Flink概述
Flink是Apache的一个顶级项目,Apache Flink 是一个开源的分布式流处理和批处理系统。Flink 的核心是在数据流上提供数据分发、通信、具备容错的分布式计算。同时,Flink 在流处理引擎上构建了批处理引擎,原生支持了迭代计算、内存管理和程序优化。
现有的开源计算方案,会把流处理和批处理作为两种不同的应用类型,因为它们所提供的SLA(Service-Level-Aggreement)是完全不相同的:流处理一般需要支持低延迟、Exactly-once保证,而批处理需要支持高吞吐、高效处理。
Flink从另一个视角看待流处理和批处理,将二者统一起来:Flink是完全支持流处理,也就是说作为流处理看待时输入数据流是×××的;批处理被作为一种特殊的流处理,只是它的输入数据流被定义为有界的。
Flink流处理特性:
- 支持高吞吐、低延迟、高性能的流处理
- 支持带有事件时间的窗口(Window)操作
- 支持有状态计算的Exactly-once语义
- 支持高度灵活的窗口(Window)操作,支持基于time、count、session,以及data-driven的窗口操作
- 支持具有Backpressure功能的持续流模型
- 支持基于轻量级分布式快照(Snapshot)实现的容错
- 一个运行时同时支持Batch on Streaming处理和Streaming处理
- Flink在JVM内部实现了自己的内存管理
- 支持迭代计算
- 支持程序自动优化:避免特定情况下Shuffle、排序等昂贵操作,中间结果有必要进行缓存
Flink架构图:
Flink以层级式系统形式组件其软件栈,不同层的栈建立在其下层基础上,并且各层接受程序不同层的抽象形式。
在最基本的层面上,一个Flink应用程序是由以下几部分组成:
- Data source: 数据源,将数据输入到Flink中
- Transformations: 处理数据
- Data sink: 将处理后的数据传输到某个地方
如下图:
目前Flink支持如下框架:
- Apache Kafka (sink/source)
- Elasticsearch 1.x / 2.x / 5.x (sink)
- HDFS (sink)
- RabbitMQ (sink/source)
- Amazon Kinesis Streams (sink/source)
- Twitter (source)
- Apache NiFi (sink/source)
- Apache Cassandra (sink)
- Redis, Flume, and ActiveMQ (via Apache Bahir) (sink)
Flink官网地址如下:
http://flink.apache.org/
部分内容参考自如下文章:
https://blog.csdn.net/jdoouddm7i/article/details/62039337
使用Flink完成wordcount统计
Flink下载地址:
http://flink.apache.org/downloads.html
Flink快速开始文档地址:
https://ci.apache.org/projects/flink/flink-docs-release-1.4/quickstart/setup_quickstart.html
注:安装Flink之前系统中需要安装有jdk1.7以上版本的环境
我这里下载的是2.6版本的Flink:
[root@study-01 ~]# cd /usr/local/src/
[root@study-01 /usr/local/src]# wget http://mirrors.tuna.tsinghua.edu.cn/apache/flink/flink-1.4.2/flink-1.4.2-bin-hadoop26-scala_2.11.tgz
[root@study-01 /usr/local/src]# tar -zxvf flink-1.4.2-bin-hadoop26-scala_2.11.tgz -C /usr/local
[root@study-01 /usr/local/src]# cd ../flink-1.4.2/
[root@study-01 /usr/local/flink-1.4.2]# ls
bin conf examples lib LICENSE log NOTICE opt README.txt resources tools
[root@study-01 /usr/local/flink-1.4.2]#启动Flink:
[root@study-01 /usr/local/flink-1.4.2]# ./bin/start-local.sh
[root@study-01 /usr/local/flink-1.4.2]# jps
6576 Jps
6131 JobManager
6499 TaskManager
[root@study-01 /usr/local/flink-1.4.2]# 启动成功之后就可以访问主机ip的8081端口,进入到Flink的web页面:
我们现在就可以开始实现wordcount案例了,我这里有一个文件,内容如下:
[root@study-01 /usr/local/flink-1.4.2]# cat /data/hello.txt
hadoop welcome
hadoop hdfs mapreduce
hadoop hdfs
hello hadoop
spark vs mapreduce
[root@study-01 /usr/local/flink-1.4.2]#执行如下命令,实现wordcount案例,如果学习过Hadoop会发现这个命令和Hadoop上使用MapReduce实现wordcount案例是类似的:
[root@study-01 /usr/local/flink-1.4.2]# ./bin/flink run ./examples/batch/WordCount.jar --input file:///data/hello.txt --output file:///data/tmp/flink_wordcount_out执行完成后,可以到web页面上,查看任务的执行信息: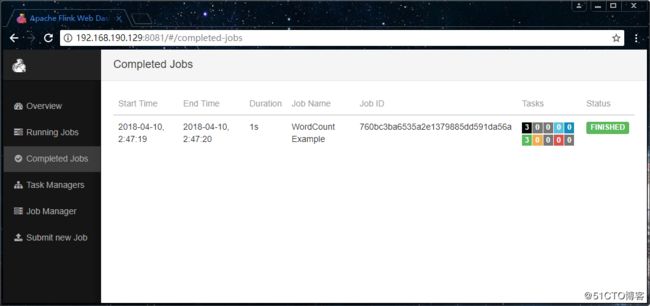
查看输出结果:
[root@study-01 /usr/local/flink-1.4.2]# cat /data/tmp/flink_wordcount_out
hadoop 4
hdfs 2
hello 1
mapreduce 2
spark 1
vs 1
welcome 1
[root@study-01 /usr/local/flink-1.4.2]#Beam概述
Google的新老三驾马车:
- 老的三驾马车:GFS、MapReduce、BigTable
- 新的三驾马车:Dremel、Pregel、Caffeine
我们都知道,Hadoop生态圈内的几个框架都源于Google老的三驾马车,而一些新的框架实现也是部分源于Google新的三驾马车的概念。所以现在市面上的大数据相关框架很多,框架多就会导致编程规范多、处理模式不一致,而我们希望有一个工具能够统一这些编程模型,因此,Beam就诞生了。
Apache Beam是 Apache 软件基金会于2017年1 月 10 日对外宣布的开源平台。Beam 为创建复杂数据平行处理管道,提供了一个可移动(兼容性好)的 API 层。这层 API 的核心概念基于 Beam 模型(以前被称为 Dataflow 模型),并在每个 Beam 引擎上不同程度得执行。
背景:
2016 年 2 月份,谷歌及其合作伙伴向 Apache 捐赠了一大批代码,创立了孵化中的 Beam 项目( 最初叫 Apache Dataflow)。这些代码中的大部分来自于谷歌 Cloud Dataflow SDK——开发者用来写流处理和批处理管道(pipelines)的库,可在任何支持的执行引擎上运行。当时,支持的主要引擎是谷歌 Cloud Dataflow,附带对 Apache Spark 和 开发中的 Apache Flink 支持。如今,它正式开放之时,已经有五个官方支持的引擎。除去已经提到的三个,还包括 Beam 模型和 Apache Apex。
Beam特点:
- 统一了数据批处理(batch)和流处理(stream)编程范式,
- 能在任何执行引擎上运行。
- 它不仅为模型设计、更为执行一系列数据导向的工作流提供了统一的模型。这些工作流包括数据处理、吸收和整合。
Beam的官方网站:
https://beam.apache.org/
将WordCount的Beam程序以多种不同Runner运行
Beam Java的快速开始文档:
https://beam.apache.org/get-started/quickstart-java/
安装Beam的前置也是需要系统具备jdk1.7以上版本的环境,以及Maven环境。
使用如下命令下载Beam以及wordcount案例代码:
mvn archetype:generate \
-DarchetypeGroupId=org.apache.beam \
-DarchetypeArtifactId=beam-sdks-java-maven-archetypes-examples \
-DarchetypeVersion=2.4.0 \
-DgroupId=org.example \
-DartifactId=word-count-beam \
-Dversion="0.1" \
-Dpackage=org.apache.beam.examples \
-DinteractiveMode=false进入下载后的目录进行查看:
[root@study-01 /usr/local/src]# cd word-count-beam/
[root@study-01 /usr/local/src/word-count-beam]# tree
.
├── pom.xml
└── src
├── main
│ └── java
│ └── org
│ └── apache
│ └── beam
│ └── examples
│ ├── common
│ │ ├── ExampleBigQueryTableOptions.java
│ │ ├── ExampleOptions.java
│ │ ├── ExamplePubsubTopicAndSubscriptionOptions.java
│ │ ├── ExamplePubsubTopicOptions.java
│ │ ├── ExampleUtils.java
│ │ └── WriteOneFilePerWindow.java
│ ├── complete
│ │ └── game
│ │ ├── GameStats.java
│ │ ├── HourlyTeamScore.java
│ │ ├── injector
│ │ │ ├── Injector.java
│ │ │ ├── InjectorUtils.java
│ │ │ └── RetryHttpInitializerWrapper.java
│ │ ├── LeaderBoard.java
│ │ ├── StatefulTeamScore.java
│ │ ├── UserScore.java
│ │ └── utils
│ │ ├── GameConstants.java
│ │ ├── WriteToBigQuery.java
│ │ ├── WriteToText.java
│ │ └── WriteWindowedToBigQuery.java
│ ├── DebuggingWordCount.java
│ ├── MinimalWordCount.java
│ ├── WindowedWordCount.java
│ └── WordCount.java
└── test
└── java
└── org
└── apache
└── beam
└── examples
├── complete
│ └── game
│ ├── GameStatsTest.java
│ ├── HourlyTeamScoreTest.java
│ ├── LeaderBoardTest.java
│ ├── StatefulTeamScoreTest.java
│ └── UserScoreTest.java
├── DebuggingWordCountTest.java
├── MinimalWordCountTest.java
└── WordCountTest.java
20 directories, 31 files
[root@study-01 /usr/local/src/word-count-beam]#默认情况下,beam的runner是Direct,下面就用Direct来运行wordcount案例,命令如下:
[root@study-01 /usr/local/src/word-count-beam]# ls
pom.xml src target
[root@study-01 /usr/local/src/word-count-beam]#
[root@study-01 /usr/local/src/word-count-beam]# mvn compile exec:java -Dexec.mainClass=org.apache.beam.examples.WordCount -Dexec.args="--inputFile=/data/hello.txt --output=counts" -Pdirect-runner运行的结果会存放在当前的目录下:
[root@study-01 /usr/local/src/word-count-beam]# ls
counts-00000-of-00003 counts-00001-of-00003 counts-00002-of-00003 pom.xml src target
[root@study-01 /usr/local/src/word-count-beam]# more counts* # 查看结果文件
::::::::::::::
counts-00000-of-00003
::::::::::::::
welcome: 1
spark: 1
::::::::::::::
counts-00001-of-00003
::::::::::::::
hdfs: 2
hadoop: 4
mapreduce: 2
::::::::::::::
counts-00002-of-00003
::::::::::::::
hello: 1
vs: 1
[root@study-01 /usr/local/src/word-count-beam]#如果需要指定其他的runner则可以使用--runner参数进行指定,例如我要指定runner为Flink,则修改命令如下即可:
[root@study-01 /usr/local/src/word-count-beam]# mvn compile exec:java -Dexec.mainClass=org.apache.beam.examples.WordCount -Dexec.args="--runner=FlinkRunner --inputFile=/data/hello.txt --output=counts" -Pflink-runner删除之前生成的文件及目录,我们来使用Spark的方式进行运行。使用Spark的话,也只是修改--runner以及-Pspark参数即可:
[root@study-01 /usr/local/src/word-count-beam]# mvn compile exec:java -Dexec.mainClass=org.apache.beam.examples.WordCount -Dexec.args="--runner=SparkRunner --inputFile=/data/hello.txt --output=counts" -Pspark-runner运行成功后,也是会生成如下文件及目录:
[root@study-01 /usr/local/src/word-count-beam]# ls
counts-00000-of-00003 counts-00001-of-00003 counts-00002-of-00003 pom.xml src target
[root@study-01 /usr/local/src/word-count-beam]#查看处理结果:
[root@study-01 /usr/local/src/word-count-beam]# more counts*
::::::::::::::
counts-00000-of-00003
::::::::::::::
spark: 1
::::::::::::::
counts-00001-of-00003
::::::::::::::
welcome: 1
hello: 1
mapreduce: 2
::::::::::::::
counts-00002-of-00003
::::::::::::::
vs: 1
hdfs: 2
hadoop: 4
[root@study-01 /usr/local/src/word-count-beam]#以上这两个示例只是想说明一点,同一份代码,可以运行在不同的计算引擎上。不需要为不同的引擎开发不同的代码,这就是Beam框架的最主要的设计目的之一。