前言:
文章以Andrew Ng 的 deeplearning.ai 视频课程为主线,记录Programming Assignments 的实现过程。相对于斯坦福的CS231n课程,Andrew的视频课程更加简单易懂,适合深度学习的入门者系统学习!
这次作业的主题是使用一个隐藏层区分平面数据,涉及到两种类型的激活函数分别为tanh和sigmoid,使用gradient descent算法对参数进行更新,个人觉得这次作业的最大亮点是划分平面数据,让我们认识到神经网络不仅仅对图片有很好的performance,对其他类型的数据也是可以尝试这种方法进行classification
1.1 Dataset
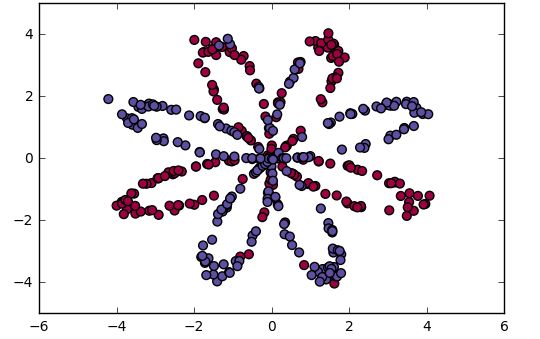
let's get the dataset,the code will load a "flower" 2-class dataset into variables X and Y:
X, Y = load_planar_dataset()
plt.scatter(X[0, :], X[1, :], c=Y, s=40, cmap=plt.cm.Spectral);
shape_X = X.shape
shape_Y = Y.shape
m = X.shape[1] # training set size
print ('The shape of X is: ' + str(shape_X))
print ('The shape of Y is: ' + str(shape_Y))
print ('I have m = %d training examples!' % (m))

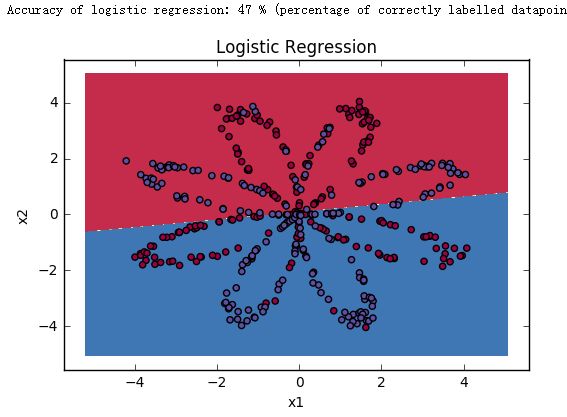
1.2 Simple Logistic Regression
Before building a full neural network, lets first see how logistic regression performs on this problem. You can use sklearn's built-in functions to do that. Run the code below to train a logistic regression classifier on the dataset.
clf = sklearn.linear_model.LogisticRegressionCV();
clf.fit(X.T, Y.T)
plot_decision_boundary(lambda x: clf.predict(x), X, Y)
plt.title("Logistic Regression")
LR_predictions = clf.predict(X.T)
print ('Accuracy of logistic regression: %d ' % float((np.dot(Y,LR_predictions) + np.dot(1-Y,1-LR_predictions))/float(Y.size)*100) +
'% ' + "(percentage of correctly labelled
1.3 Neural Network model
Logistic Regression 在 flower dataset 上的表现不是很好,所以我们尝试使用带有一个隐藏层的神经网络来训练我们的数据集
这里是我们的模型和一些数学推到:

下面是实现代码:
def layer_sizes(X, Y):
n_x = X.shape[0] # size of input layer
n_h = 4
n_y = Y.shape[0] # size of output layer
return (n_x, n_h, n_y)
def initialize_parameters(n_x, n_h, n_y):
np.random.seed(2)
W1 = np.random.randn(n_h,n_x)*0.01
b1 = np.zeros((n_h,1))
W2 = np.random.randn(n_y,n_h)*0.01
b2 = np.zeros((n_y,1))
assert (W1.shape == (n_h, n_x))
assert (b1.shape == (n_h, 1))
assert (W2.shape == (n_y, n_h))
assert (b2.shape == (n_y, 1))
parameters = {"W1": W1,
"b1": b1,
"W2": W2,
"b2": b2}
return parameters
def forward_propagation(X, parameters):
W1 = parameters["W1"]
b1 = parameters["b1"]
W2 = parameters["W2"]
b2 = parameters["b2"]
Z1 = np.dot(W1,X)+b1
A1 = np.tanh(Z1)
Z2 = np.dot(W2,A1)+b2
A2 = sigmoid(Z2)
assert(A2.shape == (1, X.shape[1]))
cache = {"Z1": Z1,
"A1": A1,
"Z2": Z2,
"A2": A2}
return A2, cache
def compute_cost(A2, Y, parameters):
m = Y.shape[1] # number of example
logprobs = Y*np.log(A2)+(1-Y)*np.log(1-A2)
cost = -1/m*np.sum(logprobs)
cost = np.squeeze(cost)
assert(isinstance(cost, float))
return cost
这是梯度下降的数学推导:

def backward_propagation(parameters, cache, X, Y):
m = X.shape[1]
W1 = parameters["W1"]
W2 = parameters["W2"]
A1 = cache["A1"]
A2 = cache["A2"]
dZ2= A2-Y
dW2 = 1/m*np.dot(dZ2,A1.T)
db2 = 1/m*np.sum(dZ2,axis=1,keepdims=True)
dZ1 = np.dot(W2.T,dZ2)*(1-A1*A1)
dW1 = 1/m*np.dot(dZ1,X.T)
db1 = 1/m*np.sum(dZ1,axis=1,keepdims=True)
grads = {"dW1": dW1,
"db1": db1,
"dW2": dW2,
"db2": db2}
return grads
def update_parameters(parameters, grads, learning_rate = 1.2):
W1 = parameters["W1"]
b1 = parameters["b1"]
W2 = parameters["W2"]
b2 = parameters["b2"]
dW1 = grads["dW1"]
db1 = grads["db1"]
dW2 = grads["dW2"]
db2 = grads["db2"]
W1 = W1-learning_rate*dW1
b1 = b1-learning_rate*db1
W2 = W2-learning_rate*dW2
b2 = b2-learning_rate*db2
parameters = {"W1": W1,
"b1": b1,
"W2": W2,
"b2": b2}
return parameters
def nn_model(X, Y, n_h, num_iterations = 10000, print_cost=False):
np.random.seed(3)
n_x = layer_sizes(X, Y)[0]
n_y = layer_sizes(X, Y)[2]
parameters = initialize_parameters(n_x, n_h, n_y)
W1 = parameters["W1"]
b1 = parameters["b1"]
W2 = parameters["W2"]
b2 = parameters["b2"]
for i in range(0, num_iterations):
A2, cache = forward_propagation(X, parameters)
cost = compute_cost(A2, Y, parameters)
grads = backward_propagation(parameters, cache, X, Y)
parameters = update_parameters(parameters, grads)
if print_cost and i % 1000 == 0:
print ("Cost after iteration %i: %f" %(i, cost))
return parameters
def predict(parameters, X):
A2, cache = forward_propagation(X, parameters)
predictions = A2>0.5
return predictions
我们调用定义好的模型进行训练:
parameters = nn_model(X, Y, n_h = 4, num_iterations = 10000, print_cost=True)
plot_decision_boundary(lambda x: predict(parameters, x.T), X, Y)
plt.title("Decision Boundary for hidden layer size " + str(4))
训练结果如下:
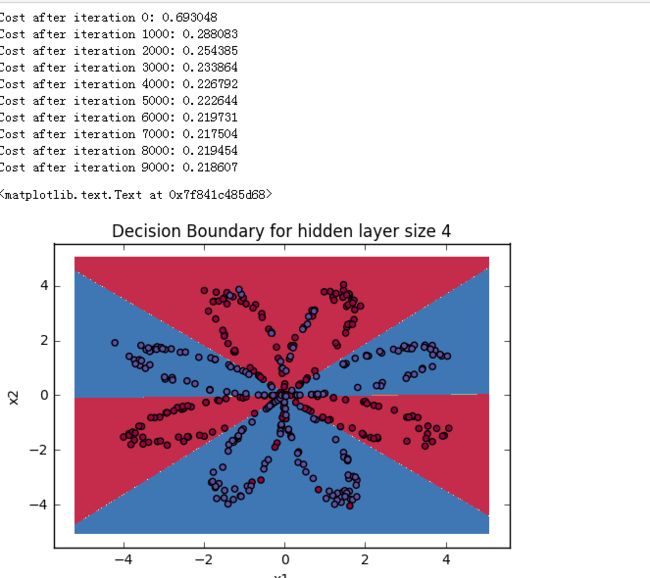
对X的数据进行预测:
predictions = predict(parameters, X)
print ('Accuracy: %d' % float((np.dot(Y,predictions.T) + np.dot(1-Y,1-predictions.T))/float(Y.size)*100) + '%')

现在我们对隐藏层的神经元数量进行tune,神经元数量分别为1,2,3,4,5,20,50,代码如下:
plt.figure(figsize=(16, 32))
hidden_layer_sizes = [1, 2, 3, 4, 5, 20, 50]
for i, n_h in enumerate(hidden_layer_sizes):
plt.subplot(5, 2, i+1)
plt.title('Hidden Layer of size %d' % n_h)
parameters = nn_model(X, Y, n_h, num_iterations = 5000)
plot_decision_boundary(lambda x: predict(parameters, x.T), X, Y)
predictions = predict(parameters, X)
accuracy = float((np.dot(Y,predictions.T) + np.dot(1-Y,1-predictions.T))/float(Y.size)*100)
print ("Accuracy for {} hidden units: {} %".format(n_h, accuracy))
结果为:

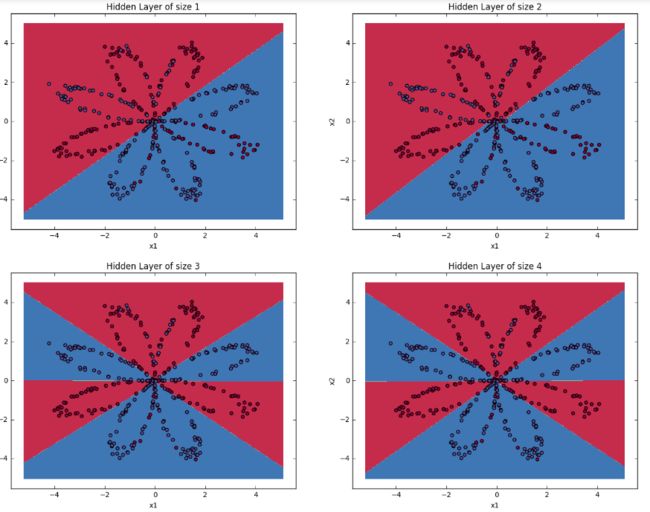

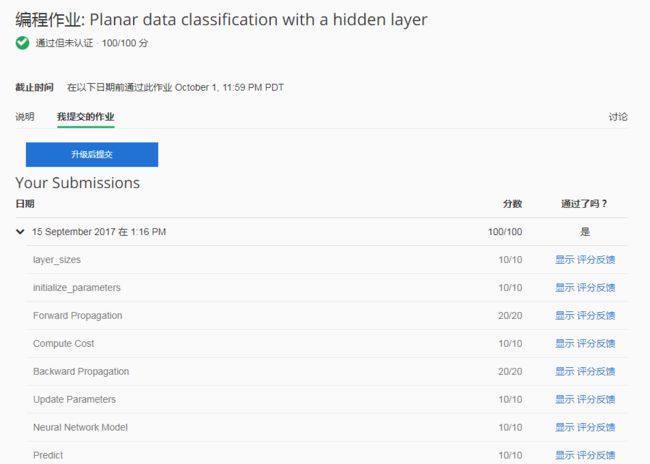
从实验结果可以看出当神经元的数量达到3个以上的时候,神经网络对flower的数据集拟合程度较好。最后附上我作业的得分,表示我的程序没有问题,如果觉得我的文章对您有用,请随意打赏,我将持续更新Deeplearning.ai的作业!