mybatis 3.x源码深度解析与最佳实践
html版离线文件可从https://files.cnblogs.com/files/zhjh256/mybatis3.x%E6%BA%90%E7%A0%81%E6%B7%B1%E5%BA%A6%E8%A7%A3%E6%9E%90%E4%B8%8E%E6%9C%80%E4%BD%B3%E5%AE%9E%E8%B7%B5.rar下载。
-
- 1 环境准备
- 1.1 mybatis介绍以及框架源码的学习目标
- 1.2 本系列源码解析的方式
- 1.3 环境搭建
- 1.4 从Hello World开始
- 2 容器的加载与初始化
- 2.1 config文件解析XMLConfigBuilder.parseConfiguration
- 2.1.1 属性解析propertiesElement
- 2.1.2 加载settings节点settingsAsProperties
- 2.1.3 加载自定义VFS loadCustomVfs
- 2.1.4 解析类型别名typeAliasesElement
- 2.1.5 加载插件pluginElement
- 2.1.6 加载对象工厂objectFactoryElement
- 2.1.7 创建对象包装器工厂objectWrapperFactoryElement
- 2.1.8 加载反射工厂reflectorFactoryElement
- 2.1.9 加载环境配置environmentsElement
- 2.1.10 数据库厂商标识加载databaseIdProviderElement
- 2.1.11 加载类型处理器typeHandlerElement
- 处理枚举类型映射
- 2.1.12 加载mapper文件mapperElement
- 2.2 mapper加载与初始化
- 2.3 解析mapper文件XMLMapperBuilder
- 2.3.1 鉴别器discriminator的解析
- 解析SQL主体
- sql语句解析的核心:mybatis语言驱动器XMLLanguageDriver
- IfHandler
- OtherwiseHandler
- BindHandler
- ChooseHandler
- ForEachHandler
- SetHandler
- TrimHandler
- WhereHandler
- 静态SQL创建RawSqlSource
- 动态SQL创建 DynamicSqlSource
- 4、二次解析未完成的结果映射、缓存参照、CRUD语句;
- 2.1 config文件解析XMLConfigBuilder.parseConfiguration
- 3 关键对象总结与回顾
- 3.1 SqlSource
- 3.2 SqlNode
- ChooseSqlNode
- ForEachSqlNode
- IfSqlNode
- StaticTextSqlNode
- TextSqlNode
- VarDeclSqlNode
- TrimSqlNode
- SetSqlNode
- WhereSqlNode
- 3.3 BaseBuilder
- 3.4 AdditionalParameter
- 3.5 TypeHandler
- 3.6 对象包装器工厂ObjectWrapperFactory
- 3.7 MetaObject
- 3.8 对象工厂ObjectFactory
- 3.13 LanguageDriver
- 3.14 ResultMap
- 3.15 ResultMapping
- 3.16 Discriminator
- 4 SQL语句的执行流程
- 4.1 传统JDBC用法
- 4.2 mybatis执行SQL语句
- 4.2.1 获取openSession
- 4.2.2 sql语句执行方式一
- mybatis结果集处理
- selectMap实现
- update/insert/delete实现
- 4.2.3 SQL语句执行方式二 SqlSession.getMapper实现
- 4.3 动态sql
- 4.4 存储过程与函数调用实现
- 4.5 mybatis事务实现
- 4.6 缓存
- 5 执行期主要类总结
- 5.1 执行器Executor
- 5.4.1 SIMPLE执行器
- 5.4.2 REUSE执行器
- 5.4.3 BATCH执行器
- 5.4.4 缓存执行器CachingExecutor的实现
- 5.2 参数处理器ParameterHandler
- 5.3 语句处理器StatementHandler
- 5.4 结果集处理器ResultSetHandler
- 5.1 执行器Executor
- 6 插件
- 6.1 分页插件PageHelper详解
- 6.2 自定义监控插件StatHelper实现
- 7 与spring集成
- 1 环境准备
1 环境准备
1.1 mybatis介绍以及框架源码的学习目标
MyBatis是当前最流行的java持久层框架之一,其通过XML配置的方式消除了绝大部分JDBC重复代码以及参数的设置,结果集的映射。虽然mybatis是最为流行的持久层框架之一,但是相比其他开源框架比如spring/netty的源码来说,其注释相对而言显得比较少。为了更好地学习和理解mybatis背后的设计思路,作为高级开发人员,有必要深入研究了解优秀框架的源码,以便更好的借鉴其思想。同时,框架作为设计模式的主要应用场景,通过研究优秀框架的源码,可以更好的领会设计模式的精髓。学习框架源码和学习框架本身不同,我们不仅要首先比较细致完整的熟悉框架提供的每个特性,还要理解框架本身的初始化过程等,除此之外,更重要的是,我们不能泛泛的快速浏览哪个功能是通过哪个类或者接口实现和封装的,对于核心特性和初始化过程的实现,我们应该达到下列目标:
- 对于核心特性和内部功能,具体是如何实现的,采用什么数据结构,边研究边思考这么做是否合理,或者不合理,尤其是很多的特性和功能的调用频率是很低的,或者很多集合中包含的元素数量在99%以上的情况下都是1,这种情况下很多设计决定并不需要特别去选择或者适合于大数据量或者高并发的复杂实现。对于很多内部的数据结构和辅助方法,不仅需要知道其功能本身,还需要知道他们在上下文中发挥的作用。
- 对于核心特性和内部功能,具体实现采用了哪些设计模式,使用这个设计模式的合理性;
- 绝大部分框架都被设计为可扩展的,mybatis也不例外,它提供了很多的扩展点,比如最常用的插件,语言驱动器,执行器,对象工厂,对象包装器工厂等等都可以扩展,所以,我们应该知道如有必要的话,如何按照要求进行扩展以满足自己的需求;
1.2 本系列源码解析的方式
首先,和从使用层面相同,我们在理解实现细节的时候,也会涉及到学习A的时候,引用到B中的部分概念,B又引用了C的部分概念,C反过来又依赖于D接口和A的相关接口操作,D又有很多不同的具体实现。在使用层面,我们通常不需要深入去理解B的具体实现,只要知道B的概念和可以提供什么特性就可以了。在实现层面,我们必须去全部掌握这所有依赖的实现,直到最底层JDK原生操作或者某些我们熟悉的类库为止。这实际上涉及到横向流程和纵向切面的交叉引用,以及两个概念的接口和多种实现之间的交叉调用。所以,我们在整个系列中会先按照业务流程横向的方式进行整体分析,并附上必要的流程图,在整个大流程完成之后,在一个专门的章节安排对关键的类进行详细分析,它们的适用场景,这样就可以交叉引用,又不会在主流程中夹杂太多的干扰内容。
其次,因为我们免不了会对源码的主要部分做必要的注释,所以,对源码的讲解和注释会穿插进行,对于某些部分通过注释后已经完全能够知道其含义的实现,就不会在多此一举的重述。
1.3 环境搭建
从https://github.com/mybatis/mybatis-3下载mybatis 3源代码,导入eclipse工程,执行maven clean install,本书所使用的mybatis版本是3.4.6-SNAPSHOT,编写时的最新版本,读者如果使用其他版本,可能代码上会有细微差别,但其基本不影响我们对主要核心代码的分析。为了更好地理解mybatis的核心实现,我们需要创建一个演示工程mybatis-internal-example,读者可从github上下载,并将依赖的mybatis坐标改成mybatis-3.4.6-SNAPSHOT。
1.4 从Hello World开始
要理解mybatis的内部原理,最好的方式是直接从头开始,而不是从和spring的集成开始。每一个MyBatis的应用程序都以一个SqlSessionFactory对象的实例为核心。SqlSessionFactory对象的实例可以又通过SqlSessionFactoryBuilder对象来获得。SqlSessionFactoryBuilder对象可以从XML配置文件加载配置信息,然后创建SqlSessionFactory。先看下面的例子:
主程序:
package org.mybatis.internal.example;
import java.io.IOException;
import java.io.Reader;
import org.apache.ibatis.io.Resources;
import org.apache.ibatis.session.SqlSession;
import org.apache.ibatis.session.SqlSessionFactory;
import org.apache.ibatis.session.SqlSessionFactoryBuilder;
import org.mybatis.internal.example.pojo.User;
public class MybatisHelloWorld {
public static void main(String[] args) {
String resource = "org/mybatis/internal/example/Configuration.xml";
Reader reader;
try {
reader = Resources.getResourceAsReader(resource);
SqlSessionFactory sqlMapper = new SqlSessionFactoryBuilder().build(reader);
SqlSession session = sqlMapper.openSession();
try {
User user = (User) session.selectOne("org.mybatis.internal.example.mapper.UserMapper.getUser", 1);
System.out.println(user.getLfPartyId() + "," + user.getPartyName());
} finally {
session.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
配置文件:
mapper文件
mapper接口
package org.mybatis.internal.example.mapper;
import org.mybatis.internal.example.pojo.User;
public interface UserMapper {
public User getUser(int lfPartyId);
}
运行上述程序,不出意外的话,将输出:
1,汇金超级管理员
从上述代码可以看出,SqlSessionFactoryBuilder是一个关键的入口类,其中承担了mybatis配置文件的加载,解析,内部构建等职责。下一章,我们将重点分析mybatis配置文件的加载,配置类的构建等一系列细节。
2 容器的加载与初始化
SqlSessionFactory是通过SqlSessionFactoryBuilder工厂类创建的,而不是直接使用构造器。容器的配置文件加载和初始化流程如下: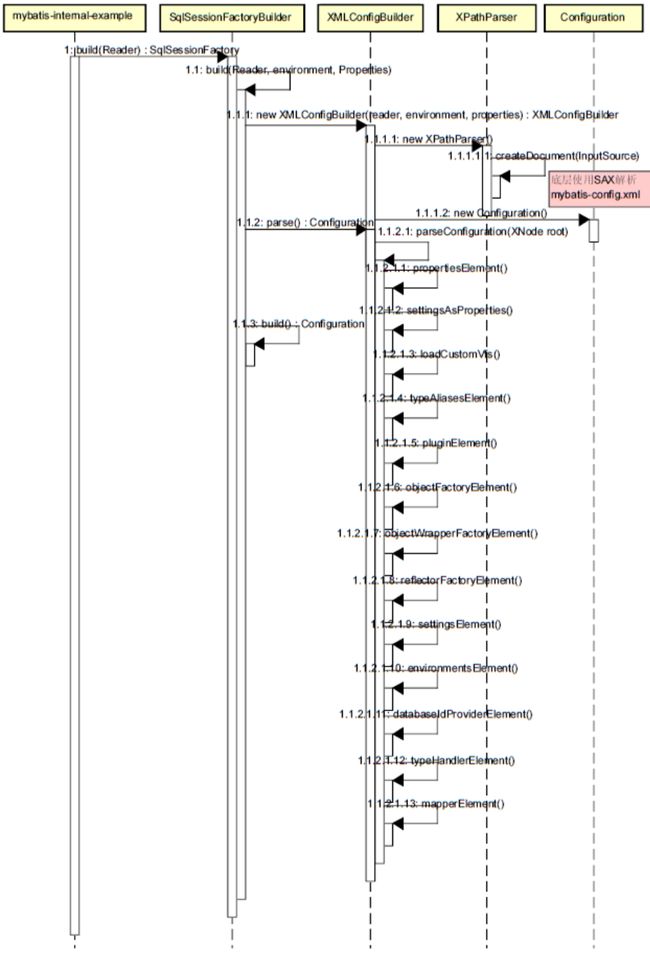
SqlSessionFactoryBuilder的主要代码如下:
public class SqlSessionFactoryBuilder {
// 使用java.io.Reader构建
public SqlSessionFactory build(Reader reader) {
return build(reader, null, null);
}
public SqlSessionFactory build(Reader reader, String environment) {
return build(reader, environment, null);
}
public SqlSessionFactory build(Reader reader, Properties properties) {
return build(reader, null, properties);
}
public SqlSessionFactory build(Reader reader, String environment, Properties properties) {
try {
XMLConfigBuilder parser = new XMLConfigBuilder(reader, environment, properties);
return build(parser.parse());
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error building SqlSession.", e);
} finally {
ErrorContext.instance().reset();
try {
reader.close();
} catch (IOException e) {
// Intentionally ignore. Prefer previous error.
}
}
}
public SqlSessionFactory build(InputStream inputStream) {
return build(inputStream, null, null);
}
public SqlSessionFactory build(InputStream inputStream, String environment) {
return build(inputStream, environment, null);
}
public SqlSessionFactory build(InputStream inputStream, Properties properties) {
return build(inputStream, null, properties);
}
public SqlSessionFactory build(InputStream inputStream, String environment, Properties properties) {
try {
XMLConfigBuilder parser = new XMLConfigBuilder(inputStream, environment, properties);
return build(parser.parse());
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error building SqlSession.", e);
} finally {
ErrorContext.instance().reset();
try {
inputStream.close();
} catch (IOException e) {
// Intentionally ignore. Prefer previous error.
}
}
}
public SqlSessionFactory build(Configuration config) {
return new DefaultSqlSessionFactory(config);
}
根据上述接口可知,SqlSessionFactory提供了根据字节流、字符流以及直接使用org.apache.ibatis.session.Configuration配置类(后续我们会详细讲到)三种途径的读取配置信息方式,无论是字符流还是字节流方式,首先都是将XML配置文件构建为Configuration配置类,然后将Configuration设置到SqlSessionFactory默认实现DefaultSqlSessionFactory的configurationz字段并返回。所以,它本身很简单,解析配置文件的关键逻辑都委托给XMLConfigBuilder了,我们以字符流也就是java.io.Reader为例进行分析,SqlSessionFactoryBuilder使用了XMLConfigBuilder作为解析器。
public class XMLConfigBuilder extends BaseBuilder {
private boolean parsed;
private XPathParser parser;
private String environment;
private ReflectorFactory localReflectorFactory = new DefaultReflectorFactory();
....
public XMLConfigBuilder(Reader reader, String environment, Properties props) {
this(new XPathParser(reader, true, props, new XMLMapperEntityResolver()), environment, props);
}
....
XMLConfigBuilder以及解析Mapper文件的XMLMapperBuilder都继承于BaseBuilder。他们对于XML文件本身技术上的加载和解析都委托给了XPathParser,最终用的是jdk自带的xml解析器而非第三方比如dom4j,底层使用了xpath方式进行节点解析。new XPathParser(reader, true, props, new XMLMapperEntityResolver())的参数含义分别是Reader,是否进行DTD 校验,属性配置,XML实体节点解析器。
entityResolver比较好理解,跟Spring的XML标签解析器一样,有默认的解析器,也有自定义的比如tx,dubbo等,主要使用了策略模式,在这里mybatis硬编码为了XMLMapperEntityResolver。
XMLMapperEntityResolver的定义如下:
public class XMLMapperEntityResolver implements EntityResolver {
private static final String IBATIS_CONFIG_SYSTEM = "ibatis-3-config.dtd";
private static final String IBATIS_MAPPER_SYSTEM = "ibatis-3-mapper.dtd";
private static final String MYBATIS_CONFIG_SYSTEM = "mybatis-3-config.dtd";
private static final String MYBATIS_MAPPER_SYSTEM = "mybatis-3-mapper.dtd";
private static final String MYBATIS_CONFIG_DTD = "org/apache/ibatis/builder/xml/mybatis-3-config.dtd";
private static final String MYBATIS_MAPPER_DTD = "org/apache/ibatis/builder/xml/mybatis-3-mapper.dtd";
/*
* Converts a public DTD into a local one
* 将公共的DTD转换为本地模式
*
* @param publicId The public id that is what comes after "PUBLIC"
* @param systemId The system id that is what comes after the public id.
* @return The InputSource for the DTD
*
* @throws org.xml.sax.SAXException If anything goes wrong
*/
@Override
public InputSource resolveEntity(String publicId, String systemId) throws SAXException {
try {
if (systemId != null) {
String lowerCaseSystemId = systemId.toLowerCase(Locale.ENGLISH);
if (lowerCaseSystemId.contains(MYBATIS_CONFIG_SYSTEM) || lowerCaseSystemId.contains(IBATIS_CONFIG_SYSTEM)) {
return getInputSource(MYBATIS_CONFIG_DTD, publicId, systemId);
} else if (lowerCaseSystemId.contains(MYBATIS_MAPPER_SYSTEM) || lowerCaseSystemId.contains(IBATIS_MAPPER_SYSTEM)) {
return getInputSource(MYBATIS_MAPPER_DTD, publicId, systemId);
}
}
return null;
} catch (Exception e) {
throw new SAXException(e.toString());
}
}
private InputSource getInputSource(String path, String publicId, String systemId) {
InputSource source = null;
if (path != null) {
try {
InputStream in = Resources.getResourceAsStream(path);
source = new InputSource(in);
source.setPublicId(publicId);
source.setSystemId(systemId);
} catch (IOException e) {
// ignore, null is ok
}
}
return source;
}
}
从上述代码可以看出,mybatis解析的时候,引用了本地的DTD文件,和本类在同一个package下,其中的ibatis-3-config.dtd应该主要是用于兼容用途。在其中getInputSource(MYBATIS_CONFIG_DTD, publicId, systemId)的调用里面有两个参数publicId(公共标识符)和systemId(系统标示符),他们是XML 1.0规范的一部分。他们的使用如下:
Hello, world!
系统标识符 “hello.dtd” 给出了此文件的 DTD 的地址(一个 URI 引用)。在mybatis中,这里指定的是mybatis-3-config.dtd和ibatis-3-config.dtd。publicId则一般从XML文档的DOCTYPE中获取,如下:
继续往下看,
public XPathParser(Reader reader, boolean validation, Properties variables, EntityResolver entityResolver) {
commonConstructor(validation, variables, entityResolver);
this.document = createDocument(new InputSource(reader));
}
private void commonConstructor(boolean validation, Properties variables, EntityResolver entityResolver) {
this.validation = validation;
this.entityResolver = entityResolver;
this.variables = variables;
XPathFactory factory = XPathFactory.newInstance();
this.xpath = factory.newXPath();
}
可知,commonConstructor并没有做什么。回过头到createDocument上,其使用了org.xml.sax.InputSource作为参数,createDocument的关键代码如下:
private Document createDocument(InputSource inputSource) {
// important: this must only be called AFTER common constructor
try {
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
factory.setValidating(validation);
//设置由本工厂创建的解析器是否支持XML命名空间 TODO 什么是XML命名空间
factory.setNamespaceAware(false);
factory.setIgnoringComments(true);
factory.setIgnoringElementContentWhitespace(false);
//设置是否将CDATA节点转换为Text节点
factory.setCoalescing(false);
//设置是否展开实体引用节点,这里应该是sql片段引用的关键
factory.setExpandEntityReferences(true);
DocumentBuilder builder = factory.newDocumentBuilder();
//设置解析mybatis xml文档节点的解析器,也就是上面的XMLMapperEntityResolver
builder.setEntityResolver(entityResolver);
builder.setErrorHandler(new ErrorHandler() {
@Override
public void error(SAXParseException exception) throws SAXException {
throw exception;
}
@Override
public void fatalError(SAXParseException exception) throws SAXException {
throw exception;
}
@Override
public void warning(SAXParseException exception) throws SAXException {
}
});
return builder.parse(inputSource);
} catch (Exception e) {
throw new BuilderException("Error creating document instance. Cause: " + e, e);
}
}
主要是根据mybatis自身需要创建一个文档解析器,然后调用parse将输入input source解析为DOM XML文档并返回。
得到XPathParser实例之后,就调用另一个使用XPathParser作为配置来源的重载构造函数了,如下:
private XMLConfigBuilder(XPathParser parser, String environment, Properties props) {
super(new Configuration());
ErrorContext.instance().resource("SQL Mapper Configuration");
this.configuration.setVariables(props);
this.parsed = false;
this.environment = environment;
this.parser = parser;
}
其中调用了父类BaseBuilder的构造器(主要是设置类型别名注册器,以及类型处理器注册器):
public abstract class BaseBuilder {
protected final Configuration configuration;
protected final TypeAliasRegistry typeAliasRegistry;
protected final TypeHandlerRegistry typeHandlerRegistry;
public BaseBuilder(Configuration configuration) {
this.configuration = configuration;
this.typeAliasRegistry = this.configuration.getTypeAliasRegistry();
this.typeHandlerRegistry = this.configuration.getTypeHandlerRegistry();
}
我们等下再来看Configuration这个核心类的关键信息,主要是xml配置文件里面的所有配置的实现表示(几乎所有的情况下都要依赖与Configuration这个类)。
设置关键配置environment以及properties文件(mybatis在这里的实现和spring的机制有些不同),最后将上面构建的XPathParser设置为XMLConfigBuilder的parser属性值。
XMLConfigBuilder创建完成之后,SqlSessionFactoryBuild调用parser.parse()创建Configuration。所有,真正Configuration构建逻辑就在XMLConfigBuilder.parse()里面,如下所示:
public class XMLConfigBuilder extends BaseBuilder {
public Configuration parse() {
if (parsed) {
throw new BuilderException("Each XMLConfigBuilder can only be used once.");
}
parsed = true;
//mybatis配置文件解析的主流程
parseConfiguration(parser.evalNode("/configuration"));
return configuration;
}
}
2.1 config文件解析XMLConfigBuilder.parseConfiguration
首先判断有没有解析过配置文件,只有没有解析过才允许解析。其中调用了parser.evalNode(“/configuration”)返回根节点的org.apache.ibatis.parsing.XNode表示,XNode里面主要把关键的节点属性和占位符变量结构化出来,后面我们再看。然后调用parseConfiguration根据mybatis的主要配置进行解析,如下所示:
private void parseConfiguration(XNode root) {
try {
//issue #117 read properties first
propertiesElement(root.evalNode("properties"));
Properties settings = settingsAsProperties(root.evalNode("settings"));
loadCustomVfs(settings);
typeAliasesElement(root.evalNode("typeAliases"));
pluginElement(root.evalNode("plugins"));
objectFactoryElement(root.evalNode("objectFactory"));
objectWrapperFactoryElement(root.evalNode("objectWrapperFactory"));
reflectorFactoryElement(root.evalNode("reflectorFactory"));
settingsElement(settings);
// read it after objectFactory and objectWrapperFactory issue #631
environmentsElement(root.evalNode("environments"));
databaseIdProviderElement(root.evalNode("databaseIdProvider"));
typeHandlerElement(root.evalNode("typeHandlers"));
mapperElement(root.evalNode("mappers"));
} catch (Exception e) {
throw new BuilderException("Error parsing SQL Mapper Configuration. Cause: " + e, e);
}
}
所有的root.evalNode底层都是调用XML DOM的evaluate()方法,根据给定的节点表达式来计算指定的 XPath 表达式,并且返回一个XPathResult对象,返回类型在Node.evalNode()方法中均被指定为NODE。
在详细解释每个节点的解析前,我们先来粗略看下mybatis-3-config.dtd的声明:
从上述DTD可知,mybatis-config文件最多有11个配置项,分别是properties?, settings?, typeAliases?, typeHandlers?, objectFactory?, objectWrapperFactory?, reflectorFactory?, plugins?, environments?, databaseIdProvider?, mappers?,但是所有的配置都是可选的,这意味着mybatis-config配置文件本身可以什么都不包含。因为所有的配置最后保存到org.apache.ibatis.session.Configuration中,所以在详细查看每块配置的解析前,我们来看下Configuration的内部完整结构:
package org.apache.ibatis.session;
...省略import
public class Configuration {
protected Environment environment;
// 允许在嵌套语句中使用分页(RowBounds)。如果允许使用则设置为false。默认为false
protected boolean safeRowBoundsEnabled;
// 允许在嵌套语句中使用分页(ResultHandler)。如果允许使用则设置为false。
protected boolean safeResultHandlerEnabled = true;
// 是否开启自动驼峰命名规则(camel case)映射,即从经典数据库列名 A_COLUMN 到经典 Java 属性名 aColumn 的类似映射。默认false
protected boolean mapUnderscoreToCamelCase;
// 当开启时,任何方法的调用都会加载该对象的所有属性。否则,每个属性会按需加载。默认值false (true in ≤3.4.1)
protected boolean aggressiveLazyLoading;
// 是否允许单一语句返回多结果集(需要兼容驱动)。
protected boolean multipleResultSetsEnabled = true;
// 允许 JDBC 支持自动生成主键,需要驱动兼容。这就是insert时获取mysql自增主键/oracle sequence的开关。注:一般来说,这是希望的结果,应该默认值为true比较合适。
protected boolean useGeneratedKeys;
// 使用列标签代替列名,一般来说,这是希望的结果
protected boolean useColumnLabel = true;
// 是否启用缓存
protected boolean cacheEnabled = true;
// 指定当结果集中值为 null 的时候是否调用映射对象的 setter(map 对象时为 put)方法,这对于有 Map.keySet() 依赖或 null 值初始化的时候是有用的。
protected boolean callSettersOnNulls;
// 允许使用方法签名中的名称作为语句参数名称。 为了使用该特性,你的工程必须采用Java 8编译,并且加上-parameters选项。(从3.4.1开始)
protected boolean useActualParamName = true;
//当返回行的所有列都是空时,MyBatis默认返回null。 当开启这个设置时,MyBatis会返回一个空实例。 请注意,它也适用于嵌套的结果集 (i.e. collectioin and association)。(从3.4.2开始) 注:这里应该拆分为两个参数比较合适, 一个用于结果集,一个用于单记录。通常来说,我们会希望结果集不是null,单记录仍然是null
protected boolean returnInstanceForEmptyRow;
// 指定 MyBatis 增加到日志名称的前缀。
protected String logPrefix;
// 指定 MyBatis 所用日志的具体实现,未指定时将自动查找。一般建议指定为slf4j或log4j
protected Class logImpl;
// 指定VFS的实现, VFS是mybatis提供的用于访问AS内资源的一个简便接口
protected Class vfsImpl;
// MyBatis 利用本地缓存机制(Local Cache)防止循环引用(circular references)和加速重复嵌套查询。 默认值为 SESSION,这种情况下会缓存一个会话中执行的所有查询。 若设置值为 STATEMENT,本地会话仅用在语句执行上,对相同 SqlSession 的不同调用将不会共享数据。
protected LocalCacheScope localCacheScope = LocalCacheScope.SESSION;
// 当没有为参数提供特定的 JDBC 类型时,为空值指定 JDBC 类型。 某些驱动需要指定列的 JDBC 类型,多数情况直接用一般类型即可,比如 NULL、VARCHAR 或 OTHER。
protected JdbcType jdbcTypeForNull = JdbcType.OTHER;
// 指定对象的哪个方法触发一次延迟加载。
protected Set lazyLoadTriggerMethods = new HashSet(Arrays.asList(new String[] { "equals", "clone", "hashCode", "toString" }));
// 设置超时时间,它决定驱动等待数据库响应的秒数。默认不超时
protected Integer defaultStatementTimeout;
// 为驱动的结果集设置默认获取数量。
protected Integer defaultFetchSize;
// SIMPLE 就是普通的执行器;REUSE 执行器会重用预处理语句(prepared statements); BATCH 执行器将重用语句并执行批量更新。
protected ExecutorType defaultExecutorType = ExecutorType.SIMPLE;
// 指定 MyBatis 应如何自动映射列到字段或属性。 NONE 表示取消自动映射;PARTIAL 只会自动映射没有定义嵌套结果集映射的结果集。 FULL 会自动映射任意复杂的结果集(无论是否嵌套)。
protected AutoMappingBehavior autoMappingBehavior = AutoMappingBehavior.PARTIAL;
// 指定发现自动映射目标未知列(或者未知属性类型)的行为。这个值应该设置为WARNING比较合适
protected AutoMappingUnknownColumnBehavior autoMappingUnknownColumnBehavior = AutoMappingUnknownColumnBehavior.NONE;
// settings下的properties属性
protected Properties variables = new Properties();
// 默认的反射器工厂,用于操作属性、构造器方便
protected ReflectorFactory reflectorFactory = new DefaultReflectorFactory();
// 对象工厂, 所有的类resultMap类都需要依赖于对象工厂来实例化
protected ObjectFactory objectFactory = new DefaultObjectFactory();
// 对象包装器工厂,主要用来在创建非原生对象,比如增加了某些监控或者特殊属性的代理类
protected ObjectWrapperFactory objectWrapperFactory = new DefaultObjectWrapperFactory();
// 延迟加载的全局开关。当开启时,所有关联对象都会延迟加载。特定关联关系中可通过设置fetchType属性来覆盖该项的开关状态。
protected boolean lazyLoadingEnabled = false;
// 指定 Mybatis 创建具有延迟加载能力的对象所用到的代理工具。MyBatis 3.3+使用JAVASSIST
protected ProxyFactory proxyFactory = new JavassistProxyFactory(); // #224 Using internal Javassist instead of OGNL
// MyBatis 可以根据不同的数据库厂商执行不同的语句,这种多厂商的支持是基于映射语句中的 databaseId 属性。
protected String databaseId;
/**
* Configuration factory class.
* Used to create Configuration for loading deserialized unread properties.
* 指定一个提供Configuration实例的类. 这个被返回的Configuration实例是用来加载被反序列化对象的懒加载属性值. 这个类必须包含一个签名方法static Configuration getConfiguration(). (从 3.2.3 版本开始)
*/
protected Class configurationFactory;
protected final MapperRegistry mapperRegistry = new MapperRegistry(this);
// mybatis插件列表
protected final InterceptorChain interceptorChain = new InterceptorChain();
protected final TypeHandlerRegistry typeHandlerRegistry = new TypeHandlerRegistry();
// 类型注册器, 用于在执行sql语句的出入参映射以及mybatis-config文件里的各种配置比如时使用简写, 后面会详细解释
protected final TypeAliasRegistry typeAliasRegistry = new TypeAliasRegistry();
protected final LanguageDriverRegistry languageRegistry = new LanguageDriverRegistry();
protected final Map mappedStatements = new StrictMap("Mapped Statements collection");
protected final Map caches = new StrictMap("Caches collection");
protected final Map resultMaps = new StrictMap("Result Maps collection");
protected final Map parameterMaps = new StrictMap("Parameter Maps collection");
protected final Map keyGenerators = new StrictMap("Key Generators collection");
protected final Set loadedResources = new HashSet();
protected final Map sqlFragments = new StrictMap("XML fragments parsed from previous mappers");
protected final Collection incompleteStatements = new LinkedList();
protected final Collection incompleteCacheRefs = new LinkedList();
protected final Collection incompleteResultMaps = new LinkedList();
protected final Collection incompleteMethods = new LinkedList();
/*
* A map holds cache-ref relationship. The key is the namespace that
* references a cache bound to another namespace and the value is the
* namespace which the actual cache is bound to.
*/
protected final Map cacheRefMap = new HashMap();
public Configuration(Environment environment) {
this();
this.environment = environment;
}
public Configuration() {
// 内置别名注册
typeAliasRegistry.registerAlias("JDBC", JdbcTransactionFactory.class);
typeAliasRegistry.registerAlias("MANAGED", ManagedTransactionFactory.class);
typeAliasRegistry.registerAlias("JNDI", JndiDataSourceFactory.class);
typeAliasRegistry.registerAlias("POOLED", PooledDataSourceFactory.class);
typeAliasRegistry.registerAlias("UNPOOLED", UnpooledDataSourceFactory.class);
typeAliasRegistry.registerAlias("PERPETUAL", PerpetualCache.class);
typeAliasRegistry.registerAlias("FIFO", FifoCache.class);
typeAliasRegistry.registerAlias("LRU", LruCache.class);
typeAliasRegistry.registerAlias("SOFT", SoftCache.class);
typeAliasRegistry.registerAlias("WEAK", WeakCache.class);
typeAliasRegistry.registerAlias("DB_VENDOR", VendorDatabaseIdProvider.class);
typeAliasRegistry.registerAlias("XML", XMLLanguageDriver.class);
typeAliasRegistry.registerAlias("RAW", RawLanguageDriver.class);
typeAliasRegistry.registerAlias("SLF4J", Slf4jImpl.class);
typeAliasRegistry.registerAlias("COMMONS_LOGGING", JakartaCommonsLoggingImpl.class);
typeAliasRegistry.registerAlias("LOG4J", Log4jImpl.class);
typeAliasRegistry.registerAlias("LOG4J2", Log4j2Impl.class);
typeAliasRegistry.registerAlias("JDK_LOGGING", Jdk14LoggingImpl.class);
typeAliasRegistry.registerAlias("STDOUT_LOGGING", StdOutImpl.class);
typeAliasRegistry.registerAlias("NO_LOGGING", NoLoggingImpl.class);
typeAliasRegistry.registerAlias("CGLIB", CglibProxyFactory.class);
typeAliasRegistry.registerAlias("JAVASSIST", JavassistProxyFactory.class);
languageRegistry.setDefaultDriverClass(XMLLanguageDriver.class);
languageRegistry.register(RawLanguageDriver.class);
}
... 省去不必要的getter/setter
public Class getVfsImpl() {
return this.vfsImpl;
}
public void setVfsImpl(Class vfsImpl) {
if (vfsImpl != null) {
this.vfsImpl = vfsImpl;
VFS.addImplClass(this.vfsImpl);
}
}
public ProxyFactory getProxyFactory() {
return proxyFactory;
}
public void setProxyFactory(ProxyFactory proxyFactory) {
if (proxyFactory == null) {
proxyFactory = new JavassistProxyFactory();
}
this.proxyFactory = proxyFactory;
}
/**
* @since 3.2.2
*/
public List getInterceptors() {
return interceptorChain.getInterceptors();
}
public LanguageDriverRegistry getLanguageRegistry() {
return languageRegistry;
}
public void setDefaultScriptingLanguage(Class driver) {
if (driver == null) {
driver = XMLLanguageDriver.class;
}
getLanguageRegistry().setDefaultDriverClass(driver);
}
public LanguageDriver getDefaultScriptingLanguageInstance() {
return languageRegistry.getDefaultDriver();
}
/** @deprecated Use {@link #getDefaultScriptingLanguageInstance()} */
@Deprecated
public LanguageDriver getDefaultScriptingLanuageInstance() {
return getDefaultScriptingLanguageInstance();
}
public MetaObject newMetaObject(Object object) {
return MetaObject.forObject(object, objectFactory, objectWrapperFactory, reflectorFactory);
}
public ParameterHandler newParameterHandler(MappedStatement mappedStatement, Object parameterObject, BoundSql boundSql) {
ParameterHandler parameterHandler = mappedStatement.getLang().createParameterHandler(mappedStatement, parameterObject, boundSql);
parameterHandler = (ParameterHandler) interceptorChain.pluginAll(parameterHandler);
return parameterHandler;
}
public ResultSetHandler newResultSetHandler(Executor executor, MappedStatement mappedStatement, RowBounds rowBounds, ParameterHandler parameterHandler,
ResultHandler resultHandler, BoundSql boundSql) {
ResultSetHandler resultSetHandler = new DefaultResultSetHandler(executor, mappedStatement, parameterHandler, resultHandler, boundSql, rowBounds);
resultSetHandler = (ResultSetHandler) interceptorChain.pluginAll(resultSetHandler);
return resultSetHandler;
}
public StatementHandler newStatementHandler(Executor executor, MappedStatement mappedStatement, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) {
StatementHandler statementHandler = new RoutingStatementHandler(executor, mappedStatement, parameterObject, rowBounds, resultHandler, boundSql);
statementHandler = (StatementHandler) interceptorChain.pluginAll(statementHandler);
return statementHandler;
}
public Executor newExecutor(Transaction transaction) {
return newExecutor(transaction, defaultExecutorType);
}
public Executor newExecutor(Transaction transaction, ExecutorType executorType) {
executorType = executorType == null ? defaultExecutorType : executorType;
executorType = executorType == null ? ExecutorType.SIMPLE : executorType;
Executor executor;
if (ExecutorType.BATCH == executorType) {
executor = new BatchExecutor(this, transaction);
} else if (ExecutorType.REUSE == executorType) {
executor = new ReuseExecutor(this, transaction);
} else {
executor = new SimpleExecutor(this, transaction);
}
if (cacheEnabled) {
executor = new CachingExecutor(executor);
}
executor = (Executor) interceptorChain.pluginAll(executor);
return executor;
}
public void addKeyGenerator(String id, KeyGenerator keyGenerator) {
keyGenerators.put(id, keyGenerator);
}
public Collection getKeyGeneratorNames() {
return keyGenerators.keySet();
}
public Collection getKeyGenerators() {
return keyGenerators.values();
}
public KeyGenerator getKeyGenerator(String id) {
return keyGenerators.get(id);
}
public boolean hasKeyGenerator(String id) {
return keyGenerators.containsKey(id);
}
public void addCache(Cache cache) {
caches.put(cache.getId(), cache);
}
public Collection getCacheNames() {
return caches.keySet();
}
public Collection getCaches() {
return caches.values();
}
public Cache getCache(String id) {
return caches.get(id);
}
public boolean hasCache(String id) {
return caches.containsKey(id);
}
public void addResultMap(ResultMap rm) {
resultMaps.put(rm.getId(), rm);
checkLocallyForDiscriminatedNestedResultMaps(rm);
checkGloballyForDiscriminatedNestedResultMaps(rm);
}
public Collection getResultMapNames() {
return resultMaps.keySet();
}
public Collection getResultMaps() {
return resultMaps.values();
}
public ResultMap getResultMap(String id) {
return resultMaps.get(id);
}
public boolean hasResultMap(String id) {
return resultMaps.containsKey(id);
}
public void addParameterMap(ParameterMap pm) {
parameterMaps.put(pm.getId(), pm);
}
public Collection getParameterMapNames() {
return parameterMaps.keySet();
}
public Collection getParameterMaps() {
return parameterMaps.values();
}
public ParameterMap getParameterMap(String id) {
return parameterMaps.get(id);
}
public boolean hasParameterMap(String id) {
return parameterMaps.containsKey(id);
}
public void addMappedStatement(MappedStatement ms) {
mappedStatements.put(ms.getId(), ms);
}
public Collection getMappedStatementNames() {
buildAllStatements();
return mappedStatements.keySet();
}
public Collection getMappedStatements() {
buildAllStatements();
return mappedStatements.values();
}
public Collection getIncompleteStatements() {
return incompleteStatements;
}
public void addIncompleteStatement(XMLStatementBuilder incompleteStatement) {
incompleteStatements.add(incompleteStatement);
}
public Collection getIncompleteCacheRefs() {
return incompleteCacheRefs;
}
public void addIncompleteCacheRef(CacheRefResolver incompleteCacheRef) {
incompleteCacheRefs.add(incompleteCacheRef);
}
public Collection getIncompleteResultMaps() {
return incompleteResultMaps;
}
public void addIncompleteResultMap(ResultMapResolver resultMapResolver) {
incompleteResultMaps.add(resultMapResolver);
}
public void addIncompleteMethod(MethodResolver builder) {
incompleteMethods.add(builder);
}
public Collection getIncompleteMethods() {
return incompleteMethods;
}
public MappedStatement getMappedStatement(String id) {
return this.getMappedStatement(id, true);
}
public MappedStatement getMappedStatement(String id, boolean validateIncompleteStatements) {
if (validateIncompleteStatements) {
buildAllStatements();
}
return mappedStatements.get(id);
}
public Map getSqlFragments() {
return sqlFragments;
}
public void addInterceptor(Interceptor interceptor) {
interceptorChain.addInterceptor(interceptor);
}
public void addMappers(String packageName, Class superType) {
mapperRegistry.addMappers(packageName, superType);
}
public void addMappers(String packageName) {
mapperRegistry.addMappers(packageName);
}
public void addMapper(Class type) {
mapperRegistry.addMapper(type);
}
public T getMapper(Class type, SqlSession sqlSession) {
return mapperRegistry.getMapper(type, sqlSession);
}
public boolean hasMapper(Class type) {
return mapperRegistry.hasMapper(type);
}
public boolean hasStatement(String statementName) {
return hasStatement(statementName, true);
}
public boolean hasStatement(String statementName, boolean validateIncompleteStatements) {
if (validateIncompleteStatements) {
buildAllStatements();
}
return mappedStatements.containsKey(statementName);
}
public void addCacheRef(String namespace, String referencedNamespace) {
cacheRefMap.put(namespace, referencedNamespace);
}
/*
* Parses all the unprocessed statement nodes in the cache. It is recommended
* to call this method once all the mappers are added as it provides fail-fast
* statement validation.
*/
protected void buildAllStatements() {
if (!incompleteResultMaps.isEmpty()) {
synchronized (incompleteResultMaps) {
// This always throws a BuilderException.
incompleteResultMaps.iterator().next().resolve();
}
}
if (!incompleteCacheRefs.isEmpty()) {
synchronized (incompleteCacheRefs) {
// This always throws a BuilderException.
incompleteCacheRefs.iterator().next().resolveCacheRef();
}
}
if (!incompleteStatements.isEmpty()) {
synchronized (incompleteStatements) {
// This always throws a BuilderException.
incompleteStatements.iterator().next().parseStatementNode();
}
}
if (!incompleteMethods.isEmpty()) {
synchronized (incompleteMethods) {
// This always throws a BuilderException.
incompleteMethods.iterator().next().resolve();
}
}
}
/*
* Extracts namespace from fully qualified statement id.
*
* @param statementId
* @return namespace or null when id does not contain period.
*/
protected String extractNamespace(String statementId) {
int lastPeriod = statementId.lastIndexOf('.');
return lastPeriod > 0 ? statementId.substring(0, lastPeriod) : null;
}
// Slow but a one time cost. A better solution is welcome.
protected void checkGloballyForDiscriminatedNestedResultMaps(ResultMap rm) {
if (rm.hasNestedResultMaps()) {
for (Map.Entry entry : resultMaps.entrySet()) {
Object value = entry.getValue();
if (value instanceof ResultMap) {
ResultMap entryResultMap = (ResultMap) value;
if (!entryResultMap.hasNestedResultMaps() && entryResultMap.getDiscriminator() != null) {
Collection discriminatedResultMapNames = entryResultMap.getDiscriminator().getDiscriminatorMap().values();
if (discriminatedResultMapNames.contains(rm.getId())) {
entryResultMap.forceNestedResultMaps();
}
}
}
}
}
}
// Slow but a one time cost. A better solution is welcome.
protected void checkLocallyForDiscriminatedNestedResultMaps(ResultMap rm) {
if (!rm.hasNestedResultMaps() && rm.getDiscriminator() != null) {
for (Map.Entry entry : rm.getDiscriminator().getDiscriminatorMap().entrySet()) {
String discriminatedResultMapName = entry.getValue();
if (hasResultMap(discriminatedResultMapName)) {
ResultMap discriminatedResultMap = resultMaps.get(discriminatedResultMapName);
if (discriminatedResultMap.hasNestedResultMaps()) {
rm.forceNestedResultMaps();
break;
}
}
}
}
}
protected static class StrictMap extends HashMap {
private static final long serialVersionUID = -4950446264854982944L;
private final String name;
public StrictMap(String name, int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);
this.name = name;
}
public StrictMap(String name, int initialCapacity) {
super(initialCapacity);
this.name = name;
}
public StrictMap(String name) {
super();
this.name = name;
}
public StrictMap(String name, Map m) {
super(m);
this.name = name;
}
@SuppressWarnings("unchecked")
public V put(String key, V value) {
if (containsKey(key)) {
throw new IllegalArgumentException(name + " already contains value for " + key);
}
if (key.contains(".")) {
final String shortKey = getShortName(key);
if (super.get(shortKey) == null) {
super.put(shortKey, value);
} else {
super.put(shortKey, (V) new Ambiguity(shortKey));
}
}
return super.put(key, value);
}
public V get(Object key) {
V value = super.get(key);
if (value == null) {
throw new IllegalArgumentException(name + " does not contain value for " + key);
}
if (value instanceof Ambiguity) {
throw new IllegalArgumentException(((Ambiguity) value).getSubject() + " is ambiguous in " + name
+ " (try using the full name including the namespace, or rename one of the entries)");
}
return value;
}
private String getShortName(String key) {
final String[] keyParts = key.split("\\.");
return keyParts[keyParts.length - 1];
}
protected static class Ambiguity {
final private String subject;
public Ambiguity(String subject) {
this.subject = subject;
}
public String getSubject() {
return subject;
}
}
}
}
mybatis中所有环境配置、resultMap集合、sql语句集合、插件列表、缓存、加载的xml列表、类型别名、类型处理器等全部都维护在Configuration中。Configuration中包含了一个内部静态类StrictMap,它继承于HashMap,对HashMap的装饰在于增加了put时防重复的处理,get时取不到值时候的异常处理,这样核心应用层就不需要额外关心各种对象异常处理,简化应用层逻辑。
从设计上来说,我们可以说Configuration并不是一个thin类(也就是仅包含了属性以及getter/setter),而是一个rich类,它对部分逻辑进行了封装便于用户直接使用,而不是让用户各自散落处理,比如addResultMap方法和getMappedStatement方法等等。
最新的完整mybatis每个配置属性含义可参考http://www.mybatis.org/mybatis-3/zh/configuration.html。
从Configuration构造器和protected final TypeAliasRegistry typeAliasRegistry = new TypeAliasRegistry();可以看出,所有我们在mybatis-config和mapper文件中使用的类似int/string/JDBC/POOLED等字面常量最终解析为具体的java类型都是在typeAliasRegistry构造器和Configuration构造器执行期间初始化的。下面我们来每块分析。
2.1.1 属性解析propertiesElement
解析properties的方法为:
propertiesElement(root.evalNode("properties"));
private void propertiesElement(XNode context) throws Exception {
if (context != null) {
// 加载property节点为property
Properties defaults = context.getChildrenAsProperties();
String resource = context.getStringAttribute("resource");
String url = context.getStringAttribute("url");
// 必须至少包含resource或者url属性之一
if (resource != null && url != null) {
throw new BuilderException("The properties element cannot specify both a URL and a resource based property file reference. Please specify one or the other.");
}
if (resource != null) {
defaults.putAll(Resources.getResourceAsProperties(resource));
} else if (url != null) {
defaults.putAll(Resources.getUrlAsProperties(url));
}
Properties vars = configuration.getVariables();
if (vars != null) {
defaults.putAll(vars);
}
parser.setVariables(defaults);
configuration.setVariables(defaults);
}
}
总体逻辑比较简单,首先加载properties节点下的property属性,比如:
然后从url或resource加载配置文件,都先和configuration.variables合并,然后赋值到XMLConfigBuilder.parser和BaseBuilder.configuration。此时开始所有的属性就可以在随后的整个配置文件中使用了。
2.1.2 加载settings节点settingsAsProperties
private Properties settingsAsProperties(XNode context) {
if (context == null) {
return new Properties();
}
Properties props = context.getChildrenAsProperties();
// Check that all settings are known to the configuration class
// 检查所有从settings加载的设置,确保它们都在Configuration定义的范围内
MetaClass metaConfig = MetaClass.forClass(Configuration.class, localReflectorFactory);
for (Object key : props.keySet()) {
if (!metaConfig.hasSetter(String.valueOf(key))) {
throw new BuilderException("The setting " + key + " is not known. Make sure you spelled it correctly (case sensitive).");
}
}
return props;
}
首先加载settings下面的setting节点为property,然后检查所有属性,确保它们都在Configuration中已定义,而非未知的设置。注:MetaClass是一个保存对象定义比如getter/setter/构造器等的元数据类,localReflectorFactory则是mybatis提供的默认反射工厂实现,这个ReflectorFactory主要采用了工厂类,其内部使用的Reflector采用了facade设计模式,简化反射的使用。如下所示:
public class MetaClass {
private ReflectorFactory reflectorFactory;
private Reflector reflector;
private MetaClass(Class type, ReflectorFactory reflectorFactory) {
this.reflectorFactory = reflectorFactory;
this.reflector = reflectorFactory.findForClass(type);
}
public static MetaClass forClass(Class type, ReflectorFactory reflectorFactory) {
return new MetaClass(type, reflectorFactory);
}
...
}
@Override
public Reflector findForClass(Class type) {
if (classCacheEnabled) {
// synchronized (type) removed see issue #461
Reflector cached = reflectorMap.get(type);
if (cached == null) {
cached = new Reflector(type);
reflectorMap.put(type, cached);
}
return cached;
} else {
return new Reflector(type);
}
}
public Reflector(Class clazz) {
type = clazz;
addDefaultConstructor(clazz);
addGetMethods(clazz);
addSetMethods(clazz);
addFields(clazz);
readablePropertyNames = getMethods.keySet().toArray(new String[getMethods.keySet().size()]);
writeablePropertyNames = setMethods.keySet().toArray(new String[setMethods.keySet().size()]);
for (String propName : readablePropertyNames) {
caseInsensitivePropertyMap.put(propName.toUpperCase(Locale.ENGLISH), propName);
}
for (String propName : writeablePropertyNames) {
caseInsensitivePropertyMap.put(propName.toUpperCase(Locale.ENGLISH), propName);
}
}
得到setting之后,调用settingsElement(Properties props)将各值赋值给configuration,同时在这里有重新设置了默认值,所有这一点很重要,configuration中的默认值不一定是真正的默认值。
2.1.3 加载自定义VFS loadCustomVfs
VFS主要用来加载容器内的各种资源,比如jar或者class文件。mybatis提供了2个实现 JBoss6VFS 和 DefaultVFS,并提供了用户扩展点,用于自定义VFS实现,加载顺序是自定义VFS实现 > 默认VFS实现 取第一个加载成功的,默认情况下会先加载JBoss6VFS,如果classpath下找不到jboss的vfs实现才会加载默认VFS实现,启动打印的日志如下:
org.apache.ibatis.io.VFS.getClass(VFS.java:111) Class not found: org.jboss.vfs.VFS
org.apache.ibatis.io.JBoss6VFS.setInvalid(JBoss6VFS.java:142) JBoss 6 VFS API is not available in this environment.
org.apache.ibatis.io.VFS.getClass(VFS.java:111) Class not found: org.jboss.vfs.VirtualFile
org.apache.ibatis.io.VFS$VFSHolder.createVFS(VFS.java:63) VFS implementation org.apache.ibatis.io.JBoss6VFS is not valid in this environment.
org.apache.ibatis.io.VFS$VFSHolder.createVFS(VFS.java:77) Using VFS adapter org.apache.ibatis.io.DefaultVFS
jboss vfs的maven仓库坐标为:
org.jboss
jboss-vfs
3.2.12.Final
找到jboss vfs实现后,输出的日志如下:
org.apache.ibatis.io.VFS$VFSHolder.createVFS(VFS.java:77) Using VFS adapter org.apache.ibatis.io.JBoss6VFS
2.1.4 解析类型别名typeAliasesElement
private void typeAliasesElement(XNode parent) {
if (parent != null) {
for (XNode child : parent.getChildren()) {
if ("package".equals(child.getName())) {
String typeAliasPackage = child.getStringAttribute("name");
configuration.getTypeAliasRegistry().registerAliases(typeAliasPackage);
} else {
String alias = child.getStringAttribute("alias");
String type = child.getStringAttribute("type");
try {
Class clazz = Resources.classForName(type);
if (alias == null) {
typeAliasRegistry.registerAlias(clazz);
} else {
typeAliasRegistry.registerAlias(alias, clazz);
}
} catch (ClassNotFoundException e) {
throw new BuilderException("Error registering typeAlias for '" + alias + "'. Cause: " + e, e);
}
}
}
}
}
从上述代码可以看出,mybatis主要提供两种类型的别名设置,具体类的别名以及包的别名设置。类型别名是为 Java 类型设置一个短的名字,存在的意义仅在于用来减少类完全限定名的冗余。
当这样配置时,Blog可以用在任何使用domain.blog.Blog的地方。设置为package之后,MyBatis 会在包名下面搜索需要的 Java Bean。如:
每一个在包 domain.blog 中的 Java Bean,在没有注解的情况下,会使用 Bean的首字母小写的非限定类名来作为它的别名。 比如 domain.blog.Author 的别名为author;若有注解,则别名为其注解值。所以所有的别名,无论是内置的还是自定义的,都一开始被保存在configuration.typeAliasRegistry中了,这样就可以确保任何时候使用别名和FQN的效果是一样的。
2.1.5 加载插件pluginElement
几乎所有优秀的框架都会预留插件体系以便扩展,mybatis调用pluginElement(root.evalNode(“plugins”));加载mybatis插件,最常用的插件应该算是分页插件PageHelper了,再比如druid连接池提供的各种监控、拦截、预发检查功能,在使用其它连接池比如dbcp的时候,在不修改连接池源码的情况下,就可以借助mybatis的插件体系实现。加载插件的实现如下:
private void pluginElement(XNode parent) throws Exception {
if (parent != null) {
for (XNode child : parent.getChildren()) {
String interceptor = child.getStringAttribute("interceptor");
Properties properties = child.getChildrenAsProperties();
//将interceptor指定的名称解析为Interceptor类型
Interceptor interceptorInstance = (Interceptor) resolveClass(interceptor).newInstance();
interceptorInstance.setProperties(properties);
configuration.addInterceptor(interceptorInstance);
}
}
}
插件在具体实现的时候,采用的是拦截器模式,要注册为mybatis插件,必须实现org.apache.ibatis.plugin.Interceptor接口,每个插件可以有自己的属性。interceptor属性值既可以完整的类名,也可以是别名,只要别名在typealias中存在即可,如果启动时无法解析,会抛出ClassNotFound异常。实例化插件后,将设置插件的属性赋值给插件实现类的属性字段。mybatis提供了两个内置的插件例子,如下所示:
我们会在第6章详细讲解自定义插件的实现。
2.1.6 加载对象工厂objectFactoryElement
什么是对象工厂?MyBatis 每次创建结果对象的新实例时,它都会使用一个对象工厂(ObjectFactory)实例来完成。 默认的对象工厂DefaultObjectFactory做的仅仅是实例化目标类,要么通过默认构造方法,要么在参数映射存在的时候通过参数构造方法来实例化。如下所示:
public class DefaultObjectFactory implements ObjectFactory, Serializable {
private static final long serialVersionUID = -8855120656740914948L;
@Override
public T create(Class type) {
return create(type, null, null);
}
@SuppressWarnings("unchecked")
@Override
public T create(Class type, List> constructorArgTypes, List 无论是创建集合类型、Map类型还是其他类型,都素hi同样的处理方式。如果想覆盖对象工厂的默认行为,则可以通过创建自己的对象工厂来实现。ObjectFactory 接口很简单,它包含两个创建用的方法,一个是处理默认构造方法的,另外一个是处理带参数的构造方法的。最后,setProperties 方法可以被用来配置 ObjectFactory,在初始化你的 ObjectFactory 实例后,objectFactory元素体中定义的属性会被传递给setProperties方法。例如:
public class ExampleObjectFactory extends DefaultObjectFactory {
public Object create(Class type) {
return super.create(type);
}
public Object create(Class type, List constructorArgTypes, List
2.1.7 创建对象包装器工厂objectWrapperFactoryElement
对象包装器工厂主要用来包装返回result对象,比如说可以用来设置某些敏感字段脱敏或者加密等。默认对象包装器工厂是DefaultObjectWrapperFactory,也就是不使用包装器工厂。既然看到包装器工厂,我们就得看下对象包装器,如下:
BeanWrapper是BaseWrapper的默认实现。其中的两个关键接口是getBeanProperty和setBeanProperty,它们是实现包装的主要位置:
private Object getBeanProperty(PropertyTokenizer prop, Object object) {
try {
Invoker method = metaClass.getGetInvoker(prop.getName());
try {
return method.invoke(object, NO_ARGUMENTS);
} catch (Throwable t) {
throw ExceptionUtil.unwrapThrowable(t);
}
} catch (RuntimeException e) {
throw e;
} catch (Throwable t) {
throw new ReflectionException("Could not get property '" + prop.getName() + "' from " + object.getClass() + ". Cause: " + t.toString(), t);
}
}
private void setBeanProperty(PropertyTokenizer prop, Object object, Object value) {
try {
Invoker method = metaClass.getSetInvoker(prop.getName());
Object[] params = {value};
try {
method.invoke(object, params);
} catch (Throwable t) {
throw ExceptionUtil.unwrapThrowable(t);
}
} catch (Throwable t) {
throw new ReflectionException("Could not set property '" + prop.getName() + "' of '" + object.getClass() + "' with value '" + value + "' Cause: " + t.toString(), t);
}
}
要实现自定义的对象包装器工厂,只要实现ObjectWrapperFactory中的两个接口hasWrapperFor和getWrapperFor即可,如下:
public class CustomBeanWrapperFactory implements ObjectWrapperFactory {
@Override
public boolean hasWrapperFor(Object object) {
if (object instanceof Author) {
return true;
} else {
return false;
}
}
@Override
public ObjectWrapper getWrapperFor(MetaObject metaObject, Object object) {
return new CustomBeanWrapper(metaObject, object);
}
}
2.1.8 加载反射工厂reflectorFactoryElement
因为加载配置文件中的各种插件类等等,为了提供更好的灵活性,mybatis支持用户自定义反射工厂,不过总体来说,用的不多,要实现反射工厂,只要实现ReflectorFactory接口即可。默认的反射工厂是DefaultReflectorFactory。一般来说,使用默认的反射工厂就可以了。
2.1.9 加载环境配置environmentsElement
环境可以说是mybatis-config配置文件中最重要的部分,它类似于spring和maven里面的profile,允许给开发、生产环境同时配置不同的environment,根据不同的环境加载不同的配置,这也是常见的做法,如果在SqlSessionFactoryBuilder调用期间没有传递使用哪个环境的话,默认会使用一个名为default”的环境。找到对应的environment之后,就可以加载事务管理器和数据源了。事务管理器和数据源类型这里都用到了类型别名,JDBC/POOLED都是在mybatis内置提供的,在Configuration构造器执行期间注册到TypeAliasRegister。
mybatis内置提供JDBC和MANAGED两种事务管理方式,前者主要用于简单JDBC模式,后者主要用于容器管理事务,一般使用JDBC事务管理方式。mybatis内置提供JNDI、POOLED、UNPOOLED三种数据源工厂,一般情况下使用POOLED数据源。
private void environmentsElement(XNode context) throws Exception {
if (context != null) {
if (environment == null) {
environment = context.getStringAttribute("default");
}
for (XNode child : context.getChildren()) {
String id = child.getStringAttribute("id");
//查找匹配的environment
if (isSpecifiedEnvironment(id)) {
// 事务配置并创建事务工厂
TransactionFactory txFactory = transactionManagerElement(child.evalNode("transactionManager"));
// 数据源配置加载并实例化数据源, 数据源是必备的
DataSourceFactory dsFactory = dataSourceElement(child.evalNode("dataSource"));
DataSource dataSource = dsFactory.getDataSource();
// 创建Environment.Builder
Environment.Builder environmentBuilder = new Environment.Builder(id)
.transactionFactory(txFactory)
.dataSource(dataSource);
configuration.setEnvironment(environmentBuilder.build());
}
}
}
}
2.1.10 数据库厂商标识加载databaseIdProviderElement
MyBatis 可以根据不同的数据库厂商执行不同的语句,这种多厂商的支持是基于映射语句中的 databaseId 属性。 MyBatis 会加载不带 databaseId 属性和带有匹配当前数据库 databaseId 属性的所有语句。 如果同时找到带有 databaseId 和不带 databaseId 的相同语句,则后者会被舍弃。 为支持多厂商特性只要像下面这样在 mybatis-config.xml 文件中加入 databaseIdProvider 即可:
这里的 DB_VENDOR 会通过 DatabaseMetaData#getDatabaseProductName() 返回的字符串进行设置。 由于通常情况下这个字符串都非常长而且相同产品的不同版本会返回不同的值,所以最好通过设置属性别名来使其变短,如下:
在有 properties 时,DB_VENDOR databaseIdProvider 的将被设置为第一个能匹配数据库产品名称的属性键对应的值,如果没有匹配的属性将会设置为 “null”。
因为每个数据库在实现的时候,getDatabaseProductName() 返回的通常并不是直接的Oracle或者MySQL,而是“Oracle (DataDirect)”,所以如果希望使用多数据库特性,一般需要实现 org.apache.ibatis.mapping.DatabaseIdProvider接口 并在 mybatis-config.xml 中注册来构建自己的 DatabaseIdProvider:
public interface DatabaseIdProvider {
void setProperties(Properties p);
String getDatabaseId(DataSource dataSource) throws SQLException;
}
典型的实现比如:
public class VendorDatabaseIdProvider implements DatabaseIdProvider {
private static final Log log = LogFactory.getLog(VendorDatabaseIdProvider.class);
private Properties properties;
@Override
public String getDatabaseId(DataSource dataSource) {
if (dataSource == null) {
throw new NullPointerException("dataSource cannot be null");
}
try {
return getDatabaseName(dataSource);
} catch (Exception e) {
log.error("Could not get a databaseId from dataSource", e);
}
return null;
}
...
private String getDatabaseName(DataSource dataSource) throws SQLException {
String productName = getDatabaseProductName(dataSource);
if (this.properties != null) {
for (Map.Entry property : properties.entrySet()) {
// 只要包含productName中包含了property名称,就算匹配,而不是使用精确匹配
if (productName.contains((String) property.getKey())) {
return (String) property.getValue();
}
}
// no match, return null
return null;
}
return productName;
}
private String getDatabaseProductName(DataSource dataSource) throws SQLException {
Connection con = null;
try {
con = dataSource.getConnection();
DatabaseMetaData metaData = con.getMetaData();
return metaData.getDatabaseProductName();
} finally {
if (con != null) {
try {
con.close();
} catch (SQLException e) {
// ignored
}
}
}
}
}
2.1.11 加载类型处理器typeHandlerElement
private void typeHandlerElement(XNode parent) throws Exception {
if (parent != null) {
for (XNode child : parent.getChildren()) {
if ("package".equals(child.getName())) {
String typeHandlerPackage = child.getStringAttribute("name");
typeHandlerRegistry.register(typeHandlerPackage);
} else {
String javaTypeName = child.getStringAttribute("javaType");
String jdbcTypeName = child.getStringAttribute("jdbcType");
String handlerTypeName = child.getStringAttribute("handler");
Class javaTypeClass = resolveClass(javaTypeName);
JdbcType jdbcType = resolveJdbcType(jdbcTypeName);
Class typeHandlerClass = resolveClass(handlerTypeName);
if (javaTypeClass != null) {
if (jdbcType == null) {
typeHandlerRegistry.register(javaTypeClass, typeHandlerClass);
} else {
typeHandlerRegistry.register(javaTypeClass, jdbcType, typeHandlerClass);
}
} else {
typeHandlerRegistry.register(typeHandlerClass);
}
}
}
}
}
无论是 MyBatis 在预处理语句(PreparedStatement)中设置一个参数时,还是从结果集中取出一个值时, 都会用类型处理器将获取的值以合适的方式转换成 Java 类型。
mybatis提供了两种方式注册类型处理器,package自动检索方式和显示定义方式。使用自动检索(autodiscovery)功能的时候,只能通过注解方式来指定 JDBC 的类型。
public void register(String packageName) {
ResolverUtil> resolverUtil = new ResolverUtil>();
resolverUtil.find(new ResolverUtil.IsA(TypeHandler.class), packageName);
Set>> handlerSet = resolverUtil.getClasses();
for (Class type : handlerSet) {
//Ignore inner classes and interfaces (including package-info.java) and abstract classes
if (!type.isAnonymousClass() && !type.isInterface() && !Modifier.isAbstract(type.getModifiers())) {
register(type);
}
}
}
为了简化使用,mybatis在初始化TypeHandlerRegistry期间,自动注册了大部分的常用的类型处理器比如字符串、数字、日期等。对于非标准的类型,用户可以自定义类型处理器来处理。要实现一个自定义类型处理器,只要实现 org.apache.ibatis.type.TypeHandler 接口, 或继承一个实用类 org.apache.ibatis.type.BaseTypeHandler, 并将它映射到一个 JDBC 类型即可。例如:
@MappedJdbcTypes(JdbcType.VARCHAR)
public class ExampleTypeHandler extends BaseTypeHandler {
@Override
public void setNonNullParameter(PreparedStatement ps, int i, String parameter, JdbcType jdbcType) throws SQLException {
ps.setString(i, parameter);
}
@Override
public String getNullableResult(ResultSet rs, String columnName) throws SQLException {
return rs.getString(columnName);
}
@Override
public String getNullableResult(ResultSet rs, int columnIndex) throws SQLException {
return rs.getString(columnIndex);
}
@Override
public String getNullableResult(CallableStatement cs, int columnIndex) throws SQLException {
return cs.getString(columnIndex);
}
}
使用这个的类型处理器将会覆盖已经存在的处理 Java 的 String 类型属性和 VARCHAR 参数及结果的类型处理器。 要注意 MyBatis 不会窥探数据库元信息来决定使用哪种类型,所以你必须在参数和结果映射中指明那是 VARCHAR 类型的字段, 以使其能够绑定到正确的类型处理器上。 这是因为:MyBatis 直到语句被执行才清楚数据类型。
通过类型处理器的泛型,MyBatis 可以得知该类型处理器处理的 Java 类型,不过这种行为可以通过两种方法改变:
- 在类型处理器的配置元素(typeHandler element)上增加一个 javaType 属性(比如:javaType=”String”);
- 在类型处理器的类上(TypeHandler class)增加一个 @MappedTypes 注解来指定与其关联的 Java 类型列表。 如果在 javaType 属性中也同时指定,则注解方式将被忽略。
可以通过两种方式来指定被关联的 JDBC 类型:
- 在类型处理器的配置元素上增加一个 jdbcType 属性(比如:jdbcType=”VARCHAR”);
- 在类型处理器的类上(TypeHandler class)增加一个 @MappedJdbcTypes 注解来指定与其关联的 JDBC 类型列表。 如果在两个位置同时指定,则注解方式将被忽略。
当决定在ResultMap中使用某一TypeHandler时,此时java类型是已知的(从结果类型中获得),但是JDBC类型是未知的。 因此Mybatis使用javaType=[TheJavaType], jdbcType=null的组合来选择一个TypeHandler。 这意味着使用@MappedJdbcTypes注解可以限制TypeHandler的范围,同时除非显示的设置,否则TypeHandler在ResultMap中将是无效的。 如果希望在ResultMap中使用TypeHandler,那么设置@MappedJdbcTypes注解的includeNullJdbcType=true即可。 然而从Mybatis 3.4.0开始,如果只有一个注册的TypeHandler来处理Java类型,那么它将是ResultMap使用Java类型时的默认值(即使没有includeNullJdbcType=true)。
还可以创建一个泛型类型处理器,它可以处理多于一个类。为达到此目的, 需要增加一个接收该类作为参数的构造器,这样在构造一个类型处理器的时候 MyBatis 就会传入一个具体的类。
public class GenericTypeHandler extends BaseTypeHandler {
private Class type;
public GenericTypeHandler(Class type) {
if (type == null) throw new IllegalArgumentException("Type argument cannot be null");
this.type = type;
}
我们映射枚举使用的EnumTypeHandler 和 EnumOrdinalTypeHandler 都是泛型类型处理器(generic TypeHandlers)。
处理枚举类型映射
若想映射枚举类型 Enum,则需要从 EnumTypeHandler 或者 EnumOrdinalTypeHandler 中选一个来使用。
比如说我们想存储取近似值时用到的舍入模式。默认情况下,MyBatis 会利用 EnumTypeHandler 来把 Enum 值转换成对应的名字。
注意 EnumTypeHandler 在某种意义上来说是比较特别的,其他的处理器只针对某个特定的类,而它不同,它会处理任意继承了 Enum 的类。
不过,我们可能不想存储名字,相反我们的 DBA 会坚持使用整形值代码。那也一样轻而易举: 在配置文件中把 EnumOrdinalTypeHandler 加到 typeHandlers 中即可, 这样每个 RoundingMode 将通过他们的序数值来映射成对应的整形。
但是怎样能将同样的 Enum 既映射成字符串又映射成整形呢?
自动映射器(auto-mapper)会自动地选用EnumOrdinalTypeHandler来处理,所以如果我们想用普通的 EnumTypeHandler,就需要为那些SQL 语句显式地设置要用到的类型处理器。比如:
2.1.12 加载mapper文件mapperElement
mapper文件是mybatis框架的核心之处,所有的用户sql语句都编写在mapper文件中,所以理解mapper文件对于所有的开发人员来说都是必备的要求。
private void mapperElement(XNode parent) throws Exception {
if (parent != null) {
for (XNode child : parent.getChildren()) {
// 如果要同时使用package自动扫描和通过mapper明确指定要加载的mapper,一定要确保package自动扫描的范围不包含明确指定的mapper,否则在通过package扫描的interface的时候,尝试加载对应xml文件的loadXmlResource()的逻辑中出现判重出错,报org.apache.ibatis.binding.BindingException异常,即使xml文件中包含的内容和mapper接口中包含的语句不重复也会出错,包括加载mapper接口时自动加载的xml mapper也一样会出错。
if ("package".equals(child.getName())) {
String mapperPackage = child.getStringAttribute("name");
configuration.addMappers(mapperPackage);
} else {
String resource = child.getStringAttribute("resource");
String url = child.getStringAttribute("url");
String mapperClass = child.getStringAttribute("class");
if (resource != null && url == null && mapperClass == null) {
ErrorContext.instance().resource(resource);
InputStream inputStream = Resources.getResourceAsStream(resource);
XMLMapperBuilder mapperParser = new XMLMapperBuilder(inputStream, configuration, resource, configuration.getSqlFragments());
mapperParser.parse();
} else if (resource == null && url != null && mapperClass == null) {
ErrorContext.instance().resource(url);
InputStream inputStream = Resources.getUrlAsStream(url);
XMLMapperBuilder mapperParser = new XMLMapperBuilder(inputStream, configuration, url, configuration.getSqlFragments());
mapperParser.parse();
} else if (resource == null && url == null && mapperClass != null) {
Class mapperInterface = Resources.classForName(mapperClass);
configuration.addMapper(mapperInterface);
} else {
throw new BuilderException("A mapper element may only specify a url, resource or class, but not more than one.");
}
}
}
}
}
mybatis提供了两类配置mapper的方法,第一类是使用package自动搜索的模式,这样指定package下所有接口都会被注册为mapper,例如:
另外一类是明确指定mapper,这又可以通过resource、url或者class进行细分。例如:
需要注意的是,如果要同时使用package自动扫描和通过mapper明确指定要加载的mapper,则必须先声明mapper,然后声明package,否则DTD校验会失败。同时一定要确保package自动扫描的范围不包含明确指定的mapper,否则在通过package扫描的interface的时候,尝试加载对应xml文件的loadXmlResource()的逻辑中出现判重出错,报org.apache.ibatis.binding.BindingException异常。
对于通过package加载的mapper文件,调用mapperRegistry.addMappers(packageName);进行加载,其核心逻辑在org.apache.ibatis.binding.MapperRegistry中,对于每个找到的接口或者mapper文件,最后调用用XMLMapperBuilder进行具体解析。
对于明确指定的mapper文件或者mapper接口,则主要使用XMLMapperBuilder进行具体解析。
下一章节,我们进行详细说明mapper文件的解析加载与初始化。
2.2 mapper加载与初始化
前面说过mybatis mapper文件的加载主要有两大类,通过package加载和明确指定的方式。
一般来说,对于简单语句来说,使用注解代码会更加清晰,然而Java注解对于复杂语句比如同时包含了构造器、鉴别器、resultMap来说就会非常混乱,应该限制使用,此时应该使用XML文件,因为注解至少至今为止不像XML/Gradle一样能够很好的表示嵌套关系。mybatis完整的注解列表以及含义可参考http://www.mybatis.org/mybatis-3/java-api.html或者http://blog.51cto.com/computerdragon/1399742或者源码org.apache.ibatis.annotations包:

为了更好的理解上下文语义,建议读者对XML配置对应的注解先了解,这样看起源码来会更加顺畅。我们先来回顾一下通过注解配置的典型mapper接口:
@Select("select *from User where id=#{id} and userName like #{name}")
public User retrieveUserByIdAndName(@Param("id")int id,@Param("name")String names);
@Insert("INSERT INTO user(userName,userAge,userAddress) VALUES(#{userName},#{userAge},#{userAddress})")
public void addNewUser(User user);
@Insert("insert into table3 (id, name) values(#{nameId}, #{name})")
@SelectKey(statement="call next value for TestSequence", keyProperty="nameId", before=true, resultType=int.class)
int insertTable3(Name name);
@Results(id = "userResult", value = {
@Result(property = "id", column = "uid", id = true),
@Result(property = "firstName", column = "first_name"),
@Result(property = "lastName", column = "last_name")
})
@TypeDiscriminator(column = "type",
cases={
@Case(value="1",type=RegisterEmployee.class,results={
@Result(property="salay")
}),
@Case(value="2",type=TimeEmployee.class,results={
@Result(property="time")
})
}
)
@Select("select * from users where id = #{id}")
User getUserById(Integer id);
@Results(id = "companyResults")
@ConstructorArgs({
@Arg(property = "id", column = "cid", id = true),
@Arg(property = "name", column = "name")
})
@Select("select * from company where id = #{id}")
Company getCompanyById(Integer id);
@ResultMap(id = "xmlUserResults")
@SelectProvider(type = UserSqlBuilder.class, method = "buildGetUsersByName")
List getUsersByName(String name);
// 注:建议尽可能避免使用SqlBuild的模式生成的,如果因为功能需要必须动态生成SQL的话,也是直接写SQL拼接返回,而不是一堆类似SELECT()、FROM()的函数调用,这只会让维护成为噩梦,这思路的设计者不是知道怎么想的, 此处仅用于演示XXXProvider功能,但是XXXProvider模式本身的设计在关键时候还是比较清晰的。
class UserSqlBuilder {
public String buildGetUsersByName(final String name) {
return new SQL(){{
SELECT("*");
FROM("users");
if (name != null) {
WHERE("name like #{value} || '%'");
}
ORDER_BY("id");
}}.toString();
}
}
我们先来看通过package自动搜索加载的方式,它的范围由addMappers的参数packageName指定的包名以及父类superType确定,其整体流程如下:
/**
* @since 3.2.2
*/
public void addMappers(String packageName, Class superType) {
// mybatis框架提供的搜索classpath下指定package以及子package中符合条件(注解或者继承于某个类/接口)的类,默认使用Thread.currentThread().getContextClassLoader()返回的加载器,和spring的工具类殊途同归。
ResolverUtil> resolverUtil = new ResolverUtil>();
// 无条件的加载所有的类,因为调用方传递了Object.class作为父类,这也给以后的指定mapper接口预留了余地
resolverUtil.find(new ResolverUtil.IsA(superType), packageName);
// 所有匹配的calss都被存储在ResolverUtil.matches字段中
Set>> mapperSet = resolverUtil.getClasses();
for (Class mapperClass : mapperSet) {
//调用addMapper方法进行具体的mapper类/接口解析
addMapper(mapperClass);
}
}
/**
* 外部调用的入口
* @since 3.2.2
*/
public void addMappers(String packageName) {
addMappers(packageName, Object.class);
}
public void addMapper(Class type) {
// 对于mybatis mapper接口文件,必须是interface,不能是class
if (type.isInterface()) {
// 判重,确保只会加载一次不会被覆盖
if (hasMapper(type)) {
throw new BindingException("Type " + type + " is already known to the MapperRegistry.");
}
boolean loadCompleted = false;
try {
// 为mapper接口创建一个MapperProxyFactory代理
knownMappers.put(type, new MapperProxyFactory(type));
// It's important that the type is added before the parser is run
// otherwise the binding may automatically be attempted by the
// mapper parser. If the type is already known, it won't try.
MapperAnnotationBuilder parser = new MapperAnnotationBuilder(config, type);
parser.parse();
loadCompleted = true;
} finally {
//剔除解析出现异常的接口
if (!loadCompleted) {
knownMappers.remove(type);
}
}
}
}
knownMappers是MapperRegistry的主要字段,维护了Mapper接口和代理类的映射关系,key是mapper接口类,value是MapperProxyFactory,其定义如下:
private final Map, MapperProxyFactory> knownMappers = new HashMap, MapperProxyFactory>();
public class MapperProxyFactory {
private final Class mapperInterface;
private final Map methodCache = new ConcurrentHashMap();
public MapperProxyFactory(Class mapperInterface) {
this.mapperInterface = mapperInterface;
}
public Class getMapperInterface() {
return mapperInterface;
}
public Map getMethodCache() {
return methodCache;
}
@SuppressWarnings("unchecked")
protected T newInstance(MapperProxy mapperProxy) {
return (T) Proxy.newProxyInstance(mapperInterface.getClassLoader(), new Class[] { mapperInterface }, mapperProxy);
}
public T newInstance(SqlSession sqlSession) {
final MapperProxy mapperProxy = new MapperProxy(sqlSession, mapperInterface, methodCache);
return newInstance(mapperProxy);
}
}
从定义看出,MapperProxyFactory主要是维护mapper接口的方法与对应mapper文件中具体CRUD节点的关联关系。其中每个Method与对应MapperMethod维护在一起。MapperMethod是mapper中具体映射语句节点的内部表示。
首先为mapper接口创建MapperProxyFactory,然后创建MapperAnnotationBuilder进行具体的解析,MapperAnnotationBuilder在解析前的构造器中完成了下列工作:
public MapperAnnotationBuilder(Configuration configuration, Class type) {
String resource = type.getName().replace('.', '/') + ".java (best guess)";
this.assistant = new MapperBuilderAssistant(configuration, resource);
this.configuration = configuration;
this.type = type;
sqlAnnotationTypes.add(Select.class);
sqlAnnotationTypes.add(Insert.class);
sqlAnnotationTypes.add(Update.class);
sqlAnnotationTypes.add(Delete.class);
sqlProviderAnnotationTypes.add(SelectProvider.class);
sqlProviderAnnotationTypes.add(InsertProvider.class);
sqlProviderAnnotationTypes.add(UpdateProvider.class);
sqlProviderAnnotationTypes.add(DeleteProvider.class);
}
其中的MapperBuilderAssistant和XMLConfigBuilder一样,都是继承于BaseBuilder。Select.class/Insert.class等注解指示该方法对应的真实sql语句类型分别是select/insert。
SelectProvider.class/InsertProvider.class主要用于动态SQL,它们允许你指定一个类名和一个方法在具体执行时返回要运行的SQL语句。MyBatis会实例化这个类,然后执行指定的方法。
MapperBuilderAssistant初始化完成之后,就调用build.parse()进行具体的mapper接口文件加载与解析,如下所示:
public void parse() {
String resource = type.toString();
//首先根据mapper接口的字符串表示判断是否已经加载,避免重复加载,正常情况下应该都没有加载
if (!configuration.isResourceLoaded(resource)) {
loadXmlResource();
configuration.addLoadedResource(resource);
// 每个mapper文件自成一个namespace,通常自动匹配就是这么来的,约定俗成代替人工设置最简化常见的开发
assistant.setCurrentNamespace(type.getName());
parseCache();
parseCacheRef();
Method[] methods = type.getMethods();
for (Method method : methods) {
try {
// issue #237
if (!method.isBridge()) {
parseStatement(method);
}
} catch (IncompleteElementException e) {
configuration.addIncompleteMethod(new MethodResolver(this, method));
}
}
}
parsePendingMethods();
}
整体流程为:
1、首先加载mapper接口对应的xml文件并解析。loadXmlResource和通过resource、url解析相同,都是解析mapper文件中的定义,他们的入口都是XMLMapperBuilder.parse(),我们稍等会儿专门专门分析,这一节先来看通过注解方式配置的mapper的解析(注:对于一个mapper接口,不能同时使用注解方式和xml方式,任何时候只能之一,但是不同的mapper接口可以混合使用这两种方式)。
2、解析缓存注解;
mybatis中缓存注解的定义为:
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.TYPE)
public @interface CacheNamespace {
Class implementation() default PerpetualCache.class;
Class eviction() default LruCache.class;
long flushInterval() default 0;
int size() default 1024;
boolean readWrite() default true;
boolean blocking() default false;
/**
* Property values for a implementation object.
* @since 3.4.2
*/
Property[] properties() default {};
}
从上面的定义可以看出,和在XML中的是一一对应的。缓存的解析很简单,这里不展开细细讲解。
3、解析缓存参照注解。缓存参考的解析也很简单,这里不展开细细讲解。
4、解析非桥接方法。在正式开始之前,我们先来看下什么是桥接方法。桥接方法是 JDK 1.5 引入泛型后,为了使Java的泛型方法生成的字节码和 1.5 版本前的字节码相兼容,由编译器自动生成的方法。那什么时候,编译器会生成桥接方法呢,举个例子,一个子类在继承(或实现)一个父类(或接口)的泛型方法时,在子类中明确指定了泛型类型,那么在编译时编译器会自动生成桥接方法。参考:
http://blog.csdn.net/mhmyqn/article/details/47342577
https://docs.oracle.com/javase/specs/jvms/se7/html/jvms-4.html#jvms-4.6
https://docs.oracle.com/javase/specs/jls/se7/html/jls-15.html#jls-15.12.4.5
所以正常情况下,只要在实现mybatis mapper接口的时候,没有继承根Mapper或者继承了根Mapper但是没有写死泛型类型的时候,是不会成为桥接方法的。现在来看parseStatement的主要实现代码(提示:因为注解方式通常不用于复杂的配置,所以这里我们进行简单的解析,在XML部分进行详细说明):
void parseStatement(Method method) {
// 获取参数类型,如果有多个参数,这种情况下就返回org.apache.ibatis.binding.MapperMethod.ParamMap.class,ParamMap是一个继承于HashMap的类,否则返回实际类型
Class parameterTypeClass = getParameterType(method);
// 获取语言驱动器
LanguageDriver languageDriver = getLanguageDriver(method);
// 获取方法的SqlSource对象,只有指定了@Select/@Insert/@Update/@Delete或者对应的Provider的方法才会被当作mapper,否则只是和mapper文件中对应语句的一个运行时占位符
SqlSource sqlSource = getSqlSourceFromAnnotations(method, parameterTypeClass, languageDriver);
if (sqlSource != null) {
// 获取方法的属性设置,对应重点来看没有带@ResultMap注解的查询方法parseResultMap(Method):
private String parseResultMap(Method method) {
// 获取方法的返回类型
Class returnType = getReturnType(method);
// 获取构造器
ConstructorArgs args = method.getAnnotation(ConstructorArgs.class);
// 获取@Results注解,也就是注解形式的结果映射
Results results = method.getAnnotation(Results.class);
// 获取鉴别器
TypeDiscriminator typeDiscriminator = method.getAnnotation(TypeDiscriminator.class);
// 产生resultMapId
String resultMapId = generateResultMapName(method);
applyResultMap(resultMapId, returnType, argsIf(args), resultsIf(results), typeDiscriminator);
return resultMapId;
}
// 如果有resultMap设置了Id,就直接返回类名.resultMapId. 否则返回类名.方法名.以-分隔拼接的方法参数
private String generateResultMapName(Method method) {
Results results = method.getAnnotation(Results.class);
if (results != null && !results.id().isEmpty()) {
return type.getName() + "." + results.id();
}
StringBuilder suffix = new StringBuilder();
for (Class c : method.getParameterTypes()) {
suffix.append("-");
suffix.append(c.getSimpleName());
}
if (suffix.length() < 1) {
suffix.append("-void");
}
return type.getName() + "." + method.getName() + suffix;
}
private void applyResultMap(String resultMapId, Class returnType, Arg[] args, Result[] results, TypeDiscriminator discriminator) {
List resultMappings = new ArrayList();
applyConstructorArgs(args, returnType, resultMappings);
applyResults(results, returnType, resultMappings);
Discriminator disc = applyDiscriminator(resultMapId, returnType, discriminator);
// TODO add AutoMappingBehaviour
assistant.addResultMap(resultMapId, returnType, null, disc, resultMappings, null);
createDiscriminatorResultMaps(resultMapId, returnType, discriminator);
}
private void createDiscriminatorResultMaps(String resultMapId, Class resultType, TypeDiscriminator discriminator) {
if (discriminator != null) {
// 对于鉴别器来说,和XML配置的差别在于xml中可以外部公用的resultMap,在注解中,则只提供了内嵌式的resultMap定义
for (Case c : discriminator.cases()) {
// 从内部实现的角度,因为内嵌式的resultMap定义也会创建resultMap,所以XML的实现也一样,对于内嵌式鉴别器每个分支resultMap,其命名为映射方法的resultMapId-Case.value()。这样在运行时,只要知道resultMap中包含了鉴别器之后,获取具体的鉴别器映射就很简单了,map.get()一下就得到了。
String caseResultMapId = resultMapId + "-" + c.value();
List resultMappings = new ArrayList();
// issue #136
applyConstructorArgs(c.constructArgs(), resultType, resultMappings);
applyResults(c.results(), resultType, resultMappings);
// TODO add AutoMappingBehaviour
assistant.addResultMap(caseResultMapId, c.type(), resultMapId, null, resultMappings, null);
}
}
}
private Discriminator applyDiscriminator(String resultMapId, Class resultType, TypeDiscriminator discriminator) {
if (discriminator != null) {
String column = discriminator.column();
Class javaType = discriminator.javaType() == void.class ? String.class : discriminator.javaType();
JdbcType jdbcType = discriminator.jdbcType() == JdbcType.UNDEFINED ? null : discriminator.jdbcType();
@SuppressWarnings("unchecked")
Class> typeHandler = (Class>)
(discriminator.typeHandler() == UnknownTypeHandler.class ? null : discriminator.typeHandler());
Case[] cases = discriminator.cases();
Map discriminatorMap = new HashMap();
for (Case c : cases) {
String value = c.value();
String caseResultMapId = resultMapId + "-" + value;
discriminatorMap.put(value, caseResultMapId);
}
return assistant.buildDiscriminator(resultType, column, javaType, jdbcType, typeHandler, discriminatorMap);
}
return null;
}
5、二次解析pending的方法。
2.3 解析mapper文件XMLMapperBuilder
Mapper文件的解析主要由XMLMapperBuilder类完成,Mapper文件的加载流程如下:
我们以package扫描中的loadXmlResource()为入口开始。
private void loadXmlResource() {
// Spring may not know the real resource name so we check a flag
// to prevent loading again a resource twice
// this flag is set at XMLMapperBuilder#bindMapperForNamespace
if (!configuration.isResourceLoaded("namespace:" + type.getName())) {
String xmlResource = type.getName().replace('.', '/') + ".xml";
InputStream inputStream = null;
try {
inputStream = Resources.getResourceAsStream(type.getClassLoader(), xmlResource);
} catch (IOException e) {
// ignore, resource is not required
}
if (inputStream != null) {
XMLMapperBuilder xmlParser = new XMLMapperBuilder(inputStream, assistant.getConfiguration(), xmlResource, configuration.getSqlFragments(), type.getName());
xmlParser.parse();
}
}
}
根据package自动搜索加载的时候,约定俗称从classpath下加载接口的完整名,比如org.mybatis.example.mapper.BlogMapper,就加载org/mybatis/example/mapper/BlogMapper.xml。对于从package和class进来的mapper,如果找不到对应的文件,就忽略,因为这种情况下是允许SQL语句作为注解打在接口上的,所以xml文件不是必须的,而对于直接声明的xml mapper文件,如果找不到的话会抛出IOException异常而终止,这在使用注解模式的时候需要注意。加载到对应的mapper.xml文件后,调用XMLMapperBuilder进行解析。在创建XMLMapperBuilder时,我们发现用到了configuration.getSqlFragments(),这就是我们在mapper文件中经常使用的可以被包含在其他语句中的SQL片段,但是我们并没有初始化过,所以很有可能它是在解析过程中动态添加的,创建了XMLMapperBuilder之后,在调用其parse()接口进行具体xml的解析,这和mybatis-config的逻辑基本上是一致的思路。再来看XMLMapperBuilder的初始化逻辑:
public XMLMapperBuilder(InputStream inputStream, Configuration configuration, String resource, Map sqlFragments, String namespace) {
this(inputStream, configuration, resource, sqlFragments);
this.builderAssistant.setCurrentNamespace(namespace);
}
public XMLMapperBuilder(InputStream inputStream, Configuration configuration, String resource, Map sqlFragments) {
this(new XPathParser(inputStream, true, configuration.getVariables(), new XMLMapperEntityResolver()),
configuration, resource, sqlFragments);
}
加载的基本逻辑和加载mybatis-config一样的过程,使用XPathParser进行总控,XMLMapperEntityResolver进行具体判断。
接下去来看XMLMapperBuilder.parse()的具体实现。
public void parse() {
if (!configuration.isResourceLoaded(resource)) {
configurationElement(parser.evalNode("/mapper"));
configuration.addLoadedResource(resource);
bindMapperForNamespace();
}
parsePendingResultMaps();
parsePendingCacheRefs();
parsePendingStatements();
}
其中,解析mapper的核心又在configurationElement中,如下所示:
private void configurationElement(XNode context) {
try {
String namespace = context.getStringAttribute("namespace");
if (namespace == null || namespace.equals("")) {
throw new BuilderException("Mapper's namespace cannot be empty");
}
builderAssistant.setCurrentNamespace(namespace);
cacheRefElement(context.evalNode("cache-ref"));
cacheElement(context.evalNode("cache"));
parameterMapElement(context.evalNodes("/mapper/parameterMap"));
resultMapElements(context.evalNodes("/mapper/resultMap"));
sqlElement(context.evalNodes("/mapper/sql"));
buildStatementFromContext(context.evalNodes("select|insert|update|delete"));
} catch (Exception e) {
throw new BuilderException("Error parsing Mapper XML. The XML location is '" + resource + "'. Cause: " + e, e);
}
}
其主要过程是:
1、解析缓存参照cache-ref。参照缓存顾名思义,就是共用其他缓存的设置。
private void cacheRefElement(XNode context) {
if (context != null) {
configuration.addCacheRef(builderAssistant.getCurrentNamespace(), context.getStringAttribute("namespace"));
CacheRefResolver cacheRefResolver = new CacheRefResolver(builderAssistant, context.getStringAttribute("namespace"));
try {
cacheRefResolver.resolveCacheRef();
} catch (IncompleteElementException e) {
configuration.addIncompleteCacheRef(cacheRefResolver);
}
}
}
缓存参考因为通过namespace指向其他的缓存。所以会出现第一次解析的时候指向的缓存还不存在的情况,所以需要在所有的mapper文件加载完成后进行二次处理,不仅仅是缓存参考,其他的CRUD也一样。所以在XMLMapperBuilder.configuration中有很多的incompleteXXX,这种设计模式类似于JVM GC中的mark and sweep,标记、然后处理。所以当捕获到IncompleteElementException异常时,没有终止执行,而是将指向的缓存不存在的cacheRefResolver添加到configuration.incompleteCacheRef中。
2、解析缓存cache
private void cacheElement(XNode context) throws Exception {
if (context != null) {
String type = context.getStringAttribute("type", "PERPETUAL");
Class typeClass = typeAliasRegistry.resolveAlias(type);
String eviction = context.getStringAttribute("eviction", "LRU");
Class evictionClass = typeAliasRegistry.resolveAlias(eviction);
Long flushInterval = context.getLongAttribute("flushInterval");
Integer size = context.getIntAttribute("size");
boolean readWrite = !context.getBooleanAttribute("readOnly", false);
boolean blocking = context.getBooleanAttribute("blocking", false);
Properties props = context.getChildrenAsProperties();
builderAssistant.useNewCache(typeClass, evictionClass, flushInterval, size, readWrite, blocking, props);
}
}
默认情况下,mybatis使用的是永久缓存PerpetualCache,读取或设置各个属性默认值之后,调用builderAssistant.useNewCache构建缓存,其中的CacheBuilder使用了build模式(在effective里面,建议有4个以上可选属性时,应该为对象提供一个builder便于使用),只要实现org.apache.ibatis.cache.Cache接口,就是合法的mybatis缓存。
我们先来看下缓存的DTD定义:
所以,最简单的情况下只要声明就可以启用当前mapper下的缓存。
3、解析参数映射parameterMap
private void parameterMapElement(List list) throws Exception {
for (XNode parameterMapNode : list) {
String id = parameterMapNode.getStringAttribute("id");
String type = parameterMapNode.getStringAttribute("type");
Class parameterClass = resolveClass(type);
List parameterNodes = parameterMapNode.evalNodes("parameter");
List parameterMappings = new ArrayList();
for (XNode parameterNode : parameterNodes) {
String property = parameterNode.getStringAttribute("property");
String javaType = parameterNode.getStringAttribute("javaType");
String jdbcType = parameterNode.getStringAttribute("jdbcType");
String resultMap = parameterNode.getStringAttribute("resultMap");
String mode = parameterNode.getStringAttribute("mode");
String typeHandler = parameterNode.getStringAttribute("typeHandler");
Integer numericScale = parameterNode.getIntAttribute("numericScale");
ParameterMode modeEnum = resolveParameterMode(mode);
Class javaTypeClass = resolveClass(javaType);
JdbcType jdbcTypeEnum = resolveJdbcType(jdbcType);
@SuppressWarnings("unchecked")
Class> typeHandlerClass = (Class>) resolveClass(typeHandler);
ParameterMapping parameterMapping = builderAssistant.buildParameterMapping(parameterClass, property, javaTypeClass, jdbcTypeEnum, resultMap, modeEnum, typeHandlerClass, numericScale);
parameterMappings.add(parameterMapping);
}
builderAssistant.addParameterMap(id, parameterClass, parameterMappings);
}
}
总体来说,目前已经不推荐使用参数映射,而是直接使用内联参数。所以我们这里就不展开细讲了。如有必要,我们后续会补上。
4、解析结果集映射resultMap
结果集映射早期版本可以说是用的最多的辅助节点了,不过有了mapUnderscoreToCamelCase属性之后,如果命名规范控制做的好的话,resultMap也是可以省略的。每个mapper文件可以有多个结果集映射。最终来说,它还是使用频率很高的。我们先来看下DTD定义:
从DTD的复杂程度就可知,resultMap相当于前面的cache/parameterMap等来说,是相当灵活的。下面我们来看resultMap在运行时到底是如何表示的。
private void resultMapElements(List list) throws Exception {
for (XNode resultMapNode : list) {
try {
resultMapElement(resultMapNode);
} catch (IncompleteElementException e) {
// ignore, it will be retried
// 在内部实现中将未完成的元素添加到configuration.incomplete中了
}
}
}
private ResultMap resultMapElement(XNode resultMapNode) throws Exception {
return resultMapElement(resultMapNode, Collections. emptyList());
}
private ResultMap resultMapElement(XNode resultMapNode, List additionalResultMappings) throws Exception {
ErrorContext.instance().activity("processing " + resultMapNode.getValueBasedIdentifier());
String id = resultMapNode.getStringAttribute("id",
resultMapNode.getValueBasedIdentifier());
String type = resultMapNode.getStringAttribute("type",
resultMapNode.getStringAttribute("ofType",
resultMapNode.getStringAttribute("resultType",
resultMapNode.getStringAttribute("javaType"))));
String extend = resultMapNode.getStringAttribute("extends");
Boolean autoMapping = resultMapNode.getBooleanAttribute("autoMapping");
Class typeClass = resolveClass(type);
Discriminator discriminator = null;
List resultMappings = new ArrayList();
resultMappings.addAll(additionalResultMappings);
List resultChildren = resultMapNode.getChildren();
for (XNode resultChild : resultChildren) {
if ("constructor".equals(resultChild.getName())) {
processConstructorElement(resultChild, typeClass, resultMappings);
} else if ("discriminator".equals(resultChild.getName())) {
discriminator = processDiscriminatorElement(resultChild, typeClass, resultMappings);
} else {
List flags = new ArrayList();
if ("id".equals(resultChild.getName())) {
flags.add(ResultFlag.ID);
}
resultMappings.add(buildResultMappingFromContext(resultChild, typeClass, flags));
}
}
ResultMapResolver resultMapResolver = new ResultMapResolver(builderAssistant, id, typeClass, extend, discriminator, resultMappings, autoMapping);
try {
return resultMapResolver.resolve();
} catch (IncompleteElementException e) {
configuration.addIncompleteResultMap(resultMapResolver);
throw e;
}
}
private void processConstructorElement(XNode resultChild, Class resultType, List resultMappings) throws Exception {
List argChildren = resultChild.getChildren();
for (XNode argChild : argChildren) {
List flags = new ArrayList();
flags.add(ResultFlag.CONSTRUCTOR);
if ("idArg".equals(argChild.getName())) {
flags.add(ResultFlag.ID);
}
resultMappings.add(buildResultMappingFromContext(argChild, resultType, flags));
}
}
private Discriminator processDiscriminatorElement(XNode context, Class resultType, List resultMappings) throws Exception {
String column = context.getStringAttribute("column");
String javaType = context.getStringAttribute("javaType");
String jdbcType = context.getStringAttribute("jdbcType");
String typeHandler = context.getStringAttribute("typeHandler");
Class javaTypeClass = resolveClass(javaType);
@SuppressWarnings("unchecked")
Class> typeHandlerClass = (Class>) resolveClass(typeHandler);
JdbcType jdbcTypeEnum = resolveJdbcType(jdbcType);
Map discriminatorMap = new HashMap();
for (XNode caseChild : context.getChildren()) {
String value = caseChild.getStringAttribute("value");
String resultMap = caseChild.getStringAttribute("resultMap", processNestedResultMappings(caseChild, resultMappings));
discriminatorMap.put(value, resultMap);
}
return builderAssistant.buildDiscriminator(resultType, column, javaTypeClass, jdbcTypeEnum, typeHandlerClass, discriminatorMap);
}
我们先来看下ResultMapping的定义:
public class ResultMapping {
private Configuration configuration;
private String property;
private String column;
private Class javaType;
private JdbcType jdbcType;
private TypeHandler typeHandler;
private String nestedResultMapId;
private String nestedQueryId;
private Set notNullColumns;
private String columnPrefix;
private List flags;
private List composites;
private String resultSet;
private String foreignColumn;
private boolean lazy;
...
}
所有下的最底层子元素比如、、等本质上都属于一个映射,只不过有着额外的标记比如是否嵌套,是否构造器等。
总体逻辑是先解析resultMap节点本身,然后解析子节点构造器,鉴别器discriminator,id。最后组装成真正的resultMappings。我们先来看个实际的复杂resultMap例子,便于我们更好的理解代码的逻辑:
resultMap里面可以包含多种子节点,每个节点都有具体的方法进行解析,这也体现了单一职责原则。在resultMapElement中,主要是解析resultMap节点本身并循环遍历委托给具体的方法处理。下面来看构造器的解析。构造器主要用于没有默认构造器或者有多个构造器的情况,比如:
public class User {
//...
public User(Integer id, String username, int age) {
//...
}
//...
}
就可以使用下列的构造器设置属性值,比如:
遍历构造器元素很简单:
private void processConstructorElement(XNode resultChild, Class resultType, List resultMappings) throws Exception {
List argChildren = resultChild.getChildren();
for (XNode argChild : argChildren) {
List flags = new ArrayList();
flags.add(ResultFlag.CONSTRUCTOR);
if ("idArg".equals(argChild.getName())) {
flags.add(ResultFlag.ID);
}
resultMappings.add(buildResultMappingFromContext(argChild, resultType, flags));
}
}
构造器的解析比较简单,除了遍历构造参数外,还可以构造器参数的ID也识别出来。最后调用buildResultMappingFromContext建立具体的resultMap。buildResultMappingFromContext是个公共工具方法,会被反复使用,我们来看下它的具体实现(不是所有元素都包含所有属性):
private ResultMapping buildResultMappingFromContext(XNode context, Class resultType, List flags) throws Exception {
String property;
if (flags.contains(ResultFlag.CONSTRUCTOR)) {
property = context.getStringAttribute("name");
} else {
property = context.getStringAttribute("property");
}
String column = context.getStringAttribute("column");
String javaType = context.getStringAttribute("javaType");
String jdbcType = context.getStringAttribute("jdbcType");
String nestedSelect = context.getStringAttribute("select");
// resultMap中可以包含association或collection复合类型,这些复合类型可以使用外部定义的公用resultMap或者内嵌resultMap, 所以这里的处理逻辑是如果有resultMap就获取resultMap,如果没有,那就动态生成一个。如果自动生成的话,他的resultMap id通过调用XNode.getValueBasedIdentifier()来获得
String nestedResultMap = context.getStringAttribute("resultMap",
processNestedResultMappings(context, Collections. emptyList()));
String notNullColumn = context.getStringAttribute("notNullColumn");
String columnPrefix = context.getStringAttribute("columnPrefix");
String typeHandler = context.getStringAttribute("typeHandler");
String resultSet = context.getStringAttribute("resultSet");
String foreignColumn = context.getStringAttribute("foreignColumn");
boolean lazy = "lazy".equals(context.getStringAttribute("fetchType", configuration.isLazyLoadingEnabled() ? "lazy" : "eager"));
Class javaTypeClass = resolveClass(javaType);
@SuppressWarnings("unchecked")
Class> typeHandlerClass = (Class>) resolveClass(typeHandler);
JdbcType jdbcTypeEnum = resolveJdbcType(jdbcType);
return builderAssistant.buildResultMapping(resultType, property, column, javaTypeClass, jdbcTypeEnum, nestedSelect, nestedResultMap, notNullColumn, columnPrefix, typeHandlerClass, flags, resultSet, foreignColumn, lazy);
}
上述过程主要用于获取各个属性,其中唯一值得注意的是processNestedResultMappings,它用于解析包含的association或collection复合类型,这些复合类型可以使用外部定义的公用resultMap或者内嵌resultMap, 所以这里的处理逻辑是如果是外部resultMap就获取对应resultMap的名称,如果没有,那就动态生成一个。如果自动生成的话,其resultMap id通过调用XNode.getValueBasedIdentifier()来获得。由于colletion和association、discriminator里面还可以包含复合类型,所以将进行递归解析直到所有的子元素都为基本列位置,它在使用层面的目的在于将关系模型映射为对象树模型。例如:
注意“ofType”属性,这个属性用来区分JavaBean(或字段)属性类型和集合中存储的对象类型。
private String processNestedResultMappings(XNode context, List resultMappings) throws Exception {
if ("association".equals(context.getName())
|| "collection".equals(context.getName())
|| "case".equals(context.getName())) {
if (context.getStringAttribute("select") == null) {
ResultMap resultMap = resultMapElement(context, resultMappings);
return resultMap.getId();
}
}
return null;
}
对于其中的每个非select属性映射,调用resultMapElement进行递归解析。其中的case节点主要用于鉴别器情况,后面我们会细讲。
注:select的用途在于指定另外一个映射语句的ID,加载这个属性映射需要的复杂类型。在列属性中指定的列的值将被传递给目标 select 语句作为参数。在上面的例子中,id的值会作为selectPostsForBlog的参数,这个语句会为每条映射到blogResult的记录执行一次selectPostsForBlog,并将返回的值添加到blog.posts属性中,其类型为Post。
得到各属性之后,调用builderAssistant.buildResultMapping最后创建ResultMap。其中除了 javaType,column外,其他都是可选的,property也就是中的name属性或者中的property属性,主要用于根据@Param或者jdk 8 -parameters形参名而非依赖声明顺序进行映射。
public ResultMapping buildResultMapping(
Class resultType,
String property,
String column,
Class javaType,
JdbcType jdbcType,
String nestedSelect,
String nestedResultMap,
String notNullColumn,
String columnPrefix,
Class> typeHandler,
List flags,
String resultSet,
String foreignColumn,
boolean lazy) {
Class javaTypeClass = resolveResultJavaType(resultType, property, javaType);
TypeHandler typeHandlerInstance = resolveTypeHandler(javaTypeClass, typeHandler);
List composites = parseCompositeColumnName(column);
return new ResultMapping.Builder(configuration, property, column, javaTypeClass)
.jdbcType(jdbcType)
.nestedQueryId(applyCurrentNamespace(nestedSelect, true))
.nestedResultMapId(applyCurrentNamespace(nestedResultMap, true))
.resultSet(resultSet)
.typeHandler(typeHandlerInstance)
.flags(flags == null ? new ArrayList() : flags)
.composites(composites)
.notNullColumns(parseMultipleColumnNames(notNullColumn))
.columnPrefix(columnPrefix)
.foreignColumn(foreignColumn)
.lazy(lazy)
.build();
}
在实际使用中,一般不会在构造器中包含association和collection。
2.3.1 鉴别器discriminator的解析
鉴别器非常容易理解,它的表现很像Java语言中的switch语句。定义鉴别器也是通过column和javaType属性来唯一标识,column是用来确定某个字段是否为鉴别器, JavaType是需要被用来保证等价测试的合适类型。例如:
对于上述的鉴别器,如果 vehicle_type=1, 那就会使用下列这个结果映射。
private Discriminator processDiscriminatorElement(XNode context, Class resultType, List resultMappings) throws Exception {
String column = context.getStringAttribute("column");
String javaType = context.getStringAttribute("javaType");
String jdbcType = context.getStringAttribute("jdbcType");
String typeHandler = context.getStringAttribute("typeHandler");
Class javaTypeClass = resolveClass(javaType);
@SuppressWarnings("unchecked")
Class> typeHandlerClass = (Class>) resolveClass(typeHandler);
JdbcType jdbcTypeEnum = resolveJdbcType(jdbcType);
Map discriminatorMap = new HashMap();
for (XNode caseChild : context.getChildren()) {
String value = caseChild.getStringAttribute("value");
String resultMap = caseChild.getStringAttribute("resultMap", processNestedResultMappings(caseChild, resultMappings));
discriminatorMap.put(value, resultMap);
}
return builderAssistant.buildDiscriminator(resultType, column, javaTypeClass, jdbcTypeEnum, typeHandlerClass, discriminatorMap);
}
其逻辑和之前处理构造器的时候类似,同样的使用build建立鉴别器并返回鉴别器实例,鉴别器中也可以嵌套association和collection。他们的实现逻辑和常规resultMap中的处理方式完全相同,这里就不展开重复讲。和构造器不一样的是,鉴别器中包含了case分支和对应的resultMap的映射。
最后所有的子节点都被解析到resultMappings中, 在解析完整个resultMap中的所有子元素之后,调用ResultMapResolver进行解析,如下所示:
ResultMapResolver resultMapResolver = new ResultMapResolver(builderAssistant, id, typeClass, extend, discriminator, resultMappings, autoMapping);
try {
return resultMapResolver.resolve();
} catch (IncompleteElementException e) {
configuration.addIncompleteResultMap(resultMapResolver);
throw e;
}

public ResultMap addResultMap(
String id,
Class type,
String extend,
Discriminator discriminator,
List resultMappings,
Boolean autoMapping) {
// 将id/extend填充为完整模式,也就是带命名空间前缀,true不需要和当前resultMap所在的namespace相同,比如extend和cache,否则只能是当前的namespace
id = applyCurrentNamespace(id, false);
extend = applyCurrentNamespace(extend, true);
if (extend != null) {
// 首先检查继承的resultMap是否已存在,如果不存在则标记为incomplete,会进行二次处理
if (!configuration.hasResultMap(extend)) {
throw new IncompleteElementException("Could not find a parent resultmap with id '" + extend + "'");
}
ResultMap resultMap = configuration.getResultMap(extend);
List extendedResultMappings = new ArrayList(resultMap.getResultMappings());
// 剔除所继承的resultMap里已经在当前resultMap中的那个基本映射
extendedResultMappings.removeAll(resultMappings);
// Remove parent constructor if this resultMap declares a constructor.
// 如果本resultMap已经包含了构造器,则剔除继承的resultMap里面的构造器
boolean declaresConstructor = false;
for (ResultMapping resultMapping : resultMappings) {
if (resultMapping.getFlags().contains(ResultFlag.CONSTRUCTOR)) {
declaresConstructor = true;
break;
}
}
if (declaresConstructor) {
Iterator extendedResultMappingsIter = extendedResultMappings.iterator();
while (extendedResultMappingsIter.hasNext()) {
if (extendedResultMappingsIter.next().getFlags().contains(ResultFlag.CONSTRUCTOR)) {
extendedResultMappingsIter.remove();
}
}
}
// 都处理完成之后,将继承的resultMap里面剩下那部分不重复的resultMap子元素添加到当前的resultMap中,所以这个addResultMap方法的用途在于启动时就创建了完整的resultMap,这样运行时就不需要去检查继承的映射和构造器,有利于性能提升。
resultMappings.addAll(extendedResultMappings);
}
ResultMap resultMap = new ResultMap.Builder(configuration, id, type, resultMappings, autoMapping)
.discriminator(discriminator)
.build();
configuration.addResultMap(resultMap);
return resultMap;
}
mybatis源码分析到这里,应该来说上面部分代码不是特别显而易见,它主要是处理extends这个属性,将resultMap各子元素节点的去对象关系,也就是去重、合并属性、构造器。处理完继承的逻辑之后,调用了ResultMap.Builder.build()进行最后的resultMap构建。build应该来说是真正创建根resultMap对象的逻辑入口。我们先看下ResultMap的定义:
public class ResultMap {
private Configuration configuration;
// resultMap的id属性
private String id;
// resultMap的type属性,有可能是alias
private Class type;
// resultMap下的所有节点
private List resultMappings;
// resultMap下的id节点比如 idResultMappings;
// resultMap下的构造器节点
private List constructorResultMappings;
// resultMap下的property节点比如 propertyResultMappings;
//映射的列名
private Set mappedColumns;
// 映射的javaBean属性名,所有映射不管是id、构造器或者普通的
private Set mappedProperties;
// 鉴别器
private Discriminator discriminator;
// 是否有嵌套的resultMap比如association或者collection
private boolean hasNestedResultMaps;
// 是否有嵌套的查询,也就是select属性
private boolean hasNestedQueries;
// autoMapping属性,这个属性会覆盖全局的属性autoMappingBehavior
private Boolean autoMapping;
...
}
其中定义了节点下所有的子元素,以及必要的辅助属性,包括最重要的各种ResultMapping。
再来看下build的实现:
public ResultMap build() {
if (resultMap.id == null) {
throw new IllegalArgumentException("ResultMaps must have an id");
}
resultMap.mappedColumns = new HashSet();
resultMap.mappedProperties = new HashSet();
resultMap.idResultMappings = new ArrayList();
resultMap.constructorResultMappings = new ArrayList();
resultMap.propertyResultMappings = new ArrayList();
final List constructorArgNames = new ArrayList();
for (ResultMapping resultMapping : resultMap.resultMappings) {
// 判断是否有嵌套查询, nestedQueryId是在buildResultMappingFromContext的时候通过读取节点的select属性得到的
resultMap.hasNestedQueries = resultMap.hasNestedQueries || resultMapping.getNestedQueryId() != null;
// 判断是否嵌套了association或者collection, nestedResultMapId是在buildResultMappingFromContext的时候通过读取节点的resultMap属性得到的或者内嵌resultMap的时候自动计算得到的。注:这里的resultSet没有地方set进来,DTD中也没有看到,不确定是不是有意预留的,但是association/collection的子元素中倒是有声明
resultMap.hasNestedResultMaps = resultMap.hasNestedResultMaps || (resultMapping.getNestedResultMapId() != null && resultMapping.getResultSet() == null);
// 获取column属性, 包括复合列,复合列是在org.apache.ibatis.builder.MapperBuilderAssistant.parseCompositeColumnName(String)中解析的。所有的数据库列都被按顺序添加到resultMap.mappedColumns中
final String column = resultMapping.getColumn();
if (column != null) {
resultMap.mappedColumns.add(column.toUpperCase(Locale.ENGLISH));
} else if (resultMapping.isCompositeResult()) {
for (ResultMapping compositeResultMapping : resultMapping.getComposites()) {
final String compositeColumn = compositeResultMapping.getColumn();
if (compositeColumn != null) {
resultMap.mappedColumns.add(compositeColumn.toUpperCase(Locale.ENGLISH));
}
}
}
// 所有映射的属性都被按顺序添加到resultMap.mappedProperties中,ID单独存储
final String property = resultMapping.getProperty();
if(property != null) {
resultMap.mappedProperties.add(property);
}
// 所有映射的构造器被按顺序添加到resultMap.constructorResultMappings
// 如果本元素具有CONSTRUCTOR标记,则添加到构造函数参数列表,否则添加到普通属性映射列表resultMap.propertyResultMappings
if (resultMapping.getFlags().contains(ResultFlag.CONSTRUCTOR)) {
resultMap.constructorResultMappings.add(resultMapping);
if (resultMapping.getProperty() != null) {
constructorArgNames.add(resultMapping.getProperty());
}
} else {
resultMap.propertyResultMappings.add(resultMapping);
}
// 如果本元素具有ID标记, 则添加到ID映射列表resultMap.idResultMappings
if (resultMapping.getFlags().contains(ResultFlag.ID)) {
resultMap.idResultMappings.add(resultMapping);
}
}
// 如果没有声明ID属性,就把所有属性都作为ID属性
if (resultMap.idResultMappings.isEmpty()) {
resultMap.idResultMappings.addAll(resultMap.resultMappings);
}
// 根据声明的构造器参数名和类型,反射声明的类,检查其中是否包含对应参数名和类型的构造器,如果不存在匹配的构造器,就抛出运行时异常,这是为了确保运行时不会出现异常
if (!constructorArgNames.isEmpty()) {
final List actualArgNames = argNamesOfMatchingConstructor(constructorArgNames);
if (actualArgNames == null) {
throw new BuilderException("Error in result map '" + resultMap.id
+ "'. Failed to find a constructor in '"
+ resultMap.getType().getName() + "' by arg names " + constructorArgNames
+ ". There might be more info in debug log.");
}
//构造器参数排序
Collections.sort(resultMap.constructorResultMappings, new Comparator() {
@Override
public int compare(ResultMapping o1, ResultMapping o2) {
int paramIdx1 = actualArgNames.indexOf(o1.getProperty());
int paramIdx2 = actualArgNames.indexOf(o2.getProperty());
return paramIdx1 - paramIdx2;
}
});
}
// lock down collections
// 为了避免用于无意或者有意事后修改resultMap的内部结构, 克隆一个不可修改的集合提供给用户
resultMap.resultMappings = Collections.unmodifiableList(resultMap.resultMappings);
resultMap.idResultMappings = Collections.unmodifiableList(resultMap.idResultMappings);
resultMap.constructorResultMappings = Collections.unmodifiableList(resultMap.constructorResultMappings);
resultMap.propertyResultMappings = Collections.unmodifiableList(resultMap.propertyResultMappings);
resultMap.mappedColumns = Collections.unmodifiableSet(resultMap.mappedColumns);
return resultMap;
}
private List argNamesOfMatchingConstructor(List constructorArgNames) {
Constructor[] constructors = resultMap.type.getDeclaredConstructors();
for (Constructor constructor : constructors) {
Class[] paramTypes = constructor.getParameterTypes();
if (constructorArgNames.size() == paramTypes.length) {
List paramNames = getArgNames(constructor);
if (constructorArgNames.containsAll(paramNames)
&& argTypesMatch(constructorArgNames, paramTypes, paramNames)) {
return paramNames;
}
}
}
return null;
}
private boolean argTypesMatch(final List constructorArgNames,
Class[] paramTypes, List paramNames) {
for (int i = 0; i < constructorArgNames.size(); i++) {
Class actualType = paramTypes[paramNames.indexOf(constructorArgNames.get(i))];
Class specifiedType = resultMap.constructorResultMappings.get(i).getJavaType();
if (!actualType.equals(specifiedType)) {
if (log.isDebugEnabled()) {
log.debug("While building result map '" + resultMap.id
+ "', found a constructor with arg names " + constructorArgNames
+ ", but the type of '" + constructorArgNames.get(i)
+ "' did not match. Specified: [" + specifiedType.getName() + "] Declared: ["
+ actualType.getName() + "]");
}
return false;
}
}
return true;
}
private List getArgNames(Constructor constructor) {
List paramNames = new ArrayList();
List actualParamNames = null;
final Annotation[][] paramAnnotations = constructor.getParameterAnnotations();
int paramCount = paramAnnotations.length;
for (int paramIndex = 0; paramIndex < paramCount; paramIndex++) {
String name = null;
for (Annotation annotation : paramAnnotations[paramIndex]) {
if (annotation instanceof Param) {
name = ((Param) annotation).value();
break;
}
}
if (name == null && resultMap.configuration.isUseActualParamName() && Jdk.parameterExists) {
if (actualParamNames == null) {
actualParamNames = ParamNameUtil.getParamNames(constructor);
}
if (actualParamNames.size() > paramIndex) {
name = actualParamNames.get(paramIndex);
}
}
paramNames.add(name != null ? name : "arg" + paramIndex);
}
return paramNames;
}
}
ResultMap构建完成之后,添加到Configuration的resultMaps中。我们发现在addResultMap方法中,还有两个针对鉴别器嵌套resultMap处理:
public void addResultMap(ResultMap rm) {
resultMaps.put(rm.getId(), rm);
// 检查本resultMap内的鉴别器有没有嵌套resultMap
checkLocallyForDiscriminatedNestedResultMaps(rm);
// 检查所有resultMap的鉴别器有没有嵌套resultMap
checkGloballyForDiscriminatedNestedResultMaps(rm);
}
应该来说,设置resultMap的鉴别器有没有嵌套的resultMap在解析resultMap子元素的时候就可以设置,当然放在最后统一处理也未尝不可,也不见得放在这里就一定更加清晰,只能说实现的方式有多种。
到此为止,一个根resultMap的解析就完整的结束了。不得不说resutMap的实现确实是很复杂。
5、解析sql片段
sql元素可以被用来定义可重用的SQL代码段,包含在其他语句中。比如,他常被用来定义重用的列:
id,username,password
sql片段的解析逻辑为:
private void sqlElement(List list, String requiredDatabaseId) throws Exception {
for (XNode context : list) {
String databaseId = context.getStringAttribute("databaseId");
String id = context.getStringAttribute("id");
id = builderAssistant.applyCurrentNamespace(id, false);
if (databaseIdMatchesCurrent(id, databaseId, requiredDatabaseId)) {
sqlFragments.put(id, context);
}
}
}
前面讲过,mybatis可以根据不同的数据库执行不同的sql,这就是通过sql元素上的databaseId属性来区别的。同样,首先设置sql元素的id,它必须是当前mapper文件所定义的命名空间。sql元素本身的处理很简单,只是简单的过滤出databaseId和当前加载的配置文件相同的语句以备以后再解析crud遇到时进行引用。之所以不进行解析,是因为首先能够作为sql元素子元素的所有节点都可以作为crud的子元素,而且sql元素不会在运行时单独使用,所以也没有必要专门解析一番。下面我们重点来看crud的解析与内部表示。
6、解析CRUD语句
CRUD是SQL的核心部分,也是mybatis针对用户提供的最有价值的部分,所以研究源码有必要对CRUD的完整实现进行分析。不理解这一部分的核心实现,就谈不上对mybatis的实现有深刻理解。CRUD解析和加载的整体流程如下:
crud的解析从buildStatementFromContext(context.evalNodes(“select|insert|update|delete”));语句开始,透过调用调用链,我们可以得知SQL语句的解析主要在XMLStatementBuilder中实现。
private void buildStatementFromContext(List list) {
if (configuration.getDatabaseId() != null) {
buildStatementFromContext(list, configuration.getDatabaseId());
}
buildStatementFromContext(list, null);
}
private void buildStatementFromContext(List list, String requiredDatabaseId) {
for (XNode context : list) {
final XMLStatementBuilder statementParser = new XMLStatementBuilder(configuration, builderAssistant, context, requiredDatabaseId);
try {
statementParser.parseStatementNode();
} catch (IncompleteElementException e) {
configuration.addIncompleteStatement(statementParser);
}
}
}
在看具体实现之前,我们先大概看下DTD的定义(因为INSERT/UPDATE/DELETE属于一种类型,所以我们以INSERT为例),这样我们就知道整体关系和脉络:
我们先来看statementParser.parseStatementNode()的实现主体部分。
public void parseStatementNode() {
String id = context.getStringAttribute("id");
String databaseId = context.getStringAttribute("databaseId");
if (!databaseIdMatchesCurrent(id, databaseId, this.requiredDatabaseId)) {
return;
}
Integer fetchSize = context.getIntAttribute("fetchSize");
Integer timeout = context.getIntAttribute("timeout");
String parameterMap = context.getStringAttribute("parameterMap");
String parameterType = context.getStringAttribute("parameterType");
Class parameterTypeClass = resolveClass(parameterType);
String resultMap = context.getStringAttribute("resultMap");
String resultType = context.getStringAttribute("resultType");
// MyBatis 从 3.2 开始支持可插拔的脚本语言,因此你可以在插入一种语言的驱动(language driver)之后来写基于这种语言的动态 SQL 查询。
String lang = context.getStringAttribute("lang");
LanguageDriver langDriver = getLanguageDriver(lang);
Class resultTypeClass = resolveClass(resultType);
// 结果集的类型,FORWARD_ONLY,SCROLL_SENSITIVE 或 SCROLL_INSENSITIVE 中的一个,默认值为 unset (依赖驱动)。
String resultSetType = context.getStringAttribute("resultSetType");
// 解析crud语句的类型,mybatis目前支持三种,prepare、硬编码、以及存储过程调用
StatementType statementType = StatementType.valueOf(context.getStringAttribute("statementType", StatementType.PREPARED.toString()));
ResultSetType resultSetTypeEnum = resolveResultSetType(resultSetType);
String nodeName = context.getNode().getNodeName();
// 解析SQL命令类型,目前主要有UNKNOWN, INSERT, UPDATE, DELETE, SELECT, FLUSH
SqlCommandType sqlCommandType = SqlCommandType.valueOf(nodeName.toUpperCase(Locale.ENGLISH));
boolean isSelect = sqlCommandType == SqlCommandType.SELECT;
// insert/delete/update后是否刷新缓存
boolean flushCache = context.getBooleanAttribute("flushCache", !isSelect);
// select是否使用缓存
boolean useCache = context.getBooleanAttribute("useCache", isSelect);
// 这个设置仅针对嵌套结果 select 语句适用:如果为 true,就是假设包含了嵌套结果集或是分组了,这样的话当返回一个主结果行的时候,就不会发生有对前面结果集的引用的情况。这就使得在获取嵌套的结果集的时候不至于导致内存不够用。默认值:false。我猜测这个属性为true的意思是查询的结果字段根据定义的嵌套resultMap进行了排序,后面在分析sql执行源码的时候,我们会具体看到他到底是干吗用的
boolean resultOrdered = context.getBooleanAttribute("resultOrdered", false);
// Include Fragments before parsing
// 解析语句中包含的sql片段,也就是
//
XMLIncludeTransformer includeParser = new XMLIncludeTransformer(configuration, builderAssistant);
includeParser.applyIncludes(context.getNode());
// Parse selectKey after includes and remove them.
processSelectKeyNodes(id, parameterTypeClass, langDriver);
// Parse the SQL (pre: and were parsed and removed)
SqlSource sqlSource = langDriver.createSqlSource(configuration, context, parameterTypeClass);
String resultSets = context.getStringAttribute("resultSets");
String keyProperty = context.getStringAttribute("keyProperty");
String keyColumn = context.getStringAttribute("keyColumn");
KeyGenerator keyGenerator;
String keyStatementId = id + SelectKeyGenerator.SELECT_KEY_SUFFIX;
keyStatementId = builderAssistant.applyCurrentNamespace(keyStatementId, true);
if (configuration.hasKeyGenerator(keyStatementId)) {
keyGenerator = configuration.getKeyGenerator(keyStatementId);
} else {
keyGenerator = context.getBooleanAttribute("useGeneratedKeys",
configuration.isUseGeneratedKeys() && SqlCommandType.INSERT.equals(sqlCommandType))
? Jdbc3KeyGenerator.INSTANCE : NoKeyGenerator.INSTANCE;
}
builderAssistant.addMappedStatement(id, sqlSource, statementType, sqlCommandType,
fetchSize, timeout, parameterMap, parameterTypeClass, resultMap, resultTypeClass,
resultSetTypeEnum, flushCache, useCache, resultOrdered,
keyGenerator, keyProperty, keyColumn, databaseId, langDriver, resultSets);
}
从DTD可以看出,sql/crud元素里面可以包含这些元素:#PCDATA(文本节点) | include | trim | where | set | foreach | choose | if | bind,除了文本节点外,其他类型的节点都可以嵌套,我们看下解析包含的sql片段的逻辑。
/**
* Recursively apply includes through all SQL fragments.
* @param source Include node in DOM tree
* @param variablesContext Current context for static variables with values
*/
private void applyIncludes(Node source, final Properties variablesContext, boolean included) {
if (source.getNodeName().equals("include")) {
Node toInclude = findSqlFragment(getStringAttribute(source, "refid"), variablesContext);
Properties toIncludeContext = getVariablesContext(source, variablesContext);
applyIncludes(toInclude, toIncludeContext, true);
if (toInclude.getOwnerDocument() != source.getOwnerDocument()) {
toInclude = source.getOwnerDocument().importNode(toInclude, true);
}
source.getParentNode().replaceChild(toInclude, source);
while (toInclude.hasChildNodes()) {
toInclude.getParentNode().insertBefore(toInclude.getFirstChild(), toInclude);
}
toInclude.getParentNode().removeChild(toInclude);
} else if (source.getNodeType() == Node.ELEMENT_NODE) {
if (included && !variablesContext.isEmpty()) {
// replace variables in attribute values
NamedNodeMap attributes = source.getAttributes();
for (int i = 0; i < attributes.getLength(); i++) {
Node attr = attributes.item(i);
attr.setNodeValue(PropertyParser.parse(attr.getNodeValue(), variablesContext));
}
}
NodeList children = source.getChildNodes();
for (int i = 0; i < children.getLength(); i++) {
applyIncludes(children.item(i), variablesContext, included);
}
} else if (included && source.getNodeType() == Node.TEXT_NODE
&& !variablesContext.isEmpty()) {
// replace variables in text node
source.setNodeValue(PropertyParser.parse(source.getNodeValue(), variablesContext));
}
}
总的来说,将节点分为文本节点、include、非include三类进行处理。因为一开始传递进来的是CRUD节点本身,所以第一次执行的时候,是第一个else if,也就是source.getNodeType() == Node.ELEMENT_NODE,然后在这里开始遍历所有的子节点。
对于include节点:根据属性refid调用findSqlFragment找到sql片段,对节点中包含的占位符进行替换解析,然后调用自身进行递归解析,解析到文本节点返回之后。判断下include的sql片段是否和包含它的节点是同一个文档,如果不是,则把它从原来的文档包含进来。然后使用include指向的sql节点替换include节点,最后剥掉sql节点本身,也就是把sql下的节点上移一层,这样就合法了。举例来说,这里完成的功能就是把:
id,username,password
转换为下面的形式:
对于文本节点:根据入参变量上下文将变量设置替换进去;
对于其他节点:首先判断是否为根节点,如果是非根且变量上下文不为空,则先解析属性值上的占位符。然后对于子节点,递归进行调用直到所有节点都为文本节点为止。
上述解析完成之后,CRUD就没有嵌套的sql片段了,这样就可以进行直接解析了。现在,我们回到parseStatementNode()刚才中止的部分继续往下看。接下去是解析selectKey节点。selectKey节点用于支持数据库比如Oracle不支持自动生成主键,或者可能JDBC驱动不支持自动生成主键时的情况。对于数据库支持自动生成主键的字段(比如MySQL和SQL Server),那么你可以设置useGeneratedKeys=”true”,而且设置keyProperty到你已经做好的目标属性上就可以了,不需要使用selectKey节点。由于已经处理了SQL片段节点,当前在处理CRUD节点,所以先将包含的SQL片段展开,然后解析selectKey是正确的,因为selectKey可以包含在SQL片段中。
private void parseSelectKeyNode(String id, XNode nodeToHandle, Class parameterTypeClass, LanguageDriver langDriver, String databaseId) {
String resultType = nodeToHandle.getStringAttribute("resultType");
Class resultTypeClass = resolveClass(resultType);
StatementType statementType = StatementType.valueOf(nodeToHandle.getStringAttribute("statementType", StatementType.PREPARED.toString()));
String keyProperty = nodeToHandle.getStringAttribute("keyProperty");
String keyColumn = nodeToHandle.getStringAttribute("keyColumn");
boolean executeBefore = "BEFORE".equals(nodeToHandle.getStringAttribute("order", "AFTER"));
//defaults
boolean useCache = false;
boolean resultOrdered = false;
KeyGenerator keyGenerator = NoKeyGenerator.INSTANCE;
Integer fetchSize = null;
Integer timeout = null;
boolean flushCache = false;
String parameterMap = null;
String resultMap = null;
ResultSetType resultSetTypeEnum = null;
SqlSource sqlSource = langDriver.createSqlSource(configuration, nodeToHandle, parameterTypeClass);
SqlCommandType sqlCommandType = SqlCommandType.SELECT;
builderAssistant.addMappedStatement(id, sqlSource, statementType, sqlCommandType,
fetchSize, timeout, parameterMap, parameterTypeClass, resultMap, resultTypeClass,
resultSetTypeEnum, flushCache, useCache, resultOrdered,
keyGenerator, keyProperty, keyColumn, databaseId, langDriver, null);
id = builderAssistant.applyCurrentNamespace(id, false);
MappedStatement keyStatement = configuration.getMappedStatement(id, false);
configuration.addKeyGenerator(id, new SelectKeyGenerator(keyStatement, executeBefore));
}
解析SelectKey节点总的来说比较简单:
1、加载相关属性;
2、使用语言驱动器创建SqlSource,关于创建SqlSource的细节,我们会在下一节详细分析mybatis语言驱动器时详细展开。SqlSource是一个接口,它代表了从xml或者注解上读取到的sql映射语句的内容,其中参数使用占位符进行了替换,在运行时,其代表的SQL会发送给数据库,如下:
/**
* Represents the content of a mapped statement read from an XML file or an annotation.
* It creates the SQL that will be passed to the database out of the input parameter received from the user.
*
* @author Clinton Begin
*/
public interface SqlSource {
BoundSql getBoundSql(Object parameterObject);
}
mybatis提供了两种类型的实现org.apache.ibatis.scripting.xmltags.DynamicSqlSource和org.apache.ibatis.scripting.defaults.RawSqlSource。
3、SelectKey在实现上内部和其他的CRUD一样,被当做一个MappedStatement进行存储;我们来看下MappedStatement的具体构造以及代表SelectKey的sqlSource是如何组装成MappedStatement的。
public final class MappedStatement {
private String resource;
private Configuration configuration;
private String id;
private Integer fetchSize;
private Integer timeout;
private StatementType statementType;
private ResultSetType resultSetType;
private SqlSource sqlSource;
private Cache cache;
private ParameterMap parameterMap;
private List resultMaps;
private boolean flushCacheRequired;
private boolean useCache;
private boolean resultOrdered;
private SqlCommandType sqlCommandType;
private KeyGenerator keyGenerator;
private String[] keyProperties;
private String[] keyColumns;
private boolean hasNestedResultMaps;
private String databaseId;
private Log statementLog;
private LanguageDriver lang;
private String[] resultSets;
...
}
对于每个语句而言,在运行时都需要知道结果映射,是否使用缓存,语句类型,sql文本,超时时间,是否自动生成key等等。为了方便运行时的使用以及高效率,MappedStatement被设计为直接包含了所有这些属性。
public MappedStatement addMappedStatement(
String id,
SqlSource sqlSource,
StatementType statementType,
SqlCommandType sqlCommandType,
Integer fetchSize,
Integer timeout,
String parameterMap,
Class parameterType,
String resultMap,
Class resultType,
ResultSetType resultSetType,
boolean flushCache,
boolean useCache,
boolean resultOrdered,
KeyGenerator keyGenerator,
String keyProperty,
String keyColumn,
String databaseId,
LanguageDriver lang,
String resultSets) {
if (unresolvedCacheRef) {
throw new IncompleteElementException("Cache-ref not yet resolved");
}
id = applyCurrentNamespace(id, false);
boolean isSelect = sqlCommandType == SqlCommandType.SELECT;
MappedStatement.Builder statementBuilder = new MappedStatement.Builder(configuration, id, sqlSource, sqlCommandType)
.resource(resource)
.fetchSize(fetchSize)
.timeout(timeout)
.statementType(statementType)
.keyGenerator(keyGenerator)
.keyProperty(keyProperty)
.keyColumn(keyColumn)
.databaseId(databaseId)
.lang(lang)
.resultOrdered(resultOrdered)
.resultSets(resultSets)
.resultMaps(getStatementResultMaps(resultMap, resultType, id))
.resultSetType(resultSetType)
.flushCacheRequired(valueOrDefault(flushCache, !isSelect))
.useCache(valueOrDefault(useCache, isSelect))
.cache(currentCache);
// 创建语句参数映射
ParameterMap statementParameterMap = getStatementParameterMap(parameterMap, parameterType, id);
if (statementParameterMap != null) {
statementBuilder.parameterMap(statementParameterMap);
}
MappedStatement statement = statementBuilder.build();
configuration.addMappedStatement(statement);
return statement;
}
MappedStatement本身构建过程很简单,没什么复杂的逻辑,关键部分都在SqlSource的创建上。其中configuration.addMappedStatement里面进行了防重复处理。
4、最后为SelectKey对应的sql语句创建并维护一个KeyGenerator。
解析SQL主体
这一部分到mybatis语言驱动器一节一起讲解。
到此为止,crud部分的解析和加载就完成了。现在我们来看看这个语言驱动器。
sql语句解析的核心:mybatis语言驱动器XMLLanguageDriver
虽然官方名称叫做LanguageDriver,其实叫做解析器可能更加合理。MyBatis 从 3.2 开始支持可插拔的脚本语言,因此你可以在插入一种语言的驱动(language driver)之后来写基于这种语言的动态 SQL 查询比如mybatis除了XML格式外,还提供了mybatis-velocity,允许使用velocity表达式编写SQL语句。可以通过实现LanguageDriver接口的方式来插入一种语言:
public interface LanguageDriver {
ParameterHandler createParameterHandler(MappedStatement mappedStatement, Object parameterObject, BoundSql boundSql);
SqlSource createSqlSource(Configuration configuration, XNode script, Class parameterType);
SqlSource createSqlSource(Configuration configuration, String script, Class parameterType);
}
一旦有了自定义的语言驱动,你就可以在 mybatis-config.xml 文件中将它设置为默认语言:
除了设置默认语言,你也可以针对特殊的语句指定特定语言,这可以通过如下的 lang 属性来完成:
默认情况下,mybatis使用org.apache.ibatis.scripting.xmltags.XMLLanguageDriver。通过调用createSqlSource方法来创建SqlSource,如下:
@Override
public SqlSource createSqlSource(Configuration configuration, XNode script, Class parameterType) {
XMLScriptBuilder builder = new XMLScriptBuilder(configuration, script, parameterType);
return builder.parseScriptNode();
}
@Override
public SqlSource createSqlSource(Configuration configuration, String script, Class parameterType) {
// issue #3
if (script.startsWith("