论文来源:ACL2017 链接:http://www.aclweb.org/anthology/P/P17/P17-1036.pdf
Aspect extraction,现有的方法使用多种主题模型topic models,但是这些方法不能产生一致的aspect(coherent aspect)。本文提出了一个novel neural approach(新颖的神经网络方法),为了发觉连贯的aspect(coherent aspect)。通过神经网络的word embeddings来获取词共现的分布(the distribution of word co-occurrences)。不像主题模型,只使用独立的词,word embedding模型可以使有相似上下文的词在embedding空间中的距离更近。除此之外,使用attention机制在训练的时候来削弱不相关词。本文的方法可以提取出更有意义和相关的aspect。
Aspect提取有两个子任务:(1)提取所有aspect terms (2)aspect terms的聚类,例如beef, pork 都是food类的。
以前的aspect extraction可以分为三种方法:(1)rule-based,经常不将提取的aspect terms分组到具体的类别中(2)有监督的学习:数据标注,收到领域应用的限制。(3)无监督学习避免了数据标注的麻烦。
近些年,LDA(Latent Dirichlet Allocation)和其变形体成为主宰了aspect extraction的无监督学习。LDA模型对主题(aspects)的建模,主题作为词种类的分布。LDA发现的the mixture of aspect可以很好的描述一个corpus,但是单个aspect的提取是很差的---aspect经常包含不相关的词或者很低关联度的concepts。 ~~~可能有两个原因:(1)传统LDA模型不直接encode word co-occurrence 统计,而是优先主题的coherence。(2)隐式的提取patterns,通过文档级别的word generation建模,假设每个词是generated independently。 除此之外,LDA模型是估计每个文档的主题分布,如果文档很短,使得估计主题分布更加困难。
本文的方法:1. 利用word embedding,已经提取了词的上下文信息。 2. 使用attention机制来过滤word embeddings,然后利用过滤后的word embedding来构建aspect embedding。3. 训练过程 for aspect embedding与autoencoders相似,本文使用降维的方法去提取embedded句子和重构后的每个句子的common factors,通过一个线性的combination of aspect embeddings。attention机制削弱了没有出现在aspect中的词,使得模型更关注在aspect词。
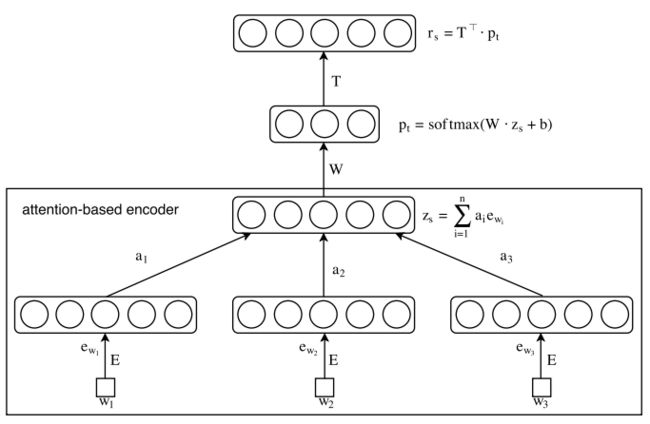
Attention-based Aspect Extraction(ABAE)
Related Work:
过去的方法:寻找频繁项,提取opinion terms通过WordNet中的同义词反义词。 频繁项集挖掘,dependency information。 依赖于提前定义好的规则,只在一少部分名词上work的比较好。
监督学习方法:转换成序列标注问题,使用HMM和CRF,分别使用一组手动提取的特征。最近的,使用自动学习特征,CRF-based aspect extraction。监督学习需要大量标注的数据。并且基于规则的模型通常不够细致,对提取的aspect terms分类。
无监督学习的方法:主题模型,这些模型的输出是word distributions或ranking for aspect。aspect的获取往往没有分离的提取和分类。最近也有一篇是利用RBM来同时提取aspect和sentiment,将aspect和sentiment作为RBM中分离的隐藏节点,然而这个模型依赖于先验知识,例如part-of-speech(POS) tagging词性标注和sentiment lexicons情感词典。 A biterm topic model(BTM)可以生成co-occurring word pairs。
Attention模型被使用在机器翻译,句子总结sentence summarization,情感分类 sentiment classification和问答。不是利用所有的信息,attention模型关注相关信息。
模型:
最终的目标是学习一组aspect embeddings,每个aspect可以理解为在embedding space中查找最近的词。
每个词的embedding是d维向量,所有词的embedding矩阵 E 是V*d的,V是vocabulary的大小。aspect的embedding与word embedding共享同一个空间,aspect的embedding T 是K*d的,K远小于V。aspect embedding用于近似在vocabulary中跟的aspect词,aspect词通过attention 机制过滤。
第一步,通过attention机制降低non-aspect的权重,构建sentence embedding zs from weighted word embeddings。
第二步,用来自T的aspect embedding线性组合重新构建句子embedding,这样进行了降维和重新构建rs。
ABAE想要将转换zs到重新构建的rs,使用最少的变型,保存最多的信息。
Sentence embedding with Attention Mechanism:

ai通过attention模型计算:
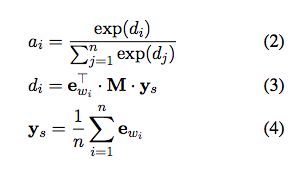
ys是word embedding的平均值,可以捕获句子global的上下文。M是一个权重矩阵d*d的,可以将global的上下文ys与word embedding进行映射,通过学习获得。
认为attention机制分为两步:给定一个句子,首先计算它的平均embedding,然后每个词的权重需要考虑两点:第一是transformation M可以过滤word,这些word可以捕获和K aspect的关系。然后我们捕获过滤后的word和sentence之间的关系,通过过滤后的word和global context ys之间的内积。
Sentence Reconstruction with Aspect Embeddings:
重构句子embedding,包括两步,类似autoencoder,线性连接T

目标函数:
最小化重构误差,使用contrastive max-margin objective!!!!
对每个句子,从训练集中随机采样m个句子, randomly sample m sentences from our training data as negative samples。 每个负采样为ni,通过计算每个词的word embedding的平均值。
目标是使重构的embedding rs与目标句子embedding zs相似,虽然与这些样本不同。所以,没有正则化的目标函数J,is formulated as the hinge loss that最大化rs和zs之间的内积,同时最小化rs和负样本之间的内积。
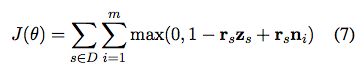
D是训练集,参数是
正则化:
embedding matrix T可能会遇到redundancy。encourage the uniqueness of each aspect embedding:
I是单位矩阵。Tn是将T的每行归一化为1。任何在Tn*TnT中的非对角的元素tij(i不等于j)都与两个不同的aspect embeddings的内积相关联。当任意两个不同的aspect embedding的内积是0的时候,U达到最小值。所以正则化可以使aspect embedding 矩阵T中每行aspect的正交化,同时惩罚不同aspect向量之间的redundancy。最终的目标函数为:
Evaluation:
根据两个标准来判断ABAE:
是否能够找到meaningful和semantically coherent aspect?
是否能改进aspect identification performance on 真实的评价数据集
Coherence Score:
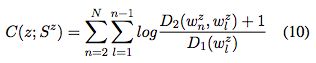
评价aspect的质量,一个aspect z, 和a set of top N words of z,Sz。