姓名:陈权 学号:17021211314
转载自:http://mp.weixin.qq.com/s?__biz=MzIzNTE3Mjg1MQ==&mid=2650314126&idx=5&sn=c2f33a8ae9b534b136d0479ca651b799&chksm=f0e71312c7909a04536fc9c0d08a1525e2e07f04163ff84244dfa1e7bf32afec7ced724a103b&mpshare=1&scene=1&srcid=1203wCKgBv8Q1vGfeHQcBF4h#rd
嵌牛导读:报告的前半部分展示了AI Index团队收集的数据。后半部分讨论了报告中没有提到的一些关键领域、专家对报告中显示的趋势的评论,并加入关于AI技术的度量和交流进展的讨论。
嵌牛鼻子:人工智能、机器学习、自然语言、深度学习
嵌牛提问:人工智能与机器学习的前景将会如何?
“AI Index”(AI指数)近日重磅发布,这是斯坦福大学AI百年研究(AI 100)的一个项目,旨在追踪人工智能的活动和进展。该报告列出了2017年人工智能在计算机视觉、自然语言理解等方向上的最新进展,分学术、产业多个角度盘点人工智能进度。报告还综合学术论文数量、招生数量和VC投资数量,得出AI发展活力指数,数据显示,最新一波AI浪潮在2015年活力最高,自那以后其实活力开始有小幅减弱。
报告全文:https://aiindex.org/2017-report.pdf
如果缺乏AI技术的相关数据,我们在有关AI的讨论和决策中,基本上是“盲目的”。
在与人工智能相关的讨论和决策中,我们本质上是“盲目的”。
“AI Index”(AI指数)是斯坦福大学AI百年研究的一个项目,它是一个开放的非营利性项目,旨在追踪人工智能的活动和进展。它的目的是促进以数据为基础的对AI的了解。本报告是AI Index的第一份年度报告,在这份报告中,我们通过多个视角来观察AI的活动和进展。我们汇总了网络上的数据,也贡献了原始数据,并从数据序列的组合中提取新的度量标准。
本报告的数据都将在AI Index网站(aiindex.org)上公开。但是,提供数据只是一个开始。为了真正实现作用,AI指数需要来自更大的社区的支持。最后,这份报告呼吁更多人的参与。你有能力提供数据、分析收集的数据,并列出你希望跟踪的数据。无论你是否有答案或问题,我们都希望这份报告能让你了解AI指数,并成为有关AI的话题的一部分。
报告总览
报告的前半部分展示了AI Index团队收集的数据。后半部分,我们讨论了报告中没有提到的一些关键领域、专家对报告中显示的趋势的评论,最后呼吁采取行动支持我们的数据收集工作,并加入关于AI技术的度量和交流进展的讨论。
数据部分
本报告中的数据包括4个主要部分:
活动量
技术表现
衍生测量
人类水平表现?
活动量(Volume of Activity)部分有关这个领域的“多少”(how much)的方面,例如参加AI会议的人数、VC对开发AI系统的初创公司的投资等。技术表现的部分有关“how good”,例如计算机在理解图像和证明数学定理方面已经做到什么程度。在报告附录中详细描述了每个数据集的收集方法。
这两组数据证实了实际上是公认的一个事实,即:所有的图表都是“向上和向右的”,反映了AI的活动是不断增加,AI技术是不断进步的趋势。在衍生测量(Derivative Measures)部分,我们调查了趋势之间的关系。我们还引入了一个探索性的测量方法——AI活力指数(AI Vibrancy Index),结合了学术界和工业界的趋势,量化了AI作为一个领域的活力。
在衡量AI系统的表现时,很自然地会将其与人类的表现进行比较。在“人类水平表现”面这一节中,我们列出了一些值得注意的领域,其中AI系统在达到甚至超越人类水平方面取得了重大进展。我们还讨论了进行这种比较时存在的困难,并提出了适当的警告。
讨论部分
在报告了团队收集的数据之后,我们将对报告中所强调的趋势进行一些讨论,并对该报告的重要领域进行全面的讨论。
部分讨论集中在报告的局限性上。这份报告的数据源倾向于以美国为中心,并且可能只通过跟踪了定义良好的基准,因此可能高估了技术领域的进展。它还缺乏数据的人口统计数据,也不包含政府和企业对AI研发投资的信息。这些领域是非常重要的,我们打算在未来的报告中解决这些问题。
我们将进一步讨论这些局限,以及其他一些在报告中缺失的部分。正如该报告的局限性所显示的, AI Index 只是描绘了局部图景。出于这个原因,这份报告也加入了各个领域的AI专家的主观评论。专家评论部分补充了对数据背后的故事的生动解释。
最后,我们将需要更多来自社区的反馈和参与来解决报告中显示的局限,揭示我们遗漏的问题,并建立一个追踪AI活动和进展的有效程序。
人工智能和机器学习全景式概览:学术、产业、人才流动、开源生态,各方各面活动量大增
这份报告做了大量调查和统计,从学术(论文发表、会议参加、学生课程选修)、产业(创业、投资)、人才(招聘、职位空缺)、开源生态(Github AI和ML软件包)、媒体报道等方面,比较全面地展现了AI和ML的图景。
1、学术
首先,论文发表数量激增:自从1996年以来,每年发表的AI论文数量增加了9倍以上。

再看不同类别的学术论文的年度发表率与1996年的发表率相比较。下图显示了所有领域的论文、计算机科学领域的论文和计算机科学领域的AI论文的增长。数据表明,人工智能发表论文数量增多,不仅受计算机科学领域升温所致。具体而言,自1996年以来,计算机科学一般领域的论文数量增长了6倍,同期,每年的人工智能论文数量增长了9倍以上。

斯坦福大学入学选修人工智能和机器学习入门课程的学生人数,自从1996年以来增长了11倍以上。报告指出,由于其他大学的数据掌握有限,因此突出了斯坦福的数据。但是,有理由认为,其他大学的情况应该类似。同时,报告表示这只代表了高等教育图景的一个具体细节,不一定代表更广的趋势。
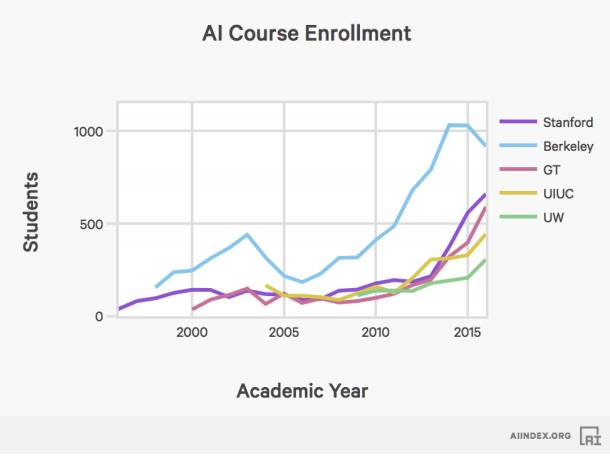

会议出席情况。业内人士都知道,在计算机科学领域,各种学术会议十分重要。这些出席人数表明,研究重点已经从符号推理转向了机器学习和深度学习。

再来看小一些的会议的情况。尽管研究重点有所转换,但是在小一些的研究社区,仍然在符号推理方面稳步进展。

2、产业
现在将目光转向产业界。下图展示了在美国,有资本支持的AI创业公司数量,从2000年以来增加了14倍:

在美国投资AI创业的基金数量也在增长,从2000年以来,每年投入AI创业的资本额增加了6倍:
根据两个在线求职平台Indeed和Monster的数据,人工智能相关岗位需求也在增长。下图展示了Indeed.com平台上,从2013年1月份起,对AI技术相关工作岗位的份额的增长。
而在美国,需要AI技术的工作岗位,在职业市场所占份额,从2013年到现在,有了4.5倍的增长。

按国家看,加拿大和英国的AI人才招聘市场规模也增长迅速。不过,Indeed.com报告指出,两者的绝对值仍然是美国AI招聘市场的5%和27%。
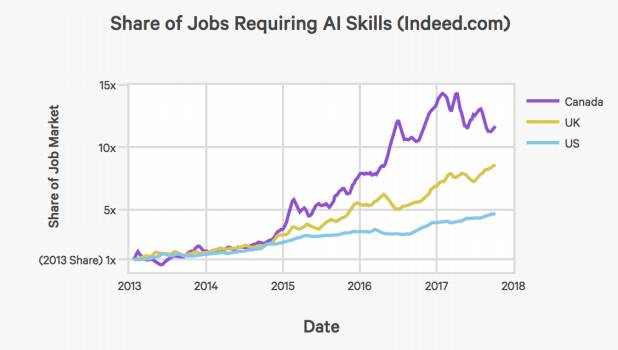
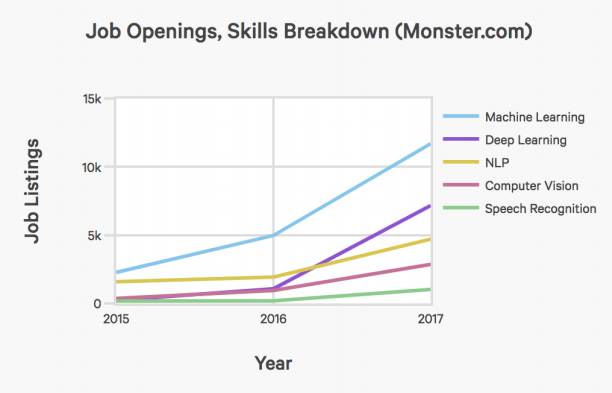
Monster平台上,按具体要求的技能细分,给定年份人工智能职位空缺的总数量:
再来看自动化应用的情况,下图展示了北美和全球工业机器人的购买以及购买增幅。工业机器人的使用正在增加。


3、开源生态
最后看开源软件使用和生态。下图展示了TensorFlow和Scikit-Learn软件包在GitHub上加星标的次数。

这张图展示了Github上其他AI和ML软件包的星标情况。

4、公众认知 / 媒体报道
包含术语“人工智能”的主流媒体文章占所有报道的比例,按照正面情绪(蓝线)、负面情绪(紫线)分类:

技术表现
1. 视觉
物体识别
大规模视觉识别挑战赛(LSVRC)比赛中AI系统对物体检测任务的性能

图像标签的错误率从2010年的28.5%下降到了2.5%。
视觉问答
人工智能系统在完成回答有关图像的开放式问题任务上的表现。截止2017年8月,最好的AI系统准确率还不到70%,而人类水平在85%左右。

2. 自然语言理解
词语解析
人工智能系统在确定句子句法结构上的表现。
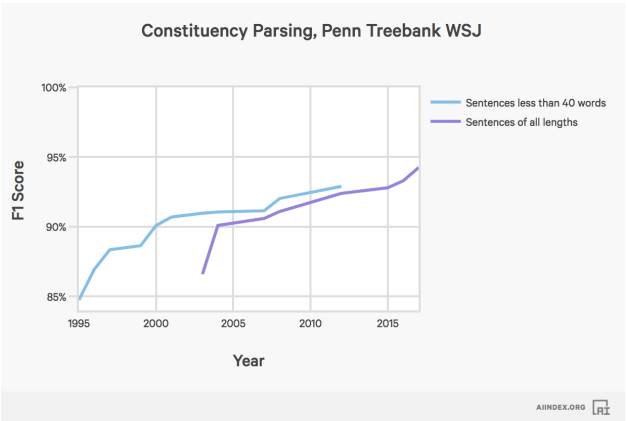
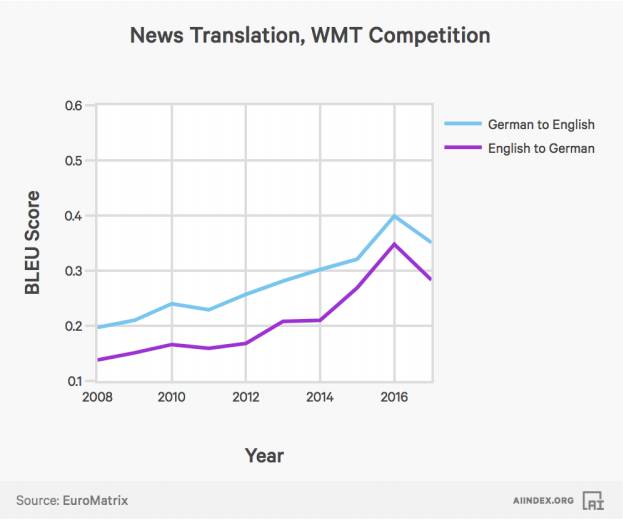
人工智能系统在翻译英文和德文的任务上的表现。
人工智能系统在从文档中找到既定问题答案任务的表现,已经越来越接近人类。

语音识别
人工智能系统识别语音录音的表现,2016已经达到人类水平。
定理证明
自动定理证明指的是一大组定理证明问题的平均易处理性。 “可追踪性”用来测量可以解决问题中最先进的自动定理证明器的一部分。
SAT Solving
具有竞争力的SAT解决者在行业应用问题上的平均表现。
另一种衡量方法:AI活力指数
通过检查各种趋势之间的关系,我们可以从前面部分衡量的标准中获得额外的洞见。下面这一部分的内容展示了AI指数所搜集到的数据如何被用于进一步分析和推动对AI发展和整个原始标准的再定义。
正如一个案例研究所展示的那样,我们通过研究学术和产业界的趋势,来探索他们的动能。进一步地,我们将这些标准综合起来,形成一个AI 活力指数。
Academia-Industry Dynamics
为了探索学术和产业界AI相关活动的关系,我们首先从前面部分的内容中选择了一些有代表性的衡量指标。值得一提的是,我们调查了AI论文的发表情况,结合斯坦福大学入门级 AI 和ML课程的报名情况、VC对AI相关初创企业的投资。这些衡量标准数据是不能直接被拿来比较的:论文发表情况、学生报名情况、投资数额。为了分析这些趋势之间的关系,我们将历史追溯到2000年,这能让我们衡量标准是如何随着时间发生变化的。
数据显示,最初,学术活动(论文发表和招生)驱动稳步前进。 2010年前后,投资者开始注意到这一趋势,这成为2013年投资者总体活动急剧增加的驱动因素。再后来,学术界逐渐赶上了工业的繁荣。
AI活力指数
AI活力指数(AI Vibrancy Index)汇集了对学术和产业的衡量标准(研究成果的发表、招生和VC投资)以对AI领域进行量化。为了计算AI活力指数,我们不断地对研究成果发表数量、招生、投资的标准取平均数。
达到人类水平表现的AI,里程碑
很自然地,我们会在同一个任务上将AI系统和人类的表现进行比较。显然,在某些任务中,计算机比人类要优秀得多,例如,1970年代的小计算器就可以比人类更好地完成算术运算。但是,AI系统在处理诸如回答问题、玩游戏和进行医学诊断等更通用的任务时更加困难。
AI系统的任务往往是在非常窄的背景下进行的,这样能在特定的问题或应用上取得进展。 虽然机器在特定的任务上可能表现出卓越的性能,但是如果任务稍微有所改动,系统性能可能会大大降低。 例如,一个能读懂汉字的人能够理解中国人的言论,了解中国文化,或者在中国餐馆无障碍点餐。相比之下,这些任务中的每一项都需要不同的AI系统来完成。
尽管将人类和AI系统进行比较不是件容易的事情,但列举那些声称计算机已达到或超过人类表现的那些成就很有意思。不过,需要说明的是,这些成就没有说明这些系统具有推广能力。我们还注意到下面的列表包含许多游戏上的成就。游戏是一个相对简单,可控的实验环境,因此经常用于AI研究。
里程碑
黑白棋
在20世纪80年代,李开复和Sanjoy Mahajan开发了一个人工智能系统BILL,这是一个玩“黑白棋”(Othello)游戏的贝叶斯学习系统。1989年这个系统拿了全美冠军,并以56-8击败了排名最高的美国玩家Brian Rose。在1997年,一个名为Logistello的黑白棋程序以6-0占战胜当时的冠军棋手。
跳棋
1952年,Arthur Samuel 设计了一系列玩西洋跳棋的程序,并通过自我对弈进行改进。但是,直到1995年,才出现一个击败人类世界冠军的跳棋程序Chinook。
国际象棋
上世纪50年代的一些计算机科学家预测,到1967年,计算机将击败人类象棋冠军。但直到1997年,IBM的“深蓝”系统才击败当时的国际象棋冠军Gary Kasparov。如今,在智能手机上运行的国际象棋程序可以表现出大师级的水平。
Jeopardy!
2011年,IBM的Watson计算机系统在流行电视节目“Jeopardy!”参与挑战,赢了前冠军Brad Rutter和Ken Jennings。
雅达利游戏
2015年,谷歌DeepMind的一个团队使用强化学习系统来学习如何玩49个Atari游戏。该系统在大多数游戏中都能达到人类水平的表现(例如Breakout打砖块游戏,虽然也有些仍然无法达到人类水平(例如,蒙特祖玛的复仇)。
ImageNet对象检测
2016年,ImageNet自动标注任务的错误率从2010年的28%下降到低于3%。人类的表现大约是5%的错误率。
围棋
2016年3月,谷歌DeepMind团队开发的AlphaGo系统击败了围棋冠军李世乭。DeepMind后来发布了AlphaGo Master,在2017年3月击败了排名第一的柯洁。2017年10月,DeepMind发表在Nature的论文详细介绍了AlphaGo的另一个新版本——AlphaGo Zero,它以100-0击败了最初的AlphaGo系统。
皮肤癌分类
在2017年的一篇Nature论文文章中,Esteva等人描述了一个AI系统,该系统在包含2032种不同疾病的129450张临床图像组成的数据集上训练,研究者将AI系统的诊断结果与21位皮肤科医生的结果进行比较,他们发现AI系统在分类皮肤癌任务上达到与人类皮肤科医生相当的水平。
Switchboard 语音识别
在2017年,微软和IBM都在Switchboard语音识别基准测试中实现了“人类同等水平”的语音识别词错率。
扑克
2017年1月,来自CMU的一个名为Libratus的AI系统在一场包含12万局游戏的双人无限注德州扑克比赛中击败了四名顶尖的人类选手。 2017年2月,来自阿尔伯塔大学的一个名为DeepStack的系统与11名专业玩家分别比赛超过3000局,胜率10/11。
吃豆人
Maluuba是微软收购的一个深度学习团队,他们创建了一个AI系统,该系统学会了在Atari 2600上玩吃豆人游戏打出999900的最高分。