在上一篇文章里,可以把重点总结成两句话:并不是GC才会STW;和STW 前要挂起所有的线程是分结果阶段的。而关于我们遇到的问题(线上的JVM发现偶尔STW时线程进入SafePoint后把自己挂起的block阶段会很长,最长有1.5s)目前通过我们把年轻代的空间调大后,症状减轻了,变成了好几天才会有一次这个问题出现,背后的逻辑应该是把YGC的时间大大延长后,减少了挂起所有线程的频率(以前是1秒都好几次,现在是6~8s 一次)所致。
这篇文章主要想走读一下SafePoint这段进入STW 阶段的C++代码,来看看VMThread 如何挂起这些Java Thread的,最后再次作出一些可能的猜测。
SafePoint.cpp
void SafepointSynchronize::begin() {
Thread* myThread = Thread::current();
assert(myThread->is_VM_thread(), "Only VM thread may execute a safepoint");
if (PrintSafepointStatistics || PrintSafepointStatisticsTimeout > 0) {
_safepoint_begin_time = os::javaTimeNanos();
_ts_of_current_safepoint = tty->time_stamp().seconds();
}
#if INCLUDE_ALL_GCS
if (UseConcMarkSweepGC) {
// In the future we should investigate whether CMS can use the
// more-general mechanism below. DLD (01/05).
ConcurrentMarkSweepThread::synchronize(false);
} else if (UseG1GC) {
SuspendibleThreadSet::synchronize();
}
#endif // INCLUDE_ALL_GCS
// By getting the Threads_lock, we assure that no threads are about to start or
// exit. It is released again in SafepointSynchronize::end().
Threads_lock->lock();
assert( _state == _not_synchronized, "trying to safepoint synchronize with wrong state");
int nof_threads = Threads::number_of_threads();
if (TraceSafepoint) {
tty->print_cr("Safepoint synchronization initiated. (%d)", nof_threads);
}
RuntimeService::record_safepoint_begin();
MutexLocker mu(Safepoint_lock);
// Reset the count of active JNI critical threads
_current_jni_active_count = 0;
// Set number of threads to wait for, before we initiate the callbacks
_waiting_to_block = nof_threads;
TryingToBlock = 0 ;
int still_running = nof_threads;
// Save the starting time, so that it can be compared to see if this has taken
// too long to complete.
jlong safepoint_limit_time = 0;
timeout_error_printed = false;
这里介绍一下SafepointSynchronize::begin() 这个方法是VM Thread 调用的,在比如GC,JIT Compile, Loading Jar 这种需要STW的时候,这个VM Thread就需要调用这个方法来STW,然后等所有的Java Thread (除了GC Thread)都block住之后,就会做它本来想做的事情(vm operation) 最后唤醒所有线程。
在这个方法的开始部分,除了一些加锁操作外,留意一下这三个变量的初始化:
_waiting_to_block = nof_threads;
TryingToBlock = 0 ;
int still_running = nof_threads;
我们再回顾一下遇到问题时的截图

对照这三个变量就是,
nof_threads 是485 总数。
接下来继续往下看,接着是一段注释
// Begin the process of bringing the system to a safepoint.
// Java threads can be in several different states and are
// stopped by different mechanisms:
//
// 1. Running interpreted
// The interpeter dispatch table is changed to force it to
// check for a safepoint condition between bytecodes.
// 2. Running in native code
// When returning from the native code, a Java thread must check
// the safepoint _state to see if we must block. If the
// VM thread sees a Java thread in native, it does
// not wait for this thread to block. The order of the memory
// writes and reads of both the safepoint state and the Java
// threads state is critical. In order to guarantee that the
// memory writes are serialized with respect to each other,
// the VM thread issues a memory barrier instruction
// (on MP systems). In order to avoid the overhead of issuing
// a memory barrier for each Java thread making native calls, each Java
// thread performs a write to a single memory page after changing
// the thread state. The VM thread performs a sequence of
// mprotect OS calls which forces all previous writes from all
// Java threads to be serialized. This is done in the
// os::serialize_thread_states() call. This has proven to be
// much more efficient than executing a membar instruction
// on every call to native code.
// 3. Running compiled Code
// Compiled code reads a global (Safepoint Polling) page that
// is set to fault if we are trying to get to a safepoint.
// 4. Blocked
// A thread which is blocked will not be allowed to return from the
// block condition until the safepoint operation is complete.
// 5. In VM or Transitioning between states
// If a Java thread is currently running in the VM or transitioning
// between states, the safepointing code will wait for the thread to
// block itself when it attempts transitions to a new state.
在前一篇文章已经介绍过了,其实VM Thread去挂起正在做不同事情的Java Thread 是需要做不同的事情的,到目前为止我记录到的现象是,这个block很长的,Initial Running 都是0,waiting to block 都是1或者几。
那么我们继续读下面的代码,看是如何去到 485 0 1 的
// Iterate through all threads until it have been determined how to stop them all at a safepoint
unsigned int iterations = 0;
int steps = 0 ;
while(still_running > 0) {
for (JavaThread *cur = Threads::first(); cur != NULL; cur = cur->next()) {
assert(!cur->is_ConcurrentGC_thread(), "A concurrent GC thread is unexpectly being suspended");
ThreadSafepointState *cur_state = cur->safepoint_state();
if (cur_state->is_running()) {
cur_state->examine_state_of_thread();
if (!cur_state->is_running()) {
still_running--;
// consider adjusting steps downward:
// steps = 0
// steps -= NNN
// steps >>= 1
// steps = MIN(steps, 2000-100)
// if (iterations != 0) steps -= NNN
}
if (TraceSafepoint && Verbose) cur_state->print();
}
}
if (PrintSafepointStatistics && iterations == 0) {
begin_statistics(nof_threads, still_running);
}
if (still_running > 0) {
// Check for if it takes to long
if (SafepointTimeout && safepoint_limit_time < os::javaTimeNanos()) {
print_safepoint_timeout(_spinning_timeout);
}
这里面抓哟的逻辑就是:遍历一把所有的线程,然后做一次cur_state->examine_state_of_thread();如果判断不是running了则可以减一,再看看这个方法cur_state->examine_state_of_thread()里面主逻辑是:
void ThreadSafepointState::examine_state_of_thread() {
JavaThreadState state = _thread->thread_state();
// Save the state at the start of safepoint processing.
_orig_thread_state = state;
bool is_suspended = _thread->is_ext_suspended();
if (is_suspended) {
roll_forward(_at_safepoint);
return;
}
// Some JavaThread states have an initial safepoint state of
// running, but are actually at a safepoint. We will happily
// agree and update the safepoint state here.
if (SafepointSynchronize::safepoint_safe(_thread, state)) {
SafepointSynchronize::check_for_lazy_critical_native(_thread, state);
roll_forward(_at_safepoint);
return;
}
if (state == _thread_in_vm) {
roll_forward(_call_back);
return;
}
这里VM Thread会check一下每个Java Thread,如果它本身就是挂起的(我的机器只有24个核,就算它用满其实也有400多个被挂起了),那么直接标记它进入了SafePoint,我们等一下再去看那个roll_forward()方法, 现在先看第二种判断
bool SafepointSynchronize::safepoint_safe(JavaThread *thread, JavaThreadState state) {
switch(state) {
case _thread_in_native:
// native threads are safe if they have no java stack or have walkable stack
return !thread->has_last_Java_frame() || thread->frame_anchor()->walkable();
// blocked threads should have already have walkable stack
case _thread_blocked:
assert(!thread->has_last_Java_frame() || thread->frame_anchor()->walkable(), "blocked and not walkable");
return true;
default:
return false;
}
}
这里我并不了解这个has_last_Java_frame() 和frame_anchor()->walkable()我先暂且觉得只要进入了 in_native状态的Java Thread 全都进入了SafePoint。那再看看roll_forward的定义:
void ThreadSafepointState::roll_forward(suspend_type type) {
_type = type;
switch(_type) {
case _at_safepoint:
SafepointSynchronize::signal_thread_at_safepoint();
DEBUG_ONLY(_thread->set_visited_for_critical_count(true));
if (_thread->in_critical()) {
// Notice that this thread is in a critical section
SafepointSynchronize::increment_jni_active_count();
}
break;
case _call_back:
set_has_called_back(false);
break;
case _running:
default:
ShouldNotReachHere();
}
}
在roll_forward()里,第一行就很重要:把该线程的_type直接从running 置成 type (比如_at_safepoint),这个会直接影响到最上面examine_state_of_thread()后的判断;
接着,比较醒目的是这句SafepointSynchronize::signal_thread_at_safepoint(); 这句代码只有一行
static void signal_thread_at_safepoint() { _waiting_to_block--; }
那从examine_state_of_thread()一直往下的所有代码,它大致意思就是,把那些挂起的,in_native 的,这些线程都标记为已经进入SafePoint了,并且把这个统计变量做_waiting_to_block-- 操作,而如果Java Thread扔还在跑Java Code时,则只做一个_call_back 状态标记。
好了,所有的这些操作都将会影响到examine_state_of_thread()接着的判断,我们再回到最初examine_state_of_thread():
while(still_running > 0) {
for (JavaThread *cur = Threads::first(); cur != NULL; cur = cur->next()) {
assert(!cur->is_ConcurrentGC_thread(), "A concurrent GC thread is unexpectly being suspended");
ThreadSafepointState *cur_state = cur->safepoint_state();
if (cur_state->is_running()) {
cur_state->examine_state_of_thread();
if (!cur_state->is_running()) {
still_running--;
// consider adjusting steps downward:
// steps = 0
// steps -= NNN
// steps >>= 1
// steps = MIN(steps, 2000-100)
// if (iterations != 0) steps -= NNN
}
if (TraceSafepoint && Verbose) cur_state->print();
}
}
大家还记得我们的场景是 485 0 1 吗, 也就是说,过完这个while循环, 我们的still_running要减到0, 也就是说,所有的Java Thread 当初都是 is_running,然后都不是is_running了,也就是说,有484 个线程它要么被挂起了,要么是执行native 要么是已经在SafePoint 了。只有1个线程,它要么在in_java_code, 要么 thread_in_vm, 而,因为它
必须不能是running,所以它必须只能是 thread_in_vm.
接着,一大段的 if(is_still_running > ) 都直接pass掉,直到:
if (PrintSafepointStatistics) {
update_statistics_on_spin_end();
}
// wait until all threads are stopped
while (_waiting_to_block > 0) {
if (TraceSafepoint) tty->print_cr("Waiting for %d thread(s) to block", _waiting_to_block);
if (!SafepointTimeout || timeout_error_printed) {
Safepoint_lock->wait(true); // true, means with no safepoint checks
} else {
// Compute remaining time
jlong remaining_time = safepoint_limit_time - os::javaTimeNanos();
// If there is no remaining time, then there is an error
if (remaining_time < 0 || Safepoint_lock->wait(true, remaining_time / MICROUNITS)) {
print_safepoint_timeout(_blocking_timeout);
}
}
}
这里就是上一篇文章那个地方了,也就是说,VM Thread 把所有的Java Thread标记完了,如果还有线程还处于_waiting_to_block的话,它只能把自己先挂起,等待这些线程都把自己block住,再通知自己。
我们确实还有一个这样的线程,它之前的状态是 thread_in_vm, 为什么说之前的状态呢,还记得吗?在roll_foward()里它已近置成call_back了。
好,现在我们来关心这个活动的Java Thread的去向,和它究竟何时去唤醒我们的VM Thread。大家都知道,VM Thread需要STW时,它往所有的Java Thread设置阑珊,所有的线程在SafePoint里把自己block的手段就放在这个make_polling_page_unreadable里(在SafePoint.cpp里找到)
// Mark the polling page as unreadable
void os::make_polling_page_unreadable(void) {
if( !guard_memory((char*)_polling_page, Linux::page_size()) )
fatal("Could not disable polling page");
};
...
bool os::guard_memory(char* addr, size_t size) {
return linux_mprotect(addr, size, PROT_NONE);
}
而实现在 os_linux_86.cpp
extern "C" JNIEXPORT int
JVM_handle_linux_signal(int sig,
siginfo_t* info,
void* ucVoid,
int abort_if_unrecognized) {
ucontext_t* uc = (ucontext_t*) ucVoid;
...
pc = (address) os::Linux::ucontext_get_pc(uc);
...
if (thread->thread_state() == _thread_in_Java) {
// Java thread running in Java code => find exception handler if any
// a fault inside compiled code, the interpreter, or a stub
if (sig == SIGSEGV && os::is_poll_address((address)info->si_addr)) {
stub = SharedRuntime::get_poll_stub(pc);
}
..
这里我们不关心具体的OS调用了,我们唯一好奇的如果往后的代码都不会长时间阻塞一个线程的话,那么阻塞很可能就在这里了。
那我们继续往后看
这个线程当然最终会读这个page不成功,触发 pageFail,然后会回到VM里回调方法SafepointSynchronize::handle_polling_page_exception这里有个细节让我注意到了
// ------------------------------------------------------------------------------------------------------
// Exception handlers
void SafepointSynchronize::handle_polling_page_exception(JavaThread *thread) {
assert(thread->is_Java_thread(), "polling reference encountered by VM thread");
assert(thread->thread_state() == _thread_in_Java, "should come from Java code");
assert(SafepointSynchronize::is_synchronizing(), "polling encountered outside safepoint synchronization");
if (ShowSafepointMsgs) {
tty->print("handle_polling_page_exception: ");
}
if (PrintSafepointStatistics) {
inc_page_trap_count();
}
ThreadSafepointState* state = thread->safepoint_state();
state->handle_polling_page_exception();
}
大家看到吗,在这里它会累加一下那个 nof_page_trap, 但是从我们的问题截图上看,这个数字是0,所以这点我还不知道怎么去解释,所以只能解释的是,我们看到的问题截图那个message,是VMThread 仍处于阻塞的时候打印的。

最后会调用ThreadSafepointState::handle_polling_page_exception()在这个方法里,主要是处理一些线程返回指针和地址的一些问题,到这里我几乎都看不懂了。唯一认识的就是它会去调SafepointSynchronize::block(thread());
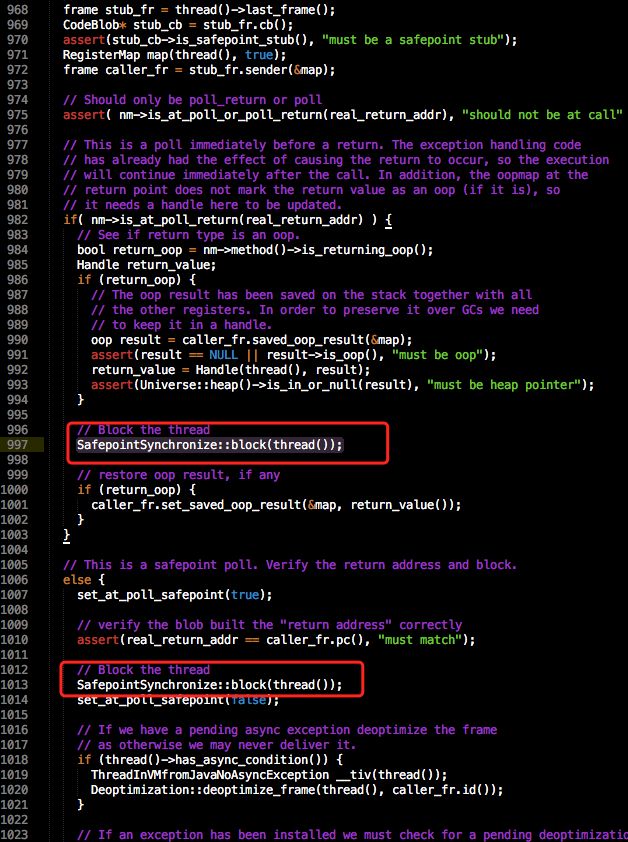
// Implementation of Safepoint callback point
void SafepointSynchronize::block(JavaThread *thread) {
... //此处省略部分代码
// Check that we have a valid thread_state at this point
switch(state) {
case _thread_in_vm_trans:
case _thread_in_Java: // From compiled g
// We are highly likely to block on the Safepoint_lock. In order to avoid blocking in this case,
// we pretend we are still in the VM.
thread->set_thread_state(_thread_in_vm);
if (is_synchronizing()) {
Atomic::inc (&TryingToBlock) ;
}
// We will always be holding the Safepoint_lock when we are examine the state
// of a thread. Hence, the instructions between the Safepoint_lock->lock() and
// Safepoint_lock->unlock() are happening atomic with regards to the safepoint code
Safepoint_lock->lock_without_safepoint_check();
if (is_synchronizing()) {
// Decrement the number of threads to wait for and signal vm thread
assert(_waiting_to_block > 0, "sanity check");
_waiting_to_block--;
thread->safepoint_state()->set_has_called_back(true);
DEBUG_ONLY(thread->set_visited_for_critical_count(true));
if (thread->in_critical()) {
// Notice that this thread is in a critical section
increment_jni_active_count();
}
// Consider (_waiting_to_block < 2) to pipeline the wakeup of the VM thread
if (_waiting_to_block == 0) {
Safepoint_lock->notify_all();
}
}
// We transition the thread to state _thread_blocked here, but
// we can't do our usual check for external suspension and then
// self-suspend after the lock_without_safepoint_check() call
// below because we are often called during transitions while
// we hold different locks. That would leave us suspended while
// holding a resource which results in deadlocks.
thread->set_thread_state(_thread_blocked);
Safepoint_lock->unlock();
// We now try to acquire the threads lock. Since this lock is hold by the VM thread during
// the entire safepoint, the threads will all line up here during the safepoint.
Threads_lock->lock_without_safepoint_check();
// restore original state. This is important if the thread comes from compiled code, so it
// will continue to execute with the _thread_in_Java state.
thread->set_thread_state(state);
Threads_lock->unlock();
break;
我这里假设这个 thread_in_vm 的线程在进入block之前吧自己状态切换成thread_in_vm_trans,在block里可以看到,它和 thread_in_java的逻辑是一样的。在这里,会重新把自己的状态置为 thread_in_vm(还记得吗,之前置成了 call_back),接着需要在Safepoint_lock里把自己的锁取到(我找了很多代码,这个地方几乎是用久成立的),接着set_has_called_back(true)表示已经调用过了,这时就可以把那个_waiting_to_block做 _waiting_to_block--了
到最最最最后,如果(waiting_to_block ==0) 则去唤醒VM Thread,后面的事情我们就不关心了。
后话
好了,分析到这里, VM Thread怎么走和其他Java Thread 怎么跑我们大致都看了一遍了,我们仍然找不到问题的答案是因为,我们还是猜测不到在 VM Thread 把自己挂起,到Java Thread 走进 block() 被什么阻塞了。
我猜想出可能是这样一种场景:我假设当时在Running的部分Java Thread其实都在做native 调用,并且他们都在做大量的IO操作,这个可能性是比较大的。由于他们都是在native调用,所以VM Thread是会认为它们都是安全的。而有一个线程在 Thread in vm状态,那么碰巧就是它在做unreadable page load时就由于OS在做IO所以这个page被swap out 了,等待swap in 等待了这么久。
不过这种猜测很多疑点,比如这个Page很少可能性被swap out 了
我厂的ivy 同学还有另外一种假设,就是线程是在做thread 的tran,应该是OS的操作把它阻塞了
而我厂的姐夫同学就给出一个很有价值的信息,我们线上的服务器的SSD是做了raid 0 的,而实验环境没有, raid 0 在做高负荷IO时,是有可能会block住。
所有的疑问也只能等到有机会时来去验证了。
待续。。。
参考资料
https://github.com/JetBrains/jdk8u_hotspot/blob/master/src/share/vm/runtime/
http://blog.csdn.net/iter_zc/article/details/41843595
http://jcdav.is/2015/11/09/More-JVM-Signal-Tricks/