CSS一个主要的优势就是对所有同类型的元素批量设置样式。觉得没啥了不起的么?试想一下,通过编辑一行CSS,你可以修改所有标题的颜色。随心所欲修改任何你想要的样式,这让你专注在设计上而不是繁重的工作,下一次别人让你修改下标题,你只需简单的编辑然后重新加载,马上就可以看到结果,所见即所得。
当然啦,CSS不能解决所有问题,你不能通过设置CSS来改变PNG图片的colorspace,不过它可以提供一些全局的修改。让我们从选择器和结构开始吧。
基本的样式规则
Grouping聚合
Class和ID选择器
属性选择器
上面提到的class和ID的选择器,其本质还是元素属性的选择。上面两个小结中的语法主要是基于HTML,XHTML,SVG和MathML等这些标记语言的。而在其他的标记语言中这些class和ID的选择器就没法用了。为了解决这个问题,CSS2中引入了属性选择器,方便用户直接选择标签的属性及其对应的值。按照不同的用法可以分为以下4中属性选择器:
- 简单属性选择器(simple attribute selectors)
- 精准属性值选择器(exact attribute value selectors)
- 部分匹配属性值选择器(partial-match attribute selectors)
- 首部值属性选择器(leading-value attribute selectors)
简单属性选择器(simple attribute selectors)
如果你想要选择某个特定的属性,不管属性的值,那么你可以使用简单属性选择器。例如,要选择所有h1元素中包含class属性的那些,改变其文本颜色为silver,则可以这样写:
h1[class] {color: silver;}
Hello
Serenity
Fooling

这一策略针对XML文档很有效果,因为XML总是有一堆的元素和对应的属性名称来描述事物的特征。
举例来说,对于一个想要太阳系行星的XML文档,想要搜索行星边上(标记为pml-planet)有类似月球这种小行星(moons)的情况,可以像下面这样查询:
pml-planet[moons] {font-weight: bold;}
Venus
Earth
Mars
回到HTML中,这一特性可以用在很多地方,例如想要选择所有带有alt属性的images,可以:
img[alt] {border: 3px solid red;}
再来一个例子,如果想要设置所有元素中包含title的元素
*[title] {font-weight: bold;}
另外一次性选择多个属性也是可以的,可以直接挨个写下去,例如:
a[href][title] {font-weight: bold;}
W3C
Standards Info
dead.letter
结果是只有第一个W3C的元素被选中,可见多个[]之间是并集的关系。
针对某个特定的值做选择
如果想把属性的值限定为某个具体值来做更精确的查询,怎可以这样:
a[href="http://www.css-discuss.org/about.html"] {font-weight: bold;}
有意思的是,任何对值得改变,比如上面链接http://www.css-discuss.org/about.html中的协议http到https,或是www没有都会使该匹配消失。
属性的匹配对元素element和attribute没有任何限制,如果没找到匹配的项,那么选择器会直接忽略而不是再做模糊匹配等操作。下面例子中只会匹配制定的第2个earth元素:
planet[moons="1"] {font-weight: bold;}
Venus
Earth
Mars
跟之前的简单匹配一样,属性也可以为多个:
a[href="http://www.w3.org/"][title="W3C Home"] {font-size: 200%;}
W3C
Standards Info
dead.link
结果如下图所示:

值得注意的是,很多人会认为下面两个是一样的:
h1#page-title
h1[id="page-title"].
而事实上他们是有区别的,将会在后面的章节中介绍。
属性值的部分匹配查询
有些时候你希望能够执行部分属性值得匹配,那么CSS中也提供了对应的下面这些子字符串的匹配方式:
| 匹配类型 | 描述 |
|---|---|
| [foo~="bar"] | 查询foo属性中是否包含空格分隔的bar字符串 |
| [foo*="bar"] | 查询foo属性中是否包含bar字符串 |
| [foo^="bar"] | 查询foo属性中是否以bar字符串开头 |
| [foo$="bar"] | 查询foo属性中是否以bar字符串结尾 |
| [foo|="bar"] | 查询foo属性中是否就是bar或是跟着一个横杠(U+002D) |
一个特定的属性选择类型
可能上面最不好理解的就是|=这个了,下面举个例子:
*[lang|="en"] {color: white;}
Hello!
Greetings!
G'day!
Bonjour!
Jrooana!
因为|=匹配字符本身(en)和以en-开头的字符,所以上面的5个元素中前3个被选中,后两个落选。
~=的用法
~=最常出现的使用场景是在class的匹配中:
When handling plutonium, care must be taken to avoid the formation of a critical mass.
p[class~="warning"] {font-weight: bold;}
另外值得一提的是上面的匹配和p.warning是等价的。
*=的用法
有时候你需要匹配属性值中包含的某个部分,这是后*=就派上用场了。
span[class*="cloud"] {font-style: italic;}
Earth
上面这个例子中,span的后面2个包含cloudy的元素被选中。匹配必须是准确的,如果在选择器中包含空白,那么属性值中也必须包含。而且属性的名称和值都是大小写敏感的,Class名称,标题,URL和ID的值都是大小写敏感的,但是HTML的自身属性值却不是,因此下面的例子中仍然可以匹配到:
input[type="CHeckBoX"] {margin-right: 10px;}
^=的用法
^=用于匹配以某个值开头的属性,例如:
a[href^="https:"] {font-weight: bold;}
a[href^="mailto:"] {font-style: italic;}

下面的例子匹配图片的alt属性以Figure开头的元素:
img[alt^="Figure"] {border: 2px solid gray; display: block; margin: 2em auto;}
$=的用法
与上面^=类似,只不过$=是判断以某个字符串结尾的元素:
a[href$=".pdf"] {font-weight: bold;}

大小写不敏感标识符
CSS 选择器 level 4中针对属性选择器引入了大小写敏感选项-i,只要在属性右方括号前加上i,就可以忽略大小写,无视文档语言的规则。
a[href$='.PDF' i]
匹配.pdf, .PDF, .Pdf等所有的pdf后缀字符。这一标识符适用所有的属性选择器
使用Document结构
css之所以强大是因为借助document本身的结构来实现功能,所以如果要深入了解选择器的机制就需要先了解下document的结构。
document结构中的“父子”关系
我们首先来看下document的结构是如何组织的:
Meerkat Central
Meerkat Central
Welcome to Meerkat Central, the best meerkat web site on the entire Internet!
- We offer:
- Detailed information on how to adopt a meerkat
- Tips for living with a meerkat
- Fun things to do with a meerkat, including:
- Playing fetch
- Digging for food
- Hide and seek
- ...and so much more!
Questions? Contact us!
很多css的功能就是基于html document中的父元素-子元素形成的树状结构。在上面的层级过程中,每一个元素不是父元素就是子元素,来看看对应的树状图:
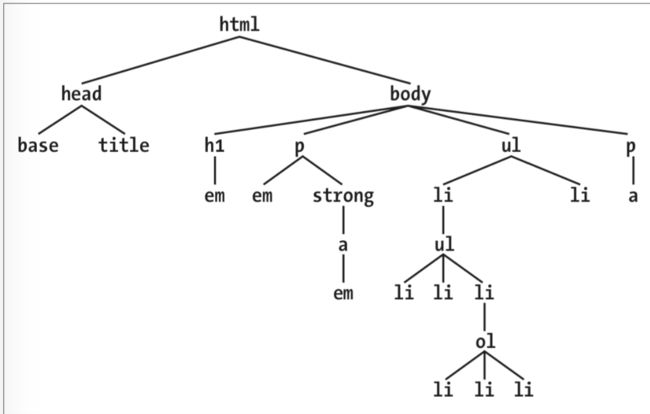
这里有必要强调下一个概念:所谓的parent-child父子关系和ancestor-descendant祖先-后代关系,后者属于更泛的概念,一般的父子关系的层级限制在一层,而祖先后代的关系可以跨越多层,就比如上图中的body是下面所有元素的祖先元素,而只是h1,p,ul,p这四个元素的父元素。
body元素是浏览器默认展示所有内容的祖先,而html则是整个document文档的祖先。正因如此,在一个HTML或是XHTML文档中,html元素同样被称为root元素(根元素)。
后代选择器
理解这一模型的第一个好处就是使用后代选择器,例如你想要选择h1下面的所有em元素,你当然可以为每个满足条件的em元素设定一个class,然而这往往比较费时费力,使用后代选择器则非常简单:
h1 em {color: gray;}

后代选择器其实很强大,能够实现很多HTML种无法实现的功能,举个例子,假定你有个文档是左右布局的,左边侧边栏(sidebar),右边是主要区域(main)。侧边栏背景蓝色,main区域背景白色,两块区域都包含很多链接,但是因为你不可能读取侧边栏中的链接,所以你也就不能够同时设置所有的链接。而通过后代选择器给两个区域分别设置不同的类则非常轻松就实现了:
.sidebar {background: blue;}
.main {background: white;}
.sidebar a:link {color: white;}
.main a:link {color: blue;}

后代选择器的另一个值得注意的特性就是没有元素的就近原则(element proximity),换句话说,规则匹不匹配与元素间的距离(层级距离)没啥关系。举例说明,
div:not(.help) span {color: gray;}
div.help span {color: red;}
This text contains a span element within.
我们来翻译下上面的两句css规则,第一句说的是祖先是div但没有help类的span子元素的颜色置灰;第二句的意思是在div为祖先元素,且有help类的span子元素的颜色设置为红色。那么结果来了,这两个规则将同时作用在上面的span元素上面,那到底最终呈现的额是什么颜色呢?答案是红色,因为两个规则具有相同的权重,那么红色的规则是最后一个,就会覆盖上面一个,所以就显示红色。
选择子类
有时候你还不想选择任意的后代元素,而将选择范围限定在子类中,那么就可以使用>(大于号)来指定了:
h1 > strong {color: red;}
规则只会作用到下面的第一个h1元素,第二个不会,因为第二个strong还不是h1的直接子元素,中间隔着一个em。
This is very important.
This is really very important.
注意h1>strong和h1 > strong是一样的,可以忽略中间的空格。
选择临近的兄弟节点
兄弟节点值得是在dom结构中在同一层级,拥有相同父节点的元素集合。举个例子,如果想要在h1后面的p设置样式,可以这样设置:
h1 + p {margin-top: 0;}
其中+号就是兄弟节点的标识符,为了更形象的理解,看下图:
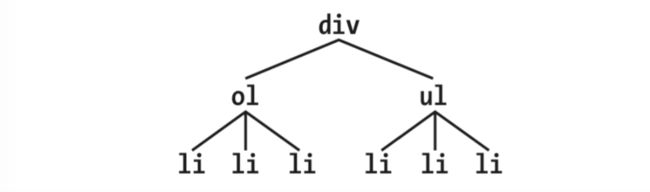
如果你写了一个li + li {font-weight:bold;},那么在下面的列表中只能选第2,第3个,第一个无法选中。

注意,节点间的文本内容是影响不了相邻节点选择器查询的,例如:
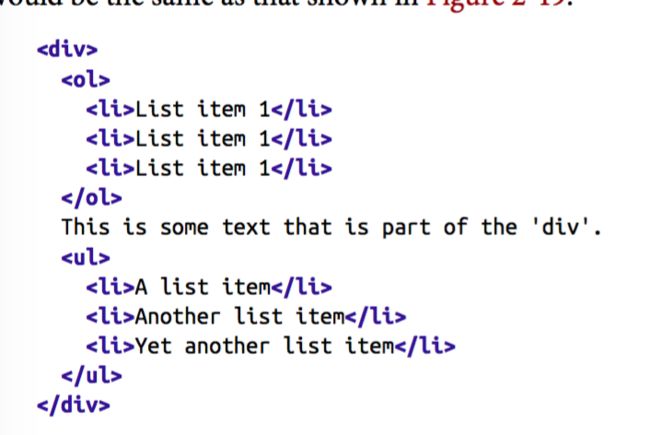
及时有文本加载两个list中间,我们仍可以通过ol + ul来选择第二个list。而如果我们将文本封装在一个元素里面,例如p,那么ol+ul就不起作用了,需要变成ol+p+ul才行。
选择紧接着的兄弟
Level 3的选择器中引入了一个新的兄弟标识符,称之为通用兄弟选择器(general sibling combinator),使用波浪号~来标记。
Subheadings
It is the case that not every heading can be a main heading. Some headings must be subheadings. Examples include:
- Headings that are less important
- Headings that are subsidiary to more important headlines
- Headings that like to be dominated
Let's restate that for the record:
- Headings that are less important
- Headings that are subsidiary to more important headlines
- Headings that like to be dominated
针对上面的dom结构,如果需求是要将h2并列的所有ol节点都设置为斜体,就可以这样写:
h2 ~ol {font-style: italic;}
来看下结果吧:

伪类选择器
结合的伪类(combining Pseudo-Classes)
伪类是可以一起使用的,即所谓的链式法则(chaining),举个例子,如果想要设置未访问的链接在hover的时候变成红色:
a:link:hover {color: red;}
或者说把已访问的链接在hover的时候设置为栗色:
a:visited:hover {color: maroon;}
而且写的伪类的顺序无所谓,再来个绝的,把语言伪类也设置上,固定是德语才起效果:
a:link:hover:lang(de) {color: gray;}
a:visited:hover:lang(de) {color: silver;}
不过得记着别用互斥的伪类,类似a:link:visited 这种写法是非常愚蠢的,而且还不起作用。
结构伪类
大多数的伪类都依赖于dom本身的结构,所有的伪类(无一例外)都是以单个分号开头,而后跟着一个具体的单词。
在开始讲伪类之前需要澄清一件事,所有的伪类总是针对他们绑定的元素(attached),而不是其他,看起来像是废话,而其实对于一些结构伪类来说,将结构伪类想成绑定后代元素的想法是常见的错误。
为了解释清楚这个问题,那自己的真人真事说下更有意思。当我的第一个孩子在2003年出生的时候,我把这个消息发布到了网上。然后当然就是一帮人表示祝贺,顺带开开css的玩笑,而其中最狠的一个就是这样写的:
#ericmeyer:first-child
而其中除了问题就在于这个选择器其实选择的是我自己,而不是我的女儿,而且当且仅当我是我的父母的第一个孩子(当然确实是这样子)。那究竟如何改呢?
#ericmeyer > :first-child
这样讲够形象了吧。所以在下面的章节中请记住选择的是伪类绑定的元素。
选择根元素
借助:root可以选择文档的根目录,不过对于HTML来说好像没啥用,因为可以直接用html就可以直接获取到根目录了。而其实,:root在xml语言中将会非常有用,因为xml中根元素是不固定的,例如RSS2.0中rss是根元素,来看个例子吧:
:root {border: 10px dotted gray;}
body {border: 10px solid black;}
选择空元素
通过:empty伪类可以选择没有子元素的空节点,也包括文本节点。有人会问这有什么用呢?答案是有些CMS想要将没有实际内容的元素隐藏掉,所以像p:empty{display:none;}就派上用处啦。
注意,有些情况下要看仔细了,什么才是真正的空,中间有空格,不算;中间有换行,也不算,比如下面这个例子,只有第1和第4个才是:
为什么说第2个和第3个不是呢,因为空格和换行会被解析为文本节点,所以就不为空了,最后一个中的注释是不会被解析为内容的。
看了上面的如果你想要选中页面上所有的空元素是不是应该这样呢?*:empty {display:none;},如果真这样写就大错特错了,因为像img和input,还有textarea等元素都会被识别为空元素而一同消失,img和img:empty效果是一样的。
选择唯一的子节点
如果你想要选中被一个链接包裹的图片元素,而且是唯一的一个子元素,那么就可以使用:only-child这个伪类。它可以帮助选择所有归属于另一个节点的唯一子节点。一如既往的举例说明,如果说你想要为是唯一子节点的图片来添加一个边框:
img:only-child {border: 1px solid black;}
假设在
元素中包含一个,而且img是唯一的元素,那么这个img也会被选中,不管它的前后是否有文本内容。来个实际例子,选择链接里面的图片:
a[href] img:only-child {border: 2px solid black;}
 The W3C
The W3C
The W3C
The W3C

针对这个:only-child,需要记住两件事:
- 你选择应用的元素是唯一的子节点元素,而不是对应的父节点,也就是搞清楚你到底选择的是哪个元素;
- 当把:only-child应用到后代选择器中时,层级关系不止限于父子关系。比如说a[href] img:only-child,那么这个img可以不是a的直接子节点,也可以是后代。
上面的方案解决了选择唯一节点的问题,但如果父节点中包含多个子元素,那该如何选择img呢?
•
比如上面这个,这时候就可以使用:only-of-type这个伪类:
a[href] img:only-of-type {border: 5px solid black;}
•
•

对比下这两个伪类就会发现,:only-of-type匹配的是所有兄弟节点中是否包含这一元素,而:only-child关注的是匹配的元素必须没有兄弟节点。
section > h2 {margin: 1em 0 0.33em; font-size: 1.8rem; border-bottom: 1px solid gray;}
section > h2:only-of-type {font-size: 2.4rem;}
上面的例子该如何理解呢?对于section下的子阶段,如果有且只有1个h2,那么就会触发第二个,不然的话样式就取第一个。
再来分析一个例子:
p.unique:only-of-type {color: red;}
This paragraph has a 'unique' class.
This paragraph doesn't have a class at all.
看看这个样式会匹配哪个元素呢?答案是两个都没有,因为在div下有两个p,而only-of-type只允许有一个。
选择第一个和最后一个子节点
想要针对一系列的子节点中的第一个或是最后一个节点配置样式是非常常见的,例如导航栏的第一个tab bar元素,要是以前的话还必须为每个元素设置特殊的class,现在的话,伪类就可以帮我们实现。
:first-child用于选择第一个子节点
These are the necessary steps:
- Insert key
- Turn key clockwise
- Push accelerator
Do not push the brake at the same time as the accelerator.
如果css的样式设置为下面这样:
p:first-child {font-weight: bold;}
li:first-child {text-transform: uppercase;}
那么最终显示的结果就是:

这里需要强调的一点就是伪类的翻译,其实按照人的正常逻辑很容易误以为像p:first-child应该解析为p的第一个子节点,而其实就像最早提及的,伪类的翻译更接近于as,就是p as first-child,作为第一个子元素的p,这样来理解就不会走入这个误区。
和:first-child对应的就是:last-child,还是拿我们上个例子来说,如果都改成last-child会是怎么样呢?
p:last-child {font-weight: bold;}
li:last-child {text-transform: uppercase;}
These are the necessary steps:
- Insert key
- Turn key clockwise
- Push accelerator
Do not push the brake at the same time as the accelerator.

有意思的是我们可以将两者结合起来来实现一下上面说到的:only-child,其实看了答案以后就非常简单啦:
p:only-child {color: red;}
p:first-child:last-child {background-color: red;}
上面两个选取的是同一个。
选择第一个或是最后一个类型
就像选择子元素一样,也可以选择对应的类型。来看个例子:
table:first-of-type {border-top: 2px solid gray;}
那么针对下面的结构,蓝色区域就是被选中的节点:
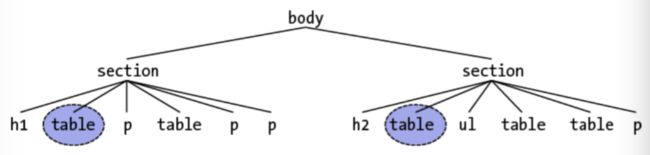
再来看一个常用的例子,在table里面:
td:first-of-type {border-left: 1px solid red;}
Count 7 6
11
Q X - 结果两行tr中的第1个td都可以被选中,不过要是换成了:first-child那么只有第2个被选中了。
和:first-of-type对应的就是:last-of-type,与之前类似,这里直接上之前例子结构中的选择结果:
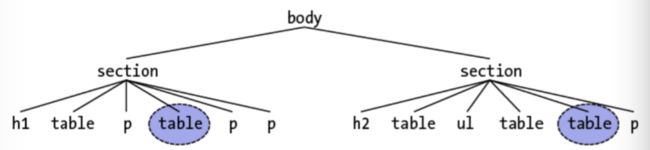
更之前一样,下面两个是一样的效果:
table:only-of-type{color: red;}
table:first-of-type:last-of-type {background: red;}
选择第n个子节点
借助:nth-child()伪类,在括号中填充整数或是简单的代数表达式,我们可以选择任意序列的子元素。
不是说可以选择任意子节点么,首先来试下第一个,也就是:first-child对应的等价表达式:
p:nth-child(1) {font-weight: bold;}
li:nth-child(1) {text-transform: uppercase;}
These are the necessary steps:
- Insert key
- Turn key clockwise
- Push accelerator
Do not push the brake at the same time as the accelerator.
如果我们把数值从1改成2,那么p就没有匹配的了,而li将会匹配第二个:

上面是纯数字的例子,而更强大的是括号里面可以加入简单的代数表达式,形式是固定的:an + b,其中a,b是正整数,而n是代表自增的变量。当然an - b也是可以的。
假定我们要选择一个无序列表中的每3个间隔的列表项,则可以这样写:
ul > li:nth-child(3n + 1) {text-transform: uppercase;}

代数表达式中的n是从0,1,2,3...一直到无穷大的序列,因此3n+1浏览器就解析为1,4,7,10,13。
注意所有的dom元素的序列序号是从1开始的,因此如果在nth-child()的表达式中出现了小于1的值(0和负数)是无效的,不会有任何元素被选中。
因此一个常见的推论就是:nth- child(2n)用来选择偶数项,而:nth-child(2n+1)或是:nth-child(2n-1)用来选择奇数项。当然啦,如果你嫌麻烦,也可以用现成的代号:odd代表奇数,even代表偶数,来看个例子吧。

上面就是选择奇数的情况,另外如果你想使用负号的话就必须把加号去掉,向下面第二种情况,解析器是直接忽略的。
tr:nth-child(4n - 2) {background: silver;}
tr:nth-child(3n + −2) {background: red;}
如果要选择第9个元素开始的所有元素,那么下面两种方式都是可以的:
tr:nth-child(n + 9) {background: silver;}
tr:nth-child(8) ~ tr {background: silver;}
有正向搜索就有反向搜索,因此和nth-child对应的就是nth-last-child,其中的语法与前者完全一致,只不过调整了下检索的顺序从末尾开始。举个例子,如果需要实现从末尾开始的奇数选择,下面两种都是可以的:
tr:nth-last-child(odd) {background: silver;}
tr:nth-last-child(2n+1) {background: silver;}
更高级的玩法是将两者结合起来来实现更精确的选择和需求,就像下面这些,这些规则的组合其实是用来弹性布局末尾几个元素的宽度:
li:only-child {width: 100%;}
li:nth-child(1):nth-last-child(2),
li:nth-child(2):nth-last-child(1) {width: 50%;}
li:nth-child(1):nth-last-child(3),
li:nth-child(1):nth-last-child(3) ~ li {width: 33.33%;}
li:nth-child(1):nth-last-child(4),
li:nth-child(1):nth-last-child(4) ~ li {width: 25%;}
选择第n个子类型
和:nth-child和:nth-last-child对应的就是:nth-of-type() 和:nth-last-of- type().可以忽略其他元素的情况下,针对某个类的元素列表做查找,举个例子,想要查找
段落内部的所有偶数链接的元素,就可以这样:

动态伪类
上面咱们讲完了结构伪类,可是很多情况下即使页面渲染完了,还是存在不少的非结构的动态情况,为了应付这种类型的样式选择,CSS中引入了动态伪类。觉得太抽象?看下我们最常用的链接元素(英文中称为anchor,锚),用户点击了哪些链接事前是不知道的,而如果要已访问的和未访问的做样式的区分就需要动态伪类的帮忙了。
超链接伪类
在CSS2.1中定义了针对链接定义了两个伪类,来看看吧:
| 名称 | 描述 |
|---|---|
| :link | 未访问的链接 |
| :visited | 已访问的链接,出于安全考虑,能够应用到已访问链接的样式是受限的 |
那大家就会说啦,这个第一个的:link好像没啥用啊,如果要定义样式,直接这样不就行了:
a {color: blue;}
a:visited {color: red;}
没有访问的直接用a的样式来代替,但这可以,但是会漏掉一种情况,就是a中没有href属性,比如这样:
4. The Lives of Meerkats
那么上面是会匹配到这一情况的,而a:link就不会,因为这一伪类都需要链接是必须有href属性可跳转的。
使用动作伪类
CSS定义了几个伪类来应对用户的活动,比如激活,移动到元素上面等。虽然大多用在链接上,实际它们可以用在更多的元素上面。
| 名称 | 描述 |
|---|---|
| :focus | 节点获取到输入焦点时触发,例如获取键盘输入或其他方式 |
| :hover | 鼠标指针移动到上面是触发 |
| :active | 元素被用户输入激活时触发,一般像用户点击一个链接,在用户点击鼠标还未抬起的这段时间内就是处于active激活状态 |
适用active的元素其实还不少,除了链接外,像菜单列表项,按钮等都可以。而对于获取焦点的focus状态,基本上所有的交互元素,内容可编辑的元素都是可以实现的。
当然啦,上面提到的4个伪类中应用最广的就是链接了,下面是常见的网站链接的伪类:
a:link {color: navy;}
a:visited {color: gray;}
a:focus {color: orange;}
a:hover {color: red;}
a:active {color: yellow;}
之前说了动态伪类可以应用在任何的元素上面,这就来个例子:
input:focus {background: silver; font-weight: bold;}
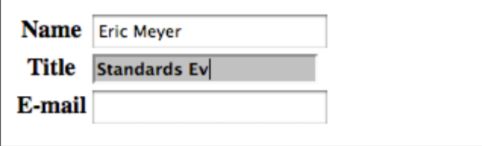
上面的input在每次获得焦点时都会触发样式变化。
UI状态伪类
更动态伪类息息相关的就是UI状态伪类(user-interface state pseudo-classes),我们将他们统一放到下面的表格中:
| 名称 | 描述 |
|---|---|
| :enabled | UI元素,例如表单元素,可以输入状态 |
| :disabled | UI元素禁止使用状态 |
| :checked | 针对radio单选按钮或是checkbox被选中的状态 |
| :indeterminate | radio 按钮或是checkbox的未知状态,既不是checked也不是unchecked,这个状态只能被dom的脚本修改,用户输入是改不了的 |
| :default | 针对radio 按钮,checkbox或是那些默认已选中的元素 |
| :valid | 针对满足数据合理性效验的用户输入 |
| :invalid | 针对不满足数据合理性效验的用户输入 |
| :in-range | 针对用户输入在最小值和最大值之间的元素 |
| :out-of-range | 针对用户输入超出范围的元素 |
| :required | 针对必须有输入的元素 |
| :optional | 针对不必须有用户输入的元素 |
| :read-write | 针对用户可编辑的元素 |
| :read-only | 针对用户不可编辑的元素 |
从上面我们可以看到,修改UI元素状态的不只是有用户输入,文档结构或是DOM的脚本也是可以修改的。
启用/禁用UI元素
借助DOM脚本和HTML5, 我们是可以将元素设置为禁用状态,一旦设置了,那么元素虽然可以显示出来,但却无法激活与编辑选择。设置的方式很多,可以借助dom的脚本实现,也可以通过为元素设置disbled属性来实现。
check状态
针对checkbox或是radio,选择器的Level 3标准定义了:checked伪类,貌似没有对应的:unchecked,但是不是有:indeterminate这一伪类来确定中间状态么,下面就来看个实际的例子:
:checked {background: silver;}
:indeterminate {border: red;}

只有radio按钮和checkbox才会有checked,而其他的元素,包括这两者的未选中状态,都满足:not(:checked),至于这个表达式具体啥含义,卖个关子,因为后面的否定伪类会详细介绍。
除了咱们常见的check和uncheck状态,上面不是还有个indeterminate的模糊状态么,截止2017年底,这个状态只能通过dom脚本或是user agent用户代理(指的一般就是浏览器)自己设置。那么问题就来了,为啥要设置中间状态呢,因为就是要在视觉上强制用户来指定元素的状态,因为中间状态的样式一般都不同,注意上面所说的视觉上这个词,因为其实它是完全不影响UI元素本身的状态的。
:default 默认伪类
:default伪类更多的是在一系列相似元素的集合上,很适合菜单选项。像在页面上默认checked的radio按钮和checkbox都能够匹配default属性,下面来看个例子:
[type="checkbox"]:default + label { font-style: italic; }
必须/可选项伪类
:required用来匹配那些在表单控制中标记为必填的元素,而对应的:optional伪类用来匹配那些不必须的,或者是某个元素的required属性设置为false也是可以匹配到的。
来看个例子:
input:required { border: 1px solid #f00;}
input:optional { border: 1px solid #ccc;}
第一个input匹配required,后面两个匹配optional。同时别忘了我们也可以用属性选择器来代替上面的css样式,来看下如何实现的:
input[required] { border: 1px solid #f00;} input:not([required]) { border: 1px solid #ccc;}
注意如果元素不是表单的input元素的话这两个伪类是不起作用的。
检验数据有效性的伪类
:valid伪类用来匹配所有满足数据合理性的元素,而对应的:invalid用来匹配那些不满足要求的。因此这两个伪类其实是有使用限制的,像div这种完全没有数据合理性要求的元素对这些伪类是无效的。来看个email的input元素的使用例子,要求是对不同的有效性显示不同的背景图:
input[type="email"]:focus { background-position: 100% 50%; background-repeat: no-repeat;
}
input[type="email"]:focus:invalid {
background-image: url(warning.jpg); }
input[type="email"]:focus:valid { background-image: url(checkmark.jpg);
}

范围伪类
伪类:in-range用来匹配数值数据在合理的范围内,最大值最小值可以通过HTML5中的min和max来设置,而对应的伪类:out-of-range就用来匹配那些超出范围的元素。
同样举个例子说明下,我们将范围设定为0-1000:
input[type="number"]:focus { background-position: 100% 50%; background-repeat: no-repeat;
}
input[type="number"]:focus:out-of-range {
background-image: url(warning.jpg); }
input[type="number"]:focus:in-range { background-image: url(checkmark.jpg);
}
\
注意就像上面说的,如果这个input没有范围,例如设定类型为tel等的话范围伪类是没有作用。
在H5中还有一个step属性,就是规定每步的跳跃大小,在这里就要说明一下如果某个元素在范围里面但是却不是规定的step要求,那么在匹配的时候是可以匹配in-range伪类的,但是在合理性上面匹配invalid伪类。举例说明,下面的input就会同时匹配到两个css属性:
input[type="number"]:invalid {color: red;} input[type="number"]:in-range {font-weight: bold;}
可变的伪类
这里说的可变其实指的是元素是否可以编辑,因此就可以猜得出来这里要说的伪类就是:read-only只读的伪类,和:read-write可写的伪类。
在下面的例子中,两条css规则都会匹配到对应的元素,来看下吧:
textarea:read-only { opacity: 0.75;}
pre:read-write:hover {border: 1px dashed green;}
Type your own code!
注意这里出现了一个新的属性contenteditable,就是标记内容是否是可编辑的,一旦设定了就是可以编辑的,所以满足:read-write属性。
:target 伪类
:target伪类用来匹配URL后面的段落分隔符(fragment identifier),其实就是用来定位到页面中的某个具体段落,如果你对这个专用名词还不熟悉的话,来看个具体的url就清楚了:
http://www.w3.org/TR/css3-selectors/#target-pseudo
是不是在很多的url上都看到过,这个段落分隔符就是以#开头的,那如果打开的页面中有个元素的id能够匹配伪类中的名称(就是这里的target-pseudo),那么这个元素就可以应用:target后面的规则。来看个例子:
*:target {border-left: 5px solid gray; background: yellow url(target.png) top right no-repeat;}

不过需要注意:target伪类在下面两种情况下是不能用的:
- URL后面没有段落标识符;
- URL后面有段落标识符,但是页面中完全没有对应的元素
有人要问了,如果一个页面中有好几个id都匹配:target伪类怎么办?其实答案很简单,判断有几个id或者强制用户为元素设定唯一的id是浏览器的事情,而只要是合理的target都可以匹配这一伪类。
:lang伪类
对于那些想要基于语言来选择元素的用户来说就可以用:lang这个伪类。而这一伪类其实和属性选择其中的|=是等价的,来看个例子吧:
*:lang(fr) {font-style: italic;}
*[lang|="fr"] {font-style: italic;}
虽然功能上等价但存在差异,上面两者的主要区别在于语言的信息的来源不同,相较于后者只从lang属性中获取属性,:lang伪类可以匹配元素的所有后代声明的语言信息。选择器的Level 3中是这么讲的:
在HTML中,语言信息是由lang属性,meta中可能的定义和协议,例如http头共同决定的。而在XML中,有专门的xml:lang来定义语言属性,而其他的标记语言也有不同的定义。
所以根据上面说的,伪类相比属性更好的能够获取到语言信息。
否定伪类
之前我们说的那么多伪类都是按照用户需求正向应用规则,有正就有反,所以选择器Level 3中映入了反向或者叫否定伪类:not。相比于其他的选择器,使用上还是有不少限制的,我们还是通过例子来理解吧。
如果想要针对一串li列表中没有moreinfo类的元素来做匹配,没有否定伪类之前几乎是不可能的:
li:not(.moreinfo) {font-style: italic;}

那么来看下:not()伪类是如何工作的把,首先伪类显示匹配你想要的元素(例如上面的li),然后作用括号里面的简单选择器,那什么叫简单选择器呢,根据W3C的定义就是:
类型选择器,通用选择器,属性选择器,类选择器,ID选择器,伪类这几种属于简单选择器。
其实简单来理解就是没有祖先-后代关系的选择器。注意这里是有不少限制的,首先在not的括号中不能混用上面的几类简单选择器,也不准有后代选择器。再回到之前的例子,这次我们要选取的是有moreinfo类但是不属于li列表项的:
.moreinfo:not(li) {font-style: italic;}

另外从技术上讲p:not(*), p:not(p)等都是可以的,不过没有任何意义。再举个例子:选择不在thead中的th元素
*:not(thead) > tr > th
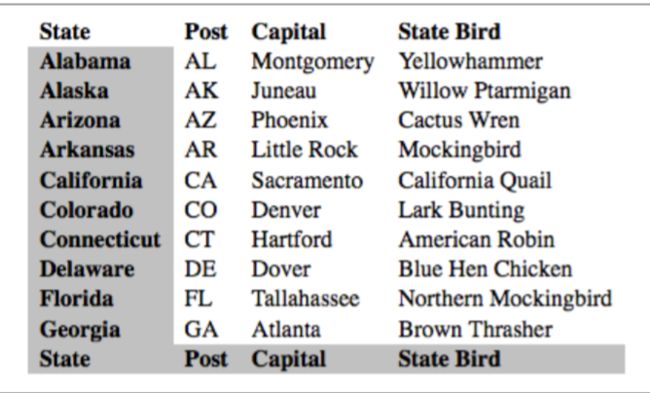
注意否定伪类是不能嵌套的,否则会被忽略,例如像p:not(:not(p))是不行的。但是:not是支持链式写法的:
*.link:not(li):not(p) {font-style: italic;}
每个:not之间是and的关系。有时候我们需要关注多个规则间的冲突,来看个例子:
div:not(.one) p {font-weight: normal;}
div.one p {font-weight: bold;}
I'm a paragraph!
注意上面两个规则都会作用到
上,而由于所谓的级联规则,后者会覆盖前者,因此最终呈现的规则就是粗体的结果。
伪元素选择器
前面见识过不少伪类选择器,而这里我们再来关注下另一类选择器-称为伪元素选择器(Pseudo-Element Selectors),在CSS2中定义了4种伪元素选择器来帮助我们选择元素的第一个字母(::first-letter),元素的第一行(::first-line),元素的前后内容(::before ::after)。当然还有一些其他的,将在后面的章节中介绍(eg: ::marker),之所以把这4个拎出来讲,是因为它们使用很久而且很具有代表性。
不像伪类只有一个冒号,伪元素都有两个冒号。这成了它们的主要区别,而在以前(值得就是CSS2),这两种类型都是使用一个冒号,所以浏览器考虑到兼容性的话也会接受单一冒号作为伪元素选择器的语法。不过别想着偷懒,哪天浏览器不支持了就凉凉了,所以还是老老实实的写2个冒号把。
另一个需要注意的点是伪元素必须放在选择器的最后,像p::first-line em这种是不行的,因为伪元素的解析是在选择器之前,换句话说,每个选择器有且只能有一个伪元素,虽然未来可能会放开这个限制,不过现在(截止2017年底)还不允许。
::first-letter
::first-letter用来匹配元素的第一个字母,下面的例子将每个段落的首字母标记为红色:
p::first-letter {color: red;}
或者想要将第一个段落的首字母变大2倍:
p:first-of-type::first-letter {font-size: 200%;}

想知道浏览器是怎么处理这个的么?首先它会自动生成下面的结构:
T his is a p element, with a styled first letter
这其中的
另一个需要注意的就是样式作用域打印字母为单元的文本域中,像图片这种样式的内容是不支持的。针对不同语言,首字母是不同的,不过伪元素会为我们自动指定合适的语言首字母。
::first-line
和上面的类似,first-line用来设置第一行文本的样式,例如:
p::first-line {
font-size: 150%;
color: purple;
}

这里的第一行的内容其实受多种因素的影响,比如字体大小,字母间的空格,父容器的宽度等等,所以第一行结束的时候其实是很容易出现还处在嵌套元素的情况,比如em或是超链接,而first-line只会讲样式作用于第一行的元素中。
::first-letter和::first-line的限制
这两个伪元素现在只能作用在{display:block}的块级元素上,例如标题和段落,而像超链接这种inline的内联元素则不行。而且对于作用其上的CSS属性也有限制,具体参见下表:
| ::first-letter | ::first-line |
|---|---|
| 所有字体属性 | 所有字体属性 |
| 所有背景属性 | 所有背景属性 |
| 所有文本装饰属性text-decoration | 所有的margin属性 |
| 所有的内联typesetting属性 | 所有的padding属性 |
| 所有的内联layout属性 | 所有的border属性 |
| 所有的border属性 | 所有的文本装饰属性 |
| box-shadow | 所有的内联typesetting属性 |
| color | color |
| opacity | opacity |
元素的前置和后置内容
如果想要在所有的h2元素之前加一对方括号的话,我们可以这样:
h2::before {content: "]]"; color: silver;}
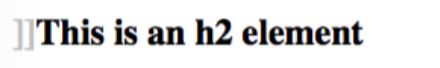
CSS中允许你生成想要的内容,然后通过伪元素类::before和::after放上去。
具体怎么生成内容就是另外一回事了,将在后面的第15章讲解。
小结
通过使用基于document语言的选择器,开发人员可以将创建的css规则应用在一大批相似的元素上面。而将选择器和规则聚合的能力让样式的使用更加紧实灵活,这样就可以使文件更小,下载速度更快。
浏览器和开发者两边都需要正确使用选择器,一边解析必须正确,一边使用必须正确,不然都会导致样式的缺失。而想要正确使用就必须了解选择器是如何关联到document以及它们本身的层级关系,这些因素最终导致了元素的渲染。