Tesseract官方文档页面
https://github.com/tesseract-ocr/tesseract
jTessBoxEditor官方文档页面
http://vietocr.sourceforge.net/training.html
工具和环境准备
- Tesseract-OCR引擎
- jTessBoxEditor用来训练字库
- Tesseract-OCR在centos 7中安装,jTessBoxEditor安装在win中
安装Tesseract
之所以选择在centos 7下安装Tesseract,因为在此之前安装过win版本,和在centos 6编译和yum安装过,但是在使用过程中都会提示缺少某一部分内容。
在centos 7下选择了yum安装。
在yum安装前,需要epel源。
[root@docker01 yum.repos.d]# yum install epel-release
/etc/yum.repos.d目录下就多了一个epel.repo文件
开始yum安装Tesseract
[root@docker01 yum.repos.d]# yum install tesseract
这样就会自动解决一些依赖关系,省的到后面用的时候出现各种缺少文件提示。
依赖关系解决
=======================================================================================================================================================================================
Package 架构 版本 源 大小
=======================================================================================================================================================================================
正在安装:
tesseract x86_64 3.04.00-3.el7 epel 11 M
为依赖而安装:
cairo x86_64 1.14.2-1.el7 base 711 k
fontconfig x86_64 2.10.95-7.el7 base 228 k
fontpackages-filesystem noarch 1.44-8.el7 base 9.9 k
giflib x86_64 4.1.6-9.el7 base 40 k
graphite2 x86_64 1.3.6-1.el7_2 updates 112 k
harfbuzz x86_64 0.9.36-1.el7 base 156 k
jbigkit-libs x86_64 2.0-11.el7 base 46 k
leptonica x86_64 1.72-2.el7 epel 928 k
libICE x86_64 1.0.9-2.el7 base 65 k
libSM x86_64 1.2.2-2.el7 base 39 k
libX11 x86_64 1.6.3-2.el7 base 605 k
libX11-common noarch 1.6.3-2.el7 base 162 k
libXau x86_64 1.0.8-2.1.el7 base 29 k
libXdamage x86_64 1.1.4-4.1.el7 base 20 k
libXext x86_64 1.3.3-3.el7 base 39 k
libXfixes x86_64 5.0.1-2.1.el7 base 18 k
libXft x86_64 2.3.2-2.el7 base 58 k
libXrender x86_64 0.9.8-2.1.el7 base 25 k
libXxf86vm x86_64 1.1.3-2.1.el7 base 17 k
libicu x86_64 50.1.2-15.el7 base 6.9 M
libjpeg-turbo x86_64 1.2.90-5.el7 base 134 k
libpng x86_64 2:1.5.13-7.el7_2 updates 213 k
libthai x86_64 0.1.14-9.el7 base 187 k
libtiff x86_64 4.0.3-25.el7_2 updates 169 k
libwebp x86_64 0.3.0-3.el7 base 170 k
libxcb x86_64 1.11-4.el7 base 189 k
libxshmfence x86_64 1.2-1.el7 base 7.2 k
mesa-libEGL x86_64 10.6.5-3.20150824.el7 base 74 k
mesa-libGL x86_64 10.6.5-3.20150824.el7 base 184 k
mesa-libgbm x86_64 10.6.5-3.20150824.el7 base 40 k
mesa-libglapi x86_64 10.6.5-3.20150824.el7 base 39 k
pango x86_64 1.36.8-2.el7 base 287 k
pixman x86_64 0.32.6-3.el7 base 254 k
测试是否安装成功
[root@docker01 tesseract]# tesseract
Usage:
tesseract imagename|stdin outputbase|stdout [options...] [configfile...]
OCR options:
--tessdata-dir /path specify the location of tessdata path
--user-words /path/to/file specify the location of user words file
--user-patterns /path/to/file specify the location of user patterns file
-l lang[+lang] specify language(s) used for OCR
-c configvar=value set value for control parameter.
Multiple -c arguments are allowed.
-psm pagesegmode specify page segmentation mode.
These options must occur before any configfile.
pagesegmode values are:
0 = Orientation and script detection (OSD) only.
1 = Automatic page segmentation with OSD.
2 = Automatic page segmentation, but no OSD, or OCR
3 = Fully automatic page segmentation, but no OSD. (Default)
4 = Assume a single column of text of variable sizes.
5 = Assume a single uniform block of vertically aligned text.
6 = Assume a single uniform block of text.
7 = Treat the image as a single text line.
8 = Treat the image as a single word.
9 = Treat the image as a single word in a circle.
10 = Treat the image as a single character.
Single options:
-v --version: version info
--list-langs: list available languages for tesseract engine. Can be used with --tessdata-dir.
--print-parameters: print tesseract parameters to the stdout.
查看当前有哪些语言环境
[root@docker01 tesseract]# tesseract --list-langs
List of available languages (2):
eng
就一个英语环境。
语言包所在的目录
[root@docker01 tessdata]# pwd
/usr/share/tesseract/tessdata
[root@docker01 tessdata]# ll
总用量 37624
drwxr-xr-x 2 root root 4096 10月 25 22:51 configs
-rw-r--r-- 1 root root 171918 6月 25 2015 eng.cube.bigrams
-rw-r--r-- 1 root root 38 6月 25 2015 eng.cube.fold
-rw-r--r-- 1 root root 181 6月 25 2015 eng.cube.lm
-rw-r--r-- 1 root root 857304 6月 25 2015 eng.cube.nn
-rw-r--r-- 1 root root 254 6月 25 2015 eng.cube.params
-rw-r--r-- 1 root root 13020078 6月 25 2015 eng.cube.size
-rw-r--r-- 1 root root 2444187 6月 25 2015 eng.cube.word-freq
-rw-r--r-- 1 root root 996 6月 25 2015 eng.tesseract_cube.nn
-rw-r--r-- 1 root root 21876550 6月 25 2015 eng.traineddata
-rw-r--r-- 1 root root 124215 10月 25 23:08 normal.traineddata
-rw-r--r-- 1 root root 568 1月 26 2016 pdf.ttf
drwxr-xr-x 2 root root 92 10月 25 22:51 tessconfigs
后期若要添加语言包,则可下载语言包后放到这里面。
pkgs.org中对tesseract的安装说明,已经安装后的一些文件信息
https://pkgs.org/centos-7/epel-x86_64/tesseract-3.04.00-3.el7.x86_64.rpm.html
安装jTessBoxEditor
jTessBoxEditor需要jre7(Java Runtime Environment)以上的版本支持。
安装完jre后,下载jTessBoxEditor,解压,运行train.bat文件即可运行
运行后界面图

至此两个所需要的软件安装结束。
初步识别工作
准备几张图片

把这几张图片传到安装tesseract的机器上
[root@docker01 test01]# ll
总用量 24
-rw-r--r-- 1 root root 1829 10月 24 16:05 0.gif
-rw-r--r-- 1 root root 1930 10月 24 16:05 1.gif
-rw-r--r-- 1 root root 1890 10月 24 16:05 2.gif
-rw-r--r-- 1 root root 1986 10月 24 16:05 3.gif
-rw-r--r-- 1 root root 1828 10月 24 16:05 4.gif
-rw-r--r-- 1 root root 1866 10月 24 16:06 5.gif
开始识别0.gif图片
[root@docker01 test01]# tesseract 0.gif out.0 -l eng
Tesseract Open Source OCR Engine v3.04.00 with Leptonica
Warning in pixReadMemGif: writing to a temp file, not directly to memory
这是在该目录下多了一个out.0.txt文件
[root@docker01 test01]# ll
总用量 28
-rw-r--r-- 1 root root 1829 10月 24 16:05 0.gif
-rw-r--r-- 1 root root 1930 10月 24 16:05 1.gif
-rw-r--r-- 1 root root 1890 10月 24 16:05 2.gif
-rw-r--r-- 1 root root 1986 10月 24 16:05 3.gif
-rw-r--r-- 1 root root 1828 10月 24 16:05 4.gif
-rw-r--r-- 1 root root 1866 10月 24 16:06 5.gif
-rw-r--r-- 1 root root 6 10月 26 00:52 out.0.txt
查看所识别到的内容
[root@docker01 test01]# cat out.0.txt
[54v
和图片上的I54v有点差别。
批量识别所有内容
[root@docker01 test01]# for i in {1..5};do tesseract $i.gif out.$i -l eng;done
Tesseract Open Source OCR Engine v3.04.00 with Leptonica
Warning in pixReadMemGif: writing to a temp file, not directly to memory
Tesseract Open Source OCR Engine v3.04.00 with Leptonica
Warning in pixReadMemGif: writing to a temp file, not directly to memory
Tesseract Open Source OCR Engine v3.04.00 with Leptonica
Warning in pixReadMemGif: writing to a temp file, not directly to memory
Tesseract Open Source OCR Engine v3.04.00 with Leptonica
Warning in pixReadMemGif: writing to a temp file, not directly to memory
Tesseract Open Source OCR Engine v3.04.00 with Leptonica
Warning in pixReadMemGif: writing to a temp file, not directly to memory
查看识别出的内容
[root@docker01 test01]# ll
总用量 48
-rw-r--r-- 1 root root 1829 10月 24 16:05 0.gif
-rw-r--r-- 1 root root 1930 10月 24 16:05 1.gif
-rw-r--r-- 1 root root 1890 10月 24 16:05 2.gif
-rw-r--r-- 1 root root 1986 10月 24 16:05 3.gif
-rw-r--r-- 1 root root 1828 10月 24 16:05 4.gif
-rw-r--r-- 1 root root 1866 10月 24 16:06 5.gif
-rw-r--r-- 1 root root 6 10月 26 00:52 out.0.txt
-rw-r--r-- 1 root root 9 10月 26 01:00 out.1.txt
-rw-r--r-- 1 root root 5 10月 26 01:00 out.2.txt
-rw-r--r-- 1 root root 6 10月 26 01:00 out.3.txt
-rw-r--r-- 1 root root 7 10月 26 01:00 out.4.txt
-rw-r--r-- 1 root root 5 10月 26 01:00 out.5.txt
[root@docker01 test01]# cat *.txt
[54v
ikhb‘
ymm
7y28
nl 9c
mzb
和上面的图片对应,其实就一个3.gif图片识别对了
训练工作
合成图片工作
返回到win系统上,运行jTessBoxEditor工具,把所有图片合成一张.tif格式的图片

打开所有要合成的图片

命名要合成图片的名字
注:有关这个命名有个说法,必须要按以下格式命名
tif命名规范:
[lang].[fontname].exp[num].tif
其中lang为语言名称,fontname为字体名称,num为序号,可以随便定义。
但我试了其他的明白,直接命名也是正常的。

提示创建成功,在图片目录下生成一个
mytest.tif的文件

生成box文件工作
把mytest.tif文件上传到centos 7 系统上
[root@docker01 04test]# ll
总用量 100
-rw-r--r-- 1 root root 99212 10月 26 15:42 mytest.tif
在mytest.tif所在的目录下打开一个命令行,产生相应的Box文件(*.box)
来生成一个box文件,该文件记录了tesseract识别出来的每一个字和其位置坐标。
[root@docker01 04test]# tesseract mytest.tif mytest batch.nochop makebox
Tesseract Open Source OCR Engine v3.04.00 with Leptonica
Page 1
Page 2
Page 3
Empty page!!
Empty page!!
Empty page!!
Page 4
Page 5
Page 6
Page 7
Empty page!!
Empty page!!
Empty page!!
Page 8
Page 9
Page 10
Page 11
Page 12
Page 13
Page 14
Page 15
Page 16
Page 17
Empty page!!
Empty page!!
Empty page!!
Page 18
Page 19
Page 20
Page 21
Empty page!!
Empty page!!
Empty page!!
Warning in pixReadMemTiff: tiff page 21 not found
这时目录多出了一个mytest.box和mytest.txt文件
[root@docker01 04test]# ll
总用量 108
-rw-r--r-- 1 root root 1005 10月 26 23:52 mytest.box
-rw-r--r-- 1 root root 99212 10月 26 15:42 mytest.tif
-rw-r--r-- 1 root root 101 10月 26 23:52 mytest.txt
修正文字内容
把mytest.box下载下来,放到win系统下,放到之前mytest.tif目录下。
使用jTessBoxEditor开始修正文字
修正文字会遇到的几种情况
-
普通情况
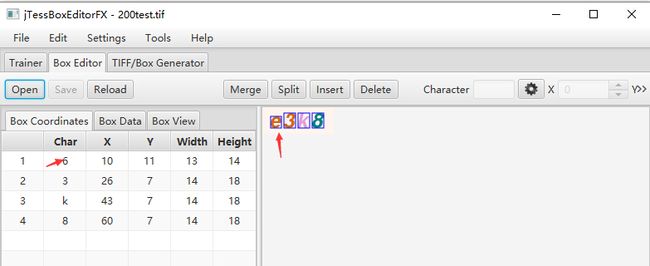
可以看到,识别到的第一个值是6,但图片中的值为e,所以开始手动修改
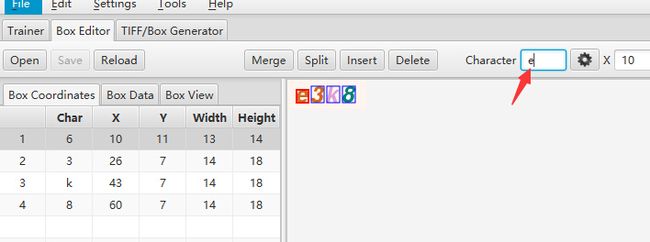
修改后,回车,然后点击save保存
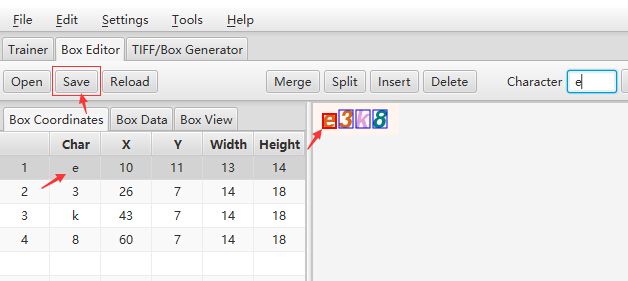
然后进行一张图片修正
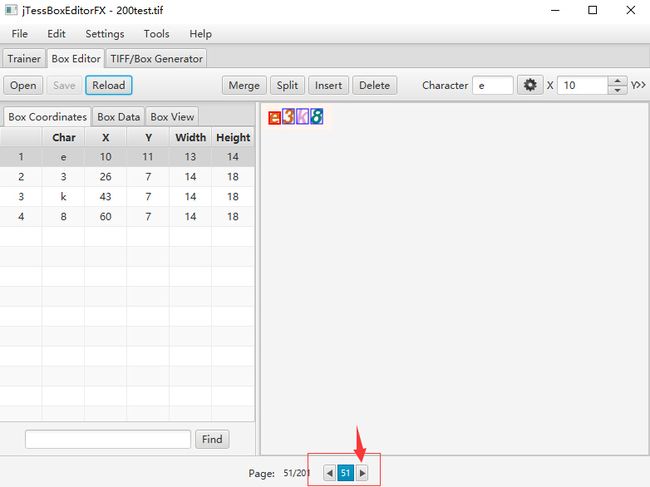
若识别到的图片的文字与图片上一样,即可继续下一张图片识别 -
表中无内容
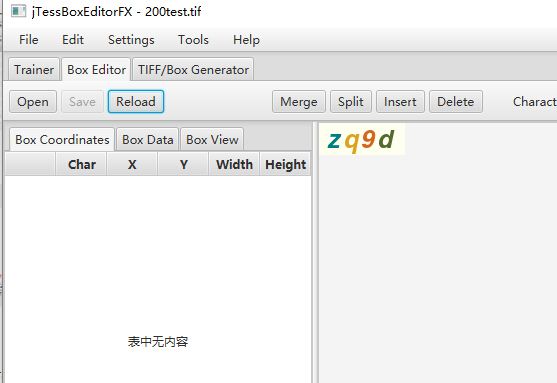
部分图片可能由于背景颜色关系,导致此张图片无法识别,可跳过继续下一张识别。
-
识别一半
例如以下图片,四个字符,只被分割成两个
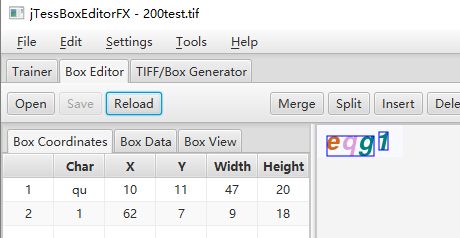
此时,可以用到分割识别框以及调整识别框位置的功能
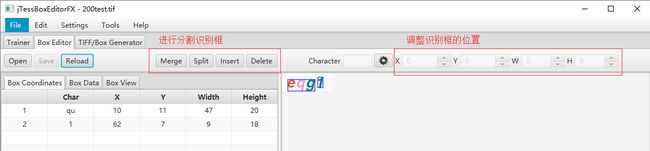
调整后的图形
Run Tesseract for Training
产生字符特征文件(*.tr)
把修正后的box文件传回centos7系统中,删除原来在centos 7系统中的box文件
[root@docker01 03test]# rm 200test.box
rm:是否删除普通文件 "200test.box"?y
[root@docker01 03test]# rz -by
rz waiting to receive.
Starting zmodem transfer. Press Ctrl+C to cancel.
Transferring 200test.box...
100% 9 KB 9 KB/sec 00:00:01 0 Errors
[root@docker01 03test]# tesseract 200test.tif 200test nobatch box.train
目录下都了一个tr文件
[root@docker01 03test]# ll
总用量 1756
-rw-r--r-- 1 root root 10210 10月 26 16:53 200test.box
-rw-r--r-- 1 root root 949532 10月 26 15:13 200test.tif
-rw-r--r-- 1 root root 830214 10月 27 00:58 200test.tr
-rw-r--r-- 1 root root 325 10月 27 00:58 200test.txt
Compute the Character Set
产生计算字符集(unicharset)
[root@docker01 03test]# unicharset_extractor 200test.box
Extracting unicharset from 200test.box
Wrote unicharset file ./unicharset.
定义字体特征文件并聚集字符特征
新建文件“font_properties”。那么需要在目录下新建一个名字为“font_properties”的文件,并且输入文本 :
注意:这里 200test 必须与训练名中的名称保持一致,填入下面内容 ,这里全取值为0,表示字体不是粗体、斜体等等。
200test 0 0 0 0 0
[root@docker01 03test]# ll
总用量 1764
-rw-r--r-- 1 root root 10210 10月 26 16:53 200test.box
-rw-r--r-- 1 root root 949532 10月 26 15:13 200test.tif
-rw-r--r-- 1 root root 830214 10月 27 00:58 200test.tr
-rw-r--r-- 1 root root 325 10月 27 00:58 200test.txt
-rw-r--r-- 1 root root 18 10月 27 01:02 font_properties
-rw-r--r-- 1 root root 2301 10月 27 01:00 unicharset
[root@docker01 03test]# cat font_properties
200test 0 0 0 0 0
执行命令:
[root@docker01 03test]# mftraining -F font_properties -U unicharset 200test.tr
Warning: No shape table file present: shapetable
Reading 200test.tr ...
Flat shape table summary: Number of shapes = 43 max unichars = 1 number with multiple unichars = 0
Warning: no protos/configs for Joined in CreateIntTemplates()
Warning: no protos/configs for |Broken|0|1 in CreateIntTemplates()
Done!
输入命令:
[root@docker01 03test]# cntraining 200test.tr
Reading 200test.tr ...
Clustering ...
Writing normproto ...
此时,在目录下应该生成若干个文件了,把unicharset, inttemp, normproto, pffmtable这四个文件加上前缀“200test.”。然后 合并训练文件
[root@docker01 03test]# ll
总用量 2100
-rw-r--r-- 1 root root 10210 10月 26 16:53 200test.box
-rw-r--r-- 1 root root 949532 10月 26 15:13 200test.tif
-rw-r--r-- 1 root root 830214 10月 27 00:58 200test.tr
-rw-r--r-- 1 root root 325 10月 27 00:58 200test.txt
-rw-r--r-- 1 root root 18 10月 27 01:02 font_properties
-rw-r--r-- 1 root root 323869 10月 27 01:03 inttemp
-rw-r--r-- 1 root root 5342 10月 27 01:04 normproto
-rw-r--r-- 1 root root 341 10月 27 01:03 pffmtable
-rw-r--r-- 1 root root 778 10月 27 01:03 shapetable
-rw-r--r-- 1 root root 2301 10月 27 01:00 unicharset
修改文件,并合并训练文件
[root@docker01 03test]# ll
总用量 2100
-rw-r--r-- 1 root root 10210 10月 26 16:53 200test.box
-rw-r--r-- 1 root root 949532 10月 26 15:13 200test.tif
-rw-r--r-- 1 root root 830214 10月 27 00:58 200test.tr
-rw-r--r-- 1 root root 325 10月 27 00:58 200test.txt
-rw-r--r-- 1 root root 18 10月 27 01:02 font_properties
-rw-r--r-- 1 root root 323869 10月 27 01:03 test200.inttemp
-rw-r--r-- 1 root root 5342 10月 27 01:04 test200.normproto
-rw-r--r-- 1 root root 341 10月 27 01:03 test200.pffmtable
-rw-r--r-- 1 root root 778 10月 27 01:03 test200.shapetable
-rw-r--r-- 1 root root 2301 10月 27 01:00 test200.unicharse
合并文件
[root@docker01 03test]# combine_tessdata test200.
Combining tessdata files
TessdataManager combined tesseract data files.
Offset for type 0 (test200.config ) is -1
Offset for type 1 (test200.unicharset ) is 140
Offset for type 2 (test200.unicharambigs ) is -1
Offset for type 3 (test200.inttemp ) is 2441
Offset for type 4 (test200.pffmtable ) is 326310
Offset for type 5 (test200.normproto ) is 326651
Offset for type 6 (test200.punc-dawg ) is -1
Offset for type 7 (test200.word-dawg ) is -1
Offset for type 8 (test200.number-dawg ) is -1
Offset for type 9 (test200.freq-dawg ) is -1
Offset for type 10 (test200.fixed-length-dawgs ) is -1
Offset for type 11 (test200.cube-unicharset ) is -1
Offset for type 12 (test200.cube-word-dawg ) is -1
Offset for type 13 (test200.shapetable ) is 331993
Offset for type 14 (test200.bigram-dawg ) is -1
Offset for type 15 (test200.unambig-dawg ) is -1
Offset for type 16 (test200.params-model ) is -1
Output test200.traineddata created sucessfully.
此时目录下“test200.traineddata”的文件拷贝到tesseract程序目录下的“tessdata”目录。
[root@docker01 03test]# cp test200.traineddata /usr/share/tesseract/tessdata
查看当前语言包有哪些
[root@docker01 tesseract_test]# tesseract --list-langs
List of available languages (4):
eng
normal
myfont
test200
至此,新的语言包已训练完成,下一步就是要用此语言包来识别图形文字
再次识别
还是最开始的5涨图片
[root@docker01 test01]# ll
总用量 44
-rw-r--r-- 1 root root 1829 10月 24 16:05 0.gif
-rw-r--r-- 1 root root 1930 10月 24 16:05 1.gif
-rw-r--r-- 1 root root 1890 10月 24 16:05 2.gif
-rw-r--r-- 1 root root 1986 10月 24 16:05 3.gif
-rw-r--r-- 1 root root 1828 10月 24 16:05 4.gif
-rw-r--r-- 1 root root 1866 10月 24 16:06 5.gif
用一个循环批量识别
[root@docker01 test01]# for i in {1..5};do tesseract $i.gif out.$i -l test200;done
Tesseract Open Source OCR Engine v3.04.00 with Leptonica
Warning in pixReadMemGif: writing to a temp file, not directly to memory
Tesseract Open Source OCR Engine v3.04.00 with Leptonica
Warning in pixReadMemGif: writing to a temp file, not directly to memory
Tesseract Open Source OCR Engine v3.04.00 with Leptonica
Warning in pixReadMemGif: writing to a temp file, not directly to memory
Tesseract Open Source OCR Engine v3.04.00 with Leptonica
Warning in pixReadMemGif: writing to a temp file, not directly to memory
Tesseract Open Source OCR Engine v3.04.00 with Leptonica
Warning in pixReadMemGif: writing to a temp file, not directly to memory
识别后输出的文件
[root@docker01 test01]# ll
总用量 48
-rw-r--r-- 1 root root 1829 10月 24 16:05 0.gif
-rw-r--r-- 1 root root 1930 10月 24 16:05 1.gif
-rw-r--r-- 1 root root 1890 10月 24 16:05 2.gif
-rw-r--r-- 1 root root 1986 10月 24 16:05 3.gif
-rw-r--r-- 1 root root 1828 10月 24 16:05 4.gif
-rw-r--r-- 1 root root 1866 10月 24 16:06 5.gif
-rw-r--r-- 1 root root 6 10月 27 01:18 out.0.txt
-rw-r--r-- 1 root root 6 10月 27 01:18 out.1.txt
-rw-r--r-- 1 root root 6 10月 27 01:18 out.2.txt
-rw-r--r-- 1 root root 6 10月 27 01:18 out.3.txt
-rw-r--r-- 1 root root 7 10月 27 01:18 out.4.txt
-rw-r--r-- 1 root root 6 10月 27 01:18 out.5.txt
查看文件内容,以及对比图片
[root@docker01 test01]# cat out.*
l54v
ikh6
ynxn
7y28
nl 9c
w4zb
图片内容
可以对比下最开始的识别情况,识别率大大提高了。