疑是正确的。但从某种程度上来看这仅仅是因为我们最习惯拿概率作为衡量某件事发生可能性的一个指标。
在 von Hippel 的例子中,“困难”来自于将几率到概率的转换。但概率本身并没有什么神圣的。几率是对事件发生概率的合理度量,我相信只要稍加训练,大多数人都能习惯几率测度。
以下是我对某一年患感冒的可能性的思考。如果几率是2,这意味着对于所有没感冒的人里就会有2个人感冒。如果几率增加到4,意味着所有不感冒的人中有4个人会感冒,这是几率的两倍,也就是说,优势比为2。另一方面,如果几率是1/3,那么每三个不感冒的人中就有一个人感冒。如果我们把几率翻两番,那么每3个不感冒的人中就有4个人感冒。更一般地说,与没有发生事件的个人相比,如果事件发生的几率增加了某个确定的百分比,那么个人对事件发生的数量预期也将增加该百分比。
几率的一个主要吸引力是它促进了乘法比较,这是因为优势比是没有上限的。如果我在下一次总统选举中投票的概率是.6,那么你的投票概率是我的两倍是不可能的。但是你的投票几率很容易是我的2、4或10倍。即使你非常喜欢概率,一旦你估计了一个 Logit 回归模型,你就可以很容易地得到用概率表示的效果估计。Stata 通过它的“页边距”命令可以特别容易的实现这一点,我将在下一节中演示这一点。
1.4 不变性
归根结底,我最喜欢 Logit 模型的原因是,对于二分法结果,有充分的理由期望优势比在时间、空间和总体上比线性回归的系数更稳定。这就是为什么对于连续的概率进行预测时,我们知道线性概率模型不可能是产生二分结果机制的“真实”描述。这是因为线性模型的外延推断会产生大于1或小于0的概率。真正的关系一定是S形曲线,虽然不一定是 Logit 关系但会是类似 Logit 的关系。
由于线性概率模型不考虑曲率,线性最小二乘法产生的斜率将取决于大部分数据在曲线上的位置。在 1 或 0 附近有一个较小的斜率,在 0.50 附近有一个较大的斜率。但是即使基本的机制保持不变,事件发生的总概率在不同情况下也会有很大的变化。
这一问题也适用于进行分类预测。考虑一个二分法的 y 和一个二分法的预测因子 x ,它们之间的关系完全可以用一个 2 x 2 的频率计数表来描述。众所周知,对该表的任何行或任何列乘以一个大于零的常数,优势比不变。因此,任何一个变量的边际分布都可以在不改变优势比的情况下发生实质性变化。这不是“两个比例之间的差异”的情况,这相当于 Y 对 x 回归 的 OLS 系数。
2. 基于 NHANES 数据 的 Stata 例证
对于产生了二分结果的线性回归来说,它很可能为线性回归中的交互作用不是“真实的”,或者逻辑回归中不需要这种交互作用提供证据。下面是一个使用 国家健康和营养检查研究 (NHANES) 数据的例子。数据集可以在 Stata 网站上搜索到,命令为 findit nhanes。最终共收集到包含有主要变量在内的 10335 个完整数据案例。
2.1 Logit 回归模型估计
首先估计了以 diabetes(编码 1 或 0)为因变量的一个 Logit 回归模型。预测因素包括 age (以年计)和两个虚拟(指标)变量,black 和 female。模型还包括了black * age的交互项。
用于估计模型的 Stata 代码如下:
webuse nhanes2f, clear
logistic diabetes black female age black#c.age
结果如下:
------------------------------------------------------------------------------
diabetes | Odds Ratio Std. Err. z P>|z| [95% Conf. Interval]
-------------+----------------------------------------------------------------
black | 3.318733 1.825189 2.18 0.029 1.129381 9.752231
female | 1.165212 .1098623 1.62 0.105 .9686107 1.401718
age | 1.063009 .0044723 14.52 0.000 1.054279 1.071811
black#c.age | .9918406 .0090871 -0.89 0.371 .9741892 1.009812
_cons | .0014978 .0003971 -24.53 0.000 .0008909 .0025183
------------------------------------------------------------------------------
如果考虑到相互作用的高p值(.371),显然没有证据显示变量 black 会随着 age 变化。
2.2 线性回归模型估计
用于估计模型的 Stata 代码如下:
reg diabetes black female age black#c.age
新结果为:
------------------------------------------------------------------------------
diabetes | Coef. Std. Err. t P>|t| [95% Conf. Interval]
-------------+----------------------------------------------------------------
black | -.0215031 .0191527 -1.12 0.262 -.0590461 .0160399
female | .0069338 .004152 1.67 0.095 -.0012049 .0150725
age | .0020176 .0001276 15.82 0.000 .0017675 .0022676
black#c.age | .0012962 .0003883 3.34 0.001 .0005351 .0020573
_cons | -.0553238 .0068085 -8.13 0.000 -.0686697 -.0419779
------------------------------------------------------------------------------
现在我们有了强有力的证据来证明交互作用,特别是 black 对高年龄的人的影响更大。black 的隐含系数从 20 岁时的 0.004(样本中的最低年龄)增加到 74 岁时的 0.074(样本中的最高年龄)。这个巨大增长充分说明 black 对高年龄的人的影响作用并不仅仅是由于样本量大导致的。
2.3 结果分析
- 糖尿病的总发病率随着年龄的增长而显著增加。当总体比率较低时,黑人和非黑人的概率差异较小。当总比率接近0.50时,Logit 曲线上最陡点的概率差异变大而优势比保持不变。
- 线性模型和逻辑模型之间差异的实质性影响往往是至关重要的。“糖尿病对黑人的不利地位随着年龄的增长而显著增加”和“糖尿病对黑人的不利地位在所有年龄都基本相同”是完全不同的。基于当前数据,我将采用第二种说法。
- 对于线性模型来说,概率变化太大时不可能是一个好的近似值。但最重要的一点是,对于二分法结果,Logit 回归模型往往比线性回归模型更为简洁。从逻辑回归模型中得到的定量估计在经历很大变化的情况下可能会更稳定。
3. 基于 Logit 模型的边际效应测度
依旧延用之前 NHANES 数据集。(数据集在 Stata 网站上是公开,可以在 Stata 会话中直接从 Internet 进行访问)。
3.1 边际效应 i.varname
首先以 diabetes(编码 1 或 0)为因变量进行 Logit 回归,预测因素包括 age(以年计)和两个虚拟(指标)变量,black 和 female 。
- 用于估计模型的 Stata 代码如下:
webuse nhanes2f, clear
logistic diabetes i.black i.female age
- 注意:
i.blacki.female前面的i的作用是向 Stata 声明把这些作为分类(因子)变量。通常情况下,这种方法对于二元回归因子是没有必要的,但重点是这种声明方法是计算边际效应的最佳方式。
- 回归结果如下:
------------------------------------------------------------------------------
diabetes | Odds Ratio Std. Err. z P>|z| [95% Conf. Interval]
-------------+----------------------------------------------------------------
1.black | 2.050133 .2599694 5.66 0.000 1.598985 2.62857
1.female | 1.167141 .1100592 1.64 0.101 .9701892 1.404074
age | 1.061269 .003962 15.93 0.000 1.053532 1.069063
_cons | .0016525 .000392 -27.00 0.000 .0010381 .0026307
------------------------------------------------------------------------------
- 结论:
- 黑人患糖尿病的几率是非黑人的两倍,这是一个非常显著的“效应”。
- 女性患糖尿病的几率比男性高17%,但这并没有统计学意义。
- 年龄每增长一岁,糖尿病的几率就会显著地增加 6% 。
3.2 平均边际效应(AME) margins
现在假设我们想估计每个变量对糖尿病发生概率的影响,而不是糖尿病发生概率的影响。
- 用于估计模型的 Stata 代码如下:
margins, dydx(black female age)
- 注意:
margins是用于边际均值、预测边际和边际效应的测度命令
- 回归结果如下:
------------------------------------------------------------------------------
| Delta-method
| dy/dx Std. Err. z P>|z| [95% Conf. Interval]
-------------+----------------------------------------------------------------
1.black | .0400922 .0087055 4.61 0.000 .0230297 .0571547
1.female | .0067987 .0041282 1.65 0.100 -.0012924 .0148898
age | .0026287 .0001869 14.06 0.000 .0022623 .0029951
------------------------------------------------------------------------------
- 结论:
- dy/dx 列给出了每一个预测因子增加1单位时糖尿病发生的预测概率变化。例如,黑人糖尿病的预测概率平均比非黑人高0.04。
- AME 估计原理:保持所有其他的预测变量不变,对于每个不同的个体在 black=1 和 black=0 条件下计算计算这两个概率之间的差异,然后再所有人进行平均。
3.3 平均值的边际效应(MEM)margins
用于估计模型的 Stata 代码如下:
margins, dydx(black female age) atmeans
- 注意:
1.平均值的边际效应(MEM):保持其他两个预测因子的平均值不变,对 black计算当black=1和black=0时预测概率之间的差异。
- MEM的计算只需要模型估计值,而 AME 则需要对单个观测值进行操作。
- 回归结果如下:
------------------------------------------------------------------------------
| Delta-method
| dy/dx Std. Err. z P>|z| [95% Conf. Interval]
-------------+----------------------------------------------------------------
1.black | .0290993 .0066198 4.40 0.000 .0161246 .0420739
1.female | .0047259 .0028785 1.64 0.101 -.0009158 .0103677
age | .0018234 .0000877 20.80 0.000 .0016516 .0019953
------------------------------------------------------------------------------
- 结论:
1.黑人的MEM明显小于其AME。这是模型本身具有的非线性结果,特别是在概率尺度(AME)上的平均值通常不会产生与 Logit 尺度(MEM)上的平均值相同。
2.逻辑模型的非线性表明,我们应该考虑不同条件下的边际效应。Williams(others)将其称为代表值的边际效应。
3.4 不同的年龄段黑人(AME)margins
- 用于估计模型的 Stata 代码如下:
margins, dydx(black) at(age=(20 35 50 65))
- 回归结果如下:
margins, dydx(black) at(age=(20 35 50 65))
1._at : age = 20
2._at : age = 35
3._at : age = 50
4._at : age = 65
------------------------------------------------------------------------------
| Delta-method
| dy/dx Std. Err. z P>|z| [95% Conf. Interval]
-------------+----------------------------------------------------------------
1.black |
_at |
1 | .0060899 .0016303 3.74 0.000 .0028946 .0092852
2 | .0144831 .0035013 4.14 0.000 .0076207 .0213455
3 | .0332459 .0074944 4.44 0.000 .018557 .0479347
4 | .0704719 .015273 4.61 0.000 .0405374 .1004065
------------------------------------------------------------------------------
结论:
20岁时黑人的 AME 很小(0.006),但65岁时变大(0.070)。但是这不应该被认为是一种交互作用,因为模型表明在所有年龄段对数概率(logit)的影响是相同的。
4. 基于线性概率模型的估计
依据 Von Hippel 的建议,我们绘制对数概率与预测概率范围的关系图,并检查图是否近似线性,再对数据进行回归。
4.1 预测概率及其范围的估计
Stata 代码如下:
predict yhat
sum yhat
注意:
predict预测命令生成d的预测概率将其存储在变量 yhat 中sum命令为 yhat 生成描述性统计信息,包括最小值和最大值。这里,最小值为0.005,最大值为0.244。
4.2 对数概率与预测概率范围的关系图
Stata 代码如下:
twoway function y=ln(x/(1-x)), range(.005 .244) ///
xtitle("Probability") ytitle("Log odds")
sum yhat
图形如下:
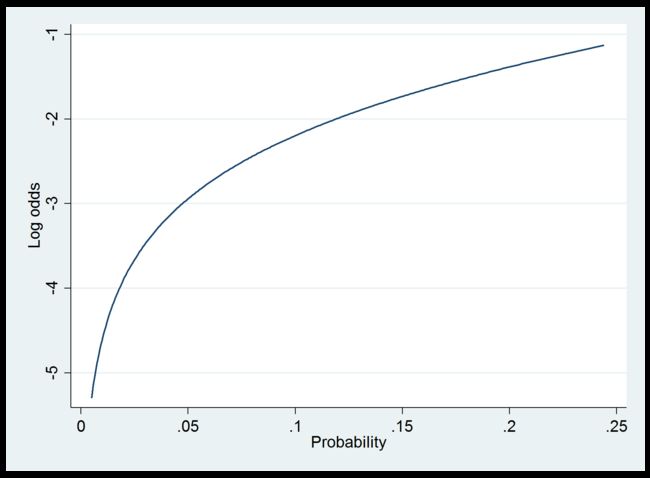
显然,此时图像呈现的对数概率与预测概率范围的关系与线性关系有很大的偏离。
4.3 线性概率模型估计
Stata 代码如下:
reg diabetes black female age, robust
注意:
- 虽然我使用了稳健的标准误来处理可能出现的异方差情况,但是无论是否有稳健标准误的情况下 t 统计量几乎都是相同的。
回归结果如下:
------------------------------------------------------------------------------
| Robust
diabetes | Coef. Std. Err. t P>|t| [95% Conf. Interval]
-------------+----------------------------------------------------------------
black | .0383148 .008328 4.60 0.000 .0219902 .0546393
female | .0068601 .0041382 1.66 0.097 -.0012515 .0149716
age | .0021575 .0001214 17.76 0.000 .0019194 .0023955
_cons | -.0619671 .0049469 -12.53 0.000 -.0716639 -.0522703
------------------------------------------------------------------------------
注意:
- 这里的 t 统计量非常接近 Logit 回归中的 z 统计量,并且系数本身与上面显示的 AME 非常相似。
- 该线性概率模型不能揭示黑人患糖尿病的概率是如何随年龄不同而变化的。若想获得具体的变化信息就必须显式地将这些变量的交互项构建到模型中。
5. 结论
- 将 Logit 回归与
margin命令结合起来,可以让你获得最佳的估计效果。这种结合的方式下得到的模型可能比单纯的线性回归模型更加准确。因为它产生的预测概率总是落在允许的范围内,并且该模型的参数即使在变化的条件下也会趋于稳定。 - 除此之外,你也可以得到易于解释的概率数值估计,并且可以具体观测到这些基于概率的估计值在不同的条件下是如何变化的。
参考文献
- Paul, v. H. (2017, MARCH 8) When Can You Fit a Linear Probability Model? More Often Than You Think. Statistical Horizons Website. Retrieved May 6, 2019,from https://statisticalhorizons.com/when-can-you-fit
- Cross Validation. Carnegie Mellon University. From https://www.cs.cmu.edu/~schneide/tut5/node42.html
- Williams, Richard. "Using the margins command to estimate and interpret adjusted predictions and marginal effects." The Stata Journal 12.2 (2012): 308-331.[PDF]

关于我们
- 【Stata 连享会(公众号:StataChina)】由中山大学连玉君老师团队创办,旨在定期与大家分享 Stata 应用的各种经验和技巧。
- 公众号推文同步发布于 CSDN-Stata连享会 、-Stata连享会 和 知乎-连玉君Stata专栏。可以在上述网站中搜索关键词
Stata或Stata连享会后关注我们。 - 点击推文底部【阅读原文】可以查看推文中的链接并下载相关资料。
- Stata连享会 精品专题 || 精彩推文
联系我们
- 欢迎赐稿: 欢迎将您的文章或笔记投稿至
Stata连享会(公众号: StataChina),我们会保留您的署名;录用稿件达五篇以上,即可免费获得 Stata 现场培训 (初级或高级选其一) 资格。 - 意见和资料: 欢迎您的宝贵意见,您也可以来信索取推文中提及的程序和数据。
- 招募英才: 欢迎加入我们的团队,一起学习 Stata。合作编辑或撰写稿件五篇以上,即可免费获得 Stata 现场培训 (初级或高级选其一) 资格。
- 联系邮件: [email protected]
往期精彩推文
- Stata连享会推文列表
- Stata连享会 精品专题 || 精彩推文

