本文是对Hive组件的学习的一个初步总结,包括如下章节的内容:
- Hive是什么
- Hive安装
- 快速上手
- Hive元数据
- 数据存储
- 运行模式
参考资料:
1、本文介绍的内容依赖hadoop环境,关于hadoop运行环境的搭建可参见《Hadoop运行环境搭建》。
2、学习Hive前,最好对关系数据库以及sql语句有所熟悉。
一、Hive是什么
Hive是基于Hadoop的一个数据仓库,它将结构化的数据文件(一般保存在hdfs上)映射为一张表,并提供类sql(称为hsql)查询功能,Hive框架将hsql语句转化为一系列mapreduce任务来对hdfs上的文件进行分析。相对于用java代码编写mapreduce程序来说,编写sql语句要简单和快速很多。Hive的优势明显:快速开发,技术门槛低,可扩展性(自由扩展集群规模),延展性(支持自定义函数)。
Hive是由Facebook开发,后来由Apache软件基金会开发,并作为进一步将它作为名义下Apache Hive为一个开源项目。
Hive是一种数据仓库系统,提到数据仓库,我们通常会想到数据库。为了更好地理解Hive作为数据仓库的应用场景。这里简单介绍下数据仓库和数据库的区别,可以从两个角度看来它们的区别:
1、数据库和数据仓库都是通过某个软件系统,基于某种数据模型来组织、管理数据。但是,数据库通常更关注业务交易处理(OLTP),而数据仓库更关注数据分析层面(OLAP),由此产生的数据库模型上也会有很大的差异。
2、数据库通常追求交易的速度,交易完整性,数据的一致性等,在数据库模型上主要遵从范式模型(1NF,2NF,3NF等),从而尽可能减少数据冗余,保证引用完整性;而数据仓库强调数据分析的效率,复杂查询的速度,数据之间的相关性分析,所以在数据库模型上,数据仓库喜欢使用多维模型,从而提高数据分析的效率。
二、Hive安装
(一)前置准备
Hive一般运行在工作站上,它把sql查询转换为一系列的mapreduce任务,提交到hadoop集群上运行。安装Hive之前,首先必须在准备安装Hive的工作站上安装与集群相同版本的hadoop,或者直接在集群环境的某台机器上安装Hive。
因为Hive工作站上也要安装Hadoop,所以我们在开发阶段,可以在Hive工作站上以独立(本地)模式或伪分布式模式启动hadoop。这时让Hive程序与本机上的hadoop交互来进行开发调试,确保功能无误后,再让Hive程序连接到实际的集群环境上进行功能,尤其性能的验证。
关于hadoop在本地如何安装和运行,可参考《Hadoop运行环境搭建》。
(二)下载版本
下载相应的Hive版本,解压到某个目录下。注意,下载的Hive版本需要与对应的hadoop版本匹配。可以通过http://hive.apache.org/downloads.html 查看Hive版本与Hadoop版本的依赖关系。在本文的案例中,我们使用的是Hive版本是hive-1.2.2。
(三)配置环境变量
export Hive_HOME=/home/hadoop/hive
PATH=$PATH:$Hive_HOME/bin
说明:上面是假设Hive解压到/home/hadoop目录下,具体要根据实际目录来设置。
三、快速上手
安装好Hive后,我们可以利用Hive提供的交互式命令行程序来快速的学习如何使用Hsql来进行数据分析。
Hive提供了一个名称叫hive的可执行程序(实际是一个shell脚本),位于Hive解压后的bin目录中,因为前面的环境变量设置中bin目录已经加到PATH环境变量中,所以可以在任意当前目录下运行hive程序,运行hive后,会出现一个交互式运行界面,这样可以执行Hive 的sql语句了,输入exit;退出交互式界面。如下面例子:
[hadoop@localhost ~]$
[hadoop@localhost ~]$ hive
............
hive>
hive> show tables;
OK
Time taken: 1.047 seconds
hive> exit;
[hadoop@localhost ~]$
可以看出,运行hive程序,出现一个交互式界面,这时输入了show tables命令(该命令显示所有的Hive表,因为还没任何建表操作,所有没有数据),执行exit命令退出交互式运行界面。注意,在hive程序的交互式执行中,命令要以分号结尾。
下面我们再通过一个简单的例子来看下如何创建Hive表、导入数据和进行数据查询。
(一)创建表
在hive>提示符下,我们创建如下的表,hsql语句如下:
create table student(id int, name string, sex string, age int, department string)
row format delimited
fields terminated by ",";
这时我们再执行 show tables 命令会发现显示 student表名。
(二)查看数据
我们执行hsql查询语句:
select * from student;
会成功,但没有数据。可以看出,这个查询语句与标准sql没有区别。
(三)导入数据
准备一个文本文件student.txt,其文件中的数据格式要符合上面创建表的结构,文件可以在本地,也可以在htfs上。文件的内容如:
95002,刘晨,女,19,IS
95017,王风娟,女,18,IS
95018,王一,女,19,IS
95013,冯伟,男,21,CS
95014,王小丽,女,19,CS
95019,邢小丽,女,19,IS
95020,赵钱,男,21,IS
执行命令
load data local inpath "/home/hadoop/localdata/student.txt" into table student;
上面命令会把本地的文件 /home/hadoop/localdata/student.txt 导入到hdfs的Hive仓库目录中,作为Hive表的数据。关于Hive的仓库目录,下面章节会详细介绍。
这时我们再执行select 语句,会发现查询的数据就是文件中的数据。
我们也可以把hdfs上的文件导入到Hive中,这时只需要把上面命令中 inpath 前面的local去掉,然后inpath 后面是hdfs上的文件路径即可。不过,如果是load hdfs上的文件,这个文件会被删除掉,相当于是被移到Hive仓库中了。
注意:Hive不支持标准sql的insert单条记录的操作。
(四)删除表
删除表的hsql语句是:
drop table 表名
这和关系数据库删除表的sql语句一样。
(五)非交互式执行命令
前面我们介绍的都是在Hive交互式命令行界面下执行命令的,但在很多时候,我们往往需要非交互式的执行,比如在希望在一个脚本中执行Hive的hsql命令。
这有两种方式,一种是将hsql命令写入到脚本文件中,假设写入的文件名为script.q。然后我们在控制台下执行:
hive -f script.q
这样hive程序会被启动,依次执行脚本中的每条hsql命令。所有命令执行完毕后,hive程序会自动退出。
对于内容(hsql命令)较少的脚本,可以直接将内容嵌入到命令中,而不用写到一个文件中。如在控制台下执行如下命令:
hive -e “select * from student”
这样hive程序会被启动,并执行跟着的hsql语句,执行完毕后,hive程序会自动退出。
上面我们通过例子快速的了解了如何使用Hive。但还有很多问题需要弄清楚。比如创建的Hive表的这个表定义信息存储在哪里了?表背后对应的数据(load操作上传的)文件放到哪里了?除了create和select语句,Hive还提供了哪些类sql语句,与标准sql有哪些区别?作为最终用户,除了通过交互式界面来执行hsql进行操作外,还有哪些方式,比如如何编写java等程序使用Hive?
下面我们接着来介绍Hive中的一些重要概念。对于Hsql更多的语法和信息,本文不再介绍。
四、Hive元数据
我们使用Hive,首先要创建表,这里的表只是对hdfs上数据文件的的一种结构描述(即表的定义信息),那这个表的定义信息保存在哪里呢?
Hive将表的定义信息,以及其它一些信息(如服务信息),称为Hive的元数据,元数据不是保存在hdfs上的,而是保存在关系数据库中的,称为metastore。
Hive的metastore(元数据存储)有三种配置方式:
1、内嵌Derby配置
内嵌方式是Hive默认的metastore配置,这时不需要修改任何Hive的配置文件。元数据是保存在一个以本地磁盘作为存储的Derby数据库实例中。Hive自带了对Derby数据库的支持。如下图所示:

一个Derby数据库的数据库相关文件在物理上对应一个本地磁盘的目录,每次只能有一个内嵌的Derby数据库实例来访问这些数据库文件。因为Hive运行需要获取元数据。这样的话,同时只能有一个Hive会话。
在内嵌模式下,当我们在控制台下首次运行hive程序(如上一节介绍),会发现在运行hive程序的当前目录下生成了一个metastore_db目录,该目录就是Derby数据库文件存放地。当我们进行了创建表等操作,这些表定义的元数据就存放到Derby数据库中。因为一个Derby数据库只支持一个实例访问,所以当我们如果在同样的当前目录下再次运行hive程序就会报错。当然我们可以在另外的目录下运行hive程序,只不过这样会在另外的目录下生成另外一个Derby数据库,这两个Derby数据库是无关的。
因此,在内嵌模式下,一旦hive程序退出后,如果我们再次启动,并希望能获取到原来操作产生的元数据,一定要在原来的目录下启动hive程序,这样关联的才是相同的Derby数据库。
2、本地配置
如果我们希望能同时支持多个会话,则需要一个独立的数据库来保存Hive元数据,这称为本地配置。对于独立的metastore,一般采用mysql数据库。对于本地配置,Hive引擎和metastore服务仍然运行在同一个jvm进程中。如下图所示:

3、远程配置
这种模式下,metastore服务会作为一个独立的服务进程运行,我们可以配置启动多个metastore服务进程。如下图所示:
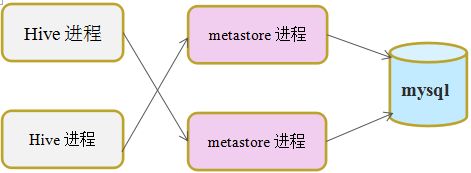
使用本地配置或远程配置,需要一些额外的工作要处理,如安装mysql数据库,修改Hive的相关配置文件。但是无论采用内嵌方式,或哪种方式,站在应用或学习的角度是没有太多区别的。在本文中,我们不对本地和远程模式的如何配置做介绍。为了简单化,我们在内嵌模式下进行例子的演示和说明。
五、数据存储
通过上一节的介绍,我们已经知道,Hive表的定义信息作为元数据存在关系数据库中,那表背后的实际数据是存储在哪里呢?
(一)表分类
其实Hive的表分两种类型,一是托管表,二是外部表。托管表的数据文件是存放到Hive的数据仓库目录下,而外部表的数据文件由建表时指定,可以是任意的hdfs目录。也就是说对于托管表其数据文件存储由Hive来管理。而对于外部表,其数据文件存储由开发者自己来管理。
我们上面举的建表例子是托管表。对于外部表,我们先知道这个概念,具体的创建和使用本文不作介绍。
(二)仓库目录
对于Hive的托管表,对应的数据文件是存放在Hive的仓库目录中,默认是hdfs系统的/user/hive/warehouse目录下(可以在hive-site.xml配置文件中配置自己需要的位置,配置属性为hive.metastore.warehouse.dir)。
Hive所创建的每张Hive表都会在该仓库目录下生成一个目录,目录名同表名。在我们使用load命令给表导入数据时,实际load命令指定的数据文件(来源是本地磁盘或hdfs上的文件)会被存放到仓库目录下的表名所在的目录。
我们前面例子创建了student表,导入了一个student.txt文件。我们查看hdfs系统上Hive仓库目录下的内容,会发现有如下目录和文件,如:
[hadoop@localhost lib]$ hadoop fs -ls /user/hive/warehouse
Found 1 items
drwxr-xr-x - hadoop supergroup 0 2018-11-29 19:34 /user/hive/warehouse/student
[hadoop@localhost lib]$ hadoop fs -ls /user/hive/warehouse/student
Found 1 items
-rwxr-xr-x 1 hadoop supergroup 434 2018-11-29 19:28 /user/hive/warehouse/student/student.txt
可以看出,默认的仓库目录下有一个student目录(目录名与student表名一样),student目录下有一个student.txt文件,就是我们导入的文件。
(三)数据合法性检查
通过前面的介绍我们知道,Hive表的定义信息只是对背后实际数据文件结构的一种映射,反过来说,我们导入的数据文件也得和表的结构相匹配,否则查询时就会报错。Hive对数据文件的合法性检查不是在导入时检查的,而是在查询时才会去判断。实际上我们也可以不用Hive的load命令导入数据文件,可直接通过hdfs的命令将文件上传到相应表的目录下,这也是可以的。
六、运行模式
Hive有多种运行模式,用户可以使用不同的方式来使用Hive。下面来一一介绍。
(一)单机模式
前面介绍的运行hive程序,启动一个交互式命令行程序,实际背后运行的是一个独立的java进程。我们通过 jps命令可以查看到java进程信息。
相当于该java进程即提供了交互界面让用户输入hsql命令,又包含了Hive执行引擎以及metastore服务(访问存储元数据的关系数据库)。
需要说明的是,在元数据内嵌模式配置下(即默认方式下),只能允许启动一个单机进程,也就是说同时只能有一个用户进行Hive操作。
如果只是为了学习Hive,使用元数据内嵌模式配置(即默认配置),然后启动单机模式(运行hive程序进行交互式操作)是最简单和方便的了。
(二)C/S模式
这种模式下,是将hive作为一个服务进程启动(就是c/s架构中的服务器程序),该服务器程序包含了Hive执行引擎以及metastore服务。
用户通过独立的客户端程序(可以是Hive自己提供的命令行程序,也可以程序员自己编写的程序)来输入hsql命令,发送给上面启动的Hive服务器程序,Hive服务器程序收到命令后执行,执行后把结果返回给客户端。实际就是一个典型的C/S架构应用。
这样即使在元数据内嵌模式配置下,只能起一个服务器程序,但可以有多个客户端程序操作,这样就可以允许多用户同时进行操作了。
将Hive作为一个服务启动的方式是,在控制台执行:
hive --service hiveserver2
这时就启动了一个服务器程序,默认的监听端口号是10000,我们可以通过linux命令查看相应的进程如:
[hadoop@localhost ~]$ netstat -nlp|grep :10000
(Not all processes could be identified, non-owned process info
will not be shown, you would have to be root to see it all.)
tcp 0 0 0.0.0.0:10000 0.0.0.0:* LISTEN 15366/java
可以看,启动的服务程序实际是一个java进程,对应的进程号是15366,该进程的监听的端口就是10000。
我们可以通过linux命令 kill 15366 来停止Hive服务程序。
上面的 hive --service hiveserver2 命令执行后,服务进程堵塞在控制台界面上,控制台窗口不能关闭,否则服务程序会退出。很多时候希望服务进程留在后台运行,这样控制台就可以关闭了。在Linux下实现程序在后台运行很简单,在上面命令后加上 & 字符,则该进程就作为后台进程启动。如下面例子:
[hadoop@localhost bin]$ hive --service hiveserver2 &
[1] 15819
[hadoop@localhost bin]$ netstat -nlp|grep :10000
(Not all processes could be identified, non-owned process info
will not be shown, you would have to be root to see it all.)
tcp 0 0 0.0.0.0:10000 0.0.0.0:* LISTEN 15819/java
[hadoop@localhost bin]$
可以看出,执行 hive --service hiveserver2 & 命令后,程序不会堵塞,并且输出了服务的进程号,这里是15819,与后面netstat查询的结果一样。这时我们把控制台关闭对服务就没影响了,服务在后台运行着。如果后面想关闭服务,执行linux命令 kill 15919即可。
Hive服务启动完毕后,我们就启动客户端程序了,有多种运行客户端的方式。第一是使用Hive提供的beeline 命令行客户端去连接hiveserver2服务器。运行beeline的具体操作过程如下:
1、在控制台运行
hive --service beeline
2、会出现beeline>提示符
3、在提示符下输入如下命令,注意不要漏了最前面的!
!connect jdbc:hive2://localhost:10000/default
4、会让输入用户名和密码,按提示输入
5、出现0: jdbc:hive2://localhost:10000/default> 提示符
6、在上面提示符下就可以执行各种hsql命令了。
具体操作过程如下:
[hadoop@localhost ~]$ hive --service beeline
Beeline version 1.2.2 by Apache Hive
beeline> !connect jdbc:hive2://localhost:10000/default
Connecting to jdbc:hive2://localhost:10000/default
Enter username for jdbc:hive2://localhost:10000/default: hadoop
Enter password for jdbc:hive2://localhost:10000/default: ******
Connected to: Apache Hive (version 1.2.2)
Driver: Hive JDBC (version 1.2.2)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://localhost:10000/default> show tables;
OK
+-----------+--+
| tab_name |
+-----------+--+
| student |
+-----------+--+
1 row selected (1.611 seconds)
0: jdbc:hive2://localhost:10000/default>
因为beeline程序是通过jdbc与Hive服务器通讯的,所以上面第3步执行的命令是一个标准的jdbc链接操作。
第二是编写程序去访问hiveserver2服务器,可以是jdbc客户端程序,也可以odbc客户端程序,还可以是thrift客户端程序。我们通过一个jdbc的例子来看下,例子的完整代码如下:
package com.hiveexample;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
public class TestJdbc {
private static String driverName = "org.apache.hive.jdbc.hiveDriver";
private static String url = "jdbc:hive2://localhost:10000/default";
private static String username = "hadoop";
private static String password = "hadoop";
public static void main(String[] args) {
loadDriver();
Connection conn=getConn();
if(conn==null){
System.out.println("conn error,exit!");
return;
}
PreparedStatement stmt = null;
ResultSet rst = null;
String sql ="select * from student";
try {
stmt = conn.prepareStatement(sql);
rst = stmt.executeQuery();
while(rst.next()){
System.out.println(rst.getString(1));
}
}catch (SQLException e) {
e.printStackTrace();
} finally {
closeConn(conn, stmt, rst);
}
}
private static void loadDriver() {
try {
Class.forName(driverName);
} catch (ClassNotFoundException e) {
e.printStackTrace();
System.exit(1);
}
}
public static Connection getConn() {
Connection conn = null;
try {
Class.forName(driverName);
conn = DriverManager.getConnection(url, username, password);
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (SQLException e) {
e.printStackTrace();
}
return conn;
}
private static void closeConn(Connection conn, PreparedStatement stmt, ResultSet rst) {
if (rst != null)
try {
rst.close();
rst = null;
} catch (SQLException e) {
}
if (stmt != null)
try {
stmt.close();
stmt = null;
} catch (SQLException e) {
}
if (conn != null)
try {
conn.close();
conn = null;
} catch (SQLException e) {
}
}
}
可以看出,上面就是一个普通的java类,通过jdbc操作数据库。编译该类不依赖任何第三方jar。但运行时,需要依赖Hive的jdbc驱动。为了简单,我们可以把编译后的class打成Jar包,然后利用Hive提供的jar服务来运行程序。假设编译后的class打成的Jar包名为hiveexample.jar,则该jar包的当前目录下,在控制台执行如下命令,即可运行该jdbc程序。
hive --service jar hiveexample.jar com.hiveexample.TestJdbc
运行hive --service jar 和运行hadoop jar类似,只是前者会同时把Hadoop的类路径和Hive的类路径同时包含进来,省的我们自己去选择运行程序时依赖的jar包路径。
(三)web模式
Hive框架提供了一种方式,可以启动一个web服务器,用户通过浏览器发送请求到web服务器,web服务器完成相关的Hive操作。具体如何配置和使用web模式,本文不作介绍。
本文只是对Hive最基本的知识的一个学习总结,很多更多高级和详细的内容没有在文中体现。