特点:
- 行锁设计
- 支持MVCC
- 支持外键
- 提供一致性非锁定读
- 有效地利用以及使用内存和CPU

1.刷新内存池中的数据,保证缓冲池中的内存缓存是最近的数据
2.将修改的数据文件刷新到磁盘文件
3.数据库发生异常的情况下InnoDB能恢复到正常运行状态
连接 MySQL 操作是一个连接进程和MySQL 数据库实例进行通信。
MySQL 常用进程通信方式
TCP / IP 套接字: mysql -h 192.180.0.1 -uroot -p
UNIX 域套接字:客户单和数据库实例在一台服务器 mysql -uroot -S /tmp/mysql.sock
查看线程变量
>$ show variables like "%threads%"
查看 io 线程
>$ show variables like 'innodb%_io_%'

内存
缓冲池
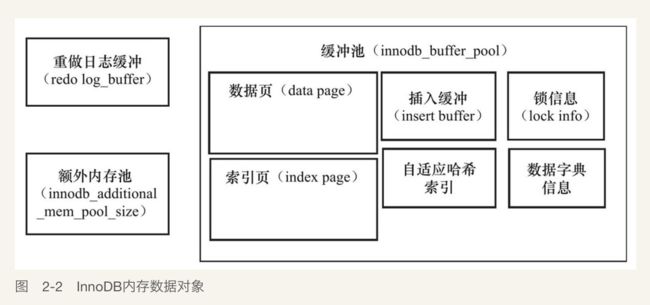
InnoDB存储引擎是基于磁盘存储的,并将其中的记录按照页的方式进行管理。因此可将其视为基于磁盘的数据库系统(Disk-base Database)。
缓冲池简单来说就是一块内存区域,通过内存的速度来弥补磁盘速度较慢对数据库性能的影响。
在数据库中进行读取页的操作,首先将从磁盘读到的页存放在缓冲池中,这个过程称为将页“FIX”在缓冲池中。下一次再读相同的页时,首先判断该页是否在缓冲池中。若在缓冲池中,称该页在缓冲池中被命中,直接读取该页。否则,读取磁盘上的页。
对于数据库中页的修改操作,则首先修改在缓冲池中的页,然后再以一定的频率刷新到磁盘上。这里需要注意的是,页从缓冲池刷新回磁盘的操作并不是在每次页发生更新时触发,而是通过一种称为Checkpoint的机制刷新回磁盘。同样,这也是为了提高数据库的整体性能。
LRU 管理内存池
innodb_old_blocks_pct 新缓存插入到LRU列表尾端37%的位置
innodb_old_blocks_time 页读取到到mid位置后加入到LRU热端需要等待的时间
当页从LRU列表的old部分加入到new部分时,称此时发生的操作为page made young,而因为innodb_old_blocks_time的设置而导致页没有从old部分移动到new部分的操作称为page not made young。可以通过命令SHOW ENGINE INNODB STATUS来观察LRU列表及Free列表的使用情况和运行状态。
>$ show engine innodb status \G;
一个 page 大小为 16kb
buffer pool size (缓冲池容量)
free buffer (空闲列表中可用页的数量)
Database pages (LRU列表中页的数量)
pages made young (LRU列表中页移动到热端的次数)
buffer pool hit rate (缓冲池命中率,若小于95%需检查是否存在全表扫表污染LRU列表)
information_schema.innodb_buffer_pool_stats 缓冲池的运行状态
pool_id
pool_size
free_buffers
database_pages
hit_rate
pages_made_young
pages_not_made_young
information_schema.innodb_buffer_page
The INNODB_BUFFER_PAGE table holds information about each page in the InnoDB buffer pool.
Warning
Querying the INNODB_BUFFER_PAGE table can introduce significant performance overhead.
Do not query this table on a production system unless you are aware of the performance impact
that your query may have, and have determined it to be acceptable.
To avoid impacting performance, reproduce the issue you want to investigate
on a test instance and query the INNODB_BUFFER_PAGE table on the test instance.
| Column Name | Description |
|---|---|
| space | Tablespace ID. Uses the same value as in INNODB_SYS_TABLES.SPACE. |
| fix_count | Number of threads using this block within the buffer pool. When zero, the block is eligible to be evicted. |
| youngest_modification | Log Sequence Number of the youngest modification number |
| oldest_modification | Log Sequence Number of the oldest modification number |
| table_name | Name of the table the page belongs to. This column is only applicable to pages of type INDEX. |
| number_records | Number of records within the page. |
| data_size | Sum of the sizes of the records. This column is only applicable to pages of type INDEX. |
| compressed_size | Compressed page size. Null for pages that are not compressed. |
information_schema.innodb_buffer_page_lru
The INNODB_BUFFER_PAGE_LRU table holds information about the pages in the InnoDB buffer pool, in particular how they are ordered in the LRU list that determines which pages to evict from the buffer pool when it becomes full.
The INNODB_BUFFER_PAGE_LRU table has the same columns as the INNODB_BUFFER_PAGE table, except that the INNODB_BUFFER_PAGE_LRU table has an LRU_POSITIONcolumn instead of a BLOCK_ID column.
| Column Name | Description |
|---|---|
| lru_position | The position of the page in the LRU list |
在LRU列表中的页被修改后,称该页为脏页(dirty page),即缓冲池中的页和磁盘上的页的数据产生了不一致。这时数据库会通过CHECKPOINT机制将脏页刷新回磁盘,而Flush列表中的页即为脏页列表。
buffer pool 中 page 的 3 种状态:
- free,当前页未被使用
- clean,当前页已使用,对应于数据库文件中的一个页面,页面未被修改
- dirty,当前页已使用,对应于数据库文件中的一个页面,页面已被修改
free类型的page,一定位于buf pool的free链表中。
clean,dirty两种类型的page,一定位于buf pool的LRU链表中。dirty page还位于buf pool的flush链表中。flush list中的dirty page,按照page的oldest_modificattion时间排序
Buffer Pool LRU/Flush List flush对比
- LRU list flush,由用户线程触发(MySQL 5.6.2之前);而Flush list flush由MySQL数据库InnoDB存储引擎后台srv_master线程处理。(在MySQL 5.6.2之后,都被迁移到page cleaner线程中)
- LRU list flush,其目的是为了写出LRU 链表尾部的dirty page,释放足够的free pages,当buf pool满的时候,用户可以立即获得空闲页面,而不需要长时间等待;Flush list flush,其目的是推进Checkpoint LSN,使得InnoDB系统崩溃之后能够快速的恢复。
- LRU list flush,其写出的dirty page,需要移动到LRU链表的尾部(MySQL 5.6.2之前版本);或者是直接从LRU链表中删除,移动到free list(MySQL 5.6.2之后版本)。Flush list flush,不需要移动page在LRU链表中的位置。
- LRU list flush,由于可能是用户线程发起,已经持有其他的page latch,因此在LRU list flush中,不允许等待持有新的page latch,导致latch死锁;而Flush list flush由后台线程发起,未持有任何其他page latch,因此可以在flush时等待page latch。
- LRU list flush,每次flush的dirty pages数量较少,基本固定,只要释放一定的free pages即可;Flush list flush,根据当前系统的更新繁忙程度,动态调整一次flush的dirty pages数量,量更大。
(第 3 条的移动什么鬼啊)
重做日志缓冲
- 重做日志缓冲文件:ib_logfile0、ib_logfile1
- 重做日志缓冲一般不需要设置得很大,因为一般情况下每一秒钟会将重做日志缓冲刷新到日志文件,因此用户只需要保证每秒产生的事务量在这个缓冲大小之内即可。该值可由配置参数innodb_log_buffer_size控制,默认为8MB:
❑Master Thread每一秒将重做日志缓冲刷新到重做日志文件;
❑每个事务提交时会将重做日志缓冲刷新到重做日志文件;
❑当重做日志缓冲池剩余空间小于1/2时,重做日志缓冲刷新到重做日志文件。
Checkpoint
Checkpoint(检查点)技术的目的是解决以下几个问题:
❑缩短数据库的恢复时间;
❑缓冲池不够用时,将脏页刷新到磁盘;
❑重做日志不可用时,刷新脏页。(重做日志可以被重用的部分是指这些重做日志已经不再需要,即当数据库发生宕机时,数据库恢复操作不需要这部分的重做日志,因此这部分就可以被覆盖重用。若此时重做日志还需要使用,那么必须强制产生Checkpoint,将缓冲池中的页至少刷新到当前重做日志的位置。)??? 不明白
当数据库发生宕机时,数据库不需要重做所有的日志,因为Checkpoint之前的页都已经刷新回磁盘。故数据库只需对Checkpoint后的重做日志进行恢复。这样就大大缩短了恢复的时间。
---
LOG
---
Log sequence number 10959900802
Log flushed up to 10959900706
Pages flushed up to 10890166048
Last checkpoint at 10890166048
0 pending log flushes, 0 pending chkp writes
11349123 log i/o's done, 2.49 log i/o's/second
Fuzzy Checkpoint:
❑Master Thread Checkpoint
❑FLUSH_LRU_LIST Checkpoint
❑Async/Sync Flush Checkpoint
❑Dirty Page too much Checkpoint
innodb_max_dirty_pages_pct值为75表示,当缓冲池中脏页的数量占据75%时,强制进行Checkpoint,刷新一部分的脏页到磁盘。
Master Thread
Master Thread会根据数据库运行的状态在loop(主循环)、background loop(后台循环)、flush loop(刷新循环)和suspend loop(暂停循环)中进行切换。
每秒一次的操作包括:
❑日志缓冲刷新到磁盘,即使这个事务还没有提交(总是);
❑合并插入缓冲(可能);
❑至多刷新100个InnoDB的缓冲池中的脏页到磁盘(可能);
❑如果当前没有用户活动,则切换到background loop(可能)。
合并插入缓冲(Insert Buffer)并不是每秒都会发生的。InnoDB存储引擎会判断当前一秒内发生的IO次数是否小于5次,如果小于5次,InnoDB认为当前的IO压力很小,可以执行合并插入缓冲的操作。
接着来看每10秒的操作,包括如下内容:
❑刷新100个脏页到磁盘(可能的情况下);
❑合并至多5个插入缓冲(总是);
❑将日志缓冲刷新到磁盘(总是);
❑删除无用的Undo页(总是);
❑刷新100个或者10个脏页到磁盘(总是)。
接着InnoDB存储引擎会进行一步执行full purge操作,即删除无用的Undo页。对表进行update、delete这类操作时,原先的行被标记为删除,但是因为一致性读(consistent read)的关系,需要保留这些行版本的信息。但是在full purge过程中,InnoDB存储引擎会判断当前事务系统中已被删除的行是否可以删除,比如有时候可能还有查询操作需要读取之前版本的undo信息,如果可以删除,InnoDB会立即将其删除。
background loop会执行以下操作:
❑删除无用的Undo页(总是);
❑合并20个插入缓冲(总是);
❑跳回到主循环(总是);
❑不断刷新100个页直到符合条件(可能,跳转到flush loop中完成)。
InnoDB关键特性
❑插入缓冲(Insert Buffer)
❑两次写(Double Write)
❑自适应哈希索引(Adaptive Hash Index)
❑异步IO(Async IO)
❑刷新邻接页(Flush Neighbor Page)
insert buffer 和 change buffer 都是对非辅助索引的操作呀
Insert Buffer
InnoDB存储引擎开创性地设计了Insert Buffer,对于非聚集索引的插入或更新操作,不是每一次直接插入到索引页中,而是先判断插入的非聚集索引页是否在缓冲池中,若在,则直接插入;若不在,则先放入到一个Insert Buffer对象中,好似欺骗。
Insert Buffer的使用需要同时满足以下两个条件:
❑索引是辅助索引(secondary index);
❑索引不是唯一(unique)的。
当满足以上两个条件时,InnoDB存储引擎会使用Insert Buffer,这样就能提高插入操作的性能了。
Inserts代表了插入的记录数;
merged recs代表了合并的插入记录数量;
merges代表合并的次数,也就是实际读取页的次数。
merges:merged recs大约为1∶3,代表了插入缓冲将对于非聚集索引页的离散IO逻辑请求大约降低了2/3。
全局只有一棵Insert Buffer B+树,负责对所有的表的辅助索引进行Insert Buffer。而这棵B+树存放在共享表空间中,默认也就是ibdata1中。因此,试图通过独立表空间ibd文件恢复表中数据时,往往会导致CHECK TABLE失败。
两次写 doublewrite
当发生数据库宕机时,可能InnoDB存储引擎正在写入某个页到表中,而这个页只写了一部分,比如16KB的页,只写了前4KB,之后就发生了宕机,这种情况被称为部分写失效(partial page write)。
重做日志中记录的是对页的物理操作,如偏移量800,写'aaaa'记录。如果这个页本身已经发生了损坏,再对其进行重做是没有意义的。这就是说,在应用(apply)重做日志前,用户需要一个页的副本,当写入失效发生时,先通过页的副本来还原该页,再进行重做,这就是doublewrite。

双写缓冲是一个位于系统表空间中的存储区域,InnoDB缓冲池中刷出的页在被写入数据文件的适当位置之前会先写入这里。只有把页刷出并写入到双写缓冲之后,InnoDB才会把页写入到适当位置。假如此时操作系统、存储子系统或mysqld进程在页写到一半时崩溃,InnoDB在之后崩溃恢复期间可以从双写缓冲中找到一个完好的页拷贝。
doublewrite由两部分组成,一部分是内存中的doublewrite buffer,大小为2MB,另一部分是物理磁盘上共享表空间中连续的128个页,即2个区(extent),大小同样为2MB。在对缓冲池的脏页进行刷新时,并不直接写磁盘,而是会通过memcpy函数将脏页先复制到内存中的doublewrite buffer,之后通过doublewrite buffer再分两次,每次1MB顺序地写入共享表空间的物理磁盘上,然后马上调用fsync函数,同步磁盘,避免缓冲写带来的问题。在这个过程中,因为doublewrite页是连续的,因此这个过程是顺序写的,开销并不是很大。在完成doublewrite页的写入后,再将doublewrite buffer中的页写入各个表空间文件中,此时的写入则是离散的。
自适应哈希 AHI
哈希(hash)是一种非常快的查找方法,在一般情况下这种查找的时间复杂度为O(1),即一般仅需要一次查找就能定位数据。而B+树的查找次数,取决于B+树的高度,在生产环境中,B+树的高度一般为3~4层,故需要3~4次的查询。
AHI是通过缓冲池的B+树页构造而来,因此建立的速度很快,而且不需要对整张表构建哈希索引。InnoDB存储引擎会自动根据访问的频率和模式来自动地为某些热点页建立哈希索引。
AHI是非常好的优化模式,其设计思想是数据库自优化的(self-tuning),即无需DBA对数据库进行人为调整。
由于AHI是由InnoDB存储引擎控制的。
Asynchronous IO,AIO
用户可以在发出一个IO请求后立即再发出另一个IO请求,当全部IO请求发送完毕后,等待所有IO操作的完成,这就是AIO。
Flush Neighbor Page(刷新邻接页)
其工作原理为:当刷新一个脏页时,InnoDB存储引擎会检测该页所在区(extent)的所有页,如果是脏页,那么一起进行刷新。这样做的好处显而易见,通过AIO可以将多个IO写入操作合并为一个IO操作,故该工作机制在传统机械磁盘下有着显著的优势。
启动、关闭与恢复
innodb_fast_shutdown影响着表的存储引擎为InnoDB的行为。该参数可取值为0、1、2,默认值为1。
❑0表示在MySQL数据库关闭时,InnoDB需要完成所有的full purge和merge insert buffer,并且将所有的脏页刷新回磁盘。这需要一些时间,有时甚至需要几个小时来完成。如果在进行InnoDB升级时,必须将这个参数调为0,然后再关闭数据库。
❑1是参数innodb_fast_shutdown的默认值,表示不需要完成上述的full purge和merge insert buffer操作,但是在缓冲池中的一些数据脏页还是会刷新回磁盘。
❑2表示不完成full purge和merge insert buffer操作,也不将缓冲池中的数据脏页写回磁盘,而是将日志都写入日志文件。这样不会有任何事务的丢失,但是下次MySQL数据库启动时,会进行恢复操作(recovery)。