原文地址:http://sunnyqjm.github.io/2018/05/19/computer_networking_04/
Introduction
- 网络层完成主机到主机之间的数据传输
- 网络层协议存在于所有的主机和路由器当中(二层交换机中没有)
- 当IP数据报通过路由器时,路由器会检查所有数据报首部字段(Header Checksum)
-
Forwarding and Routing ( 存储和转发 )
-
Forwarding(转发)
When a packet arrives at a router's input link, the router must move the packet to the appropriate.
=> 转发指的是路由器将某个入口链路上到来的数据包转移到合适的出口链路的过程。
-
Routing(路由)
The networklayer must determine the route or path taken by packets as they flow from a sender to a receiver. The algorithms that calculate these paths are reffered to as routing algorithms.
=> 路由是指网络通过运行路由算法,计算出一条从源端到目的端的路径的过程
-
补充
- 转发是路由器内部的事,而路由不是(路由需要网络里各个路由器的参与)
- 网络中的各个路由器,通过运行 路由算法 (routing algorithms)计算出保存在各个路由器本地的 本地转发表 (local forwarding table)。路由器根据此转发表来进行转发数据包。
-
Connection Setup(连接建立)
- 这是 网络 除转发和路由外 的第三个重要功能(互联网没有这个功能)
- 在网络层建立连接
- EG.:ATM、frame-relay
-
Virtual Circuit and Datagram Networks
- 虚电路网络:在网络层建立连接的网络
- 数据报网络:在网络层不建立连接的网络
-
Virtual-Circuit Networks (虚电路网络)
-
组成
- 从源到目的端的路径
- VC number是标识沿路径每条链路上的号码(在每条链路上唯一即可)
- 沿途路由器中转发表中的项(由进入端口号的VC Number决定从哪个口出去,以及出去的时候VC Number修改为什么)
-
示例
-
网络结构
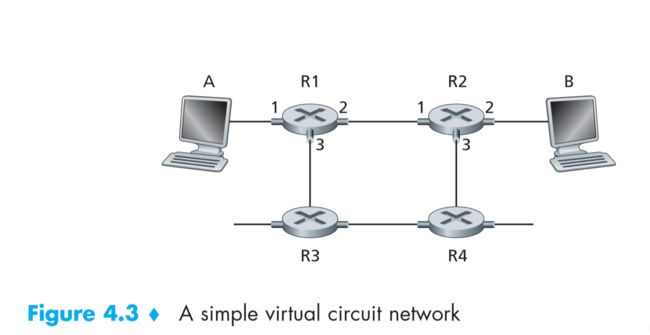 一个简单的路电路网络示例
一个简单的路电路网络示例 -
上述网络结构中路由器A的转发表
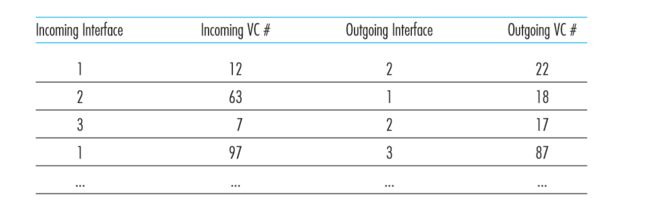 路由器A的转发表
路由器A的转发表
-
虚电路网络中连接一旦建立,数据包所走的路径就确定了(而互联网不是)
-
-
Datagram networks(数据报网络)
- no call setup at network layer => 网络层无连接建立
- routers: no state about end-to-end connections => 路由器不保持端到端的连接状态
- Packets forward using destination host address => 数据包的转发是根据目的端主机地址来进行转发的
- 查询路由表进行转发的时候采用的是 最长前缀匹配 (longest perfix matching rule)
- IP是数据包网络的寻址方式
-
虚电路网络 VS 数据报网络
- Internet(互联网) => 数据报网络
- data exchange among computers
- 弹性服务,无严格的定时要求
- “smart” end system => 终端相对智能
- many link type => 有多种链路类型
- ATM => 虚电路网络
- envolved from telephone => 演化自电话技术
- 有严格的定时要求,可靠性要求高
- “dump” end systems => 端系统简单,网络内部实现复杂
- Internet(互联网) => 数据报网络
What's inside a Router?
-
Router的两个功能
- run routing algorithms/protocol (RIP, OSPF, BGP)
=> 运行路由算法/协议 - forwarding datagrams from incoming to outgoing link
=> 从入链路到出链路转发数据报
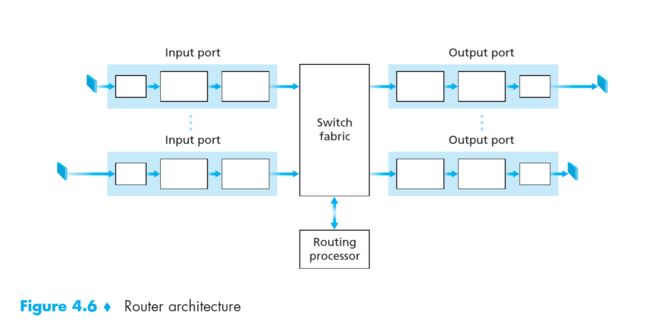 路由器架构
路由器架构 - run routing algorithms/protocol (RIP, OSPF, BGP)
-
Input ports
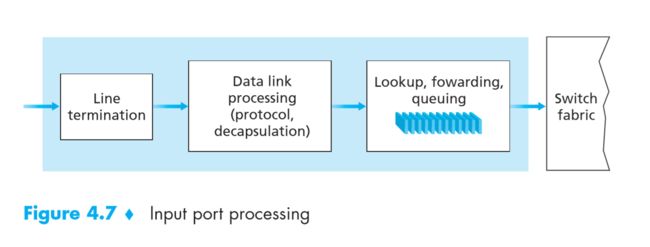 输入端处理流程
输入端处理流程- Line termination => 物理层
- Lookup => 根据数据报的目的地址,在输入口内存中使用转发表查找应该从哪个端口输出
- forwarding => 将数据包转移到对应的出口
- queueing => 如果数据报到达的速率比交换结构的转发速率要快,则导致排队的发生
-
三种类型的交换
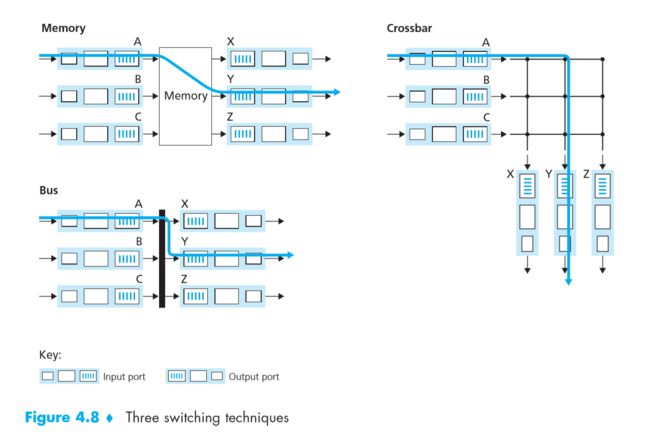 三种交换技术
三种交换技术- Memory:共享内存 => 交换速率受内存大小的限制
- Bus:总线型 => 交换速率受总线带宽的限制
- Crossbar
-
Output ports
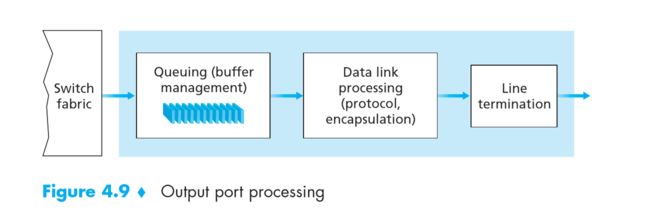 出口端处理流程
出口端处理流程 -
Where does Queuing Occur?
路由器中排队的发生可能在入口端的接收缓存或者是出口端的发送缓存
-
发送排队的时机
- 入端口收到数据包的速率大于路由器转移数据包的速率 => 入口端发生排队
- 出口端收到路由器转发过来的数据包的速率大于发送数据包的速率 => 出口端发生排队
网络中所有数据的调度都是非抢占式的
-
缓存溢出时的策略
- drop-tail: 如果缓存已满,则直接将新收到的数据包丢弃
- RED(Random Early Detection) => 随机早期检测。在缓存将满而未满的时候就主动随机丢弃缓存队列中的数据包 (可以优化网络的拥塞状态)
-
路由协议一般是应用层的
IP(Internet Protocol, 网际协议)
- PDU为Datagram
-
Datagram Format (数据报结构)
 IPV4数据报结构
IPV4数据报结构Version (4bits) : IP协议版本号
Header Length (4bits) : IP数据报头的长度,单位为字节 。包括头部Options
Type of service (8bits) : TOS,用来标识IP数据报的服务类型
Datagram length (16bits) : 整个数据报的长度,单位为字节。包括头部和数据域
第二行的个字段主要用于分片
Time-to-live (8bits) : TTL,有效时间 => 通常指的是跳数
Upper-layer protocol (8bits) : 上层所使用的协议
Header-checksum (16bits) : 首部校验和
-
网络层只对Datagram首部进行校验
-
可行性
- data在传输层有checksum,故可以不需要再网络层对data进行校验
- 网络层提供的是不可靠的传输,允许出错
-
优点
只对首部进行校验,可以减少delay,同时减轻路由器的负载 => 每个路由器都要网络层数据包处理,所以要让处理的开销尽量的小
-
存在的问题
- 当某个正在网络中传播的数据包data部分出错,其途经的路由器由于只对其网络层头部进行校验,而不对data进行校验,所以会将这个出错的包继续传递,直到传递到终端才检测出来数据包错误。=> 造成传输资源的浪费
- TCP和UDP之外的其它传输层协议可能本身并不具备校验功能
-
-
为何每个路由器都要对数据包进行重新打包?
header中的数据 每经过一个路由器都 会改变,比如TTL每跳减一,因此 header checksum 需要重新计算
IPv4 datagram 首部 最小、默认 开销为 20个字节 => 严格来讲,由于Options域的存在,首部的开销是不确定的
-
IPv4 Datagram Fragmentation (IPv4 数据报分片)
-
为什么(何时)要进行分片?
低层(链路层)网络不同协议所支持的 MTU ( maximun transimit unit, 最大传输单元 ) 不一致。而互联网中不同链路可以采用不同的协议,就可能导致 路由器两端链路的MTU不一致。=> 当路由器两端链路的MTU不一致,且是从MTU大的一端 -> 小的一端的时候,就可能需要分片 (当然,除了分片之外,路由器也可以选择主动丢弃,让发送端去调节数据包的大小)
-
IPv4用于实现分片的头部字段
 IPV4用于实现分片的字段
IPV4用于实现分片的字段- Identification : 属于同一个数据包的分片都有一个相同的Id
- DF : 若该标识置1,则表示不分片
- MF : 若该标识置1,则表示不是最后一个分片
- Fragment Offset: 分片的偏移量
 IPv4分片偏移图示
IPv4分片偏移图示- 单位是8bits
- 一定要注意,偏移计算的是data部分,每个分片都单独有一个网络层头部
- 当 (MTU - 首部size) 不是8的倍数时,每个分片data部分的最大size,取不超过但最大的能整除8的数
-
一个示例
 一个IP分片的栗子
一个IP分片的栗子 -
注意
- 发送主机 或者 路由器 都有 可能对IP数据报进行分片
- 一个 IP分组可能被多次分段(分片)
- 但 IP分片重组 (reassembly) 仅在目的主机进行
-
为何IP分片重组只在目的主机进行
- 不同的数据包从源端到目的端所走的路径可能不同,这就导致 不同分片可能经由不同的路由器组到达目的端 ==> 换句话说,途中的某个路由器可能无法收到同一个数据包的所有分片,就无法进行分片重组
- 这样可以减少路由器的开销,提高网络核心的效率
-
-
IPv4 Addressing (IPv4编址)
-
IP address
- 主机 和 路由器 接口长度为32bits的标识
- 常采用 点分十进制 (dotted-decimal notation)进行表示
-
Interface(接口)
主机或路由器和物理链路的接口
-
Subnets(子网)
To determine the subnets, detach each interface from its host or router, creating islands of isolated networks, with interfaces terminating the end points of the isolated networks. Each of these isolated networks is called a subnet
- 同一个子网内IP的高位比特位一致
- 拔开所有接口后,仍然连砸一起的网络属于同一个子网
-
CIDR(Classless Interdomain Routing, 无类型域间选路)
- 网络地址(子网地址)部分是长度可变的
- 格式:a.b.c.d/x => 其中x表示的是网络地址(子网地址)部分的长度
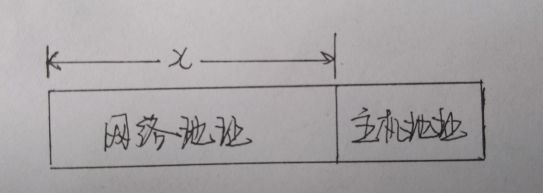 IP地址网络地址和主机地址划分示意图
IP地址网络地址和主机地址划分示意图- 子网地址(网络地址):前 x 位保留,后 32-x 位置0
- 主机地址:前 x 位置0,后 32-x 位保留
- 子网掩码 (subnet mask):前 x 位置1,后 32-x 位置0 => 网络地址部分全置1,主机地址部分全置0
-
Classful Addressing(分类编址)
当ip地址表示的时候没有 /x 的时候,就可能采用的是这种方式判断网络地址和主机地址
- Class A: 0.0.0.0 ~ 127.255.255.255 => A类地址前8位为网络地址
- Class B: 128.0.0.0 ~ 191.255.255.255 => B类地址前16位为网络地址
- Class C: 192.0.0.0 ~ 223.255.255.255 => C类地址前24位为网络地址
- Class D: 224.0.0.0 ~ 239.255.255.255 => D类地址为多播地址
- Class E: 240.0.0.0 ~ 255.255.255.255 => E类地址预留未用
-
Private IP(私有IP地址 / 内网地址)
==> 在很大程度上可以对互联网进行扩容(通过NAT技术)
- 10.0.0.0 ~ 10.255.255.255
- 172.16.0.0 ~ 172.31.255.255
- 192.168.0.0 ~ 192.168.255.255
-
特殊的IP地址
- 0.0.0.0 => 本主机
- 0···0 | Host => 主机地址
- 255.255.255.255 => 全局广播地址
- network | 1···1 => 子网内广播地址
- 127 + Anything => 回环(Loopback)地址
-
如何辨别IP地址
 子网划分以及IP地址范围示意图
子网划分以及IP地址范围示意图IP地址范围 是包括了主机地址部分全0和全1的两个地址,但是 可分配给主机的IP地址范围 不包括。
Explicit(显示):VLSM => 通过可变长子网掩码判别网络地址和主机地址
Implicit(隐式):Classful => 通过判断ip地址属于哪一类IP地址,进而判断网络地址和主机地址
-
举个栗子
Subnet mask is: 255.255.255.224 Host IP: 202.112.41.241 Problems: 1. network address and host address ? 2. how many subnets are created at most ? 解: 首先判断将当前的子网掩码转为2进制: 255.255.255.224 => 1···100000 (前27位为1) 224 => 11100000 241 => 11110001 ①. 网络地址:202.112.41.224 主机地址:0.0.0.17 ②. 分析可知该IP属于C类IP,前24位是网络地址 27 - 24 = 3(位) 2^3 = 8(个) 所以对多可以创建8个子网。
-
-
DHCP (Dynamic Host Configuration Protocol, 动态主机配置协议)
- plug-and-play => 即插即用
- 基于UDP
- 动态自动分配IP地址,可充分利用IP地址资源
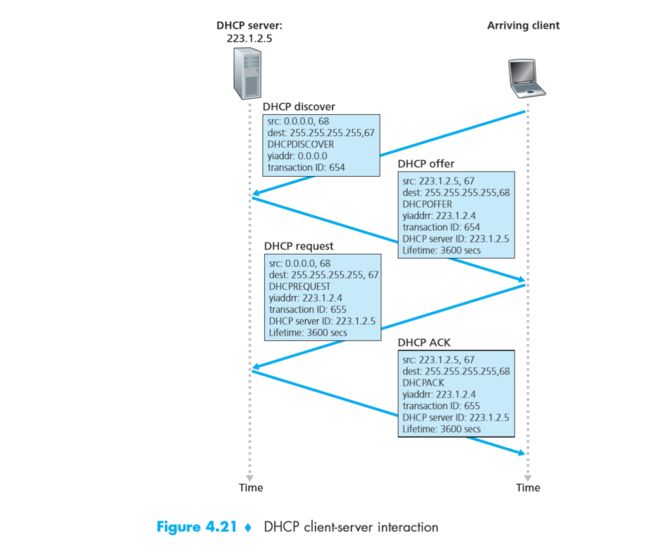 DHCP客户端和服务端交互示意图
DHCP客户端和服务端交互示意图-
为何选用UDP
- TCP延迟大,UDP效率高
- 一开始Client并没有IP地址,无法与服务端建立连接,只能通过UDP广播的形式与服务端通信
- 分配IP的去求对丢包和可靠传输的要求不高。
-
IPv4地址耗尽的解决措施
- VLSM / CIDR IPv4
- DHCP
- NAT
- IPv6
NAT (Network Address Translation, 网络地址转换)
- NAT是在共有IP地址和私有IP地址之间进行转换的技术
- NAT中的每个外网端口号对应内网主机当中的一个进程 => 使得一个IP的资源被充分的利用
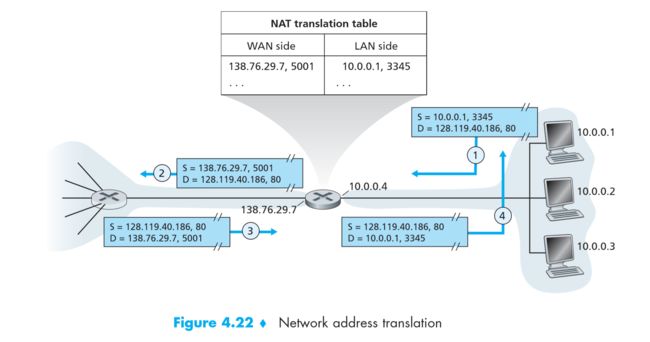
对于从 内网流出的数据包,将其 源IP地址和端口号 从私有的IP地址和端口号 替换成公网的IP地址和端口号
将内网IP、端口与外网IP、端口的 映射关系,保存在 NAT table 当中
对于从 外网流入的数据包,参照 NAT Table,将 目的IP地址和端口号 替换成私有的IP和端口
ICPM (Internet Control Message Protocol, 互联网控制消息协议)

- 报告差错 => 用于在IP主机路由器之间传递控制消息(主机通否?主机可达否?路由可用否?)
- ping
IPv6
- IP地址扩容
- 提供区分服务
- 减少路由器的工作,提高效率 => IPv6 有分片机制,但是在基本首部中是不支持的,在扩展首部中可以支持。但 规定之只能在端系统中进行分片和重组,路由器不可操作扩展首部(除了逐跳选项)
-
制定IPv6协议的动机
- 32位的IPv4地址不够用 => 这是最主要的动机
- IPv6首部的格式有利于提高转发和处理速率
- IPv6首部的变化,提高了Qos
-
IPv6 datagram format
- 首部长度固定为40 bits (基本首部)
- 路由器上不允许进行分片
-
概述
- IPv6吧IP地址的长度增加到了16个字节
- IPv6简化了IP Datagram的首部格式 => 字段数减少了,且基本首部的长度是固定的
- IPv6增强了对进一步扩展的支持 => 将IPv4首部中Options项移到了扩展首部当中
- IPv6增强了对Qos(Quality of Service)的支持
- IPv6增强了对安全的支持
- IPv6增加了对Anycast通信方式的支持
-
IPv6数据报的一般格式
 IPv6数据报的一般格式
IPv6数据报的一般格式 -
IPv6数据报的首部
- 长度固定为40个字节,称为基本首部
- 取消不必要的功能,字段个数减为8
- 取消Header checksum 加快了路由器处理数据报的速度
- 支持扩展首部(分片、逐跳选项、路由选择...) => 数据报途中经过的路由器都不处理这些扩展首部(除了逐跳选项),这 大大提高了路由器的处理效率
- 有效载荷(payload)= 扩展首部 + 数据
- 地址长度扩展为128位
-
IPv6数据报格式
 IPv6数据报格式
IPv6数据报格式 -
补充
- 记法:采 冒号十六进制记法,支持零压缩
- IPv6支持:单播、组播、任播(目的站是一组计算机,但数据报在交付的时候只交付其中的一个,通常是距离最近的一个)
-
IPv4映射的IPv6地址
 IPv4映射的IPv6地址
IPv4映射的IPv6地址
-
IPv6相较于IPv4的变化
- IPv6首部长度固定为40字节,而IPv4的默认为20,可以由options
- IPv6基本首部中没有分片字段,移动到了扩展首部中(而且IPv6的分片和重组只能在终端上运行)
- IPv6没有首部Checksum => 简化路由器的工作,提高效率
- IPv6地址长度为128位,而IPv4为32位
- IPv6支持任播,而IPv4不支持
- IPv6首部字段减少,提高了路由器的处理效率
-
ICMPv6
- 差错报告报文
- 提供信息的报文
- 多播听众发现报文
- 邻端发现报文
-
IPv4向IPv6过渡的方案
- 双协议栈——Dual IP Layer/Dualo Stack => 在主机和路由器上同时实现IPv4和IPv6两种协议
- 隧道技术(Tunneling):把IPv6分组封装在IPv4分组当中传送 => 把IPv6 datagram 整体作为数据封装在IPv4 datagram 中进行传送
Routing algorithms (路由算法)
- Routing => 确定一条从源端到目的端的一条路径的过程(不一定是最短的)
- global routing algorithms => 集中式路由算法
- decentralized routing algorithms => 分散式路由算法
-
The Link-State (LS) Routing Algorithms
- 链路状态路由算法(集中式)
- 采用Dijstra算法求最短路径
-
伪代码
- u => 源端
- N' => 一个包含所有到源端最短路径已知的点的集合
- C(x, y) => x, y之间的link-cost
- D(v) => 节点v到源端的距离,不可达则为∞
- P(v) => 节点v到源端路径的前向节点
Initiazation: N' = {u} for all nodes v if v adjacent to u then D(v) = C(u, v) else D(v) = ∞ Loop find w not in N' such that D(w) is a minimum, add to N' update D(v) for all v adjacent to w D(v) = min{D(v), D(w) + C(w, v)} Until all nodes in N' -
举个栗子
 一个链路运行链路状态路由算法的栗子
一个链路运行链路状态路由算法的栗子 -
运行链路状态路由算法得到的结果
运行链路状态路由算法得到的结果- 得到一颗最小生成树
- 得到一张转发表
在LS路由算法中,为了获取所有节点的Link-cost,有一个 链路状态广播(利用洪泛获取link-cost信息) 的过程,开销相对较大
-
The Distance-Vector(DV) Routing Algorithms
- 链路状态路由算法(分散式)
- 利用的是动态规划的思想
-
伪代码
- Dx(y) => x到y的最短路径的link-cost
- Dx(y) = MINv{C(x, v) + Dv(y)} => 其中,v为x的所有邻居
对于每个节点x,运行如下路由算法
Initialization: for all destinations y in N: Dx(y) = C(x, y) //如果是x的邻居则有值,否则为 ∞ for each neighbor w: //一开始不知道邻居到其它节点的Link-cost Dx(y) = ? for all desrinations y in N for each neighbor w: //向自己的邻居节点发送自己已知的距离向量 send distance vector Dx = [Dx(y): y in N] to w、 Loop //等待自己到邻居的link-cost改变,或者收到邻居发给自己的距离向量 wait (until I see a link cost change to some neighbor w or until I receive a distance vector from some neighbor w) for each y in N: Dx(y) = MINv{C(x, v) + Dv(y)} // 如果自己到任一节点的link-cost发生变化,向所有的邻居发送距离向量 if Dx(y) change for any destination y: send distance vector Dx = [Dx(y): y in N] to all neighbors forever -
伪代码说明
- 每个节点在本地保存自己的距离向量和所有邻居节点的距离向量
- 一旦自己到邻居的link-cost变化或者收到邻居发的距离向量,则重新计算自己的距离向量,如果有变化就发给所有的邻居。
-
Link-cost change:
- good news travels fast => 当某个 link-cost 减小,网络很快趋于稳定(收敛)
- bad news travels slow => 当某个 link-cost 增大,需要经过很多次迭代才收敛(存在计数到无穷问题)
-
poison reverse(毒性反转)
当RouterA发现与RouterX的连接断开,并准备向邻居节点发送新的距离向量的时候,并不是忽略它,而是将到他的路径毒化,设置其跳数为最大跳数加1,即不可到达。让其他节点尽快知道RouterX已经不可经由RouterA到达了,加快网络的收敛速度。
-
DV vs LS
- Message Complexity(报文复杂性)
- LS: n个node,E跳link,需发送O(nE)个messages
- DV: 只在相邻节点间传递消息
- 收敛速度
- LS: 固定,要求发送O(nE)个messages => 可能存在震荡
- DV: 收敛时间变化不定 => 环路问题,计数到无穷问题
- 健壮性
- LS: 节点可能通告不正确的链路费用 ;每个节点仅计算自己的表
- DV: 节点可能通告不正确的路径信息 ;每个节点的表都由他人使用 => 差错通过网络进行传播
- Message Complexity(报文复杂性)
| Distance Vector | Link State |
|---|---|
| 仅与邻居节点交换消息 | 向网络上所有其他节点广播消息 |
| 消息包括到所有节点的最短距离 | 消息仅包括到邻居节点的距离 |
| 收敛速度比较慢 | 收敛速度比较快 |
| 会广播不正确的路径信息 | 会广播不正确的链路信息 |
| 有计数到无穷(Count to Infinity Problem)问题 | 没有计数到无穷(Count to Infinity Problem)问题 |
-
Hierarchical Routing(分层式路由)
- Intra-AS routing algorithms => 自治系统内部路由算法
- Inter-AS routing algorithms => 自治系统间路由算法(只传递可达性信息)
Routing in the Internet
- 内部网关协议(IGP) => 自治系统内部路由协议的总称
- RIP
- OSPF
-
RIP
- 基于UDP,且RIP为应用层协议(RIP的报文封装在UDP数据报中发送,故RIP为应用层协议)=> 值得注意的是,路由器应该有应用层和传输层,否则无法运行路由协议。但是在转发数据包的时候不使用传输层和应用层的功能
- 采用距离向量路由算法(DV算法)=> 以跳数作为距离指标,并且将跳数限制在15跳以内
- RIP跳数 => 从当前节点到目的节点所穿越的子网个数,包含目的子网(最小为1)
- RIP协议的最大跳数为15
- 每30s更新一次,如果180s未收到某个邻居节点的向量表,则认为其已经断开(采用毒性反转之后,如果收到某个邻居节点的向量表中包含某个跳数大于RIP的最大跳数,就认为那条路径断开,而不用等待180s)
-
转发表示例
 RIP转发表示例
RIP转发表示例
-
OSPF
- 读书路由协议属于应用层,而 OSPF 不是,它 是传输层协议。它在IP之上却没有使用其他传输层协议
- 采用的是链路状态路由算法(LS算法)
-
BGP(边界网关协议)
- 自治系统间的路由协议
- 基于TCP
- 主要传递可达性信息
-
静态路由表的计算 (!!!圈重点)
-
例题:
 静态路由表栗子题目
静态路由表栗子题目 -
解答:
静态路由表栗子解答
-
-
单播、组播、广播、任播
单播:一对一,只有一个接收端
组播:一对一组 => 组内成员可以来自不同的子网,接收端是组内的所有成员
广播:一对所有 => 默认是在某个子网内部,不能穿越路由器
共性:一个发送端
Brodcast and multicast routing
实现广播的两种复制数据的方式
- Source-duplication => 源端复制(效率很低)
- In-network duplication => 网内复制(会有洪泛问题)
-
Uncontrolled Flooding(不可控洪泛)
When node receives broadcast packet, sends copy to all neighbors
当收到某个邻居的广播报文时,无条件地转播给其它所有的邻居
=> 如果有网络有回路存在,就会导致“广播风暴”
-
Controlled Flooding(可控洪泛)
-
Sequence-number-controlled flooding (序列号可控洪泛)
给每个数据包都加上一个序列号,当再次收到一个序列号相同的数据包的时候不再转发给邻居
=> 可以避免“广播风暴”,但是不能完全解决冗余数据包的问题
-
Reverse path forwarding (RPF, 反向路径转发)
- 依赖于路由器知道自己与发送端的一条最短路径
- 当收到一个数据包的时候
- 先创建一个从自己到源端的最短路径
- 如果发送这个 数据包的节点在该路径上,则将其转发给所有的邻居,否则不转发
- 可以避免 广播风暴,但是仍然存在冗余数据包问题
-
利用生成树进行广播
生成树构建好之后,路由器收到一个广播数据包,只转发向包含于生成树的路径转发数据包
=> 没有冗余数据包,也可以避免广播风暴
-
-
用于组播的协议
- Distance-Vector Multicast Routing Protocol(DVMRP)
- Protocol-Independent Multicast(PIM) routinh protocol