第九课 案例分析:共享单车需求
本数据包含某城市共享单车租借数据。共享单车使人们可以一个地方租借自行车并在另一个地方换车,符合目前低碳环保的理念。 新增知识点:
特征工程的概念
日期型变量的处理
相关性分析
问题:
租车人数是由哪些因素决定的?
数据特征描述
datatime - 日期+时间
season - 1=春天,2=夏天,3=秋天,4=冬天
holiday - 是否是节假日
workingday - 1=工作日 0=周末
weather -
1:晴天,多云
2:雾天,阴天
3:小雪,小雨
4:大雨,大雪,大雾
temp - 气温摄氏度
atemp - 体感温度
humidity - 湿度
windspeed - 风速
casual - 非注册用户个数
registered - 注册用户个数
count - 给定日期时间(每小时)总租车人数,是casual和registered的求和。
1、读取数据
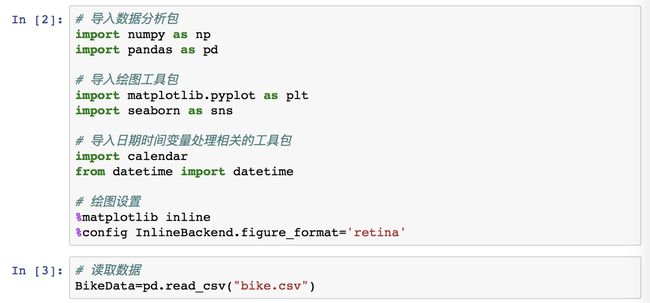
还是一样的套路,导入数据分析包/绘图工具包/时间变量处理相关的工具包/绘图设置,导入基础包之后,再导入共享单车这个案例的数据包,赋值给变量 BikeData。又是一次数据导入,现在的数据读取完全没有压力啦!QQ群或者老师给的 GitHub 链接的资料下载数据,然后在 jupyter 页面,首先是要找到数据所在的路径,然后 upload 数据,文件名不改变的话,都可以直接在 jupyter 里面用 “bike.csv” 来读取使用。
数据上手三部曲
了解数据大小
查看前几行/最后几行数据
查看数据类型与缺失值

此处的 shape 是一个属性,不是对象的一个方法,所以这后面没有(),直接用 .shape 就可以看到数据的大小了——10886 行和 12 列数据。12 列也称为 12 个特征。

用的是 head 语句,查看前十行的数据,我们可以发现,每一行的数据是间隔一个小时的。

在第三步的输出,我们可以看到这份数据的大多数都是字符数据 int,有几个是浮点型 float,还有一个比较特殊的 datetime 是 object 类型,其实也指的是字符串类型。
然后我们可以观察此处是否有缺失值,我们上节课的泰坦尼克号在填充缺失值这一步,就耗费了很多时间呢!总数一共是 10886 行,显示的所有行数都是 10886 行,所以可以看到,这里是没有缺失值的。
这个“数据上手三部曲”的套路,大家可以熟悉一下,毕竟之前我们都是这么学的,后面应该也是这么用的。我的理解就是,这个三部曲就是让我们这些小白在拿到一份数据之后,不会懵逼地不知道自己下一步应该做什么,这个三部曲给了我们一点思路,看整份数据的大小,看前面十行最后十行直观了解数据的内容,然后看数据的整体信息,数据类型,有无缺失值,是否需要填充,后面是否需要增加更多数据,这份数据什么样的思考方向值得继续探索,等等。
我们上面只是对数据进行导入,下面来看对变量进行处理。
2、日期型变量的处理
特征工程(feature engineering)
数据和特征决定了机器学习的上限,而一个好的模型只是逼近那个上限而已
我们的目标是尽可能得从原始数据上获取有用的信息,一些原始数据本身往往不能直接作为模型的变量。
特征工程是利用数据领域的相关知识来创建能够使机器学习算法达到最佳性能的特征的过程。
(又在解密大数据团队的课程回放PPT里面截图了。。)

老师说,从原始数据里面提取的特征,能够尽量地概括描述原始数据。特征工程包括三个子模块:
特征的构建(人工构建)
/特征的提取(自动提取)
/特征的选择(从特征集合中挑选一组最具统计意义的特征子集,从而达到降维的效果)。
老师说这一部分内容的加入,是因为之前使用的时间变量并不能达到我们想要的效果,所以我们学习新的东西来获取新的特征。
来,正经地:
以 datetime 为例子,这个特征里包含了日期和时间点两个重要信息。我们还可以进一步从日期中导出其所对应的月份和星期数。
为了简单起见,取第一个元素:表示是2011年1月1号一点整,是一个字符串

第9行的输出是 “str”,应该大家还记得这表示 ex 是一个字符串类型吧?字符串可以用 split 方法进行拆分的,我们看到原本选取的数据,日期和时间点之间是用空格来区分的,通过 split 语句,我们看到第 10 行,生成了一个列表,这个列表中有两个元素,每个元素都是字符串。此处的目的是拆分字符串,提取相应的日期。
2.1 通过datetime这个特征来生成租车的日期

因为有了上面的列表字符串,所以可以索取这个列表的第 0 个字符串,我们能够得到日期的输出。这里用到了索引的方法。
但是我们这里去到的是一个列的元素,要是我们回到刚开始的那份数据,想要取一排的数据呢?可能很多同学想到的就是用循环来取。老师提醒我们,对整个列进行操作—— apply 方法。之前使用这个方法是在分组数据中使用这个数据的,这个可以对一个列的数据进行同时操作,但是这里我们先要定义一个获取日期的函数。
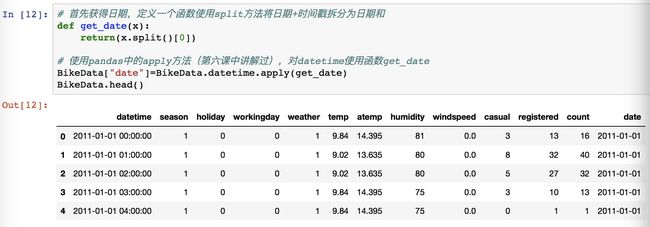
定义函数用 def 开头,函数名 get_date,参数名 X 是之前定义的字符串类型,用 return 作为返回的数值,返回的结果是 ( x.split( )[0] ),也就是如何获取日期的方法。这个输出结果,就把之前含有时间和日期的字符串,返回成只有日期的字符串。有了这个函数,就可以使用 apply 方法来。
把新生成的这一列定义为 date ,然后使用前面的数据,参数是刚刚定义好的 get_date 函数,参数是一个函数名。这样就可以在 datetime 整个函数上进行操作,对每一个函数都进行操作。所以上图的输出最后一列是新增的,此处只剩日期了。
2.2 生成租车时间(24小时)
得到时间的字符串,这个字符串中间是用冒号分隔的。此处用的是 split 来进行分隔,不过之前默认的是空格,这里用的是冒号。

将时分秒转换成列表的形式,转换成小时时,就是需要索引为 0 的元素了。

但是我们要造的不是一列,而是很多列,操作方法还是先定义一个函数:

将这个新赋值的函数用 apply 的方法运用到 datetime 上,然后定义成一个新的列,叫 hour。我们在定义新函数get_hour 后面还是 x,这个 x 表示的是一个字符串,比如在输出的 datetime 中,2011-01-01 00:00:00 这一项,就是 x 的表达。由于使用的是 apply 方法,所以在此处是可以整列操作的,但是每次传递给x的值,只是一个日期。
课堂上的此进度有同学问起,要是删除了datetime ,我们生成的 date 和 hour 会被自动删除吗?余老师回答,不会的。不过必须是在有 datetime 的情况下,先生成 date 和 hour,然后删除的 datetime 是不影响的。我的理解是,Python 里面会会自动更新最新一步,要是修改了数据,会让最新的数据作为更新的条目在代码中,此刻要是已经生成了date 和 hour ,过河拆桥的事情在 Python 中是被允许的。
2.3 生成日期对应的星期数
我们上面讲的是把一串时间分成日期和时间戳,那要是我们需要显示相应的星期数的时候,怎么操作呢?这里会复杂一些,因为不是拆分字符串了,需要数据格式的转换。这节课一开始就导入的数据包里面含有calendar,我们来看看这个这个方法在这里怎么用起来的:

生成了周一到周日的代称。

dateString 是一个字符串类型,把一个字符串分割之后还是一个字符串。对于这个数据类型,此处进行数据类型的转换,使用的是 Python 中的模块 datetime 里面的函数 strptime ,这里使用的 datetime 是 Python 之中的模块,和前面列举的列名是不一样的,虽然名字是重合的。这里的 strptime 从名字上可以看到是把 time 变成字符串的格式,表示从 datetime 时间日期到字符串的转换。这里的参数就是上一句获取日期的字符串 dateString 了,后一个参数 %Y-%m-%d 就是日期的形式了。日期的形式为什么要这样设定呢?因为前面我们生成表格中的日期就是2011-01-01的,要是不设置成一致,此处将会无法识别,通过这样的格式告诉程序,dateString 的格式是这样的,然后将这个字符串转换成相应的日期格式了。将它储存在 dateDT 的变量中。
这里先看类型转换成不成功。type 后的输出是 datetime.datetime,表示的是在模块 datetime 中的 datetime 类型。
我们知道,前面的每一步都是为了后面做铺垫的,这里的转换格式,也是为了后面操作方便,比如下一步要查看日期是星期几的时候,直接用上 dateDT 再加一个 weekday,得到星期几:

这里的 weekday 包含了 0-6 的整数。星期一对应的是 0,星期日对应的是 6,所以这里的输出 5,代表的不是星期五,而是星期六。这里的对应和上面,来,往上翻,第 17 条运行中的 calendar 得出的输出是一一对应的,等于是这里第 19 条运行是在做一个切片索引的活。所以,按照这个逻辑,我们是可以让程序输出到底是星期几,而不是一个可能让人误会的数字:

总结一下套路:
获取数据之后,将数据转换了数据类型变成时间类型的变量
——然后用 weekday 的方法来获取星期的数字
——再通过列表索引的方式获取具体的字符串类型的星期了
然后我们需要把一列数据同时进行转化了,整合一下上面的套路,加上apply 方法:

这里定义的函数其实就是上面三步的整合,输入的参数 dateString 其实就是上面 date 的每一个参数,然后用 strptime 进行类型转换,获取相应星期的数字,返回值通过索引获取相应列表的星期。最后用 apply 方法来获取,注意方法前面对应的是我们后面生成的 date 的这一列,然后这个表和上面的相比,多了星期这一列数据。
接下来讲月份了:(表格越来越宽,我表示截图很困难啊!!!
2.4 生成日期对应的月份
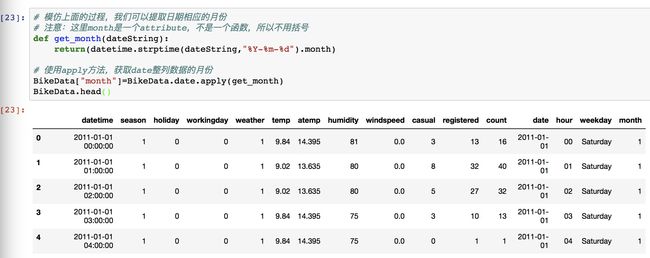
记住,套路都是一样的。
先获取定义月份的函数,输入的类型进行类型转换,直接使用 month 这个属性,就可以获取月份了。我们拉到获取星期的代码去看,使用的是获取星期的方法 weekday ,所以方法后面是要加上圆括号的,这里的 month 用的是它的属性,所以不需要加括号获取月份。这就是一个获取月份的函数了。
直到这里,我们在表格中新增了四列数据,包括 date / hour / weekday / month。
来吧,最后一击!可视化!
2.5 数据可视化举例
绘制租车人数的箱线图, 以及人数随时间(24小时)变化的箱线图
这里需要绘制两幅图,所以一开始需要设置一个比较大的画布,用 figure 的方法给出一个画布,figsize 这个参数决定了整个画布的大小:18*5 ( inch? ) 。不过显示的大小会随着你的屏幕大小进行变换的。
121,还记得吗——这个图中第1行第2列的第1行。
这里用的是 seaborn 里面的 boxplot 来绘制,括号中的参数首先是传递箱图里面的数据 data 是从 BikeData 来的,然后确定横轴和纵轴的参数,由于此处的数据是所有租车的数据,横轴在此处忽略不计,设置纵轴为租车的人数,对应的就是 “count” 这一列了。
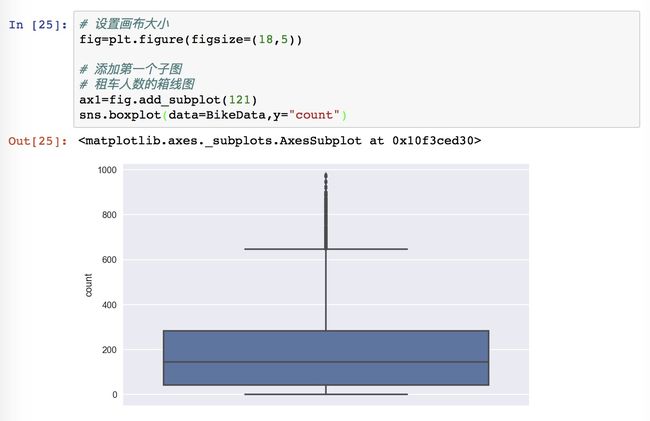
每次的图表设置后,都要想着加上图表横纵轴的标示和图表的标题,因为不说明,别人很难看得出来这个图表讲的内容是什么。

这里使用的是 set 方法来同时设置坐标轴和标题,Y 轴设置的是 “Count”,要是不设置的话,也是有这个标示的,因为对应的就是 count 的那个数据。
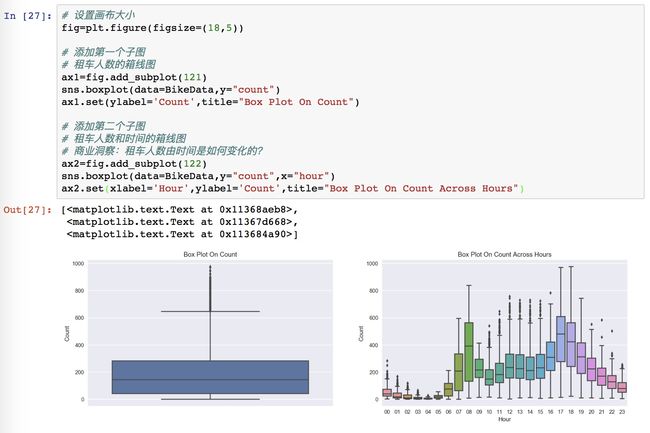
画一个横坐标和时间相关的箱线图,所以这里设置的参数加了 x 的数据 hour来区分。这里是每个小时都画一个箱图。
老师说,画完图,不要沉迷于它的美色。。。
要看图说明了什么问题:它有双峰!上下班的早晚高峰,一个是 8 点,另外两个是 17 点和 18 点。说明还是上班族使用的多哦!你们从图中看到了什么呢,分享一下吧!
作业9-1:
模仿上面的例子,画出 count 与 holiday 的箱线图以及 count 与 month 的箱线图,并将上面的两幅图和新产生的两幅图放到一个画布里。
这节课的这部分讲完了数据导入数据转换的内容,后半部分就是相关性的分析。尽量这两天更新!今晚上课啦!最后一节课了。。。