Node.js® is a JavaScript runtime built on Chrome's V8 JavaScript engine. Node.js uses an event-driven, non-blocking I/O model that makes it lightweight and efficient. Node.js' package ecosystem, npm, is the largest ecosystem of open source libraries in the world.
上面是NodeJS官网上面的介绍, 从中可了解到:
- 它是一个Javascript运行环境,并且其运在Chrome的V8 Javascript引擎之上;
- 事件驱动;
- 非阻塞I/O;
- 轻量,高效;
为什么要异步I/O
异步I/O为何在Node里如此重要,这与Node面向网络而设计不无关系,在跨网络的结构下,并发已经是现在编程中标准配备了。具体到实处,可以从用户体验和资源分配这两个方面说起。
用户体验
异步的概念之所以首先在Web2.0中火起来,是因为在浏览器中Javascript在单线程上执行,而且它还与UI渲染共用一个线程。这意味着Javascript在执行的时候UI渲染和响应是处于停滞状态的。
前端通过异步可以消除掉UI阻塞的现象,但是前端获取资源的速度也取决于后端的响应速度。假如一个资源来自于两个不同的位置的数据的返回,第一个资源需要M毫秒的耗时,第二个资源需要N毫秒的耗时。如果采用同步的方式,代码大致如下:
// 消费时间为M
getData('from_db');
// 消费时间为N
getData('from_remote_api')
但是采用异步方式,第一资源的获取不会阻塞第二个资源,如此,我们可以享受到并发的优势,相关代码如下:
getData('from_db').then((result) => {
// 消费时间为M
});
getData('from_remote_api').then((result) => {
// 消费时间为N
});
对比两者的时间消耗,前者为M+N, 而后者为max(M,N)。
资源分配
我们知道计算机在发展过程中将组件进行了抽象,分为I/O设备和计算设备。
假设业务场景中有一组互不相关的任务需要完成,现行的主流方法有以下两种。
- 单线程串行依次执行。
- 多线程并行完成。
如果创建多线程的开销小于并行执行,那么多线程的方式是首选。多线程的代价在于创建线程和执行期线程上下文切换的开销大。另外,在复杂的业务中,多线程编程经常面临销、状态同步等问题。但是多线程在多核CPU上能够有效提升CPU的利用率,这个优势是毋庸置疑的。
单线程顺序执行任务的方式比较符合编程人员按顺序思维方式。但单线程同步模型会因阻塞I/O导致硬件资源得不到更优的使用。
Node在两者之间给出了它的方案:利用单线程,远离多线程死销、状态同步等问题;利用异步I/O,让单线程上将资源分配得更高效。
Node 的异步I/O
完成整个异步I/O环节有事件循环、观察者和请求对象等。
事件循环
在进程启动时,Node便会创建一个类似于while(true)的循环,每执行一次循环体的过程我们称为一个Tick。每个Tick的过程就是查看是否有事件待处理,如果有,就取出事件及其相关的回调函数。如果存在关联的回调函数,就执行它们。然后进入下个循环,如果不再有事件处理,就退出进程。流程图如下:
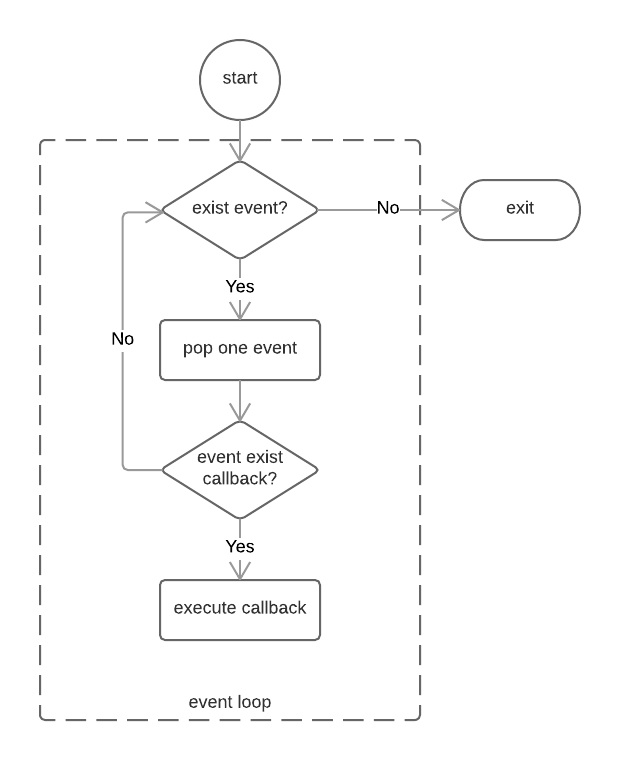
观察者
在每个Tick的过程中,如何判断是否有事件需要处理呢?这里需要引入的概念是观察者。每个事件循环中有一个或者多个观察者,而判断是否有事件要处理的过程就是向这些观察者询问是否有要处理的事件。
这个过程就如同饭馆的厨房,厨房一轮一轮地制作菜肴,但是要具体制作哪些菜肴取决于收银台收到的客人的下单。厨房每做完一轮菜肴,就去问收银台的小妹,接下来有没有要做的菜,如果没有,就下班打烊了。这个过程就,收银台的小妹就是观察者,她收到的客人点单就是关联的回调函数。当然,如果饭馆经营有方,它可能有多个收银员,就如同事件循环中有多个观察者一样。收到下单就是一个事件,一个观察者里可能有多个事件。
事件循环是一个典型的生产者/消费者模型。异步I/O、网络请求等则是事件的生产者,源源不断为Node提供不同类型的事件,这些事件被传递到对应的观察者那里,事件循环则从观察者那里取出事件并处理。
请求对象
对于一般的(非异步)回调函数,函数由我们自行调用,如下:
const forEach = (list, callback) => {
for (let i = 0; i < list.length; i++) {
callback(list[i], i, list);
}
}
对于异步I/O调用而言,回调函数却不由开发者来调用。事实上,从Javascript发起调用到内核执行完I/O操作的过渡过程中,存在一种中间产物,它叫做请求对象。
以fs.open()方法为例子,探索Node与底层之间是如何执行异步I/O调用以及回调函数究竟是如何被调用执行的:
fs.open = (path, flags, mode, callback) => {
binding.open(pathModule._makeLong(path), stringToFlags(flags), mode, callback);
}
从前面的代码中可以看到,Javascript层里的代码通过调用C++核心模块进行下层的操作:
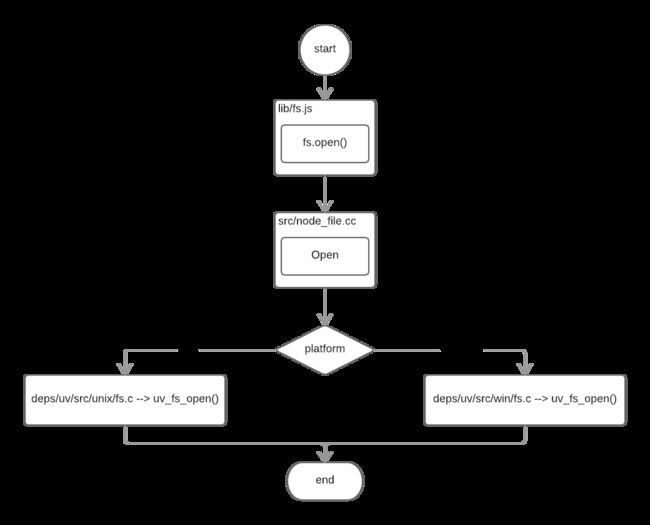
从Javascript调用Node的核心模块,核心模块调用C++内建模块,内建模块通过libuv进行系统调用,这是Node里的经典调用方式。在uv_fs_open()的调用过程中,我们创建了一个FSReqWrap请求对象。从Javascript层传入的参数和当前方法都被封装在这个请求对象中,其中我们最为关注的回调函数则被设置在这个对象的oncomplete_sym属性上:
req_wrap->object_->Set(oncomplete_sym, callback);
对象包装完毕后,在Windows下,则调用QueueUserWorkItem()方法将这个FSReqWrap对象推入线程池中等待执行,该方法的代码如下所示:
QueueUserWorkItem(&uv_fs_thread_proc, req, WT_EXECUTEDEFAULT)
至此,Javascript调用立即返回,由Javascript层面发起的异步调用的第一阶段就此结束。Javascript线程可以继续执行当前任务的后续操作。当前的I/O操作在线程池中等待执行,不管它是否阻塞I/O,都不会影响到Javascript线程的后续执行,如此就达到了异步的目的。
请求对象是异步I/O过程中的重要中间产物,所有的状态都保存在这个对象中,包括送入线程池等待执行以及I/O操作完毕后的回调处理。
执行回调
组装好请求对象、送入I/O线程池等待执行,实际上完成了异步I/O的第一部分,回调通知是第二部分。
线程池中的I/O操作调用完毕之后,会将获取的结果储存在req->result属性上,然后调用PostQueuedCompletionStatus()通知IOCP,告知当前对象操作已经完成:
PostQueuedCompletionStatus((loop) -> iocp, 0, 0, &((req) -> overlapped))
PostQueuedCompletionStatus()方法的作用是向IOCP提交执行状态,并将线程归还线程池。通过PostQueuedCompletionStatus()提交的状态,可以通过GetQueuedCompletionStatus()提取。
在这个过程中,我们其实还动用了事件循环的I/O观察者。在每次Tick执行中,它会调用IOCP相关的GetQueuedCompletionStatus()方法检查线程池中是否执行完的请求,如果存在,会将请求对象加入到I/O观察者的队列中,然后将其当做事件处理。
I/O观察者回调函数的行为就是取出请求对象的result属性作为参数,取出oncomplete_sym属性作为方法,然后调用执行,以此达到调用Javascript中传入的回调函数的目的。
整个异步I/O的流程:
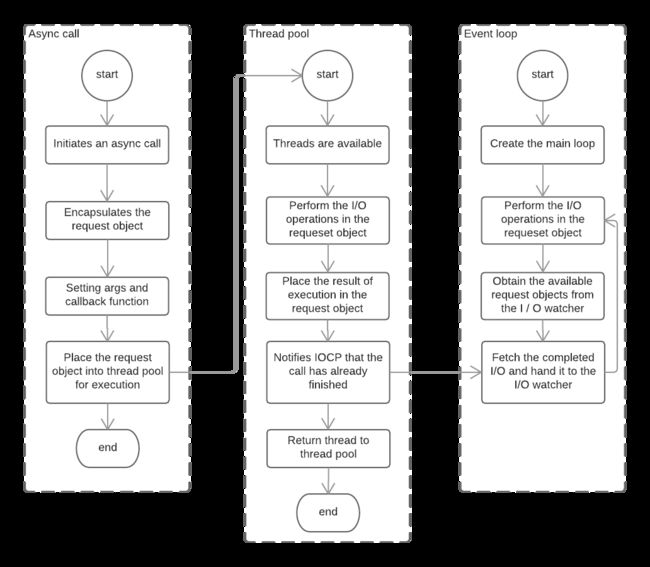
小结
从前面实现异步I/O的过程描述中,我们提取出几个关键字:单线程、事件循环、观察者和I/O线程池。这里的单线程与I/O线程池之间看起来有些悖论,由于我们知道Javascript是单线程的,所以接常识很容易理解为它不能充分利用多核CPU。事实上,在Node中,除了Javascript是单线程外,Node自身是多线程的,只是I/O线程使用的CPU较少。另一个需要重视的观点是,除了用户代码无法并行执行外,所的有I/O则是可以并行起来的。