本文由 「AI前线」原创,原文链接:下一代技术:李飞飞靠它打造Cloud AutoML,吴恩达力挺
编辑 & 策划|Natalie
编译|姚佳灵、Debra
AI 前线导读:” 迁移学习是想要实现全民玩 AI 的谷歌 Cloud AutoML 背后的核心技术,也是吴恩达在 NIPS 2016 上力推的机器学习商业化又一利器,那么你对迁移学习足够了解吗?谷歌官方说的“不用写代码的迁移学习”真的有那么好用?你不知道其实微软早在 8 个月前就推出了同样的服务 Custom Vision 吧?今天我们就来唠一唠这个潜在的下一代潮流技术,还有今天刷屏的 Cloud AutoML。”
今天谷歌推出 Cloud AutoML、旨在实现全民玩 AI 的消息又刷爆了所有科技媒体头条和所有人的朋友圈。凌晨时分,李飞飞连发三条推特,发布了谷歌最新 AI 产品——Cloud AutoML Vision,“无需精通机器学习,每个人都能用这款 AI 产品定制机器学习模型。”
AutoML Vision 是 Cloud AutoML 这个大项目推出的第一项服务,提供自定义图像识别系统自动开发服务。根据谷歌介绍,即使是没有机器学习专业知识的的小白,只需了解模型基本概念,就能借这项服务轻松搭建定制化的图像识别模型。 只需在系统中上传自己的标签数据,就能得到一个训练好的机器学习模型。整个过程,从导入数据到标记到模型训练,都可以通过拖放式界面完成。
除了图像识别,谷歌未来还计划将 AutoML 服务拓展到翻译、视频和自然语言处理等领域。
是不是超厉害!是不是棒棒哒!是不是觉得小白可以翻身吊打机器学习工程师了!等等,先别激动,这事确实挺棒的,但事情可能没有你想象的那么简单。
AI 前线注意到了谷歌官方博客中提到的 Cloud AutoML 背后的核心技术——迁移学习(Transfer Learning)。通过迁移学习,谷歌就能将已训练完成的模型(又叫预训练模型,Pre-trained models),转移到新的模型训练过程,从而用较少量数据训练出机器学习模型,而 Cloud AutoML Vision 借助的预训练模型,正是“又大又好”的图像数据集 ImageNet 和 CIFAR。此外,谷歌还通过 learning2learn 功能自动挑选适合的模型,搭配超参数调整技术(Hyperparameter tuning technologies)自动调整参数。
无独有偶,在去年的 NIPS 2016 讲座上,吴恩达也表示:“在监督学习之后,迁移学习将引领下一波机器学习技术商业化浪潮。”

那么,有了迁移学习作为核心技术,Cloud AutoML 会成为下一个机器学习大杀器吗?
专家观点
Cloud AutoML 真的有那么“震惊!厉害!NB!”吗?
AI 前线在知乎上刷到了这么一个问题“如何评价谷歌刚推出的 Cloud AutoML?”,回答者中大多都对微软表示心疼。其实早在 8 个月之前,微软就已经发布了几乎一样的服务(也不用写代码、不用调参数,会拖控件就能帮你训练深度学习模型)。
答主“grapeot”表示:“真是心疼微软 pr 部门。我作为一个软狗到今天才知道 custom vision 这个东西。google 那边发布会都没开,就发了俩 twitter 媒体就轰动了。高下立判,高下立判啊!”也有答主调侃谷歌是一家“超一流的广告公司”。
于是 AI 前线也就“谷歌的 Cloud AutoML 到底有多厉害?”等一系列问题咨询了几位业界技术专家,得到的答复颇有点耐人寻味。
来自 IBM 的专家告诉 AI 前线,这还是个新兴的领域,他不认为短期内会真正产生落地的影响力和实际效果。神经网络来训练神经网络发展时间不长,所以 Cloud AutoML 的效果还需要通过实践来进一步检验。
另一位不具名技术专家认为,Cloud AutoML 目前推出的第一项服务是针对 Vision 的,ImageNet 数据集够好够大,所以大多情况下确实能够迁移出不错的效果,而且视觉现在属于比较好做的领域了,如果是 NLP、CTR 这些领域,则要难很多。大家现在有点“谷歌爸爸做的肯定都是好的”的心理,不得不说谷歌 PR 能力确实厉害。 当然,通过迁移学习实现 AutoML 这件事情本身确实给了从业者很大的想象空间,可以打破数据孤岛,更低成本地解决更多问题,比如用电商的数据去做传统行业的推荐,或者一个新公司没有数据但可以用其他公司或行业数据来做事情。
谷歌介绍称 AutoML Vision 提供了简洁的图形化用户界面,只需导入数据和拖拽组件就能打造全新模型,更有媒体报道直接突出“无需写一行代码”,那么真的可以不用写代码吗?这位专家讳莫如深地告诉 AI 前线:“不写代码容易做,不写代码能做出好结果难呀。”
第四范式是一家致力于利用机器学习、迁移学习等人工智能技术进行大数据价值提取的公司,而第四范式的联合创始人、首席科学家杨强教授更是迁移学习领域的奠基人和开拓者,他发表论文 400 余篇,论文被引用超过三万次。
这次 Cloud AutoML 推出后,很多读者也对第四范式怎么看表示强烈关切。 因此,AI 前线也将问题抛给了第四范式先知平台架构师陈迪豪,他对与我们的问题做了十分详尽的解答,整理如下:
AI 前线:你觉得谷歌 Cloud AutoML 最大的亮点有哪些?
陈迪豪: Cloud AutoML 最大的亮点是把完整的机器学习工作流做成云端易用的产品,用户只需要在界面上拖拽样本数据就可以完成数据处理、特征抽取、模型训练等全流程,针对图像分类这个场景在易用性上做到了极致。
AI 前线:谷歌开发 Cloud AutoML 系统的技术难度有多大?
陈迪豪: 目前根据 Cloud AutoML 的介绍,开发一个针对图像分类的 Cloud AutoML 难度并不大,通过对已经训练好的 Inception 模型在新数据集上进行 finetune,可以得到一个效果不错的新模型,这部分在 TensorFlow 官方文档就有介绍,开发者甚至可以在本地开发出一个“命令行版本的 Cloud AutoML Vision”。当然 Google 在过往的论文也介绍过 Learning to learn 和自动构建神经网络等算法,这些算法对于样本规模和计算能力有更高的要求,目前在业界仍处于研究阶段。
AI 前线:Cloud AutoML 使用了迁移学习等技术,用户只要上传很少的标注数据就能生成自己的模型,倒是很方便,但新模型的效果能有多好?能不能从技术角度解释一下呢?
陈迪豪: 前面已经提到,CloudML AutoML 并没有公开生成模型的算法细节,可能是基于 finetune 对模型参数进行调优,或者是用 AutoML 论文的方法重新构建神经网络模型。目前看使用 finetune 可能性较大,以使用 TensorFlow 对 Inception 模型进行 finetune 为例,用户只需要提供非常少量的标注数据即可,首先加载官方在 ImageNet 数据集上训练完成后得到的模型参数,然后在新数据集上训练神经网络的最后一层,根据 Label 和预测值更新部分的参数,很快就可以得到一个准确率超过 90% 的图像分类模型。当然也不排除 Google 已经使用或者未来将使用 AutoML 论文的算法,使用用户提供的数据集和 ImageNet 等已经标记好的数据集进行重新训练模型,模型的参数就是构建神经网络结构的参数,模型的目标就是找到图像分类正确率最高的神经网络结构,从论文的结果看在数据量和计算能力足够的情况下,机器训练得到的模型与人类设计最顶尖的模型效果接近,如果应用到 Cloud AutoML 场景下效果也不会太差。
AI 前线:你认为 Cloud AutoML 会给人工智能未来的发展带来什么样的影响?
陈迪豪: Google 的 Cloud AutoML 只是 AutoML 的一种使用场景,在此之前包括微软、亚马逊、国内的第四范式等公司都已经有 AutoML 的实际场景了,Cloud AutoML Vision 只是解决了在图像分类领域更低门槛的建模场景而已,在其他 State of the art 的机器学习领域并没有大家预期的革新式影响。当然 Google Cloud AutoML 的推出迅速引起了国外内对于自动机器学习模型构建的关注,为 AutoML 的研究和落地提供了强力的背书,相信能推动这个领域在未来有更好的发展。
AI 前线:在你看来,Cloud AutoML 会不会帮谷歌在一众云端机器学习服务厂商(微软 Azure、AWS、IBM 等)中脱颖而出?
陈迪豪: 在我看来目前 Google Cloud AutoML 还不是一个通用场景的机器学习解决方案,并不能可能直接淘汰微软、亚马逊等云机器学习平台。当然我们非常期待 Google Cloud 和 Google Brain 部门在 AutoML 后续的工作。随着 AutoML 算法的成熟和通用化,未来会有更多低门槛、贴近用户的机器学习建模范式出来,对人工智能行业也是很大的利好。
AI 前线:你所在公司推出的机器学习工具目前推广情况如何?未来是否也会计划推出类似 Cloud AutoML 这样的服务?或者还有别的比较重要的发展方向?
陈迪豪: 我目前在第四范式担任先知平台架构师,在去年乌镇互联网大会上发布的先知 3.0 就已经集成了 AutoML 功能,通过自研的 FeatureGo 自动特征组合算法和开源的自动调参算法等可以实现从特征抽取、特征组合、模型训练、超参数调优到模型上线等全机器学习工作流。目前我们在推荐系统提供给用户的模型全部以 AutoML 算法生成的。在 TensorFlow 上训练模型实现 Learning to learn 也是我们的关注重点,除此之外像大规模的数据拼接、时序特征抽取、模型灰度发布、工作流可视化以及自学习闭环都是切实的业务痛点,我们从算法和产品维度致力于打造一个比 Google Cloud AutoML 更低门槛、并且更落地的机器学习平台,也欢迎与同行们多多交流。
以下内容节选编译自知名 AI 博主、爱尔兰国立大学 NLP 博士生 Sebastian Ruder 标题为“迁移学习:机器学习的下一个前线”博文:
迁移学习到底是什么?
在机器学习经典的监督学习场景中,如果我们打算为某个任务和 A 域训练一个模型,假设我们为相同的任务和域提供了标记好的数据。我们可以在图 1 中清楚地看到,对于我们的模型 A,训练和测试数据的任务和域是一样的。稍后,我们会给出一个任务和一个域的详细定义。现在,我们假设一个任务是我们的模型要执行的目标,比如,在图片中识别物体;一个域是我们的数据来源,比如,在旧金山咖啡店拍摄的图像。
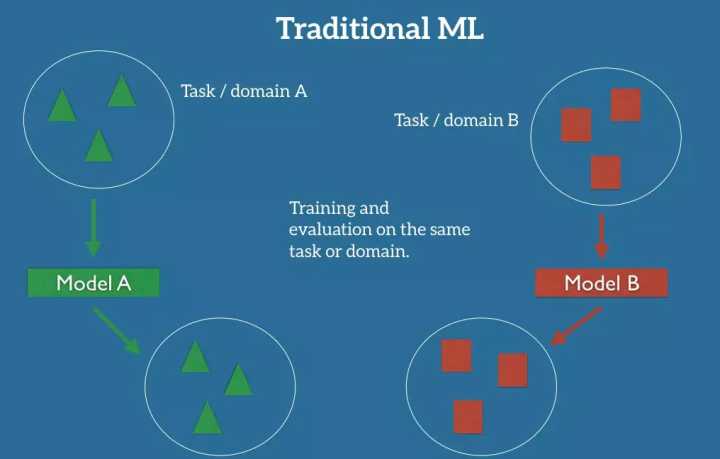
图 1:机器学习中经典的监督学习的建立
现在,我们可以在这个数据集上训练模型 a,并期望它在相同任务和域的不可见数据上表现良好。在另一种情况下,当给定其他任务或域 B 的数据时,我们需要再次标记相同任务或域的数据,以便训练新的模型 B,这样我们就可以期望它在这些数据上表现良好。
当我们没有足够的标记数据为我们所关注的要训练的可靠模型的任务或域时,经典的监督式学习范式就会崩溃。
如果我们想要训练一个模型来检测夜间图像上的行人,我们可以应用一个已经在类似的领域进行过训练的模型,比如:在日间图像上用过的。 然而在实践中,由于模型继承了训练数据的偏差,并且不知道如何推广到新的领域,我们往往会经历性能的恶化或模型的崩溃。
如果我们想要训练一个模型来执行一个新的任务,比如检测骑自行车的人,我们甚至不能重用一个现有的模型,因为任务之间的标记是不同的。
迁移学习使我们能够利用已经存在的某些相关任务或域的标记数据来处理这些场景。 我们尝试把解决源域任务所获得的知识存储在源域中,并将其应用于我们感兴趣的问题,如图 2 所示。
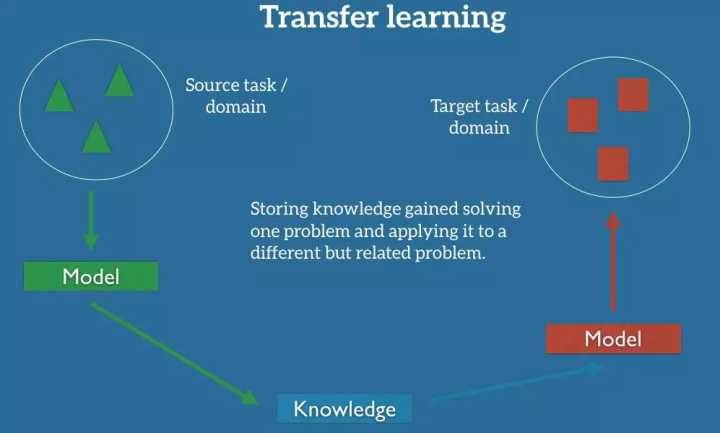
图 2:迁移学习设置
在实践中,我们试图从源头转移尽可能多的知识到我们的目标任务或域中。这种知识的形式由数据决定:它可以涉及物体是如何组成的,以便我们更容易识别新物体;可以是关于人们用来表达自己观点的一般词汇等等。
为什么迁移学习这么重要?
前百度首席科学家、斯坦福大学教授吴恩达(Andrew Ng)曾在广受欢迎的 NIPS 2016 讲座中说过:在监督学习之后,迁移学习将会成为机器学习商业成功的下一个推动力。

图 3:Andrew Ng 在 NIPS 2016 讲解迁移学习
他特意在白板上画了一张图,我尽可能忠实地复制成下面的图 4(很抱歉,我没有标记坐标轴)。 据吴恩达介绍,迁移学习将成为机器学习在行业中取得成功的关键因素。
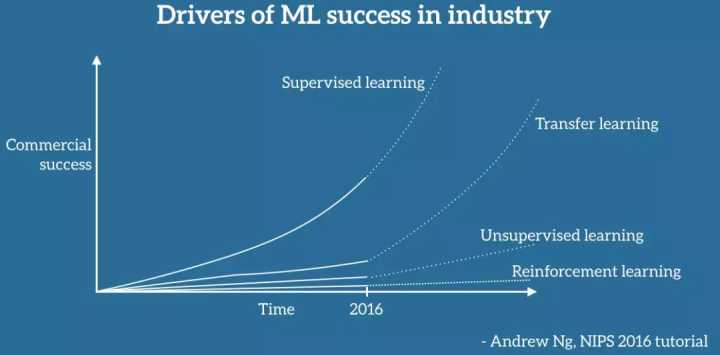
图 4:Andrew Ng 所介绍的在机器学习行业中取得成功的推动力
毋庸置疑,迄今为止机器学习在行业中的使用和成功主要是由监督学习推动的。 在深度学习的进步、功能更强大的计算工具和大型标记数据集的推动下,监督学习已经重新激发了人们对人工智能的兴趣、融资和收购的浪潮,特别是近几年来,我们已经看到机器学习的应用成为我们日常生活的一部分。 如果我们无视那些反对者和另一个 AI 冬季的预兆,而是相信 Andrew Ng 的预见,这样的成功可能会继续下去。
然而,不太清楚的是,为什么尽管迁移学习已经存在了几十年,但是目前在行业上的应用还是很少,未来是否会看到 Andrew Ng 所预测的爆炸性增长呢?甚至,与其他机器学习领域,如无监督学习和强化学习相比,迁移学习目前受到的相对较少的关注,而那些领域已经越来越受到关注:无监督学习——从图 5 中可以看出,根据 Yann LeCun 的观点,它是寻求通用 AI 的关键因素—— 已经看到了兴趣的复苏,特别受到了生成敌对网络的推动。
反过来,由谷歌 DeepMind 领头的强化学习,已经引领了 AlphaGo 的成功,并在现实世界中取得了成功,例如将谷歌的数据中心的冷却成本降低了 40%。这两个领域虽然有希望,但在可预见的未来可能只会产生相对较小的商业影响,而且大部分仍停留在尖端研究论文的范围内,因为它们仍然面临许多挑战。

图 5:在 Yann LeCun 所展示的蛋糕里,显然没有迁移学习。
迁移学习有何特别之处?
接下来,我们来看看是什么让迁移学习有所不同。在我们看来,它们激发了 Andrew Ng 的预见,并概述了为什么现在是关注迁移学习的时候。
目前在行业中对机器学习的应用呈现二元化:
一方面,在过去的几年里,我们已经获得了训练越来越精确的模型的能力。我们现在处于多任务阶段,最先进的模型已经达到了这样一个水平,它们的性能是如此的好以至于对用户来说,其不再是阻碍。有多好呢?在 ImageNet 上最新的残差网络(residual networks)实现了在识别对象时超过人类的性能;谷歌的智能回复能够自动处理 10% 的移动端回复任务;语音识别错误率不断下降,比打字输入更准确;我们可以像皮肤科医生一样自动识别皮肤癌;谷歌的 NMT 系统用于 10 多种翻译语言对的产生;百度能实时生成逼真的语音;这样的事情不胜枚举。这种成熟程度能够将这些模型大规模部署到数百万用户,并且已经被广泛采用。
另一方面,这些成功的模型非常需要数据,并且依靠大量的标记数据来实现其性能。 对于某些任务和领域,这些可用数据是多年来一直苦心经营的。 在少数情况下,它是公开的,比如, ImageNet,但是大量的标记数据通常是专有的或昂贵的,比如许多语音或 MT 数据集,因为是它们形成了竞争优势。
与此同时,在不熟悉的环境中应用机器学习模式时,模型面临着以前从未见过、不知如何处理的诸多情况;每个客户和每个用户都有自己的偏好,拥有或产生与用于训练的数据不同的数据;一个模型被要求执行许多与被训练的任务相关但不相同的任务。在所有这些情况下,我们目前最先进的模型,尽管在它们所接受的任务和域上表现出跟人类一样甚至是超人类的表现,但在性能方面却会遭受重大损失,甚至完全崩溃。
迁移学习可以帮助我们处理这些新场景,并且这对于哪些标记数据稀缺的任务领域,要使机器学习能够规模化应用,迁移学习是必不可少的。到目前为止,我们虽然已经将模型应用到了不少极具影响力的任务领域,但这些大多是数据“低树果实”,为了长远发展,我们必须学会将获得的知识转移到新的任务领域。
迁移学习还有哪些应用场景?
从模拟中学习
我认为迁移学习在将来会更多地应用于从模拟中学习,这也让我感到很兴奋。对于许多依靠硬件进行交互的机器学习应用程序来说,从现实世界中收集数据和训练模型不是昂贵、耗时,就是太危险。因此,以其他风险较小的方式收集数据是比较明智的。
在这方面,模拟是首选工具,并已在实践中被用于许多先进的机器学习系统。从模拟中学习,将获得的知识应用到实践是迁移学习的其中一个应用场景。因为源域和目标域之间的特征空间是相同的(通常两者都依赖于像素),但是模拟和现实场景中的边界概率分布不同,尽管随着模拟更接近现实,这种差异逐渐减小,但模拟场景中的物体和来源看起来仍然不同。同时,由于难以完全模拟现实世界中的所有反应,模拟与现实世界中的条件概率分布也不尽相同,例如,物理引擎不能完全模仿现实世界中物体的复杂交互。

图 6: 谷歌无人驾驶汽车(来源: 谷歌研究院博客)
然而,从模拟中学习也有好处,即可以更轻松地收集数据,这是因为模拟学习可以并行多个学习案例,在轻松绑定和分析物体的同时进行快速训练。因此,对于需要与现实世界进行交互的大型机器学习项目,它可以作为首选,比如自动驾驶汽车(参见图 6)。据谷歌的自动驾驶汽车技术负责人 Zhaoyin Jia 介绍,“如果你真的想做一辆自动驾驶汽车,模拟是必不可少的”。Udacity 已经开源了其用于训练自动驾驶汽车工程师的纳米级模拟器,如图 7 所示。OpenAI 的 Universe 也有可能会使用 GTA5 或其他视频游戏来训练自动驾驶汽车。

图 7:Udacity 的自动驾驶汽车模拟器(来源:TechCrunch)
另一个模拟学习将发生关键作用的应用领域是机器人技术:在一个真正的机器人上训练模型速度太慢且成本很高。从模拟中学习,并将知识迁移到实践中的机器人可以缓解这个问题,并且最近获得了很大的关注 [8]。图 8 是在现实世界和模拟场景中的数据操作任务示例。

图 8:机器人和模拟图像(来源:Rusu 等,2016)
最后,从模拟中学习是通向通用 AI 不可或缺的部分。训练一个代理直接在现实世界中实现通用人工智能代价太大,并且在初期不必要的复杂性会妨碍学习的效果。相反地,基于模拟环境进行学习会事半功倍,如图 9 中可见的 CommAI-env。
图 9:Facebook 人工智能研究院的 CommAI-env(来源:Mikolov 等, 2015)
适应新的域
虽然从模拟中学习是领域适应的一个特殊案例,我们还是有必要列出一些其他适应领域的例子。
在计算机视觉方向,领域适应是一个常见的需求,因为标签上的信息很容易获取,而我们真正关心的数据是不同的,无论是识别在图 10 中所示的自行车,还是在陌生环境中的其他物体。即使训练和测试数据看起来并无差异,但其中仍然可能包含对人类来说难以察觉,并会导致模型产生过度拟合的细微偏差。

图 10:不同的视觉领域(来源:Sun 等,2016)
另一个常见的领域适应场景,是适应不同的文本类型:标准的 NLP 工具,例如词类标注器或解析器,通常会使用诸如《华尔街日报》等自古以来就用于评估模型的新闻数据进行训练。然而,使用新闻数据训练的模型难以适应更新颖的文本形式,如来自社交媒体的消息。
图 11:不同的文本类型
即使在比如产品评论这样的一个领域,人们也会用不同的词语来表达同样的概念。因此,使用一种类型评论的文本的训练模式应该能够区分该领域的专业词汇和普通人使用的词汇,以免被领域的转换所迷惑。

图 12:不同的主题
最后,上述问题只是涉及到一般的文本或图像类型,但是如果将之扩大到与个人或用户群体有关的其他领域,问题就会被放大:比如语音自动识别(ASR)的情况。 语音有望成为下一个大有可为的领域,预计到 2020 年,语音搜索的占比将达 50%。传统上,大多数 ASR 系统在 Swithboard 数据集上进行评估,该数据集由 500 个说话者构成。标准口音还好,但系统很难理解移民、有口音、有言语障碍的人或儿童的语音。现在我们比以往任何时候都需要能够满足个人用户和少数群体需求的系统,以确保每个人的声音都能被理解。

图 13:不同的口音
跨语言的知识迁移
最后,在我看来,迁移学习的另一杀手级应用,是将从一种语言学习中获得知识应用到另一种语言,我已经写过关于跨语言嵌入模型的文章。可靠的跨语言适应方法将使我们能够利用已拥有的大量英文标签数据,并将其应用于任何语言,尤其是不常用和数据缺乏资源的语言。鉴于目前的最新技术水平,这似乎仍然是个乌托邦,但 zero-shot 翻译等取得的最新进展预示着我们有望在这方面更进一步。
总而言之,迁移学习为我们提供了很多激动人心的研究方向,特别是许多需要模型的应用程序,这些模型可以将知识转化为新的任务并适应新的领域。
谷歌的这场 Cloud AutoML 大秀,不论有多少 PR 的成分,只要能够推动迁移学习这一技术方向的发展,就不失为一件好事。
更多干货内容,可关注AI前线,ID:ai-front,后台回复「AI」、「TF」、「大数据」可获得《AI前线》系列PDF迷你书和技能图谱。